Download to read offline



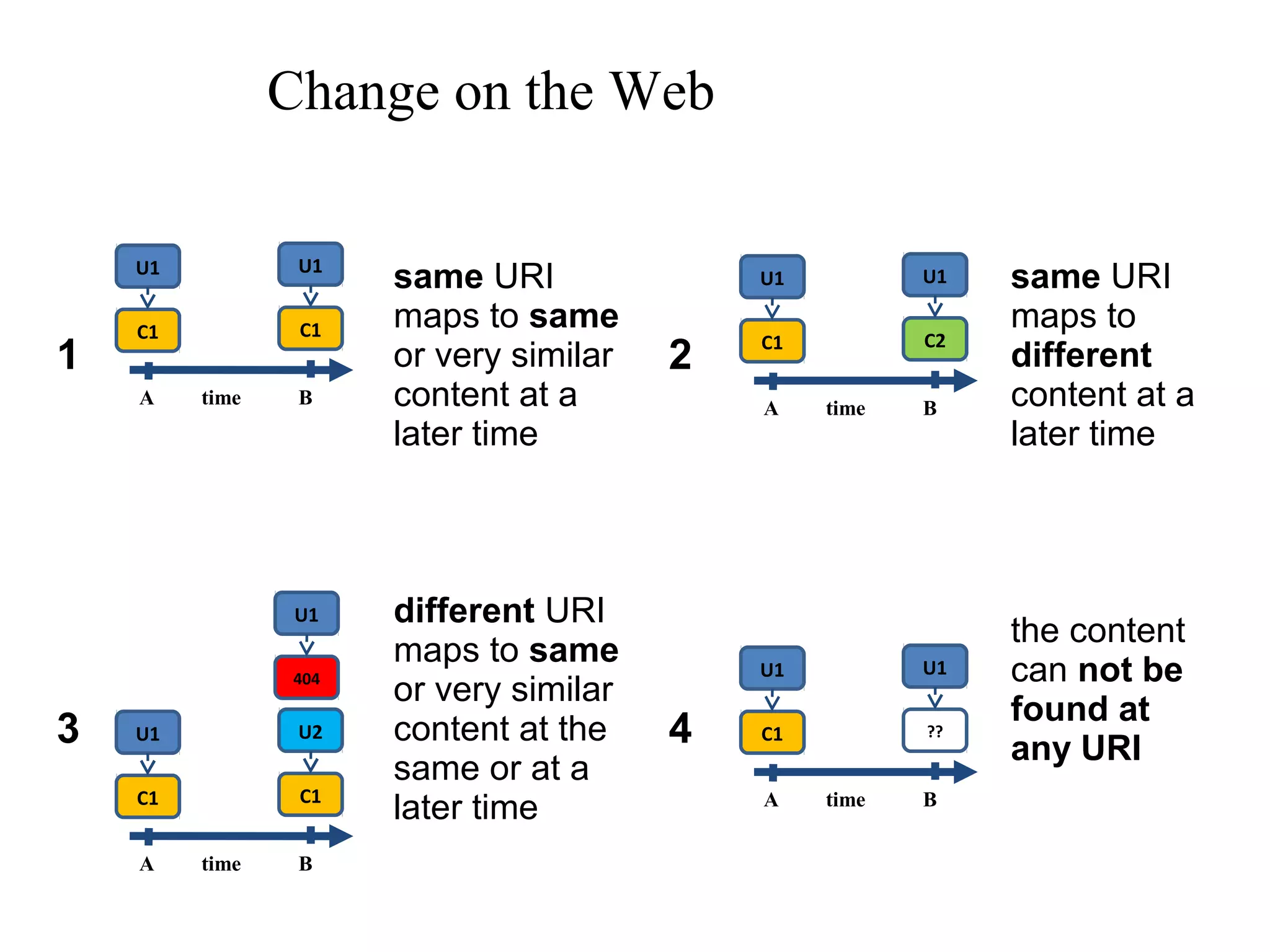






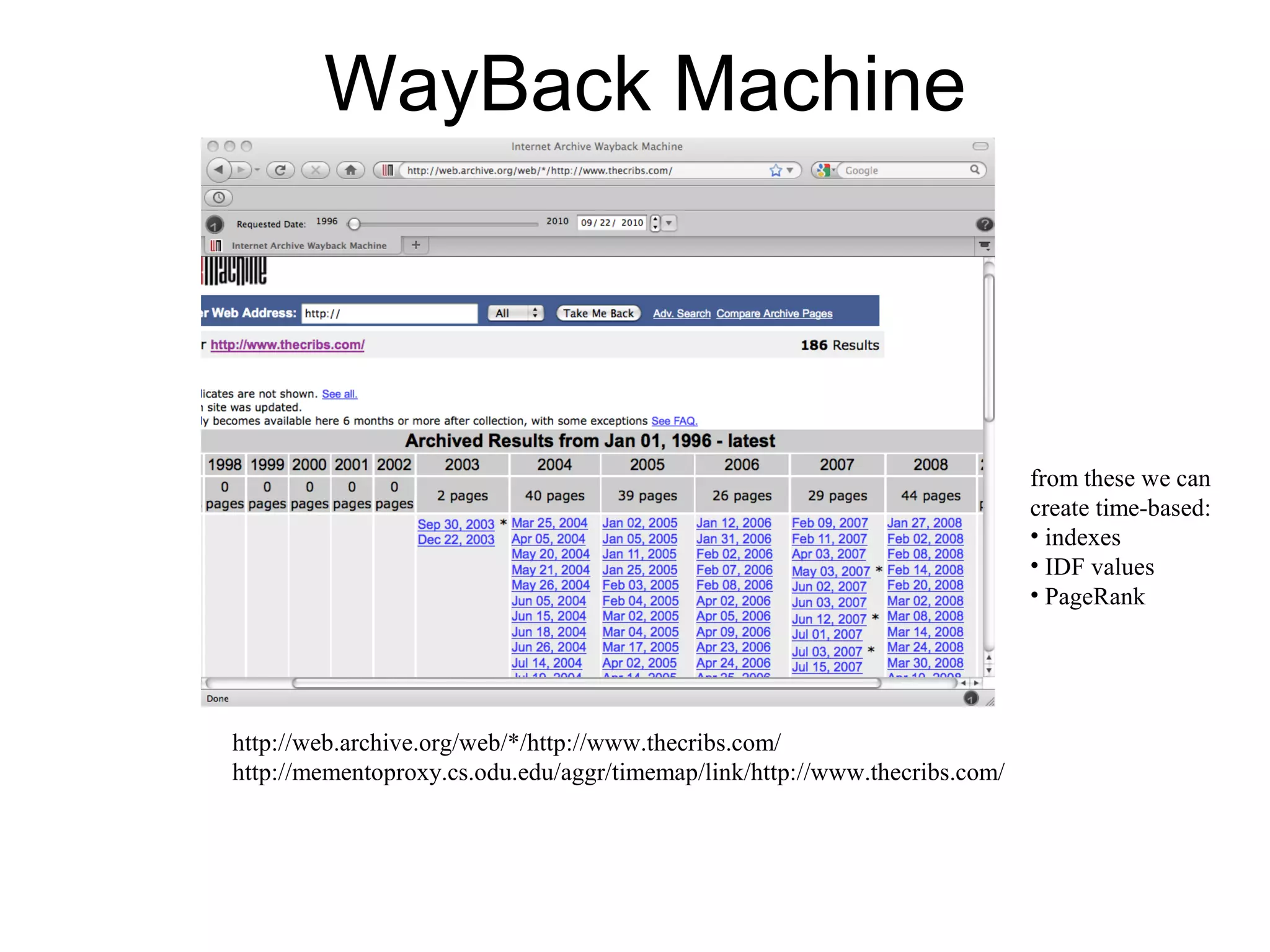
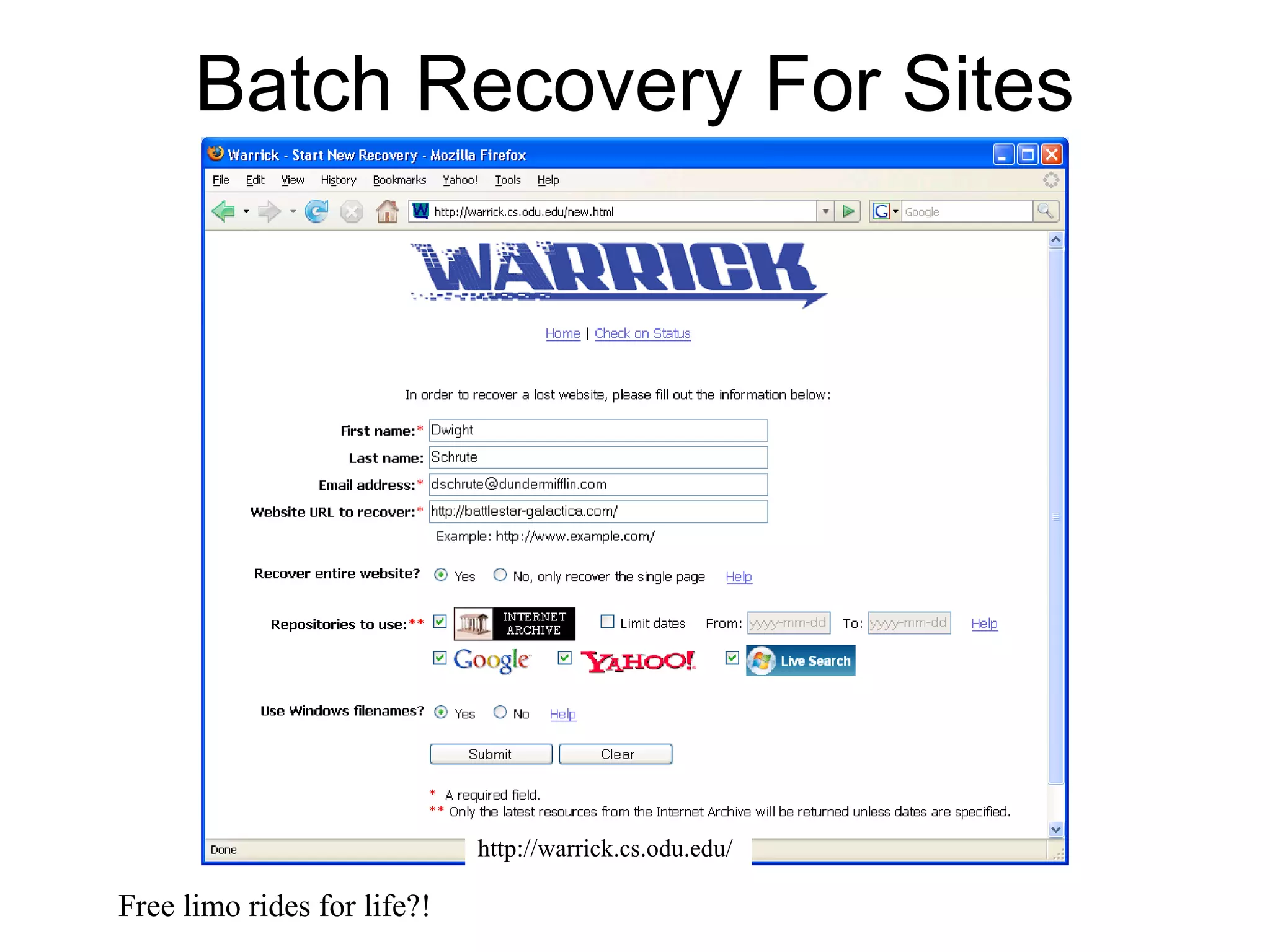
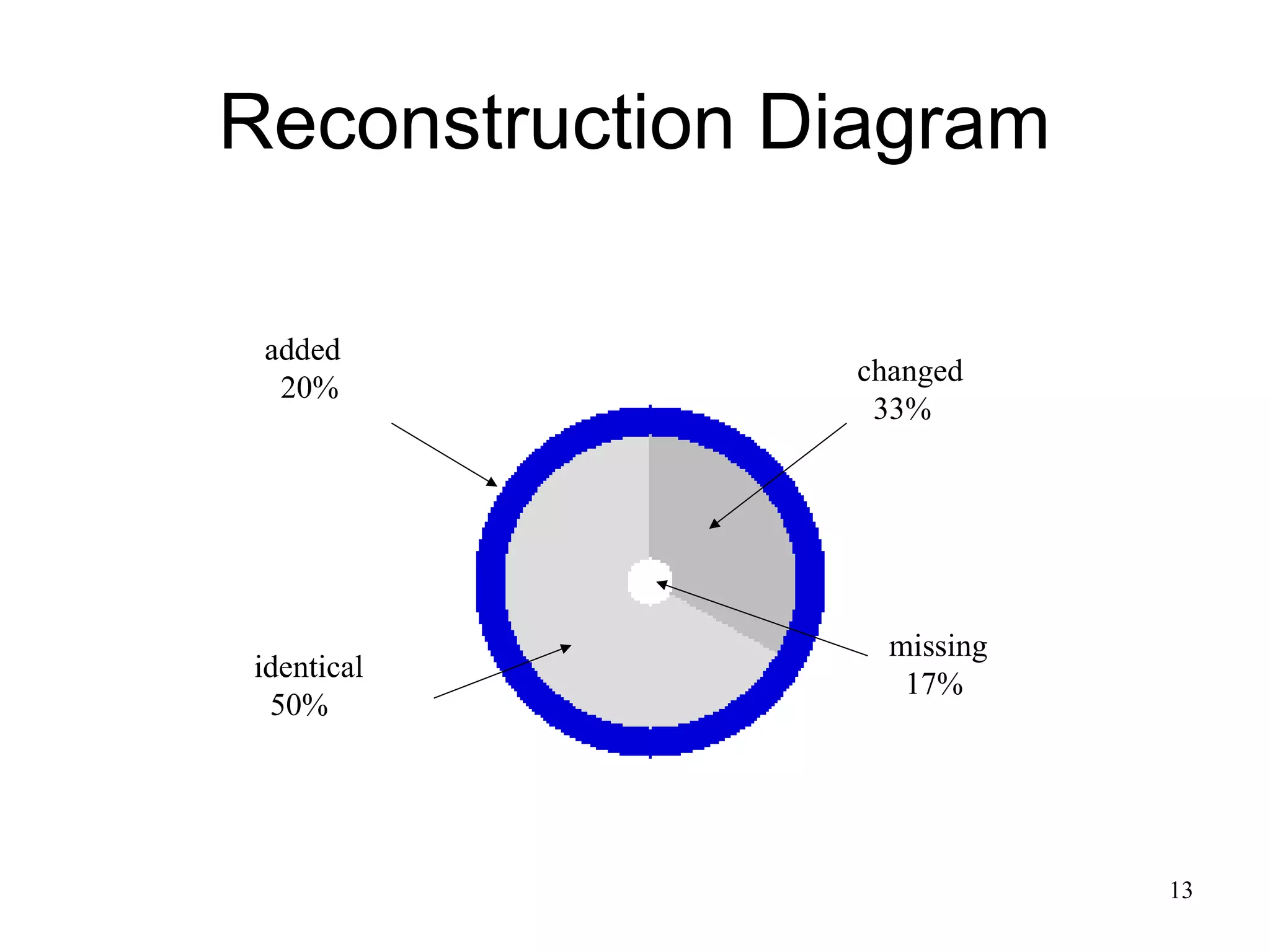
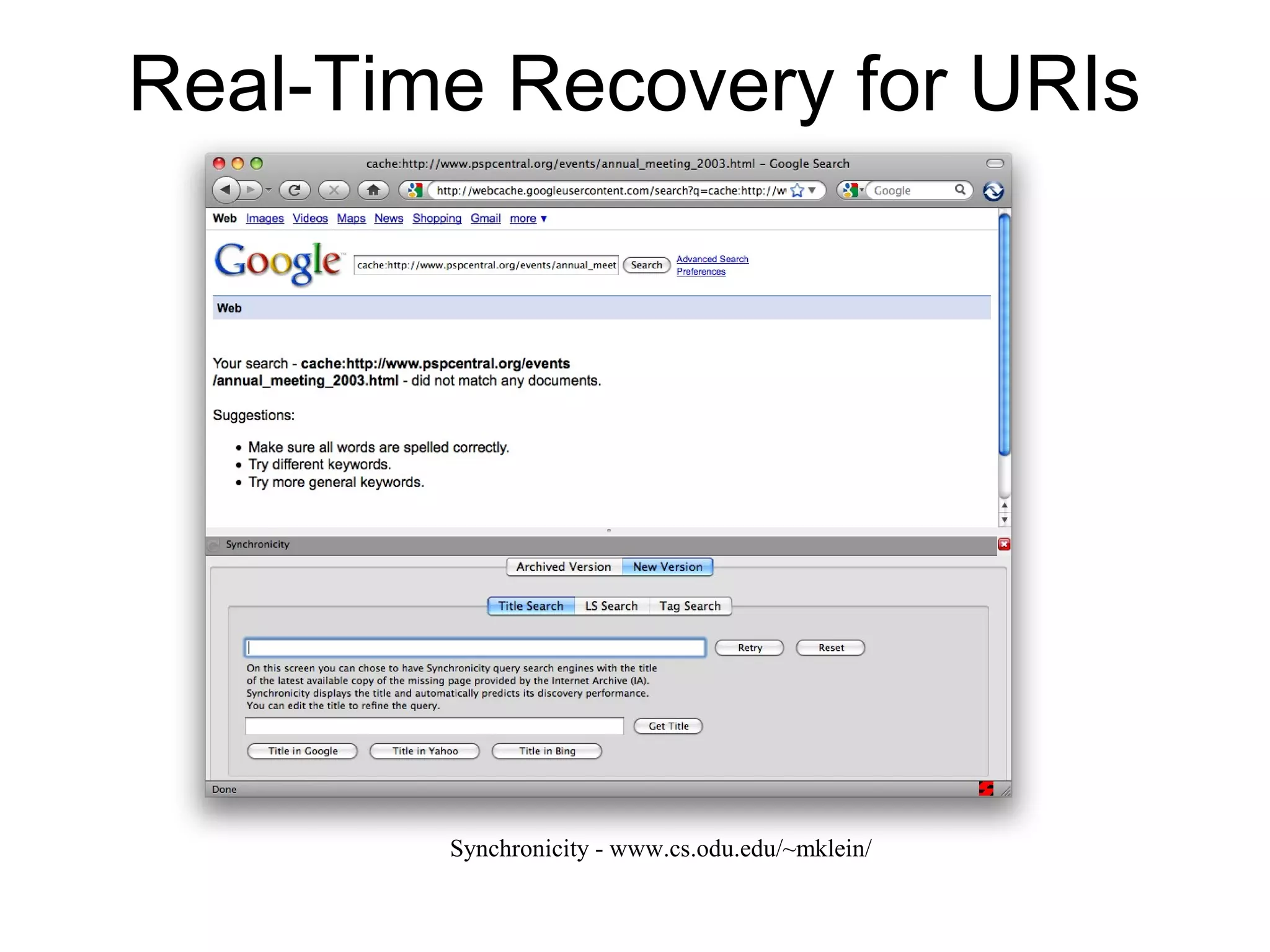


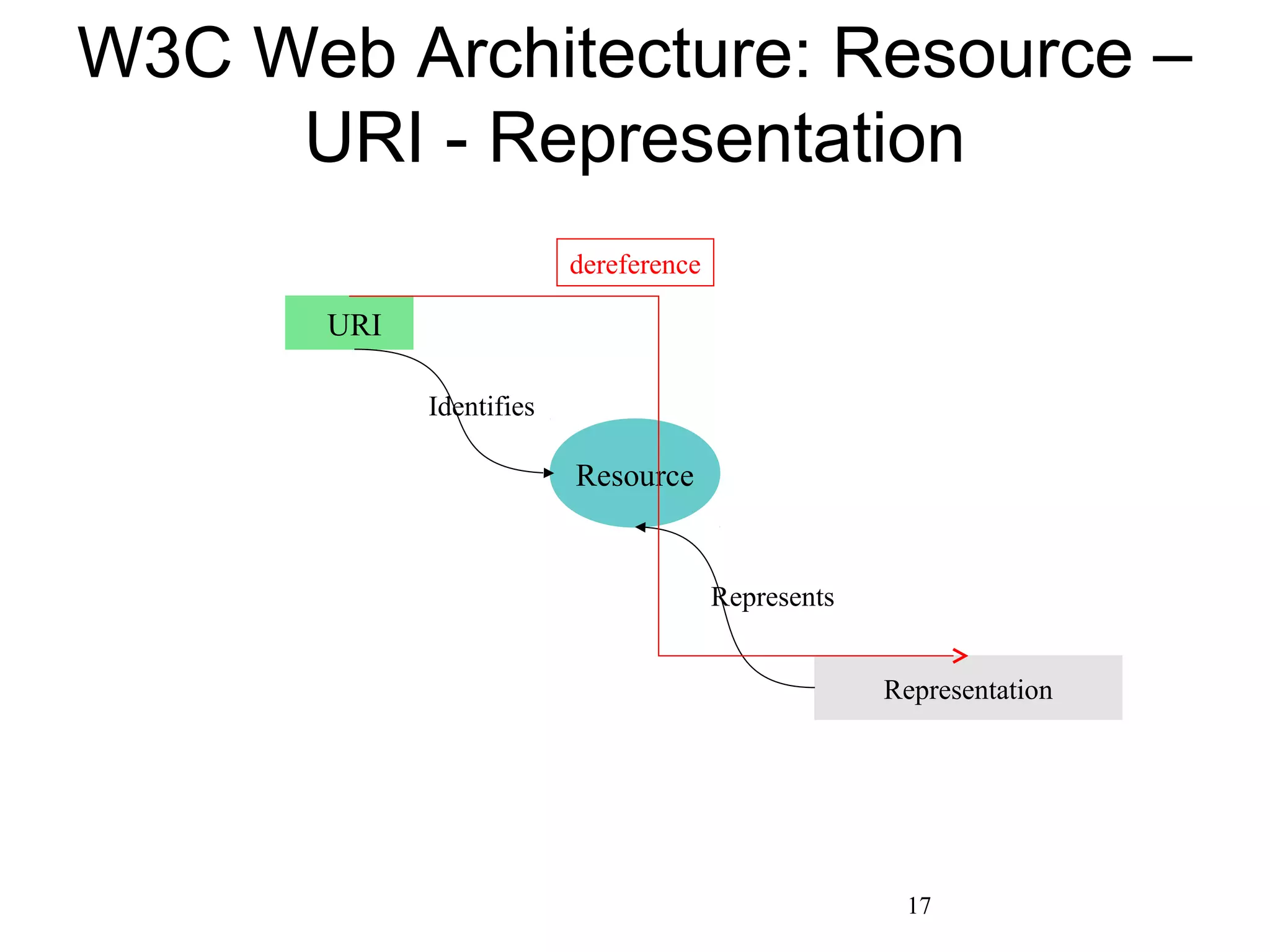
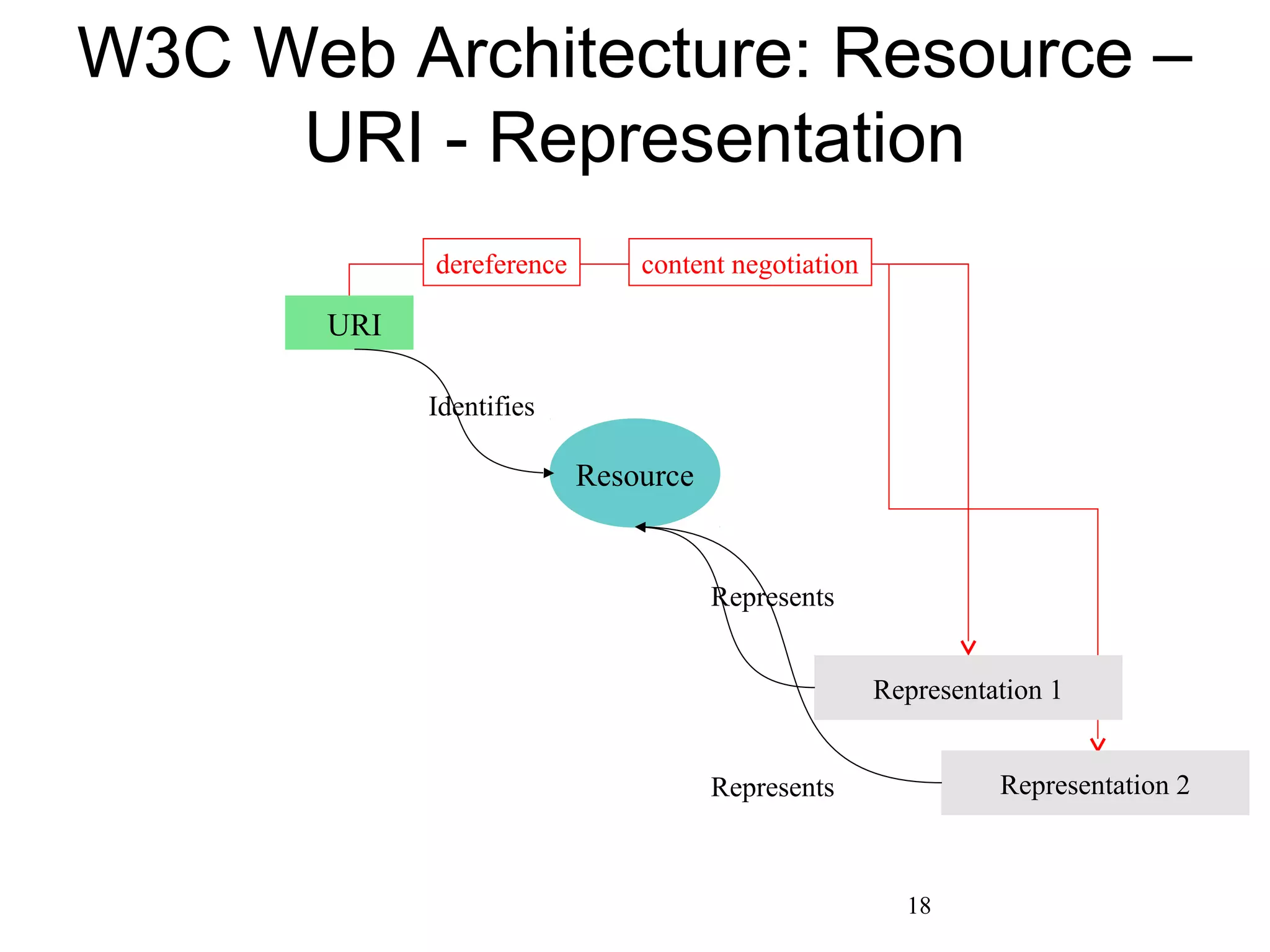

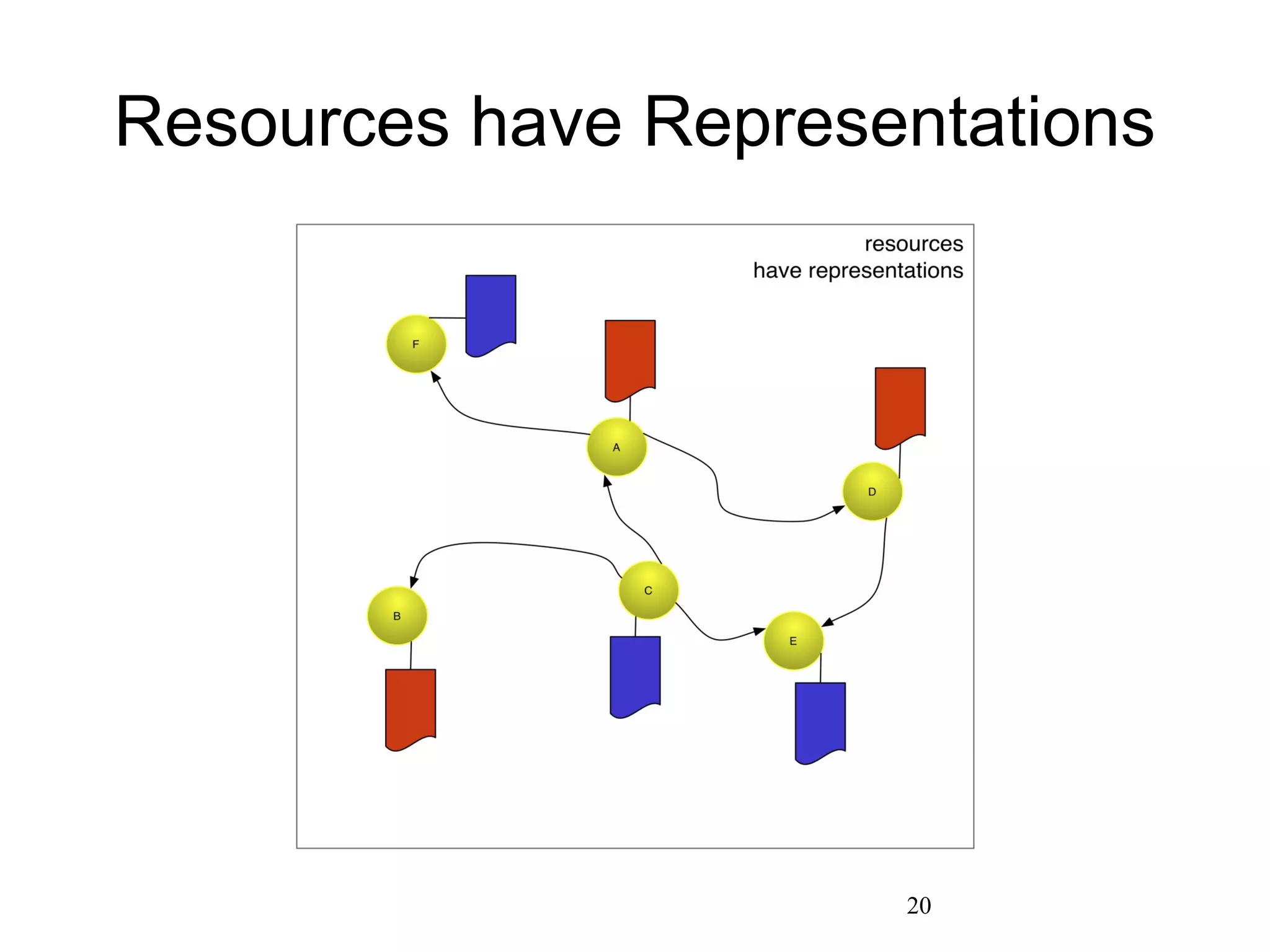
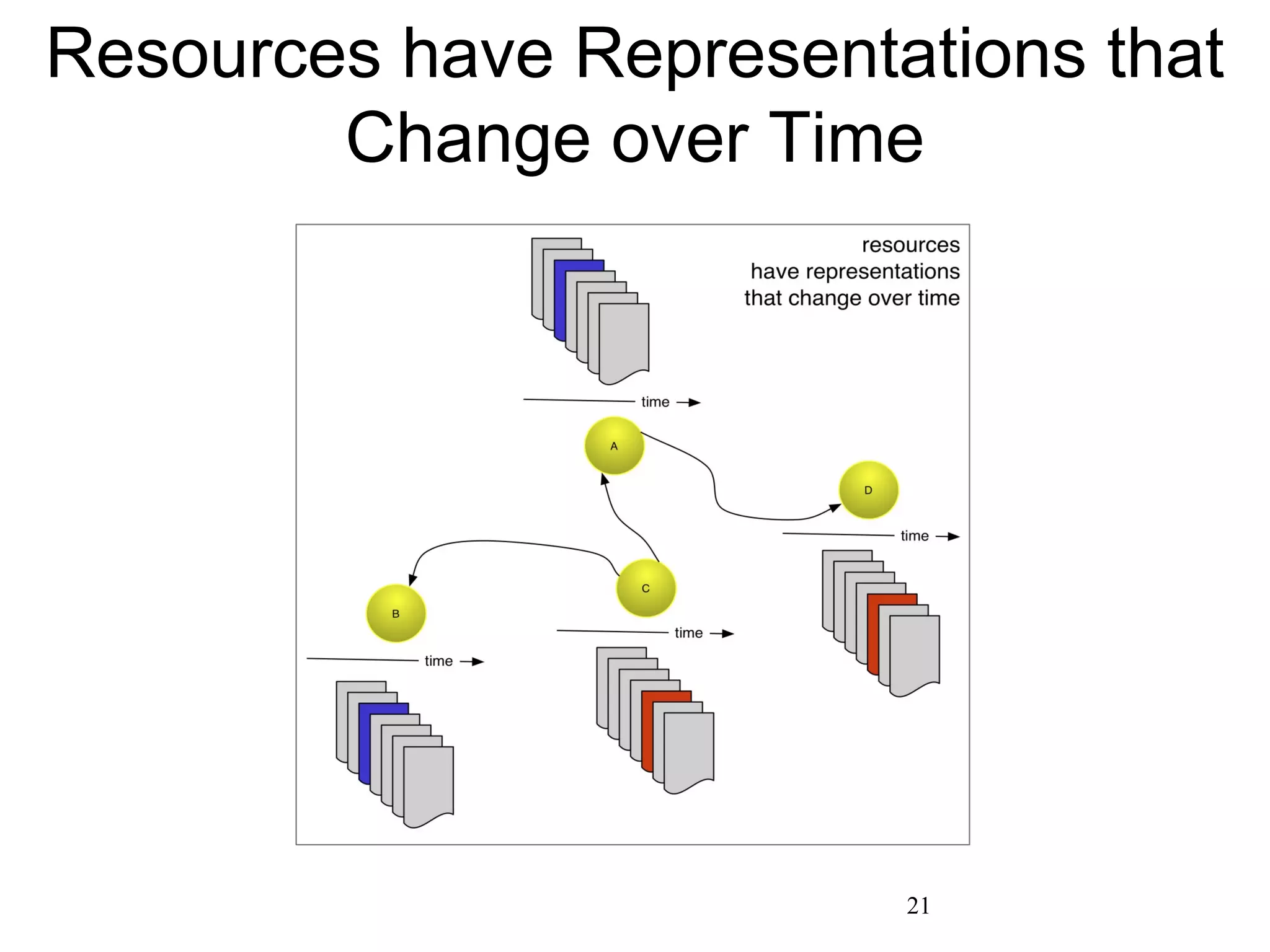

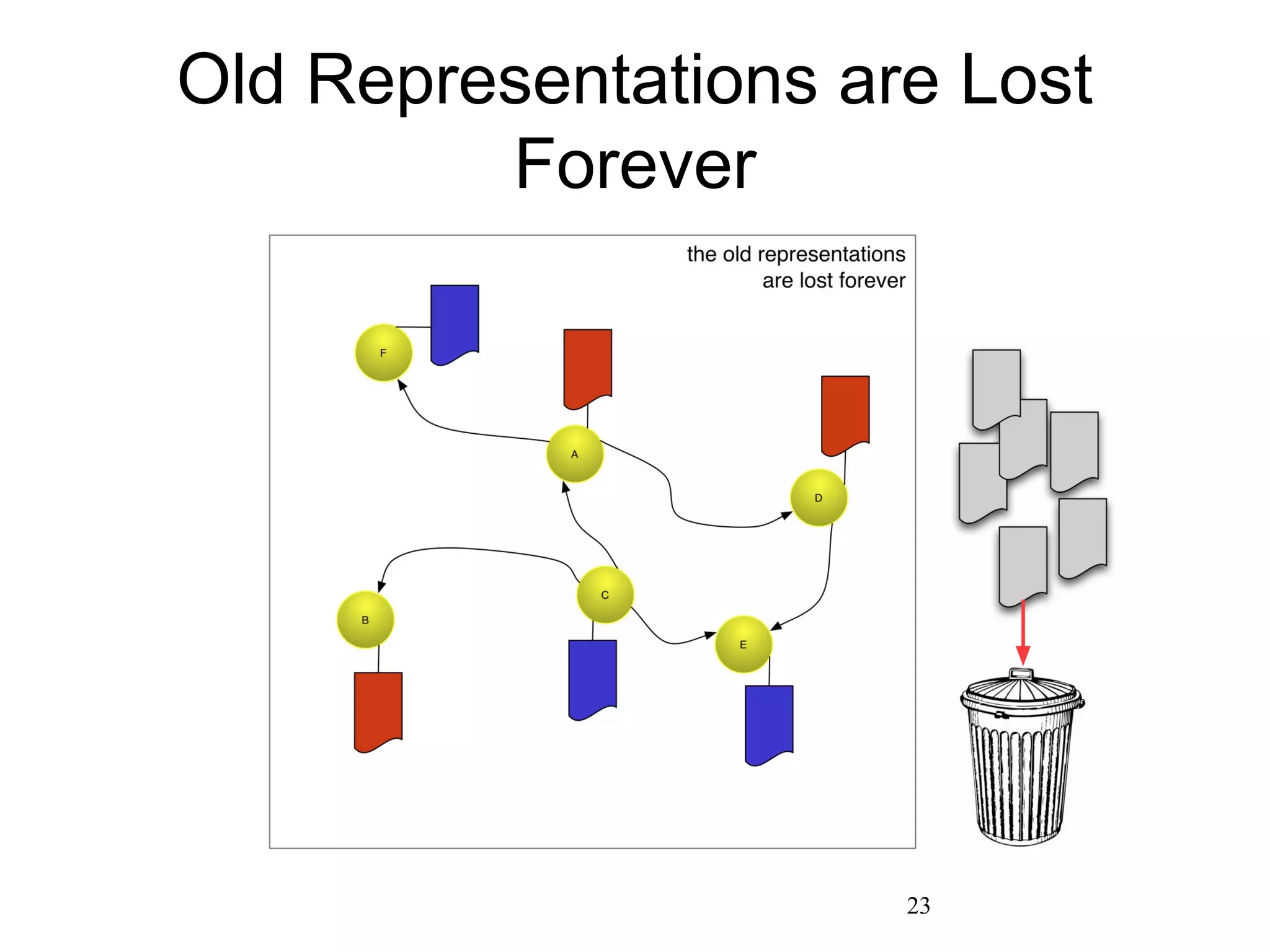
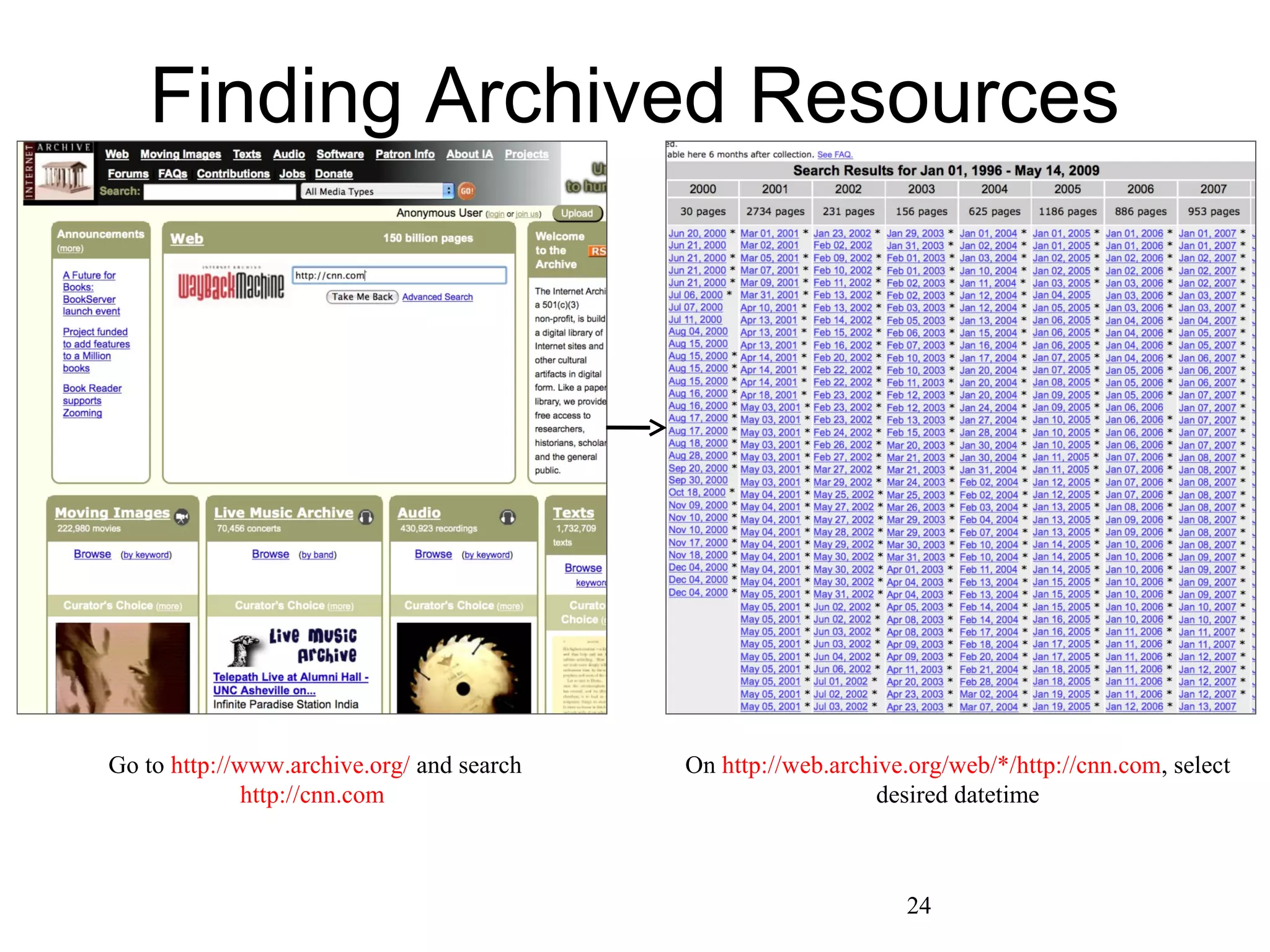
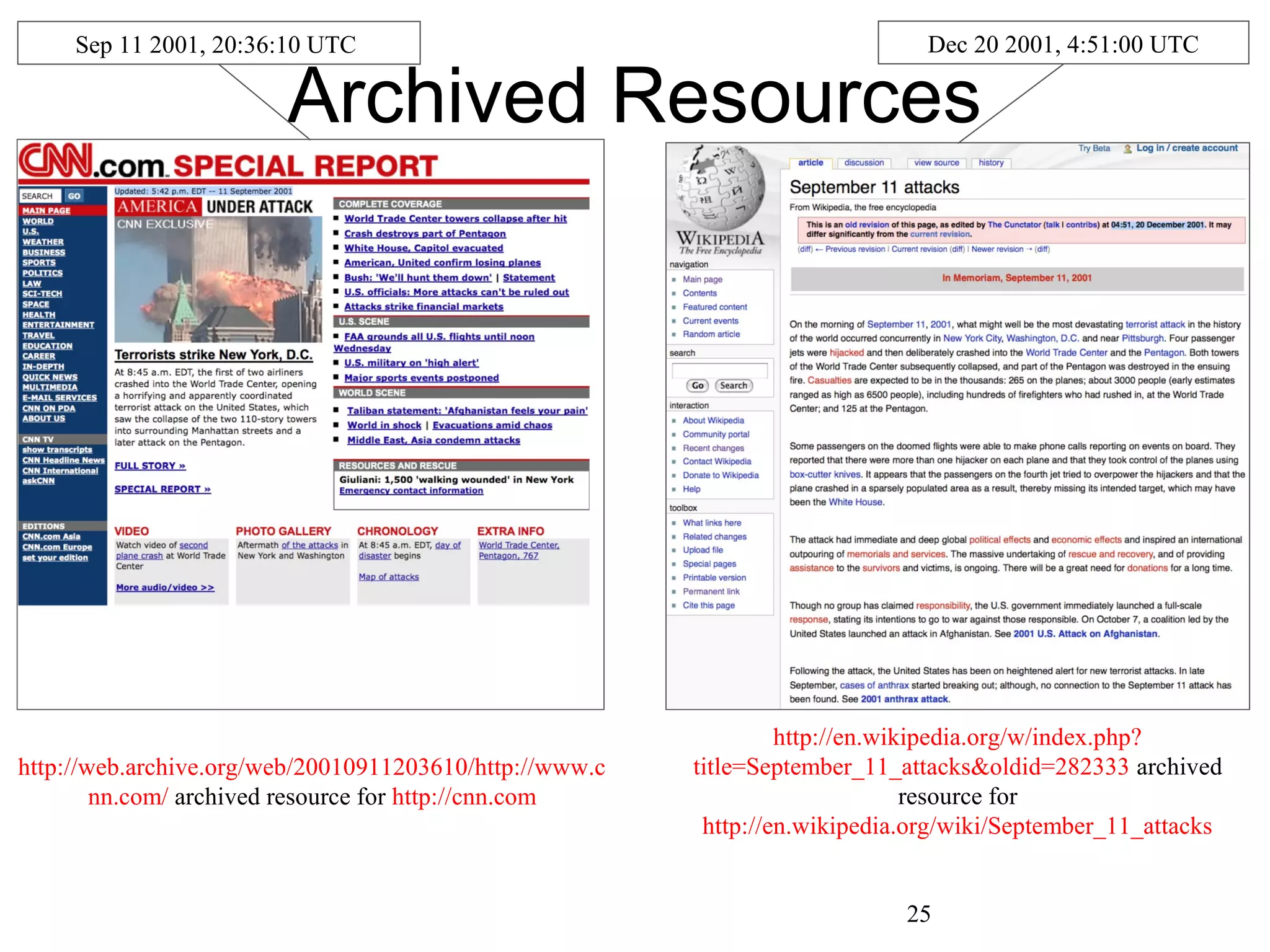

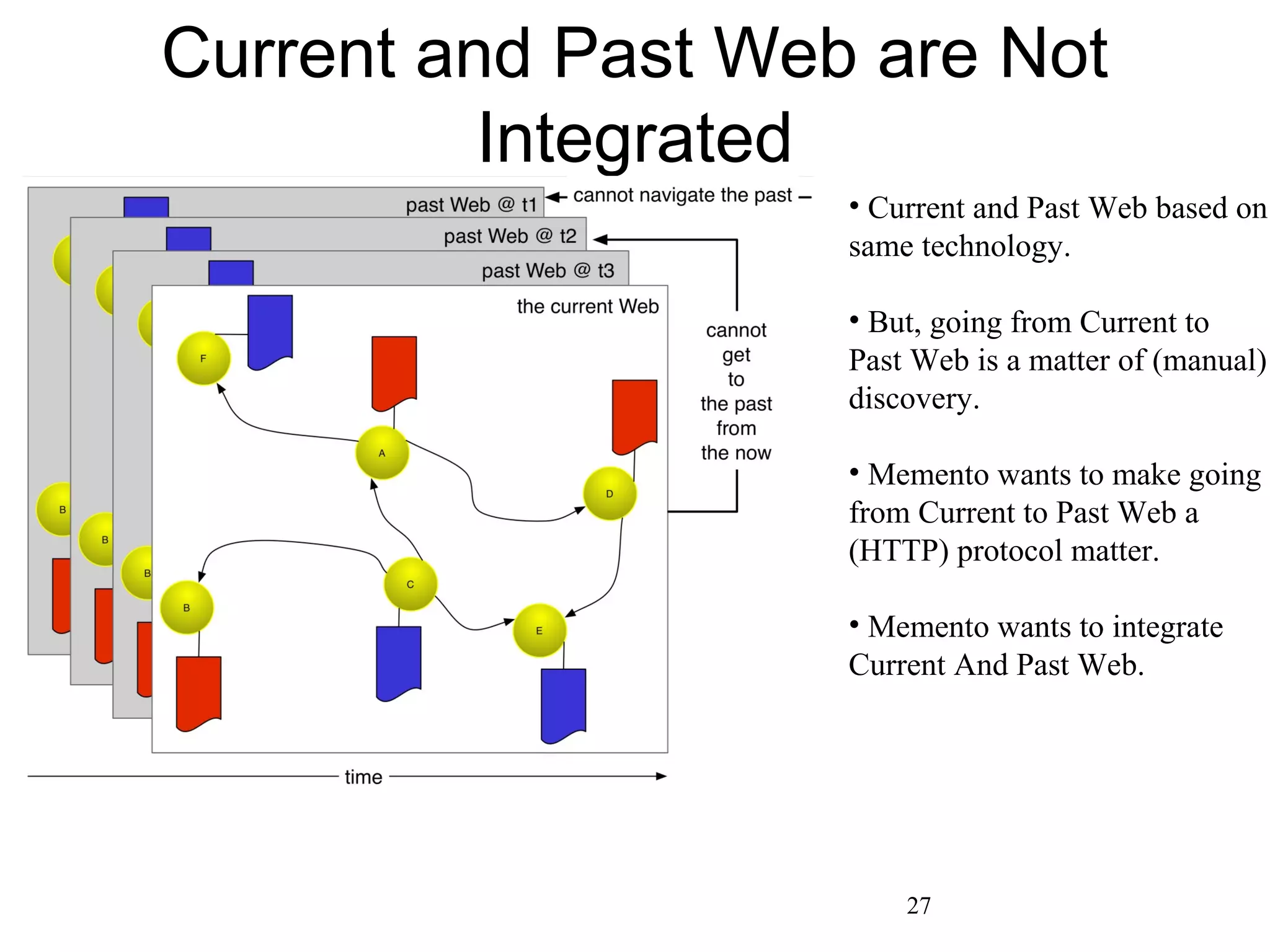

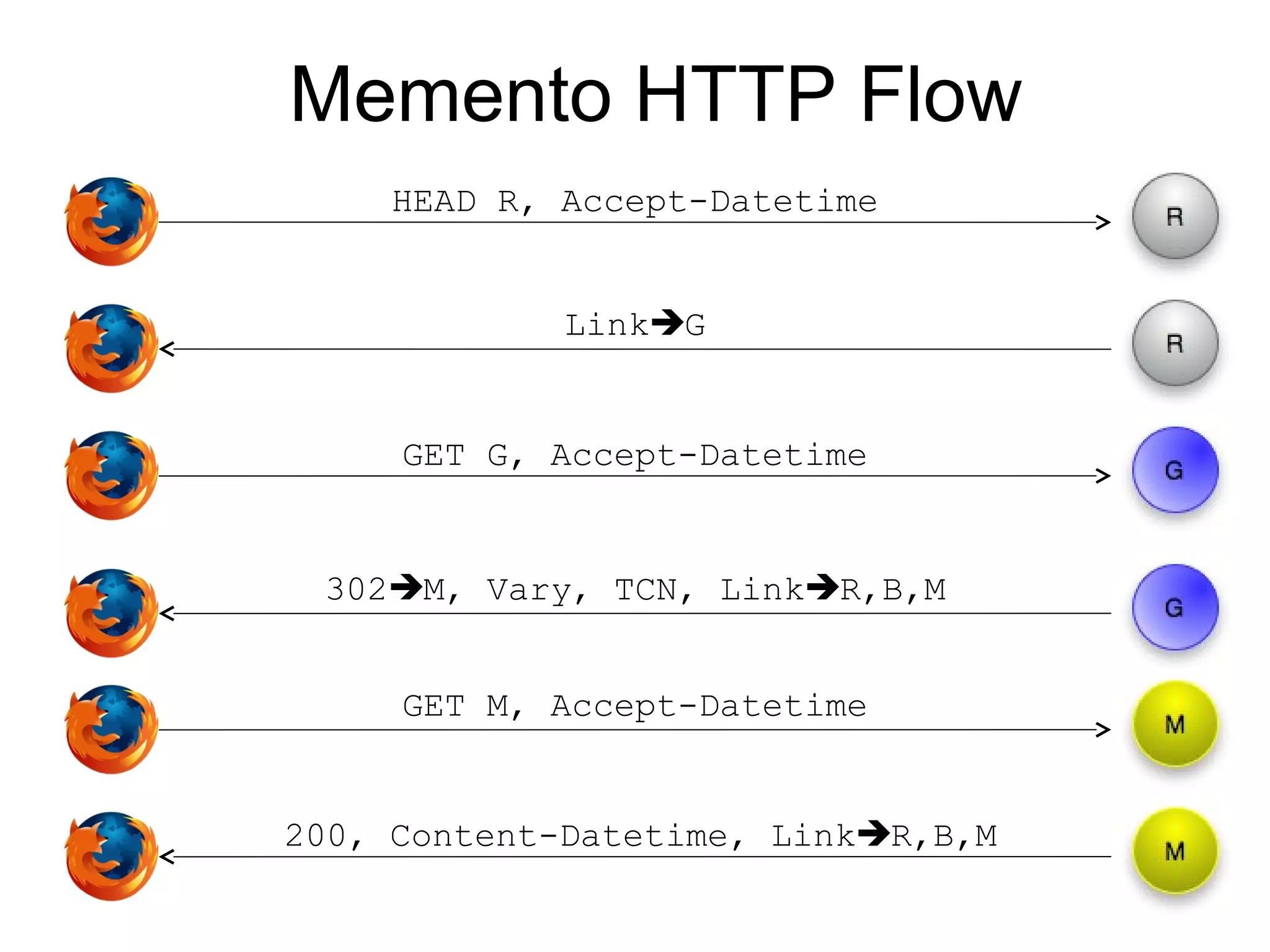

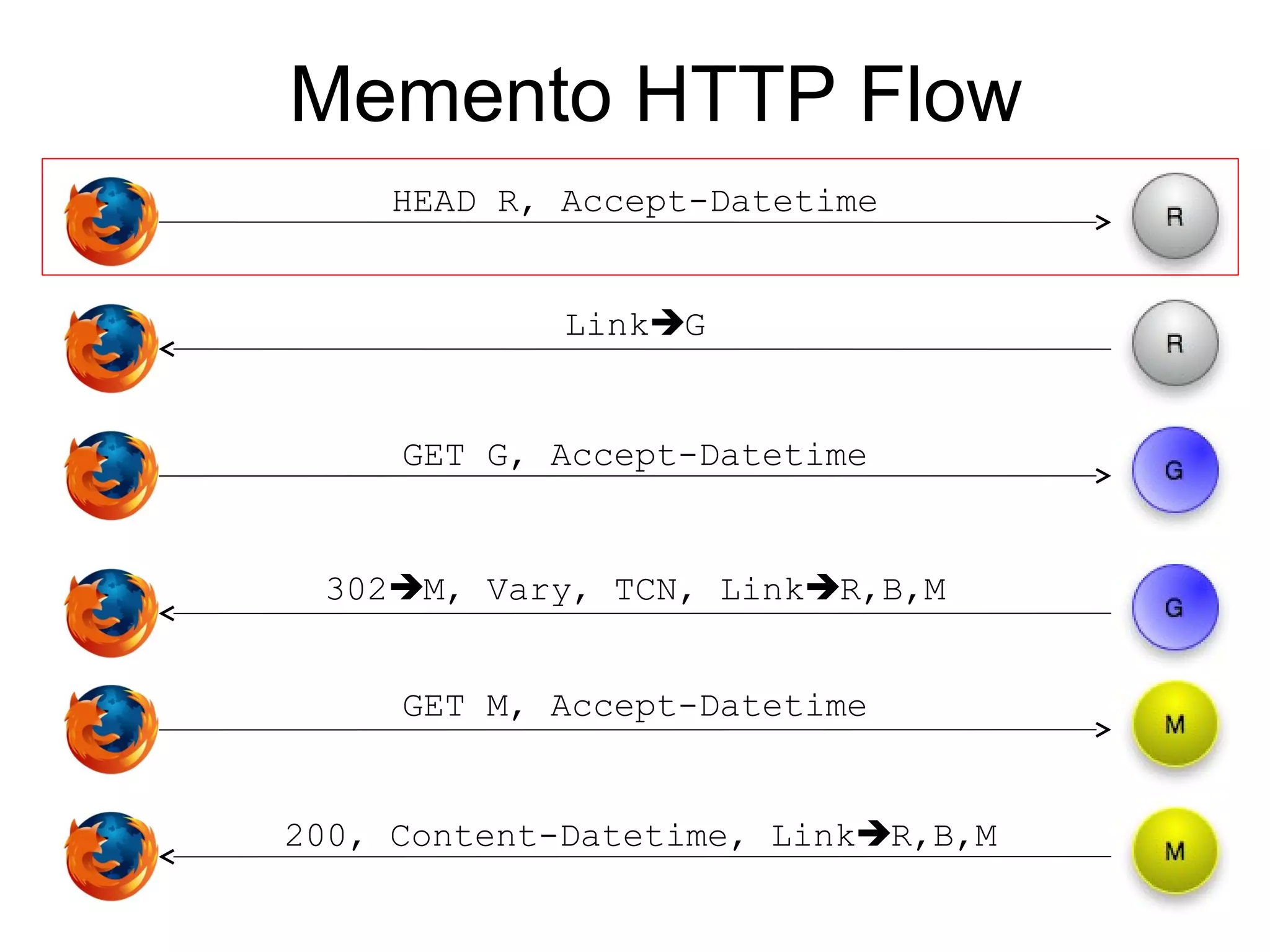
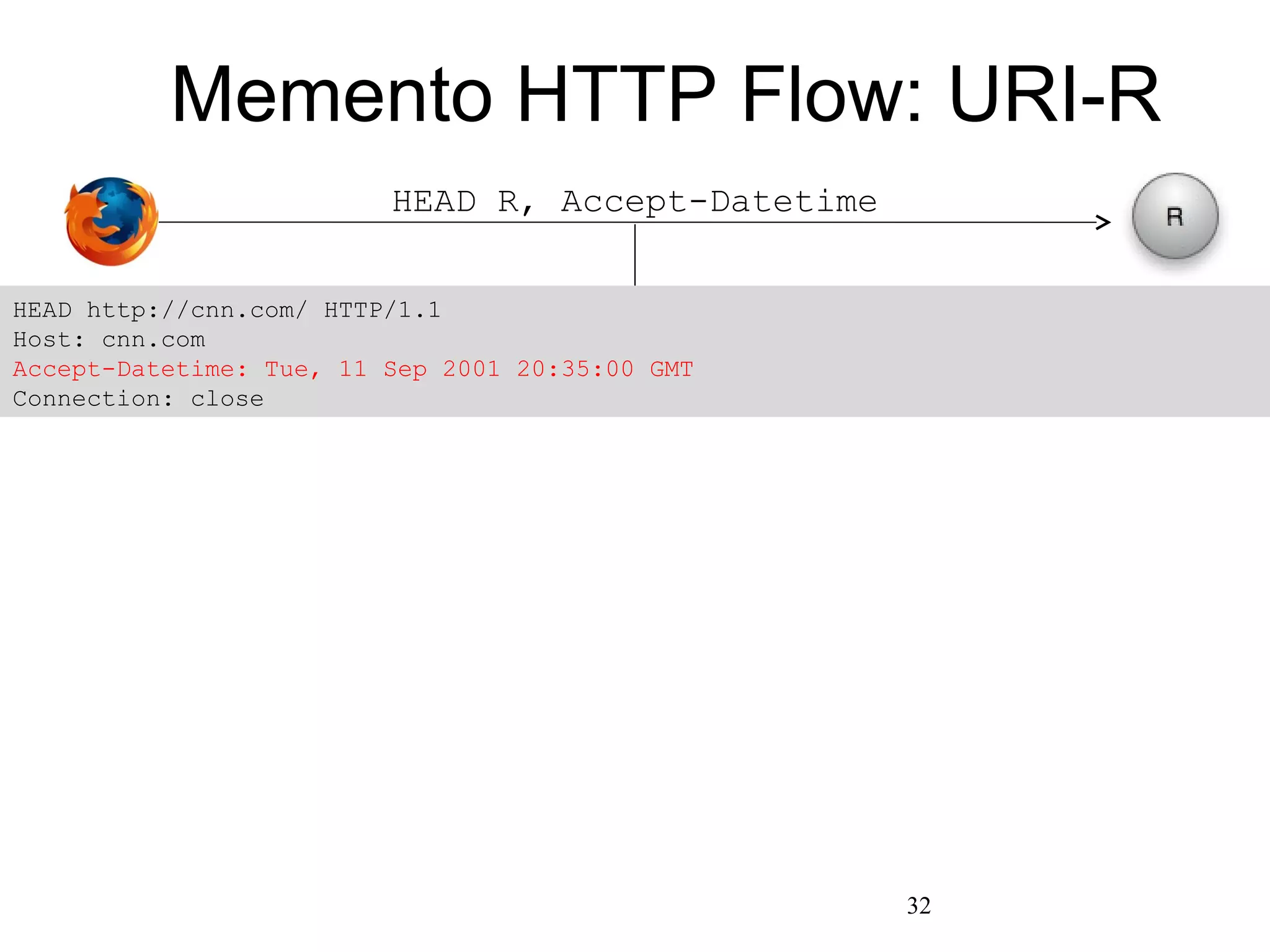
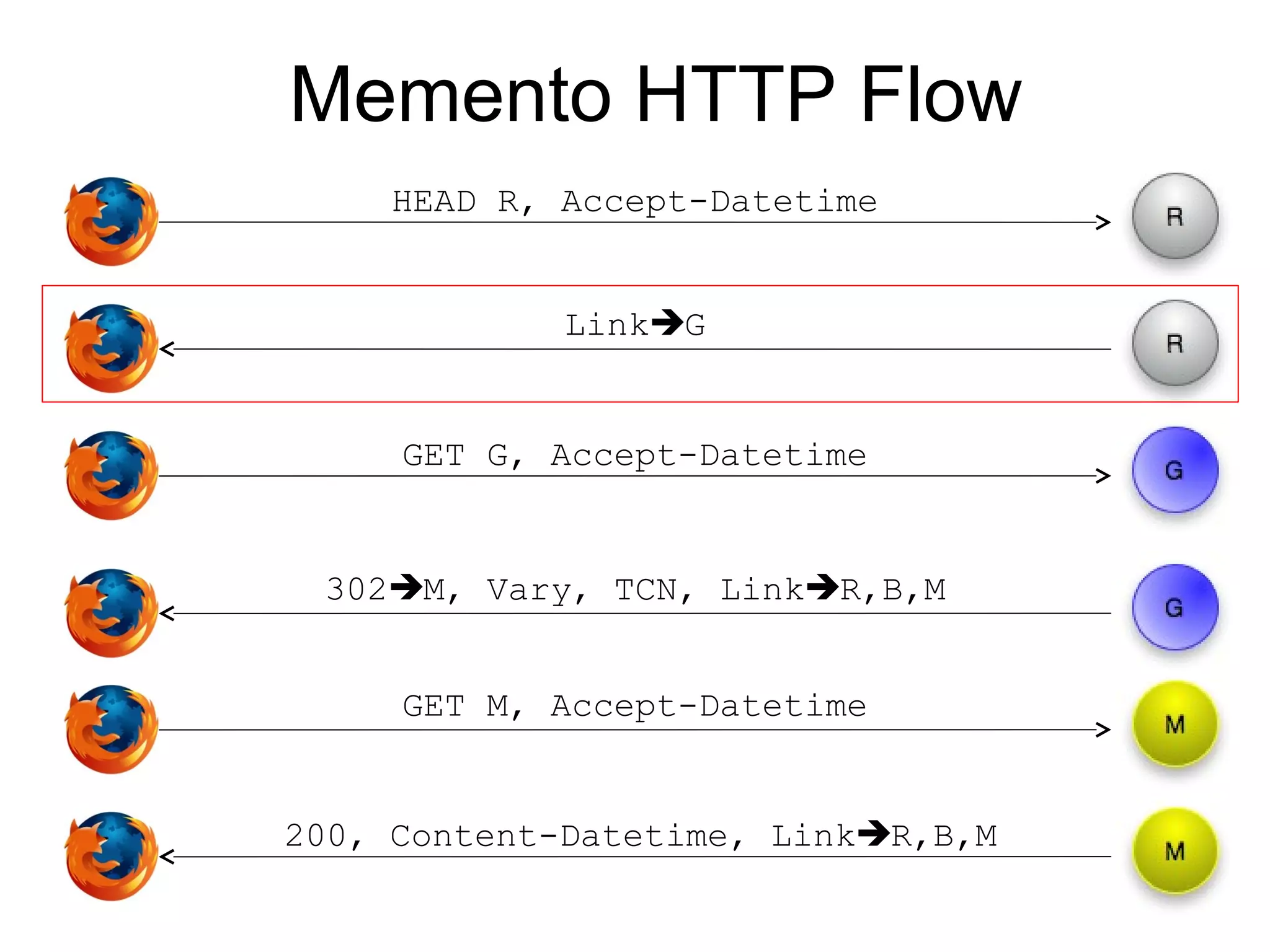



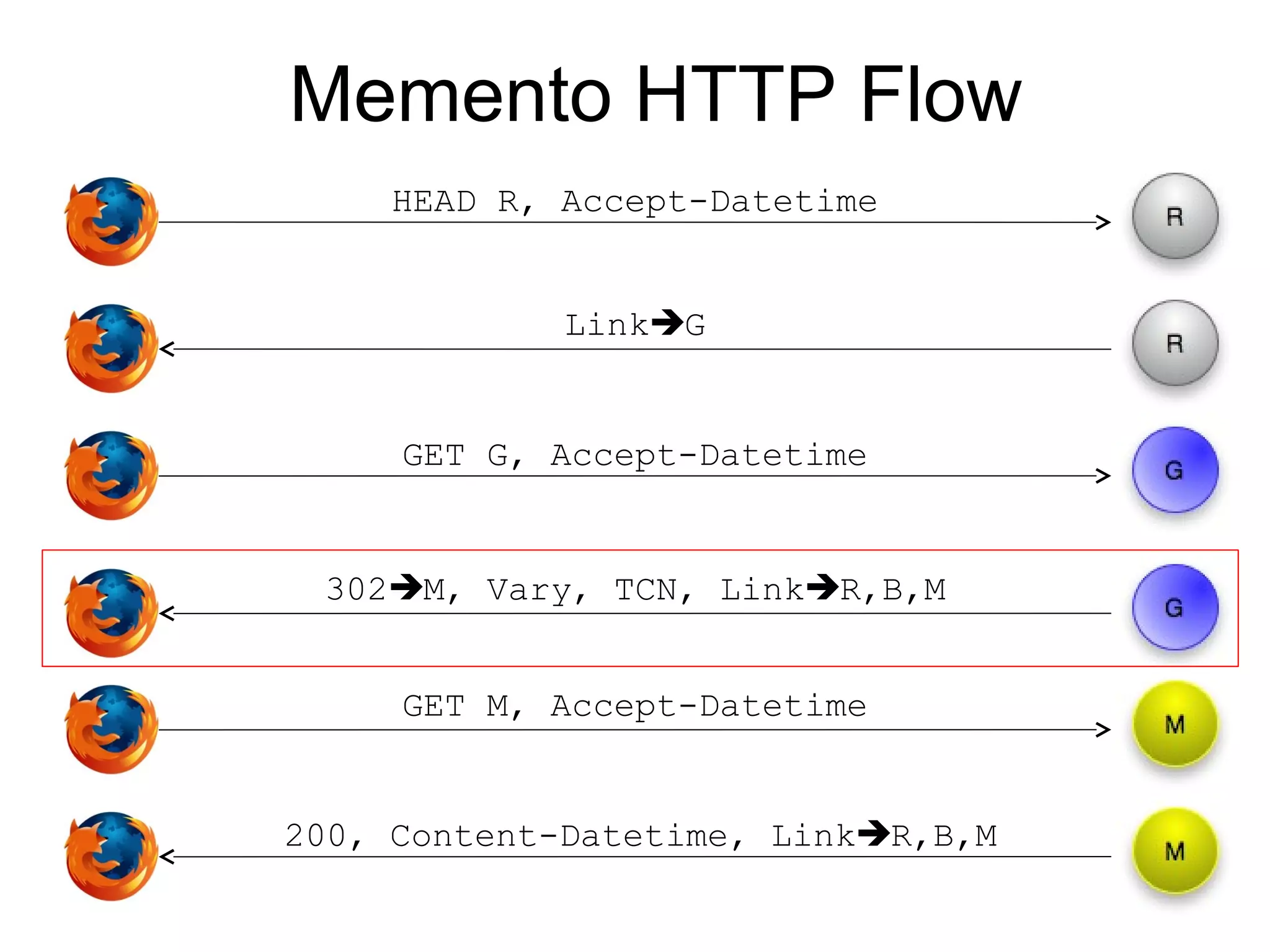
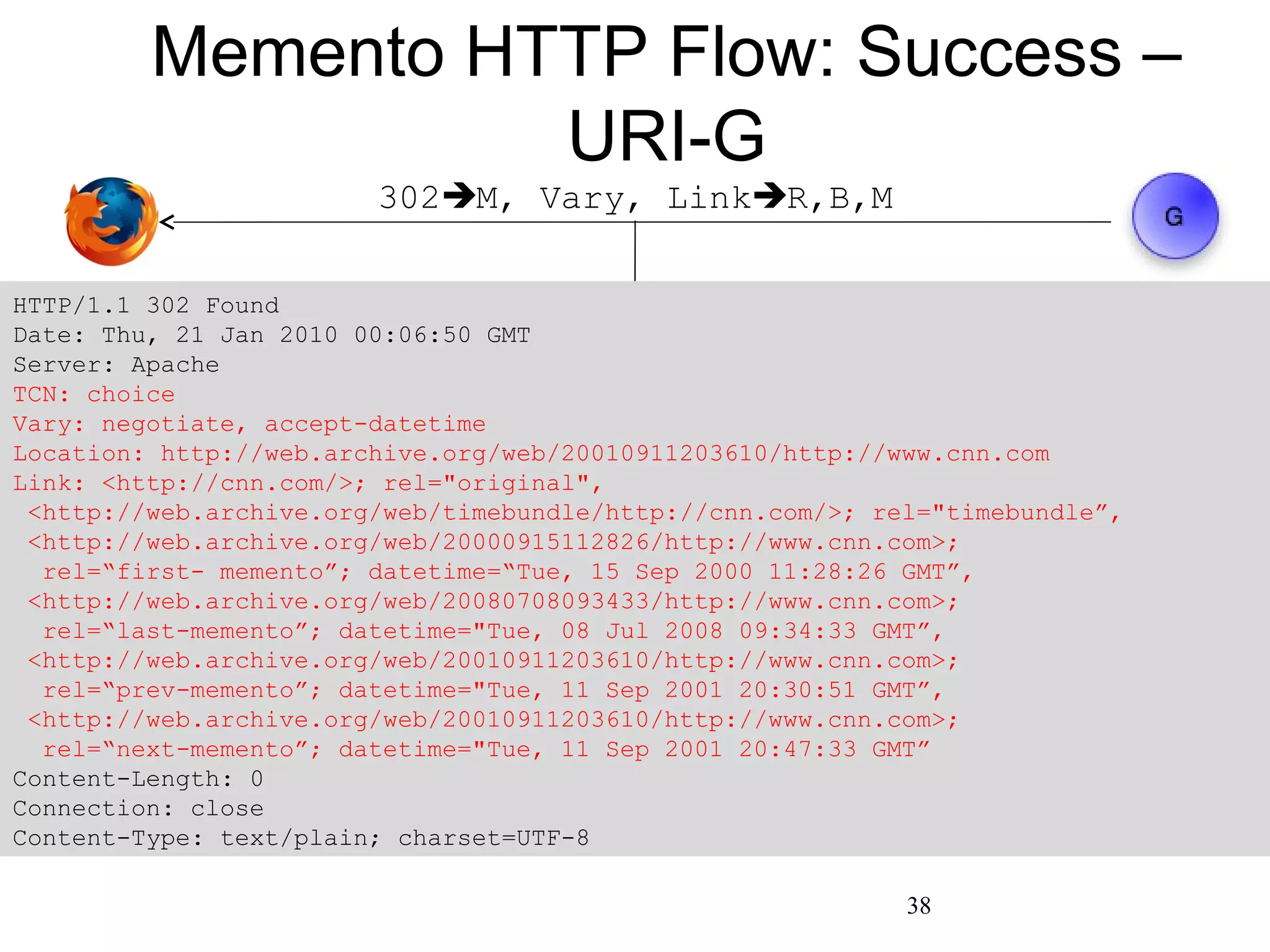
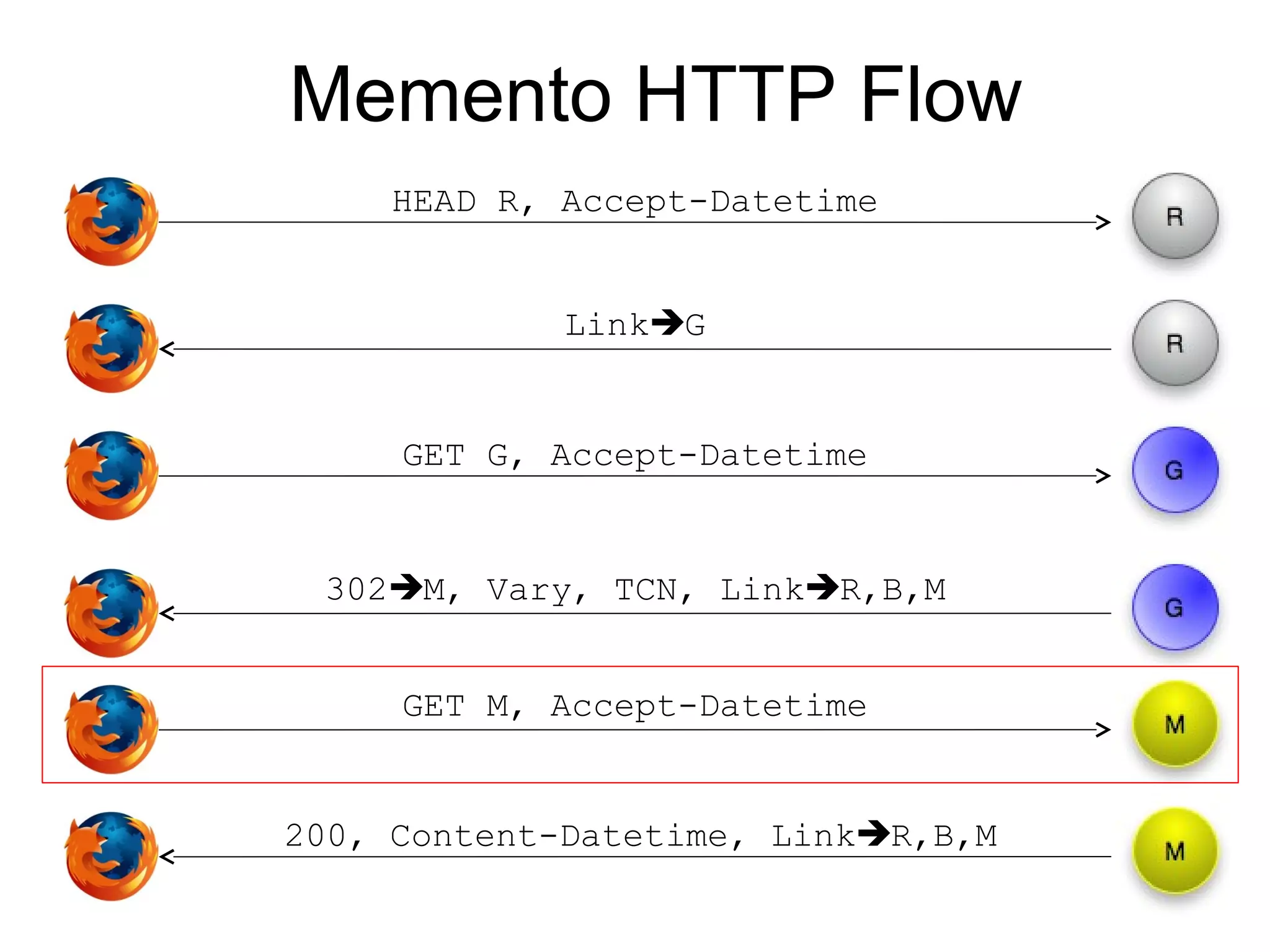
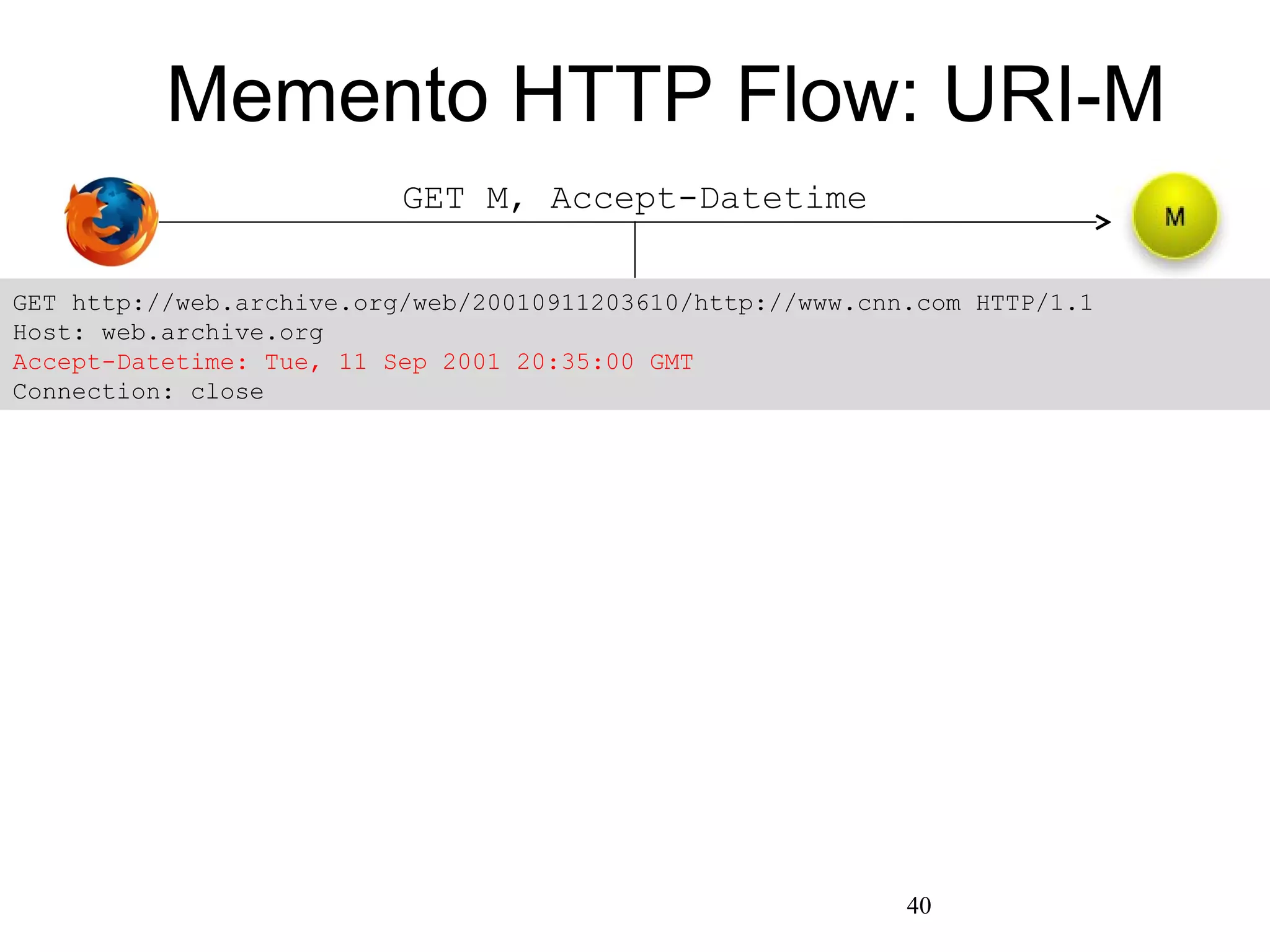
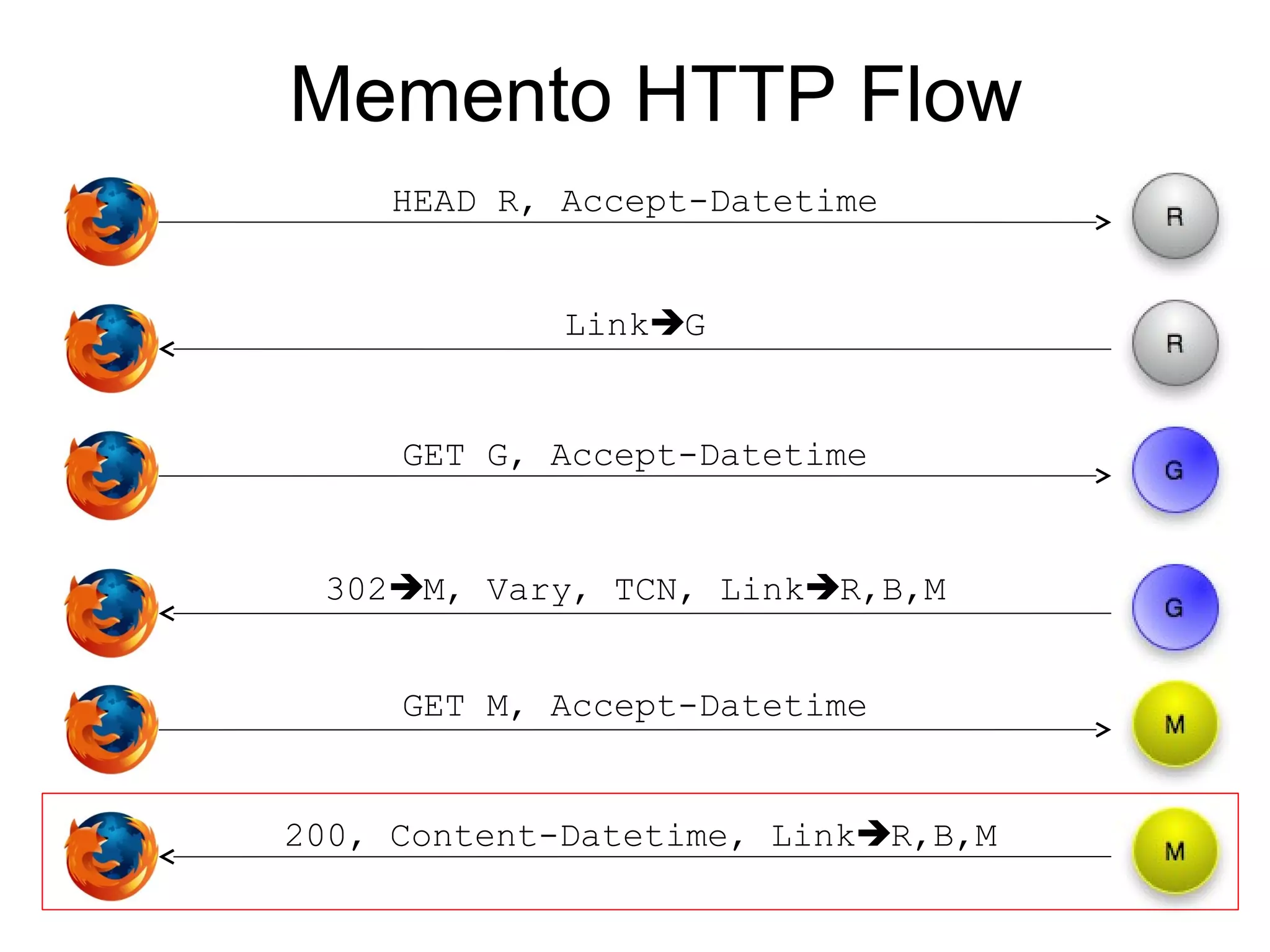
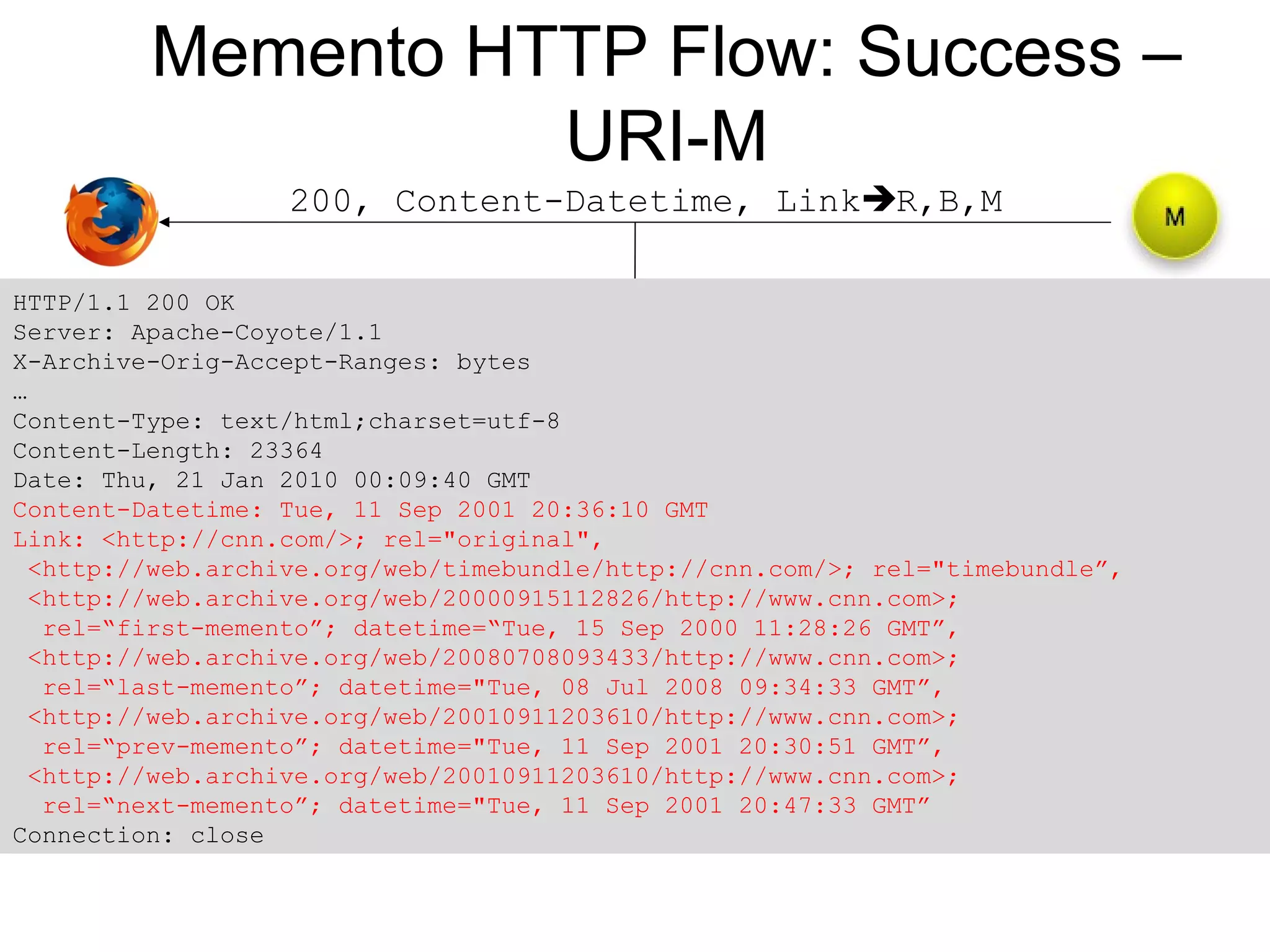




The document discusses digital preservation research at Old Dominion University, focusing on the challenges of preserving web content and the concept of 'temporal browsing.' It highlights the Memento project, which aims to integrate the current and past web, making it easier to navigate archived resources through a protocol-based system. Various preservation strategies are examined, such as lazy and just-in-time preservation, emphasizing the need for innovative approaches to maintain web content accessibility over time.







































