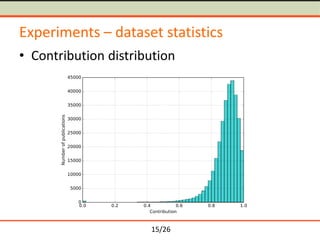
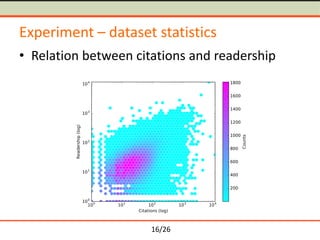
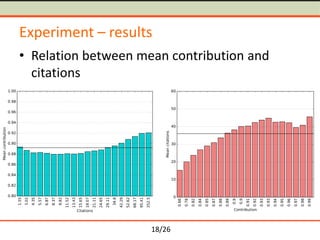
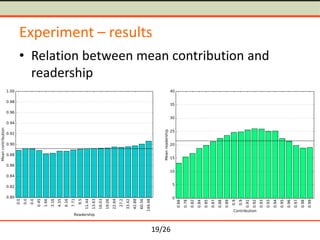
The document discusses semantometrics, a new approach to research evaluation that utilizes full-text analysis and semantic distances between publications to assess their contribution. It critiques traditional impact metrics for their limitations in capturing quality and influence and offers insights on the potential of semantometrics to consider contextual factors and improve evaluation standards. The need for a data-driven methodology in evaluating research metrics is emphasized, alongside the importance of a comprehensive dataset for accurate analysis.




![5/26
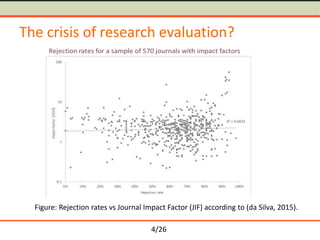
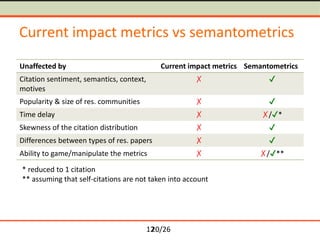
Problems of current impact metrics
• Sentiment, semantics, context and motives [Nicolaisen, 2007]
• Popularity and size of research communities [Brumback, 2009;
Seglen, 1997]
• Time delay [Priem and Hemminger, 2010]
• Skewness of the distribution [Seglen, 1992]
• Differences between types of research papers [Seglen, 1997]
• Ability to game/manipulate citations [Arnold and Fowler,
2010; PLoS Medicine Editors, 2006]](https://image.slidesharecdn.com/petr-knoth-metrics-presentation-160622110235/85/Semantometrics-Towards-Fulltext-based-Research-Evaluation-5-320.jpg)











































































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)












