Download as PDF, PPTX























![31
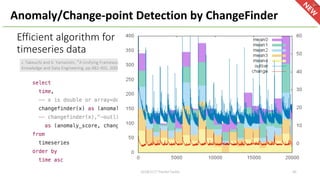
SELECT count(distinct id) FROM data
More useful functions (Sketch, NLP)
SELECT approx_count_distinct(id) FROM data
select tokenize_ja(“ ",
"normal", null, null, "https://s3.amazonaws.com/td-
hivemall/dist/kuromoji-user-dict-neologd.csv.gz");
[“ ”, "," "," "]
2018/2/17 HackerTackle](https://image.slidesharecdn.com/hackertackle-hivemall-myui-180217092348/85/Hivemall-meets-Digdag-Hackertackle-2018-02-17-31-320.jpg)

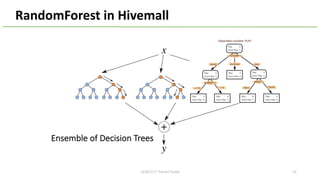



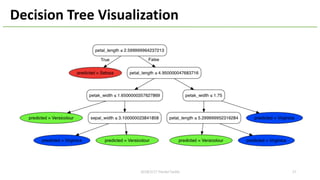
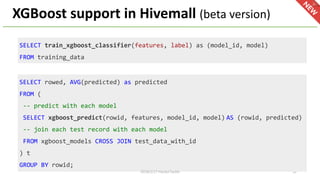





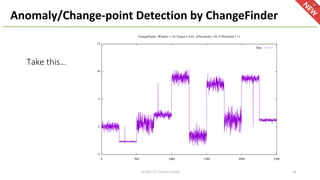
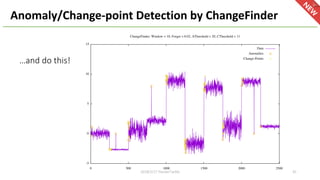


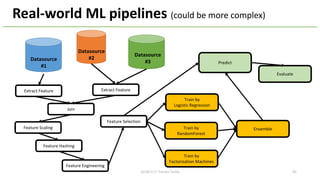
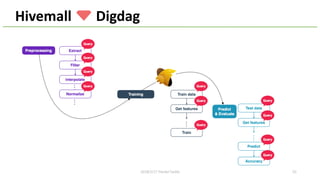
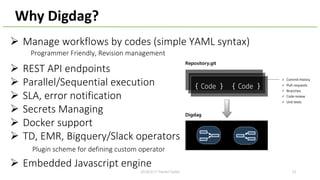

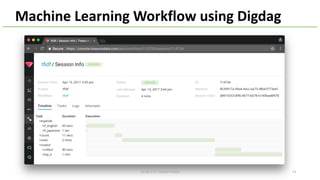
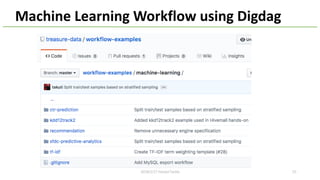




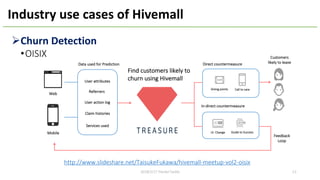
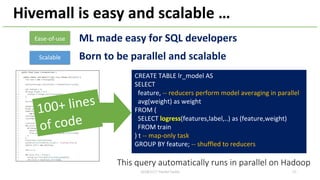
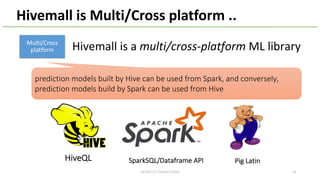
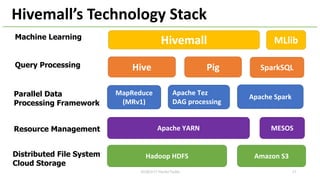
This document provides an overview of Hivemall, an open-source machine learning library built as a collection of Hive UDFs (user-defined functions). It can be used for scalable machine learning on large datasets using SQL queries. The document discusses Hivemall's supported algorithms, features, and industry use cases. It also provides examples of how to use Hivemall for tasks like classification, recommendation, and anomaly detection directly from SQL.































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






