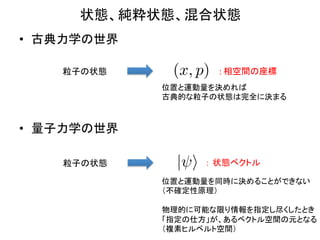
状態、純粋状態、混合状態
• 混合状態
– 純粋状態は、具体的な表示で見ると
X X
| i= |xihx| i = (x)|xi
x x
などとなり、固有状態の重ね合わせ(様々な位置にいる
状態が同時に混在している)となっている。
– 一方、複数の純粋状態の「古典的な重ね合わせ」を考え
たい場合もある
• 統計力学では、多数の粒子のあり得る配位についての確率的な
平均を考える
• それぞれの配位は物理的に干渉する訳ではないので、古典的な
重ね合わせとなる
• そのような状態を混合状態と呼ぶ
9.
状態、純粋状態、混合状態
• 混合状態
– 定義から、純粋状態 | 1 i, · · · , | k i を確率的重み
p1 , · · · , pk
で混合した混合状態に対して、物理量Aの
確率分布は
X
P (a) = pi |ha| i i|2
i
となる。
物理量Aが固有値aをとる状態のブラベクトル
10.
状態、純粋状態、混合状態
• 混合状態
– そのような混合状態を表すために、以下の密度演算子を
考えると便利
X X
⇢=
ˆ pi | i ih i | ⇢=
ˆ |xihx|ˆ|x0 ihx0 |
⇢
i x,x0
密度演算子の行列表示(密度行列)
– 密度演算子が与えられると、物理量Aの確率分布は
P (a) = ha|ˆ|ai
⇢
と書け、期待値は
X X X
aP (a) = aha|ˆ|ai =
⇢ ha|ˆA|ai ⌘ Tr(ˆA)
⇢ ⇢
a a a
と書ける
量子的Hamiltonianの取り扱い
• 量子効果を入れたHamiltonianはまともに計算する
ことができない
(Hc +Hq )
log P (x) = log Tr{e }
– 非対角な行列のexp??
• 鈴木-‐Tro9er展開
! ✓ ◆! m ✓ ◆
X Y Al 1
exp Al = exp +O
m m
l l
• Hamiltonianの非対角部分を計算可能な形に近似し、MCMCサン
プリングなどを行う
• mが一つの独立な対角Hamiltonianに対応する形となり、実装的
にはm個のシミュレーテッドアニーリングを走らせることになる
21.
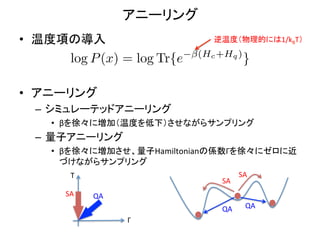
アニーリング
• 温度項の導入
逆温度(物理的には1/kBT)
(Hc +Hq )
log P (x) = log Tr{e }
• アニーリング
– シミュレーテッドアニーリング
• βを徐々に増加(温度を低下)させながらサンプリング
– 量子アニーリング
• βを徐々に増加させ、量子Hamiltonianの係数Γを徐々にゼロに近
づけながらサンプリング
T
SA
SA
SA
QA
QA
QA
Γ

















![変分ベイズ法とクラス分類
• 変分ベイズ法の枠組み
– xについての周辺尤度が
XZ P (x, , ✓)
log P (x) = d✓q( , ✓) log + KL(q||P ( , ✓|x))
q( , ✓)
XZ P (x, , ✓)
d✓q( , ✓) log ⌘ F [q]
q( , ✓)
と書け、等号が q( , ✓) = P ( , ✓|x) のときに成り立つ
ことを利用する
–
F
[q]
を最大化するqを変分的に求め、それを事後分布と
見なすことができる(F[q]を変分自由エネルギーと呼ぶ)
• そのままではqを求めることができない](https://image.slidesharecdn.com/quantumannealing-121022082430-phpapp02/85/1-18-320.jpg)



















![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep Neural Networks as Gaussian Processes](https://cdn.slidesharecdn.com/ss_thumbnails/dl0216okamoto2162-180323031830-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)































![[Paper reading] Hamiltonian Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/hamiltoniannn-200131102421-thumbnail.jpg?width=640&height=640&fit=bounds)









