Downloaded 12 times


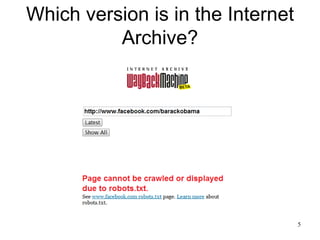
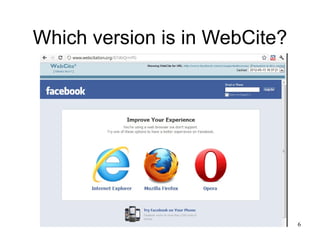
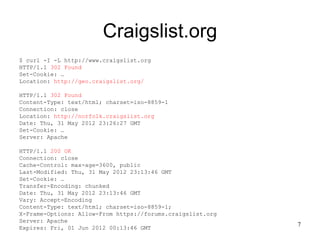
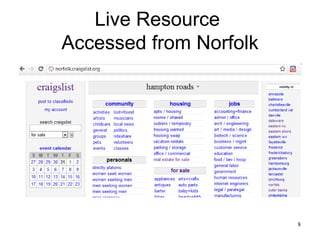


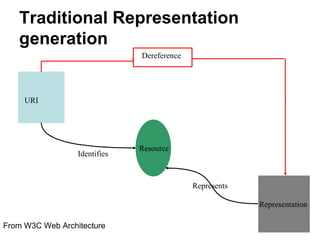
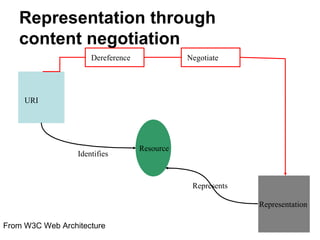
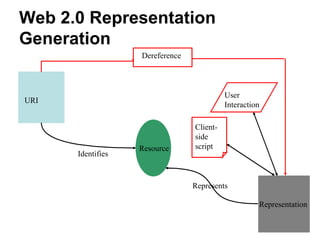













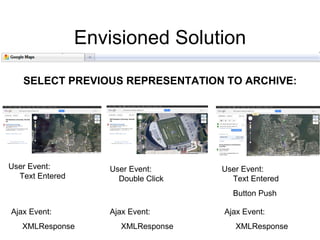

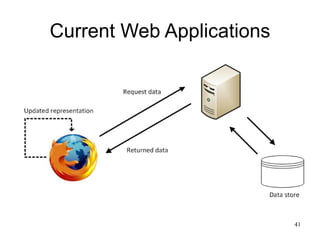
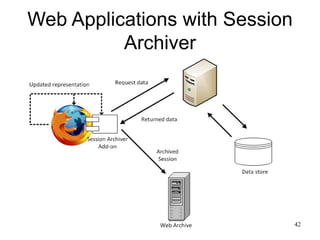

The document discusses challenges in archiving dynamically generated web content, particularly focusing on how user experiences and interactions can be effectively captured and represented. It highlights limitations of traditional web crawlers and proposes potential solutions such as browser add-ons for crowd-sourced archiving. The aim is to improve the inclusion of personal content in web archives and address questions surrounding the archiving of dynamic content.













































































