Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
長岡技術科学大学 自然言語処理研究室
1,715 views
Web上の誹謗中傷を表す文の自動抽出
Technology
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 53
2
/ 53
3
/ 53
4
/ 53
5
/ 53
6
/ 53
7
/ 53
8
/ 53
9
/ 53
10
/ 53
11
/ 53
12
/ 53
13
/ 53
14
/ 53
15
/ 53
16
/ 53
17
/ 53
18
/ 53
19
/ 53
20
/ 53
21
/ 53
22
/ 53
23
/ 53
24
/ 53
25
/ 53
26
/ 53
27
/ 53
28
/ 53
29
/ 53
30
/ 53
31
/ 53
32
/ 53
33
/ 53
34
/ 53
35
/ 53
36
/ 53
37
/ 53
38
/ 53
39
/ 53
40
/ 53
41
/ 53
42
/ 53
43
/ 53
44
/ 53
45
/ 53
46
/ 53
47
/ 53
48
/ 53
49
/ 53
50
/ 53
51
/ 53
52
/ 53
53
/ 53
More Related Content
PDF
よくわかるフリストンの自由エネルギー原理
by
Masatoshi Yoshida
PDF
「生態学における統計的因果推論」という大ネタへの挑戦:その理論的背景と適用事例
by
takehikoihayashi
PDF
時系列分析入門
by
Miki Katsuragi
PDF
PFP:材料探索のための汎用Neural Network Potential - 2021/10/4 QCMSR + DLAP共催
by
Preferred Networks
PDF
関数データ解析の概要とその方法
by
Hidetoshi Matsui
PPTX
若手・中堅研究者のための科研費
by
Yasuhisa Kondo
PDF
Deep learningの発展と化学反応への応用 - 日本化学会第101春季大会(2021)
by
Preferred Networks
PDF
(修正)機械学習デザインパターン(ML Design Patterns)の解説
by
Hironori Washizaki
よくわかるフリストンの自由エネルギー原理
by
Masatoshi Yoshida
「生態学における統計的因果推論」という大ネタへの挑戦:その理論的背景と適用事例
by
takehikoihayashi
時系列分析入門
by
Miki Katsuragi
PFP:材料探索のための汎用Neural Network Potential - 2021/10/4 QCMSR + DLAP共催
by
Preferred Networks
関数データ解析の概要とその方法
by
Hidetoshi Matsui
若手・中堅研究者のための科研費
by
Yasuhisa Kondo
Deep learningの発展と化学反応への応用 - 日本化学会第101春季大会(2021)
by
Preferred Networks
(修正)機械学習デザインパターン(ML Design Patterns)の解説
by
Hironori Washizaki
What's hot
PDF
クラシックな機械学習の入門 8. クラスタリング
by
Hiroshi Nakagawa
PDF
変分推論と Normalizing Flow
by
Akihiro Nitta
PDF
汎用なNeural Network Potential「Matlantis」を使った新素材探索_浅野_JACI先端化学・材料技術部会 高選択性反応分科会主...
by
Matlantis
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PPTX
博士課程の誤解と真実 ー進学に向けて、両親を説得した資料をもとにー
by
Atsuto ONODA
PPTX
深層学習の非常に簡単な説明
by
Seiichi Uchida
PDF
Web上の誹謗中傷を表す文の自動検出
by
長岡技術科学大学 自然言語処理研究室
PDF
機械学習と深層学習の数理
by
Ryo Nakamura
PDF
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PDF
機械学習応用システムの安全性の研究動向と今後の展望
by
Nobukazu Yoshioka
PDF
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
PDF
大規模データ時代に求められる自然言語処理
by
Preferred Networks
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PPTX
バイオインフォマティクスで実験ノートを取ろう
by
Masahiro Kasahara
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
by
Deep Learning JP
PDF
深層学習を利用した音声強調
by
Yuma Koizumi
PDF
Word2vecの並列実行時の学習速度の改善
by
Naoaki Okazaki
PDF
遺伝子のアノテーション付加
by
弘毅 露崎
クラシックな機械学習の入門 8. クラスタリング
by
Hiroshi Nakagawa
変分推論と Normalizing Flow
by
Akihiro Nitta
汎用なNeural Network Potential「Matlantis」を使った新素材探索_浅野_JACI先端化学・材料技術部会 高選択性反応分科会主...
by
Matlantis
ベイズ統計学の概論的紹介
by
Naoki Hayashi
博士課程の誤解と真実 ー進学に向けて、両親を説得した資料をもとにー
by
Atsuto ONODA
深層学習の非常に簡単な説明
by
Seiichi Uchida
Web上の誹謗中傷を表す文の自動検出
by
長岡技術科学大学 自然言語処理研究室
機械学習と深層学習の数理
by
Ryo Nakamura
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
機械学習応用システムの安全性の研究動向と今後の展望
by
Nobukazu Yoshioka
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
大規模データ時代に求められる自然言語処理
by
Preferred Networks
GAN(と強化学習との関係)
by
Masahiro Suzuki
バイオインフォマティクスで実験ノートを取ろう
by
Masahiro Kasahara
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
【DL輪読会】Code as Policies: Language Model Programs for Embodied Control
by
Deep Learning JP
深層学習を利用した音声強調
by
Yuma Koizumi
Word2vecの並列実行時の学習速度の改善
by
Naoaki Okazaki
遺伝子のアノテーション付加
by
弘毅 露崎
More from 長岡技術科学大学 自然言語処理研究室
PDF
小学生の読解支援に向けた複数の換言知識を併用した語彙平易化と評価
by
長岡技術科学大学 自然言語処理研究室
PDF
小学生の読解支援に向けた語釈文から語彙的換言を選択する手法
by
長岡技術科学大学 自然言語処理研究室
PDF
Selecting Proper Lexical Paraphrase for Children
by
長岡技術科学大学 自然言語処理研究室
PDF
Automatic Selection of Predicates for Common Sense Knowledge Expression
by
長岡技術科学大学 自然言語処理研究室
PDF
用言等換言辞書を用いた換言結果の考察
by
長岡技術科学大学 自然言語処理研究室
PDF
用言等換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
PDF
質問意図によるQAサイト質問文の自動分類
by
長岡技術科学大学 自然言語処理研究室
PDF
役所からの公的文書に対する「やさしい日本語」への変換システムの構築
by
長岡技術科学大学 自然言語処理研究室
PDF
対訳コーパスから生成したワードグラフによる部分的機械翻訳
by
長岡技術科学大学 自然言語処理研究室
PDF
用言等換言辞書を人手で作りました
by
長岡技術科学大学 自然言語処理研究室
PDF
文字列の出現頻度情報を用いた分かち書き単位の自動取得
by
長岡技術科学大学 自然言語処理研究室
PDF
「やさしい日本語」変換システムの試作
by
長岡技術科学大学 自然言語処理研究室
PDF
常識表現となり得る用言の自動選定の検討
by
長岡技術科学大学 自然言語処理研究室
PDF
動詞意味類型の曖昧性解消に向けた格フレーム情報との関連調査
by
長岡技術科学大学 自然言語処理研究室
PDF
二格深層格の定量的分析
by
長岡技術科学大学 自然言語処理研究室
PDF
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
PDF
文脈の多様性に基づく名詞換言の提案
by
長岡技術科学大学 自然言語処理研究室
PDF
保険関連文書を対象とした文章校正支援のための変換誤り検出
by
長岡技術科学大学 自然言語処理研究室
PDF
Developing User-friendly and Customizable Text Analyzer
by
長岡技術科学大学 自然言語処理研究室
PDF
普通名詞換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
小学生の読解支援に向けた複数の換言知識を併用した語彙平易化と評価
by
長岡技術科学大学 自然言語処理研究室
小学生の読解支援に向けた語釈文から語彙的換言を選択する手法
by
長岡技術科学大学 自然言語処理研究室
Selecting Proper Lexical Paraphrase for Children
by
長岡技術科学大学 自然言語処理研究室
Automatic Selection of Predicates for Common Sense Knowledge Expression
by
長岡技術科学大学 自然言語処理研究室
用言等換言辞書を用いた換言結果の考察
by
長岡技術科学大学 自然言語処理研究室
用言等換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
質問意図によるQAサイト質問文の自動分類
by
長岡技術科学大学 自然言語処理研究室
役所からの公的文書に対する「やさしい日本語」への変換システムの構築
by
長岡技術科学大学 自然言語処理研究室
対訳コーパスから生成したワードグラフによる部分的機械翻訳
by
長岡技術科学大学 自然言語処理研究室
用言等換言辞書を人手で作りました
by
長岡技術科学大学 自然言語処理研究室
文字列の出現頻度情報を用いた分かち書き単位の自動取得
by
長岡技術科学大学 自然言語処理研究室
「やさしい日本語」変換システムの試作
by
長岡技術科学大学 自然言語処理研究室
常識表現となり得る用言の自動選定の検討
by
長岡技術科学大学 自然言語処理研究室
動詞意味類型の曖昧性解消に向けた格フレーム情報との関連調査
by
長岡技術科学大学 自然言語処理研究室
二格深層格の定量的分析
by
長岡技術科学大学 自然言語処理研究室
大規模常識知識ベース構築のための常識表現の自動獲得
by
長岡技術科学大学 自然言語処理研究室
文脈の多様性に基づく名詞換言の提案
by
長岡技術科学大学 自然言語処理研究室
保険関連文書を対象とした文章校正支援のための変換誤り検出
by
長岡技術科学大学 自然言語処理研究室
Developing User-friendly and Customizable Text Analyzer
by
長岡技術科学大学 自然言語処理研究室
普通名詞換言辞書の構築
by
長岡技術科学大学 自然言語処理研究室
Web上の誹謗中傷を表す文の自動抽出
1.
Web上の誹謗中傷を表す文の自動検出 07311387 山本研究室 石坂 達也
2.
2 発表の流れ 1. 研究の背景と目的 2. 各種定義 3.
提案手法 3.1 システム概要図 3.2 単語悪口度の算出 3.3 基本単語の選定 3.4 誹謗中傷文の検出 4. まとめ
3.
3 発表の流れ 1. 研究の背景と目的 2. 各種定義 3.
提案手法 3.1 システム概要図 3.2 単語悪口度の算出 3.3 基本単語の選定 3.4 誹謗中傷文の検出 4. まとめ
4.
4 研究背景(1/2) Web上には他者を誹謗中傷する書き込みが存在 ➔ 登校拒否 ➔ うつ病 ➔
ノイローゼ 最悪の場合、自殺を引き起こしている 被害者 小中学生による書き込みが増加
5.
5 研究背景(2/2) 企業や自治体による人手の監視 現状 日々増加する大量の文 時間的、作業量的に負担が大きい 問題点 半自動化により作業の効率化、負担軽減 解決案
6.
6 目的 誹謗中傷を表す文を 自動で検出するシステムの構築
7.
7 発表の流れ 1. 研究の背景と目的 2. 各種定義 3.
提案手法 3.1 システム概要図 3.2 単語悪口度の算出 3.3 基本単語の選定 3.4 誹謗中傷文の検出 4. まとめ
8.
8 各種定義 誹謗中傷 以後「悪口」と呼ぶ 批判や中傷により他者を不快にさせる表現 製品や組織などへ対する批判は対象外 悪口単語 単語単独でも他者への批判・中傷できる単語 (例)死ね、ウザい 悪口文 悪口表現を含む文(皮肉は対象外) (例)お前みたいな認識の馬鹿は死ねば良い
9.
9 発表の流れ 1. 研究の背景と目的 2. 各種定義 3.
提案手法 3.1 システム概要図 3.2 単語悪口度の算出 3.3 基本単語の選定 3.4 誹謗中傷文の検出 4. まとめ
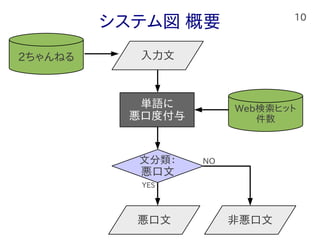
10.
10 システム図 概要 単語に 悪口度付与 2ちゃんねる 入力文 Web検索ヒット 件数 文分類: 悪口文 悪口文
非悪口文 YES NO
11.
11 単語悪口度の定義 悪口文の特徴 悪口単語を含む文が多い (例) お前は馬鹿 文や句の悪口表現を含む文
(例) サル以下の脳みそ 皮肉を表現している文 (例) あいつは頭いいからなww 悪口度 ● 悪口単語であるかどうかの可能性を示す ● 悪意が強い/弱いを意味しない 悪口の対象者の情報を必要になり、問題が大きすぎる。 本研究では皮肉は対象外 悪口単語の認識は多くの悪口文検出につながる 悪口単語か否かを判別に悪口度を活用
12.
12 悪口度算出手法 SO-PMI [Wang and
Araki, 2008] を使用 2つの基本単語を用意 ある単語がどちらの基本単語と多く共起するか Web検索ヒット数を共起数としている SO-PMI (w) = 悪口度(w)
13.
13 発表の流れ 1. 研究の背景と目的 2. 各種定義 3.
提案手法 3.1 システム概要図 3.2 単語悪口度の算出 3.3 基本単語の選定 3.4 誹謗中傷文の検出 4. まとめ
14.
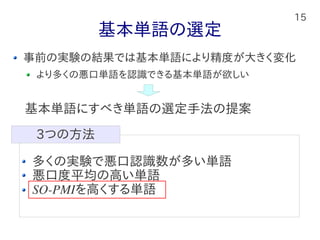
14 基本単語の選定 事前の実験の結果では基本単語により精度が大きく変化 より多くの悪口単語を認識できる基本単語が欲しい 多くの実験で悪口認識数が多い単語 悪口度平均の高い単語 SO-PMIを高くする単語 3つの方法 基本単語にすべき単語の選定手法の提案
15.
15 基本単語の選定 事前の実験の結果では基本単語により精度が大きく変化 より多くの悪口単語を認識できる基本単語が欲しい 多くの実験で悪口認識数が多い単語 悪口度平均の高い単語 SO-PMIを高くする単語 3つの方法 基本単語にすべき単語の選定手法の提案
16.
16 基本単語の条件 悪口単語との相互情報量(MI)が高い 多くの悪口単語(20以上)と共起 悪口極性の基本単語候補 悪口単語と共起しない 単独の出現頻度が多い 非悪口極性の基本単語候補
17.
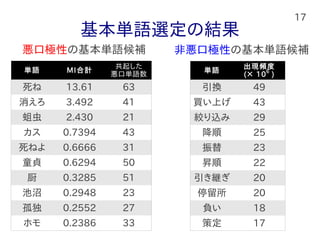
17 基本単語選定の結果 単語 MI合計 共起した 悪口単語数 死ね 13.61
63 消えろ 3.492 41 蛆虫 2.430 21 カス 0.7394 43 死ねよ 0.6666 31 童貞 0.6294 50 厨 0.3285 51 池沼 0.2948 23 孤独 0.2552 27 ホモ 0.2386 33 単語 出現頻度 (× 10 ) 引換 49 買い上げ 43 絞り込み 29 降順 25 振替 23 昇順 22 引き継ぎ 20 停留所 20 負い 18 策定 17 6 悪口極性の基本単語候補 非悪口極性の基本単語候補
18.
18 評価実験 評価用データ 異なり数2735単語 悪口単語 80語 非悪口単語 2655
語 3人の評価者が単語を悪口単語か否かを判断 3人一致で悪口単語なら悪口単語 それ以外を非悪口単語 評価方法 順位をもとした評価 悪口度が高い上位200単語の中にいくつ悪口単語があるか 単語に悪口度を与え、適切かどうかを検証
19.
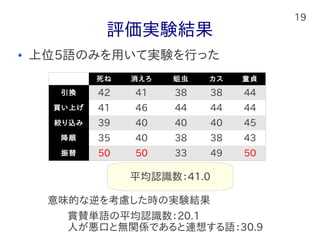
19 評価実験結果 上位5語のみを用いて実験を行った 死ね 消えろ 蛆虫
カス 童貞 引換 42 41 38 38 44 買い上げ 41 46 44 44 44 絞り込み 39 40 40 40 45 降順 35 40 38 38 43 振替 50 50 33 49 50 意味的な逆を考慮した時の実験結果 賞賛単語の平均認識数:20.1 人が悪口と無関係であると連想する語:30.9 平均認識数:41.0
20.
20 発表の流れ 1. 研究の背景と目的 2. 各種定義 3.
提案手法 3.1 システム概要図 3.2 単語悪口度の算出 3.3 基本単語の選定 3.4 誹謗中傷文の検出 4. まとめ
21.
21 文分類手法 規則による分類手法 1つでも悪口単語を含むなら悪口文 悪口度の総和が閾値を超えるなら悪口文 悪口単語の数が非悪口単語の数を超えるなら悪口文 機械学習を用いた分類手法 SVM(Support Vector Machine)を用いて分類 悪口単語を含む文が悪口文 基本的な考え方
22.
22 文分類手法 規則による分類手法 1つでも悪口単語を含むなら悪口文 悪口度の総和が閾値を超えるなら悪口文 悪口単語の数が非悪口単語の数を超えるなら悪口文 機械学習を用いた分類手法 SVM(Support Vector Machine)を用いて分類 悪口単語を含む文が悪口文 基本的な考え方
23.
23 機械学習を用いた分類手法 素性 悪口度が高い単語 ベースラインは全ての単語を素性とする 素性の重み(特徴量) 全て一律(=1) 基本単語 悪口極性:消えろ 非悪口極性:振替 閾値を超える単語 単語の存在の有無を材料に分類する
24.
24 悪口度を用いた素性の足切り 学習データへの変換例(閾値=0) 入力文: お前みたいな認識の馬鹿は死ねば良い ● お前
(0.28) ● みたい (-0.02) ● 認識 (-0.22) ● 馬鹿 (0.18) ● 死ね (0.37) ● 良い (-0.34) ● お前 (0.28) ● 馬鹿 (0.18) ● 死ね (0.37) 閾値による足切り後の素性悪口度算出 ※括弧内の数値は悪口度。重みではない
25.
25 評価用データ & 評価方法 評価用データ 悪口文/非悪口文
各1403文 評価方法 適合率, 再現率, F値による評価 5分割交差検定 適合率= 出力と正解の一致数 出力の数 再現率= 出力と正解の一致数 正解の数 F値= 2×適合率×再現率 適合率再現率
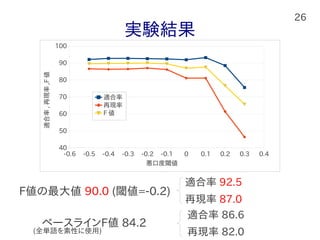
26.
26 実験結果 F値の最大値 90.0 (閾値=-0.2) 適合率
92.5 再現率 87.0 適合率 86.6 再現率 82.0 ベースラインF値 84.2 -0.6 -0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 40 50 60 70 80 90 100 適合率 再現率 F 値 悪口度閾値 適合率,再現率,F値 (全単語を素性に使用)
27.
27 発表の流れ 1. 研究の背景と目的 2. 各種定義 3.
提案手法 3.1 システム概要図 3.2 単語悪口度の算出 3.3 基本単語の選定 3.4 誹謗中傷文の検出 4. まとめ
28.
28 まとめ 単語に悪口度を付与 Web検索ヒット数をもとにしたSO-PMIの利用 SVMを使った文の分類 悪口度をもとに素性の足切り ベースラインと比較してF値が5ポイント向上 悪口文を検出するための手法を提案
29.
29 ありがとうございました
30.
30 以下 予備資料
31.
31 悪口度算出手法 悪口単語の特徴を活かせる 悪口単語同士は文書内共起しやすい 悪口/非悪口に分類された集合の準備が不要 利点 単語wがwpとwnのどちらと 文書内共起しているかの比率 何が求まるのか
32.
32 関連研究(2/2) 単語の評価極性の判別手法 1.Turney and Littman,
2002 極性を示す代表的な語(基本単語) を用意 単語 w が “excellent” と “poor” のどちらと共起しているか “excellent”ならば w は肯定極性, 逆なら w 否定極性 Web検索エンジンを使用して共起情報を獲得 2. Wang and Araki, 2008 Turney らの手法を日本語用に改良 “すばらしい” と “不良” ではヒット件数の差が大きい ヒット件数の差を考慮する要素を追加
33.
33 関連研究(1/2) 単語が悪口単語か否かを判別する手法はない しかし、特定の単語を抽出する研究は盛んに行われている 特定の分野の専門用語を抽出する手法 ある単語の関連用語を抽出する手法 評価表現を抽出する手法 悪口は人への不評表現悪口は人への不評表現
34.
34 基本単語の選択 wp:悪口単語 死ね、ウザい、キモい など 悪口の逆とは何か? 賞賛 悪口を他者への不評表現と考えた場合、逆は好評表現 悪口と無関係 「好きの反対は無関心」と同じ理屈
35.
35 評価実験 単語に悪口度を与え、正確かどうかを検証 死ね、ウザい、キモい、キチガイ、チョン、クズ、無能、ブサイク、ブス、嫌い 賞賛単語 : 可愛い、素敵、イケメン、素晴らしい、美しい 連想的無関係語:
机、チューリップ、太陽、夏、酸っぱい、四角い、赤い 非悪口極性の基本単語(12語) 悪口極性の基本単語(10語)
36.
36 他の分類手法の比較 規則による分類手法 1つでも悪口単語を含むなら悪口文 最大 F値 82.4(適合率
74.7, 再現率 91.8) 閾値=0.2 悪口度の総和が閾値を超えるなら悪口文 最大 F値 75.3 (適合率 68.0, 再現率 86.2) 閾値=-0.7 悪口単語の数が非悪口単語の数を超えるなら悪口文 最大 F値 74.8 (適合率 63.7, 再現率 90.6) 閾値=-4 機械学習による分類手法 文内の全ての単語が素性 F値 84.2 (適合率 86.6, 再現率 82.0) 閾値を超える悪口度を持つ単語のみを素性 最大 F値 90.0 (適合率 92.5, 再現率 87.0) 閾値=-0.2
37.
37 否定語の考慮 悪口単語が否定されている場合、悪口単語を含ん でいても悪口文とならない 悪口単語と否定語が文節内共起した場合は悪口単 語として扱わない 否定語は「ない」のみを取り扱う 文節の切り出しには係り受け解析器CaboChaを使用 否定語がつくことで悪口極性が打ち消される例 悪口単語:バカ、死ね、キモい
否定語と共起:バカじゃない、死ねない、キモくない
38.
38 2ちゃんねるの言語表現に対応できれば、 Web上の多くの悪口文に対応できると予想 使用する言語資源 使用するデータは全て”2ちゃんねる”より収集 2ちゃんねる 巨大で書き込み数も多い 多くの悪口文を含むことで社会的に認知 言語表現が豊富
39.
39 基本単語について wp: 「素晴らしい」,「素敵」 ←
好評表現 wn:「不良」,「悪い」 ← 不評表現 Wang and Araki 評価極性が逆の単語を使用
40.
40 基本単語選定における言語資源 使用するデータ 単語7-gram Googleが配布(Webページより作成) 異なり数 約6億 品詞は以下に限定する 動詞-自立, 名詞-一般,
形容詞 悪口単語(110語) 得られた単語を基本単語として悪口度を算出し、評価実験を行う
41.
41 基本単語の選択 wp:悪口単語 死ね、ウザい、キモい、キチガイ、チョン、クズ、無能、 ブサイク、ブス、嫌い wn:賞賛単語 可愛い、素敵、イケメン、素晴らしい、美しい wn:連想的無関係語 (人が悪口と関係ないと連想した単語) 机、チューリップ、太陽、夏、酸っぱい、四角い、赤い
42.
42 比較手法 藤村らの手法を比較手法とする [藤村ら 2005] 評価表現の極性(肯定/否定)の分類するための手法 悪口文集合と非悪口文集合のどちらに多く出現しているかを算出 悪口文/非悪口文
それぞれ1400文 を人手により収集 F w= PP w−PN w PP wPN w −1 ≤ Fw ≤ 1 w : 対象となる単語 PP(w) : 悪口文集合内でのwの出現確率 PN(w) : 非悪口文集合内でのwの出現確率
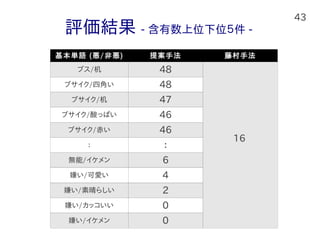
43.
43 評価結果 - 含有数上位下位5件
- 基本単語 (悪/非悪) 提案手法 藤村手法 ブス/机 48 ブサイク/四角い 48 ブサイク/机 47 ブサイク/酸っぱい 46 ブサイク/赤い 46 : : 無能/イケメン 6 嫌い/可愛い 4 嫌い/素晴らしい 2 嫌い/カッコいい 0 嫌い/イケメン 0 16
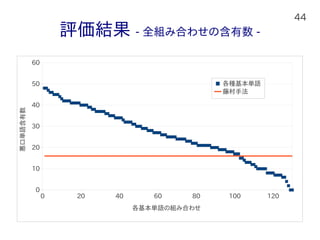
44.
44 評価結果 - 全組み合わせの含有数
- 0 20 40 60 80 100 120 0 10 20 30 40 50 60 各種基本単語 藤村手法 各基本単語の組み合わせ 悪口単語含有数
45.
45 評価結果より 比較手法よりも正確に悪口単語認識できている 130組のうち103組は比較手法より含有数が多い 最も多い時で48語 「ブサイク/四角い」「ブス/机」 賞賛単語(平均:20) < 連想的無関係語(平均:31) 形容詞(平均:24)
< 名詞 (平均:28) 基本単語により精度が大きく変化
46.
46 原因: 一部の非悪口単語に高い悪口度が付与されている 政治家の名前 など (悪口の対象となることが多い) 考察 悪口単語が下位に位置づけられる 悪口単語でなくても悪口単語に偏って共起すれば悪口度は高くなる
47.
47 原因: 一部の非悪口単語に高い悪口度が付与されている 政治家の名前 など (悪口の対象となることが多い) 考察 悪口単語が下位に位置づけられる 対処しない 悪口単語を持たない悪口文の検出に活用する 悪口単語でなくても悪口単語に偏って共起すれば悪口度は高くなる
48.
48 学習データ & 実験方法
& 評価方法 学習データ 悪口文/非悪口文 各1403文 2ちゃんねるより収集 実験方法 5分割交差検定 評価方法 適合率, 再現率, F値による評価 適合率= 出力と正解の一致数 出力の数 再現率= 出力と正解の一致数 正解の数 F値= 2×適合率×再現率 適合率再現率
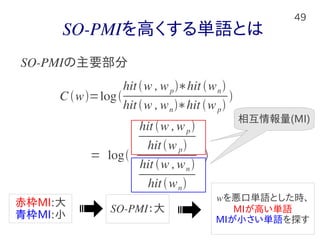
49.
49 SO-PMIを高くする単語とは C w=log hitw ,wp∗hit
wn hitw ,wn∗hit wp SO-PMIの主要部分 = log hit w ,wp hitwp hit w ,wn hitwn 相互情報量相互情報量(MI) 赤枠MI:大 青枠MI:小 SO-PMI:大 wを悪口単語とした時、 MIが高い単語 MIが小さい単語を探す
50.
50 まとめ 単語に悪口度を付与 文書内共起をもとにしたSO-PMIの利用 比較手法よりも多く悪口単語を認識できた 基本単語の選定 SO-PMIが高くなるような基本単語を探索 悪口極性:悪口単語とのMIが高く、多くの悪口単語と共起する語 非悪口極性:悪口単語と共起せず、単独の出現頻度が高い語 SVMを使った文の分類 悪口度をもとに素性の足切り ベースラインと比較してF値が5ポイント向上 悪口文を検出するための手法を提案
51.
51 悪口度算出手法 SO-PMI [Wang and
Araki, 2008] を使用 Cw=log hitw ,wp∗hit wn hitw ,wn∗hitwp f =∗log hit wp hit wn SO‐ PMI w=C w f SO-PMI (w) = 悪口度(w)
52.
52 悪口度算出手法 SO-PMI [Wang and
Araki, 2008] を使用 Cw=log hitw ,wp∗hit wn hitw ,wn∗hitwp f =∗log hit wp hit wn SO‐ PMI w=C w f wp :悪口極性の基本単語 wn :非悪口極性の基本単語 hit 関数 :Web検索ヒット件数 f 関数:検索ヒット件数の差を考慮した重み(α=0.9)
53.
53 誤り解析 悪口単語の認識誤り 造語のより正確な単語分割が出来ず、悪口単語を認識 できなかった。 (例) 意味がわからんスレたてるな競馬鹿 意味 が
わから ん スレ たてる な 競馬 鹿 悪口度 高 悪口度 高悪口度 低
Download












![12
悪口度算出手法
SO-PMI [Wang and Araki, 2008] を使用
2つの基本単語を用意
ある単語がどちらの基本単語と多く共起するか
Web検索ヒット数を共起数としている
SO-PMI (w) = 悪口度(w)](https://image.slidesharecdn.com/11thesis-ishisaka-140312035608-phpapp02/85/Web-12-320.jpg)

























![42
比較手法
藤村らの手法を比較手法とする [藤村ら 2005]
評価表現の極性(肯定/否定)の分類するための手法
悪口文集合と非悪口文集合のどちらに多く出現しているかを算出
悪口文/非悪口文 それぞれ1400文 を人手により収集
F w=
PP w−PN w
PP wPN w
−1 ≤ Fw ≤ 1
w : 対象となる単語
PP(w) : 悪口文集合内でのwの出現確率
PN(w) : 非悪口文集合内でのwの出現確率](https://image.slidesharecdn.com/11thesis-ishisaka-140312035608-phpapp02/85/Web-42-320.jpg)





![51
悪口度算出手法
SO-PMI [Wang and Araki, 2008] を使用
Cw=log
hitw ,wp∗hit wn
hitw ,wn∗hitwp
f =∗log
hit wp
hit wn
SO‐ PMI w=C w f
SO-PMI (w) = 悪口度(w)](https://image.slidesharecdn.com/11thesis-ishisaka-140312035608-phpapp02/85/Web-51-320.jpg)
![52
悪口度算出手法
SO-PMI [Wang and Araki, 2008] を使用
Cw=log
hitw ,wp∗hit wn
hitw ,wn∗hitwp
f =∗log
hit wp
hit wn
SO‐ PMI w=C w f
wp :悪口極性の基本単語
wn :非悪口極性の基本単語
hit 関数 :Web検索ヒット件数
f 関数:検索ヒット件数の差を考慮した重み(α=0.9)](https://image.slidesharecdn.com/11thesis-ishisaka-140312035608-phpapp02/85/Web-52-320.jpg)
















































