






![“640K [of memory]
ought to be enough for anybody.”
Said nobody ever](https://image.slidesharecdn.com/02-mdbe17-keith-bostic-scali-7573fceb-b320-4b01-91a8-ad18030e87d4-1342727744-171116223346/85/Scaling-and-Transaction-Futures-7-320.jpg)


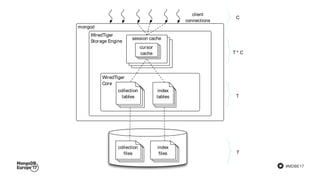

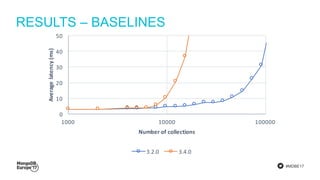



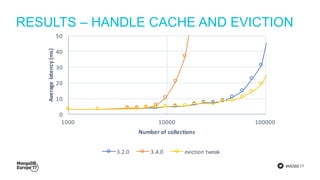



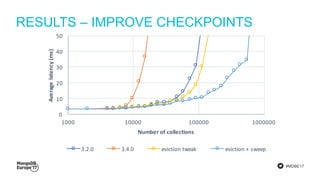

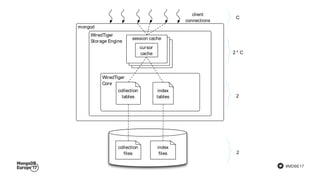
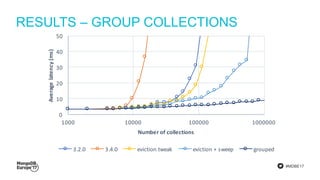
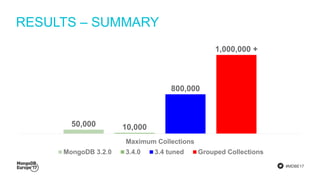








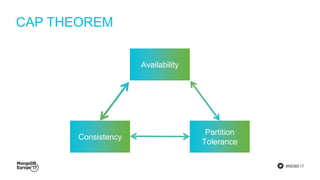










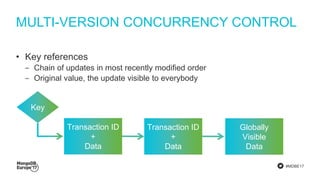












The document discusses MongoDB's journey towards supporting multi-document transactions. It describes how WiredTiger's transaction model allows for transactions that span multiple objects. MongoDB is building features on this model like retryable writes and global point-in-time reads. It introduces system timestamps to provide transaction ordering across shards. This new transactional model required significant changes to MongoDB's replication and storage engines but provides improved consistency for applications.








































![[若渴計畫] Challenges and Solutions of Window Remote Shellcode](https://cdn.slidesharecdn.com/ss_thumbnails/challengesandsolutionsofwindowremoteshellcode-171118141605-thumbnail.jpg?width=640&height=640&fit=bounds)


































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











