Downloaded 103 times












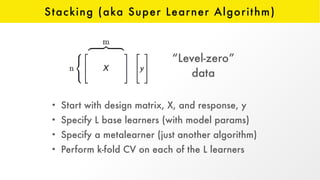
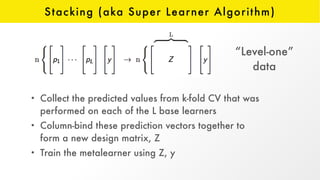










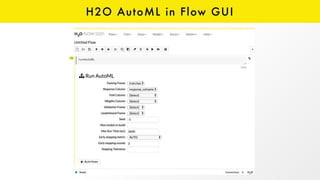
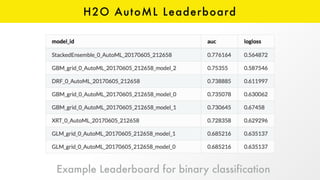



The document presents an overview of H2O.ai and its open-source machine learning platform, highlighting its capabilities in automated machine learning (AutoML), including hyperparameter optimization and model ensembles. It details the use of various techniques like Bayesian optimization and stacking to enhance model performance, as well as offering practical examples in R and Python. Additionally, it provides resources for further learning and engagement with the H2O community.












































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















