Downloaded 307 times















![29
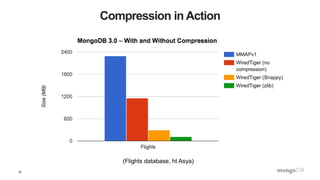
Compression
• WiredTiger uses snappy compression by default in MongoDB
• Supported compression algorithms:
– snappy [default]: good compression, low overhead
– zlib: better compression, more CPU
– none
• Indexes also use prefix compression
– stays compressed in memory](https://image.slidesharecdn.com/mongodb-wiredtiger-webinar-150709200625-lva1-app6892/85/A-Technical-Introduction-to-WiredTiger-29-320.jpg)




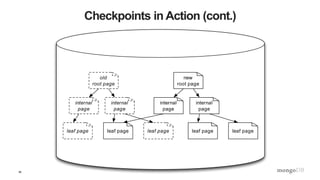


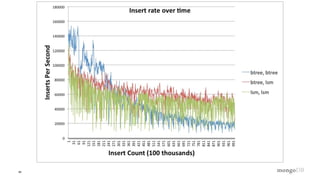



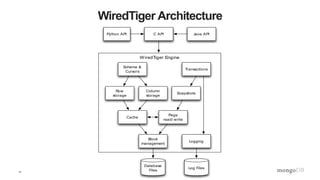
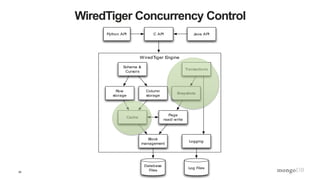
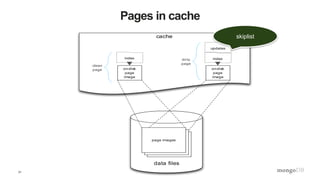
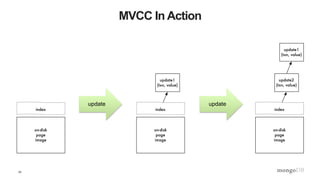
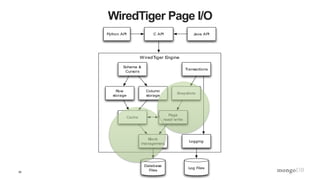
The document is a technical introduction to WiredTiger, presented by Michael Cahill from MongoDB, covering key topics such as its architecture, in-memory performance, document-level concurrency, compression, checksums, and durability. It highlights the benefits of WiredTiger in optimizing modern hardware performance and managing concurrency through techniques like multi-version concurrency control (MVCC) and checksums for data integrity. The presentation concludes with a discussion on the future developments for WiredTiger, including potential enhancements and features.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)













