This document summarizes a presentation about improving web vulnerability scanning. It discusses:
1. Current web vulnerability scanners are based on HTTP libraries and don't support JavaScript-rich applications well. Authenticated scanning is also challenging.
2. The presenter proposes replacing the HTTP library with a Webkit engine to gain full support for JavaScript, AJAX, redirects, and other modern web features. This would reduce code complexity.
3. Scaling the number of sites scanned requires distributing the workload across multiple processes to leverage multiprocessing. Handling authentication also requires strategies to identify login forms and confirm login status.





![Software Architecture
What web vulnerability scanners and fuzzers look like 6
Plugins
A HTTP Library
RXSS BSQLI EVAL
The Core
PXSS LFI OSC
Multithreading /
Output Engine
Forking
SQL RFI [...]](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-6-2048.jpg)

![A developers point of view 8
■ HTTP Libraries don’t support JS -
■ Javascript/Ajax rich applications are still not Scanners are based on an HTTP
supported Libraries
■ Authenticated scanning is still incredibly ■ Web Logins are not standarized -
challenging / not reliable So how should they be detected
■ Exploitation techniques are mostly poor ■ No time for exploits
(Already spent 100000 lines [and nights] of code
making the crawler immune to encoding issues,
■ “I don’t know which scanner will work for malformed HTML, redirects and binary content!)
foo.com and which one for bar.com, so I
use toolchains”
■ A false positive is better than a
false negative](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-8-2048.jpg)



![Webkit knows 13
■ Javascript ■ CSS Rendering
■ Javascript events ■ Binary Downloads
■ Redirects ■ Broken HTML
■ Flash ■ Broken CSS
■ Images ■ Performance
■ Websockets ■ Forking / Multiprocessing
■ WebGL ■ [...]](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-13-2048.jpg)
![Software Architecture
What it should look like 14
The Front-End
A HTTP RXSS BSQLI EVAL
The Core
Library
PXSS LFI OSC
Reporting Engine SQL RFI [...]
The Exploitation Engine](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-14-2048.jpg)
![Changes? Improvments? 15
■ Replacing the HTTP library by a Webkit Engine
■ Less code (A lot less code)
■ 100% support for JS/Ajax/Broken HTML/JS Events/Crazy Redirects
and all kinds of things
■ The ability to simulate human user behaviour
■ CSS Renderings (Two text fields beside each other: 10px - one of
them is a input[type=password]) - May be a login!](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-15-2048.jpg)





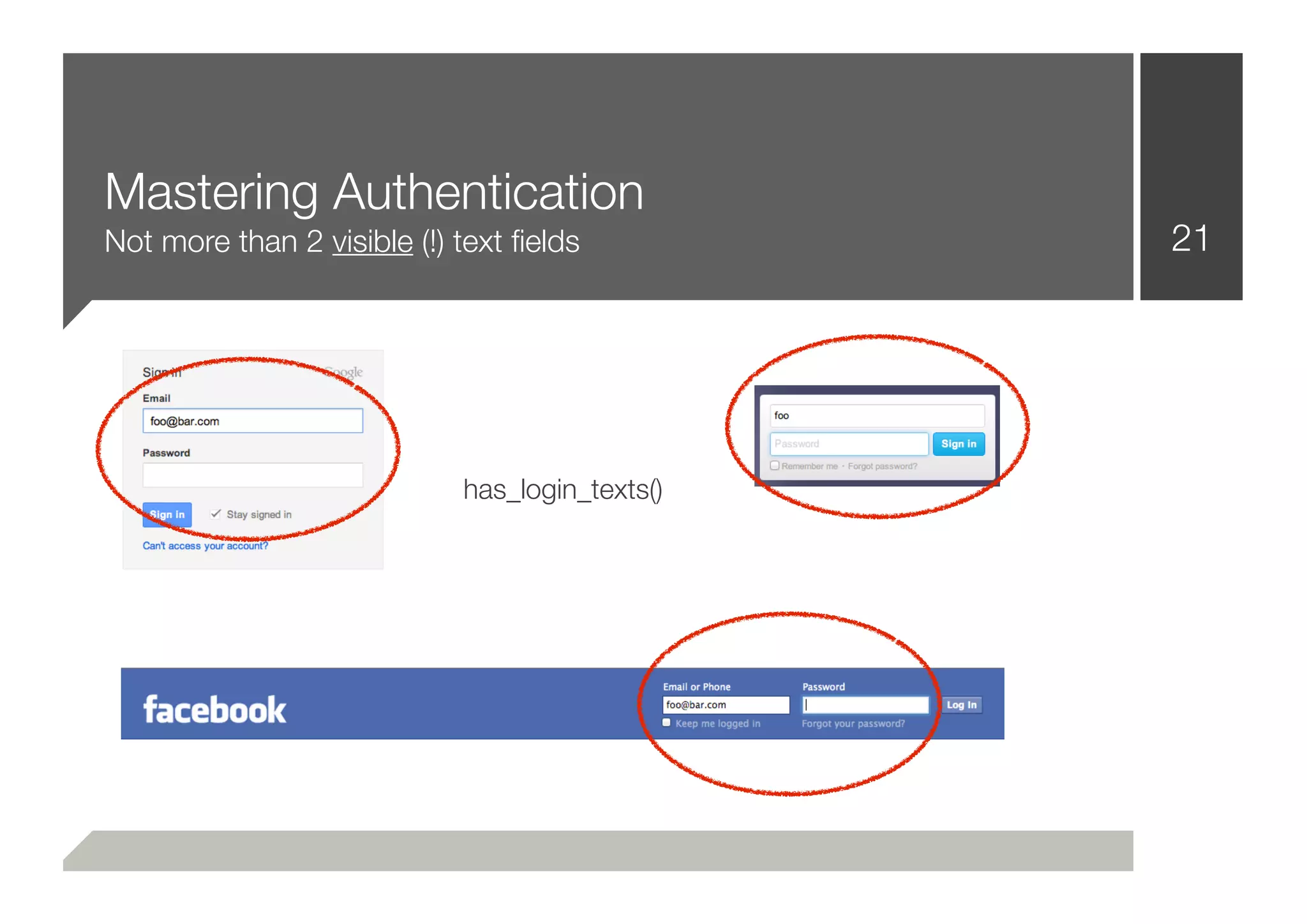
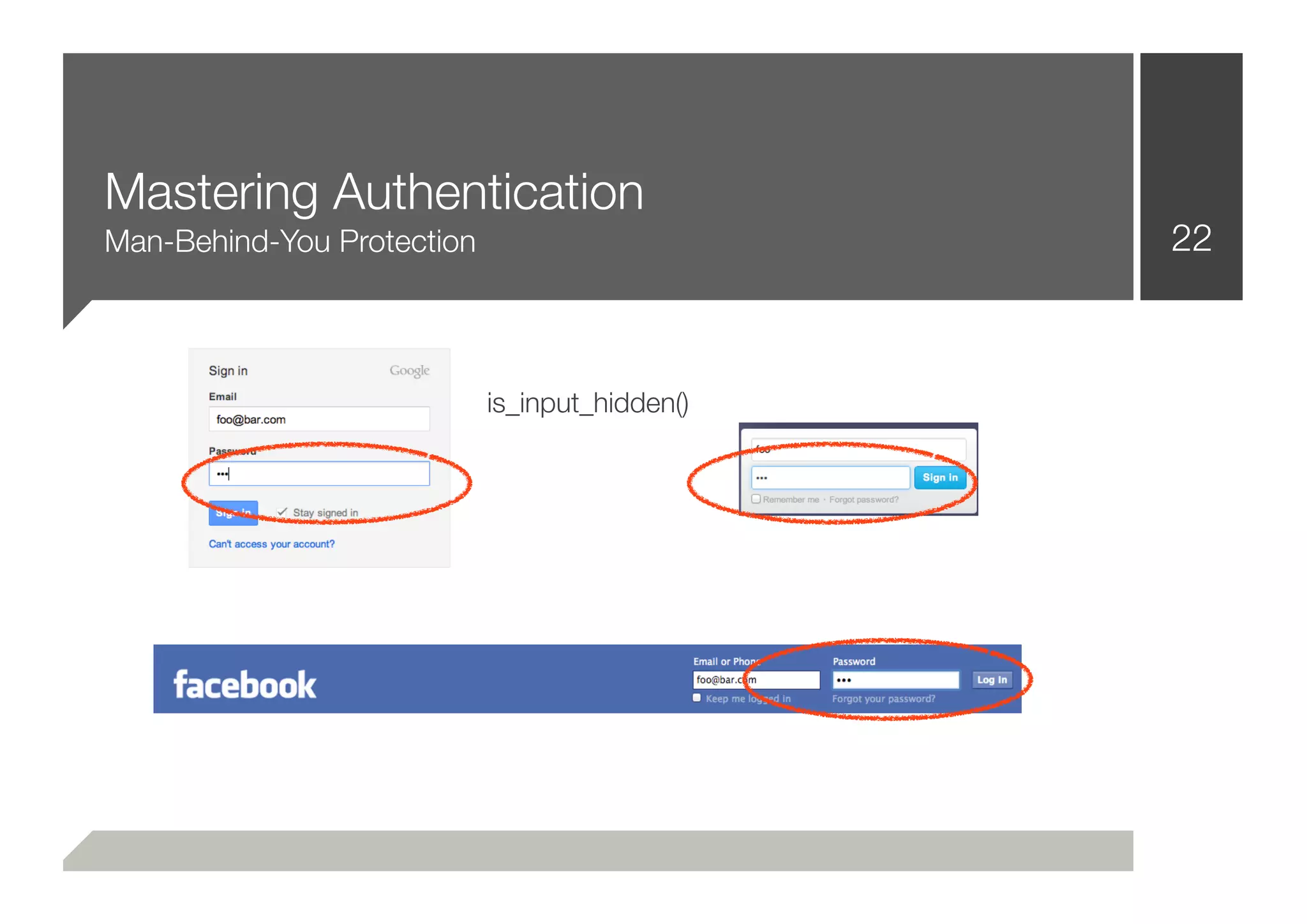
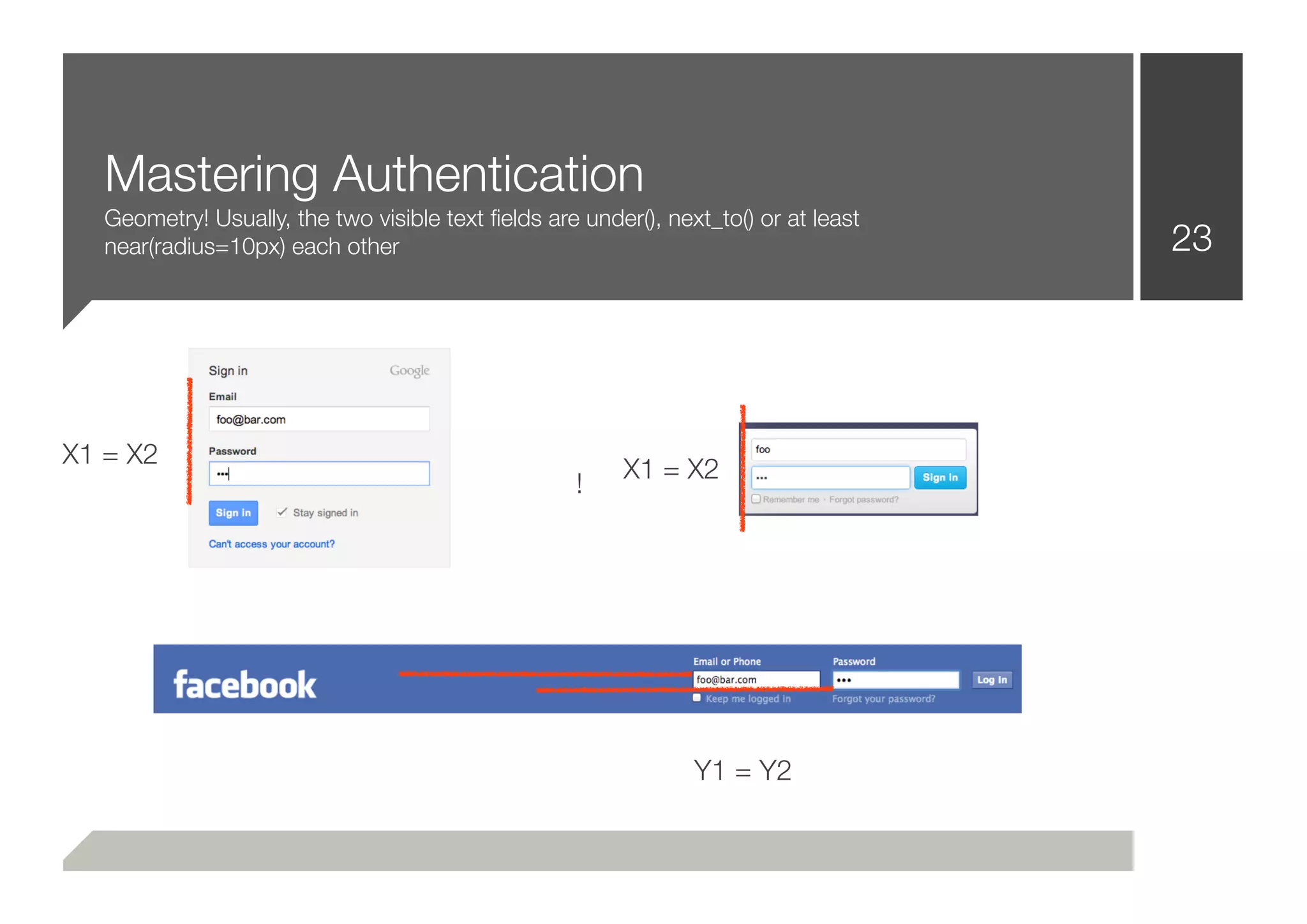
![Mastering Authentication 24
■ That was easy!
■ The common way to solve that problem, is to iterate through a
wordlist (login, auth, signin, [...]) while checking the input[id],
input[name] attributes
■ That’s not necessarily wrong or bad practice
■ After putting the pieces together:
■ .login(“username”, “password”)](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-24-2048.jpg)


![Strategy.Authentication
Step 1: Identification 27
■ Identifying a login form (3-way approach, input[type=password],
geometry, [...])](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-27-2048.jpg)
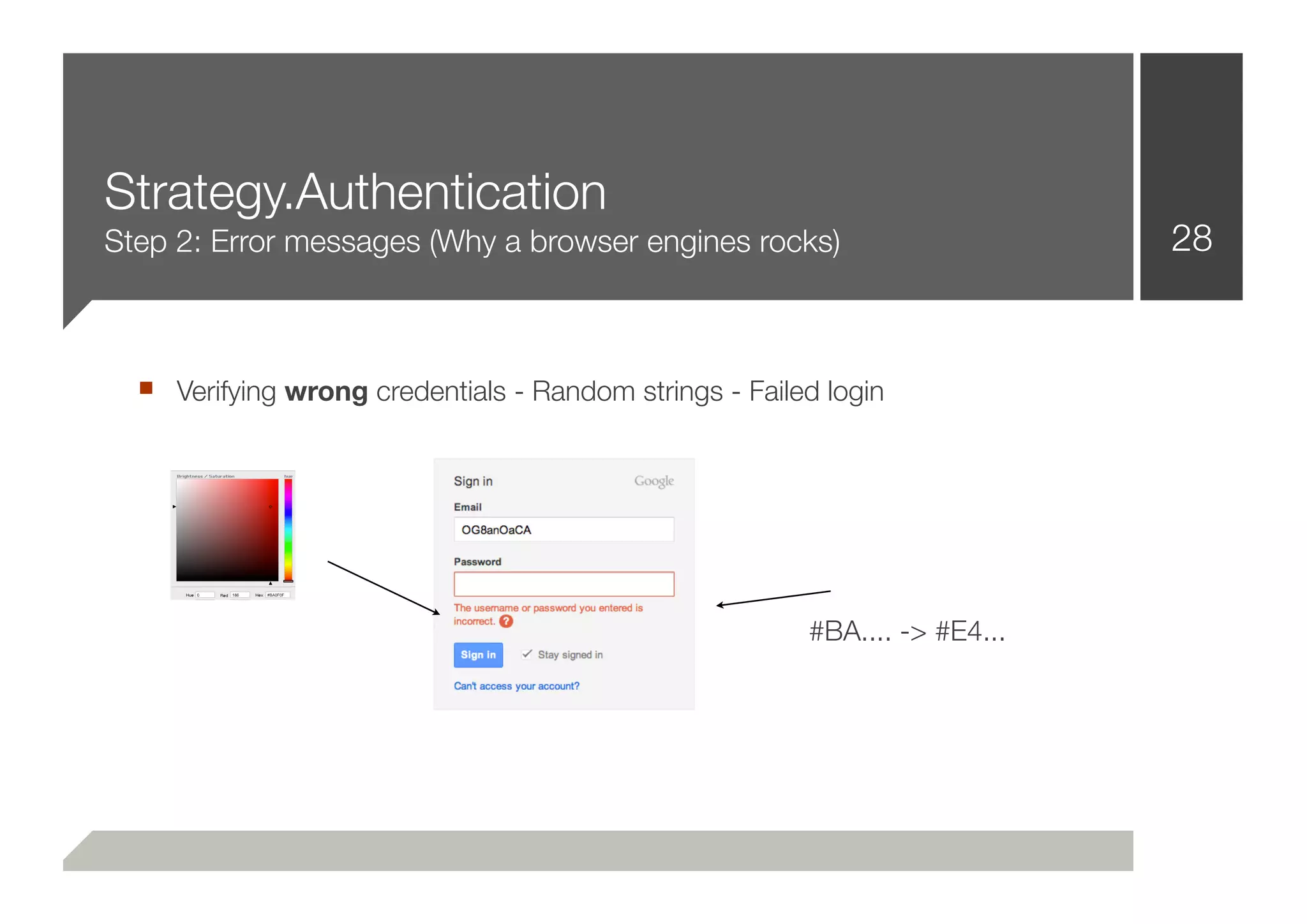
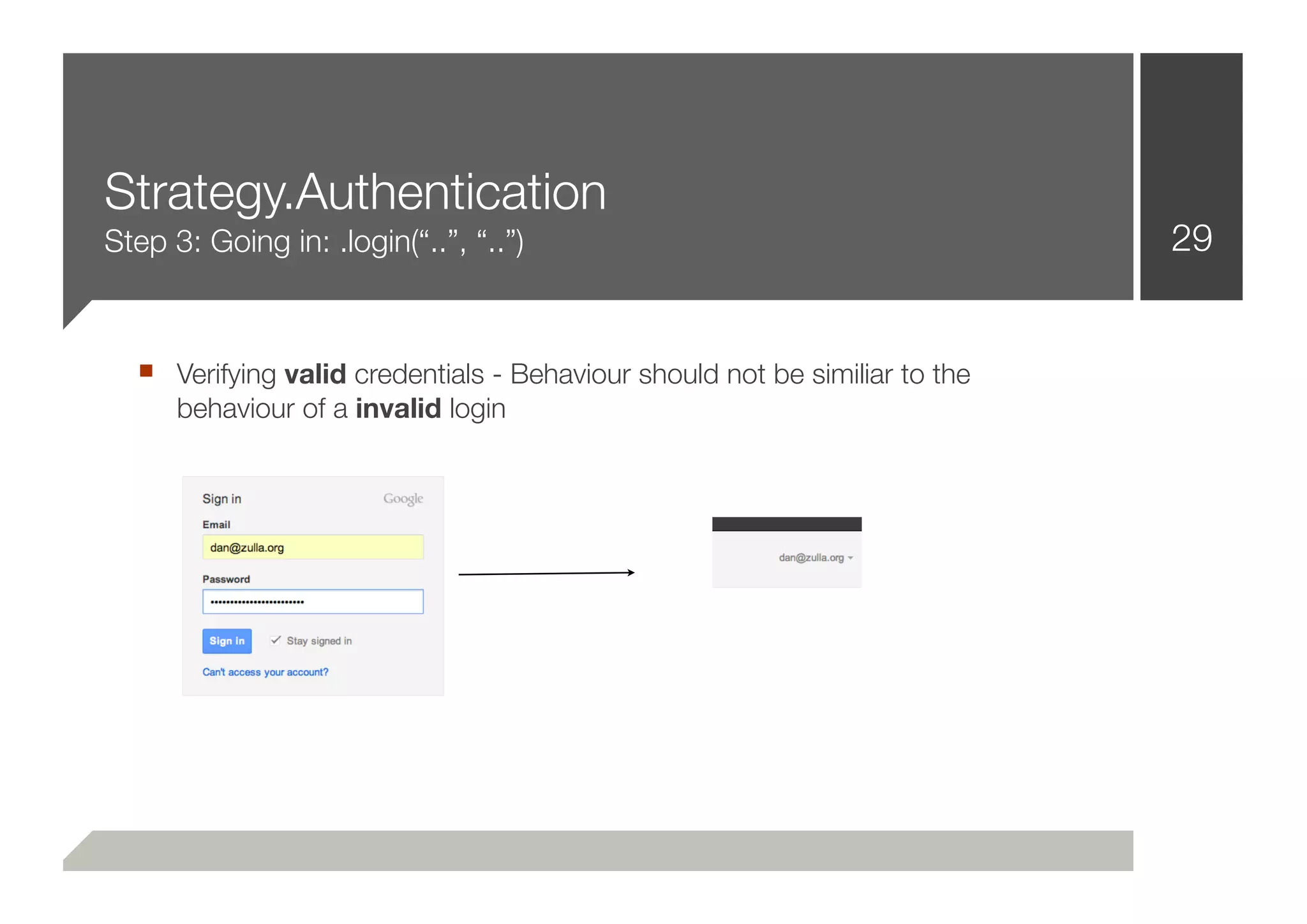







![More Live Demos 37
■ Demonstrating a logical layer beyond Authentication:
.pay(“0000111122223333”, CVV=121, type=VISA)
.search(“search query”)
.sort(“DESC UNION SELECT [...]”)
■ Interpreting error messages
■ Pivoting on penetrated hosts - Spawning another scanner instance
■ And finally: Reporting!](https://image.slidesharecdn.com/defcon-20-zulla-improving-web-vulnerability-scanning-120825045409-phpapp02/75/Defcon-20-zulla-improving-web-vulnerability-scanning-37-2048.jpg)















































![[2.1] Web application Security Trends - Omar Ganiev](https://cdn.slidesharecdn.com/ss_thumbnails/2-150301070554-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

























