Download to read offline



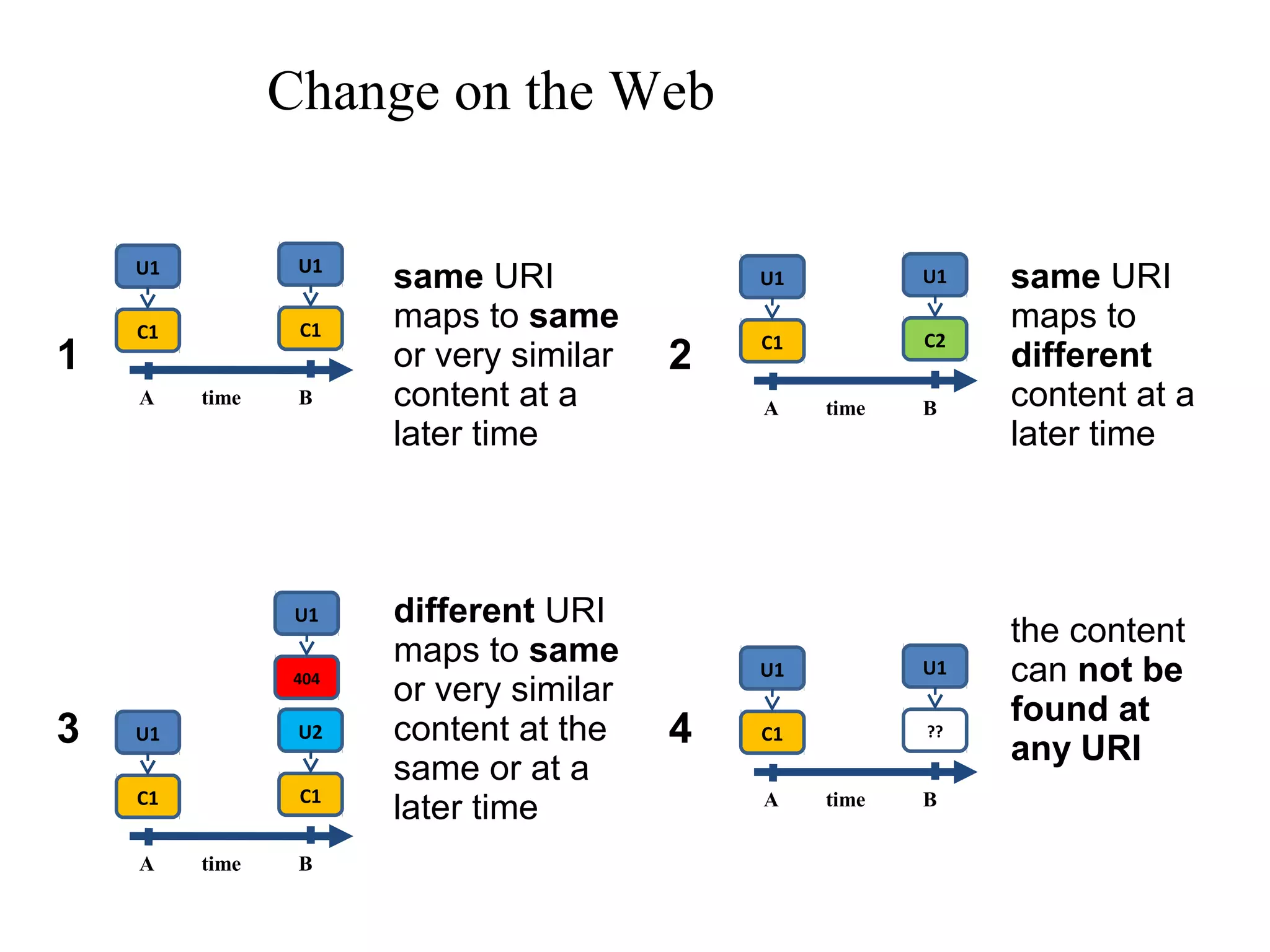






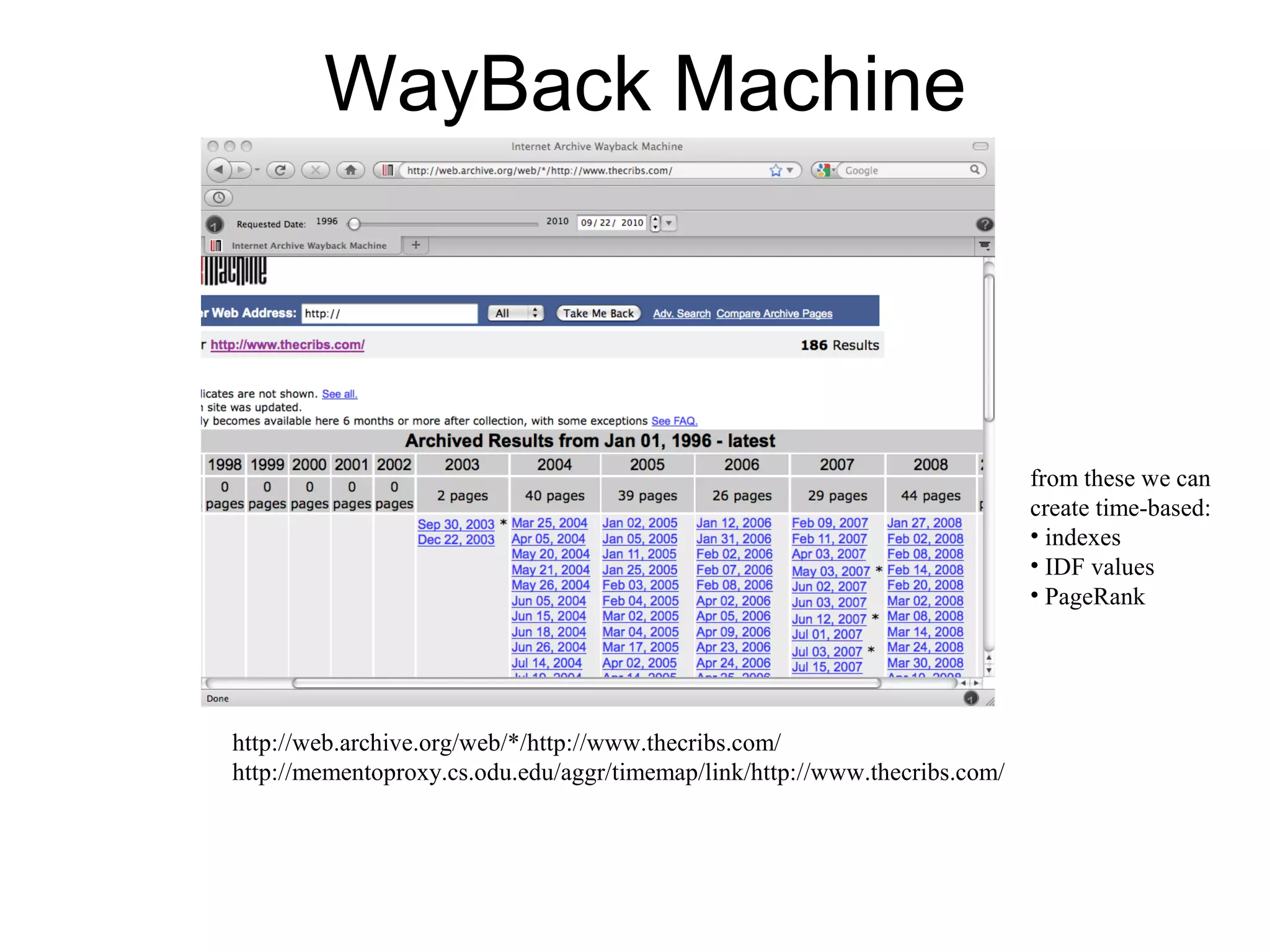
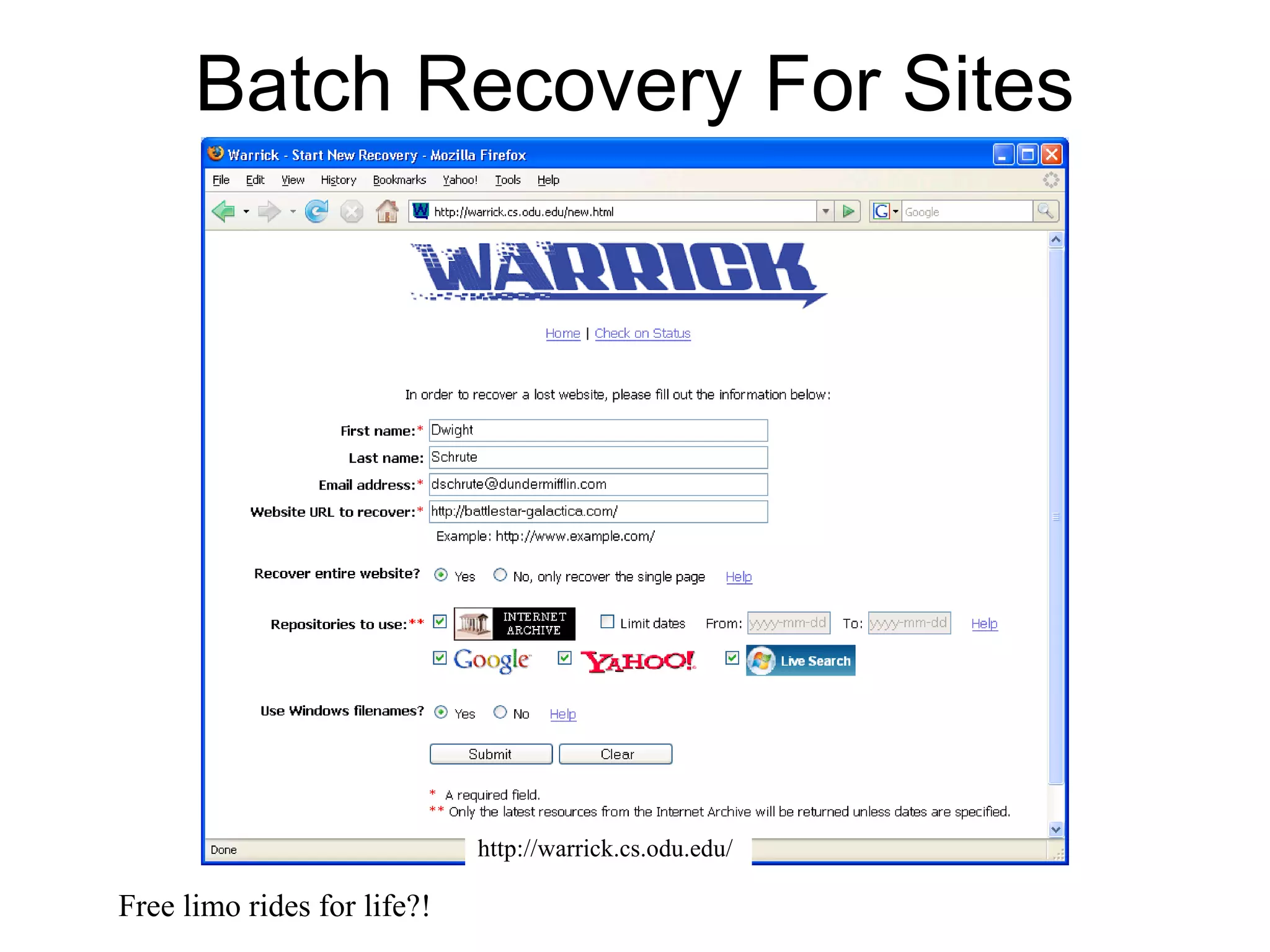
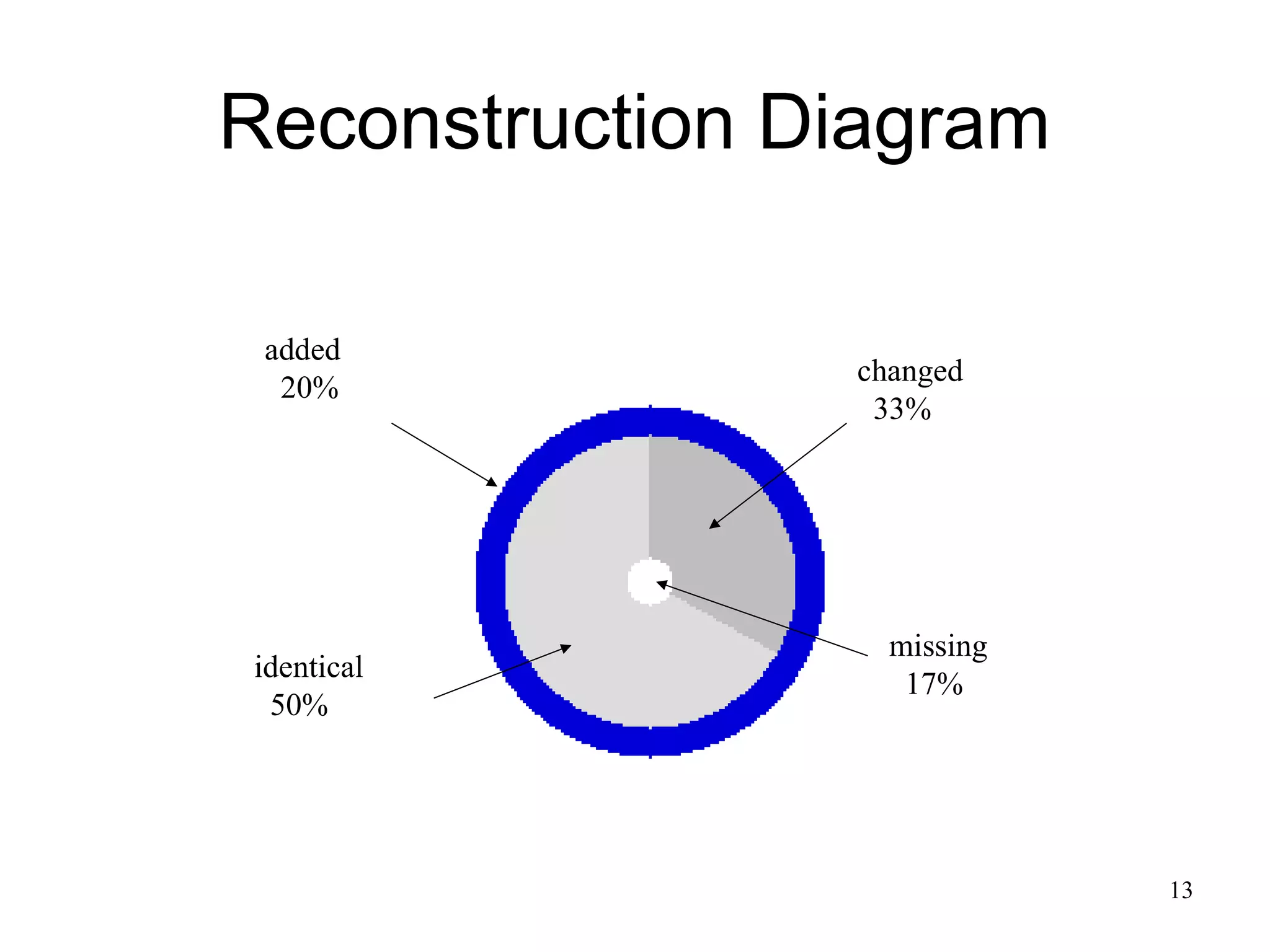
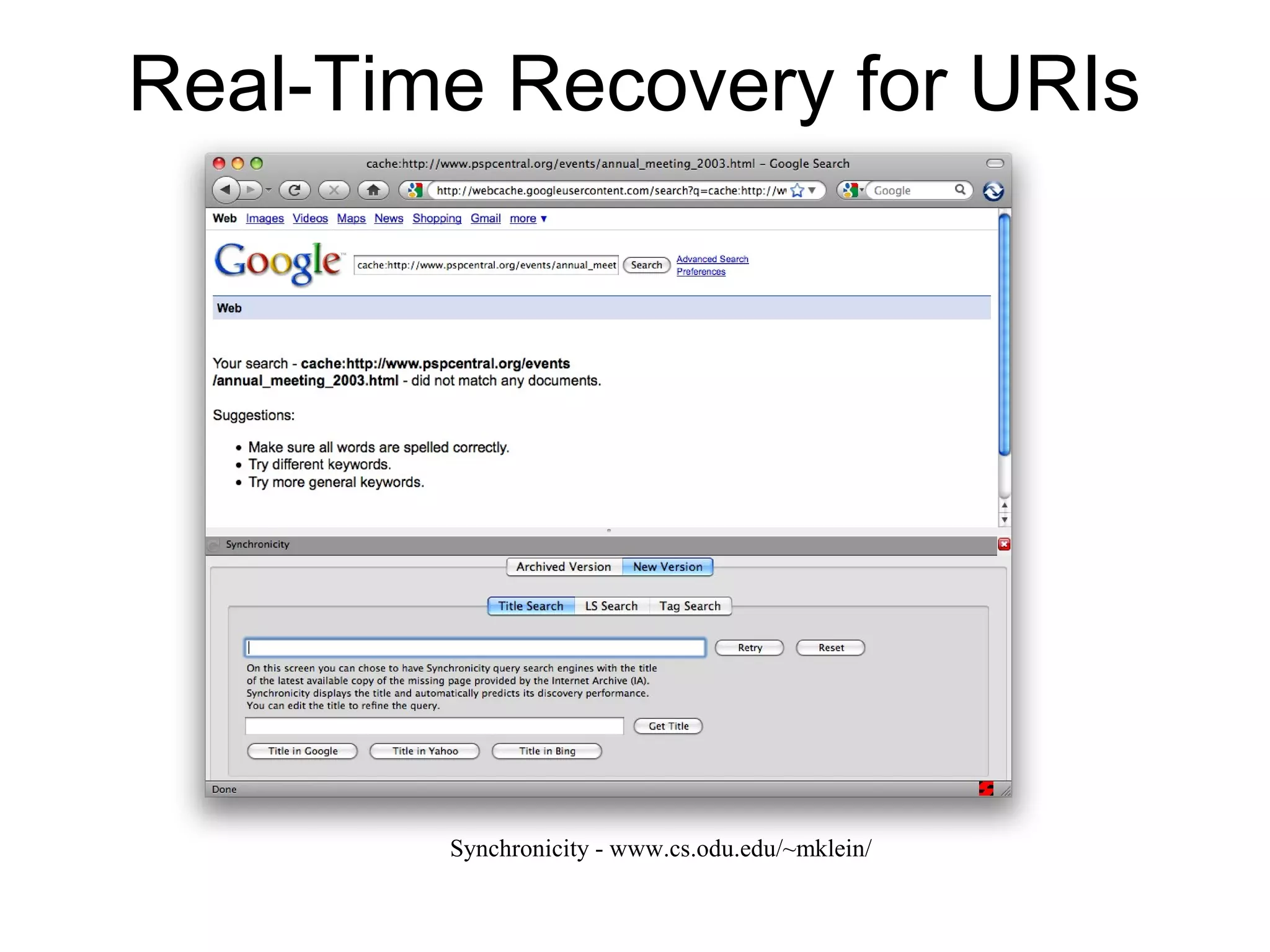


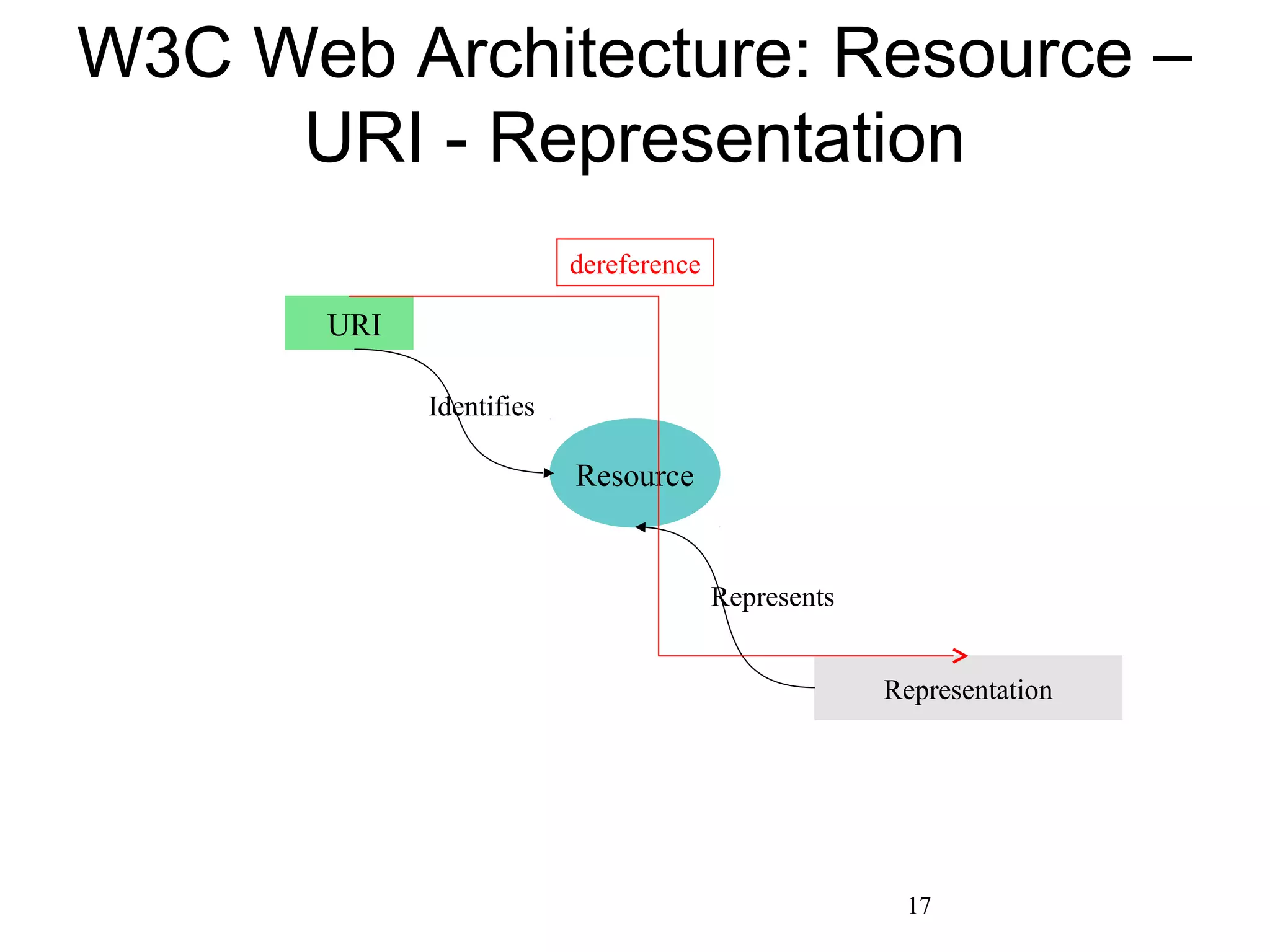
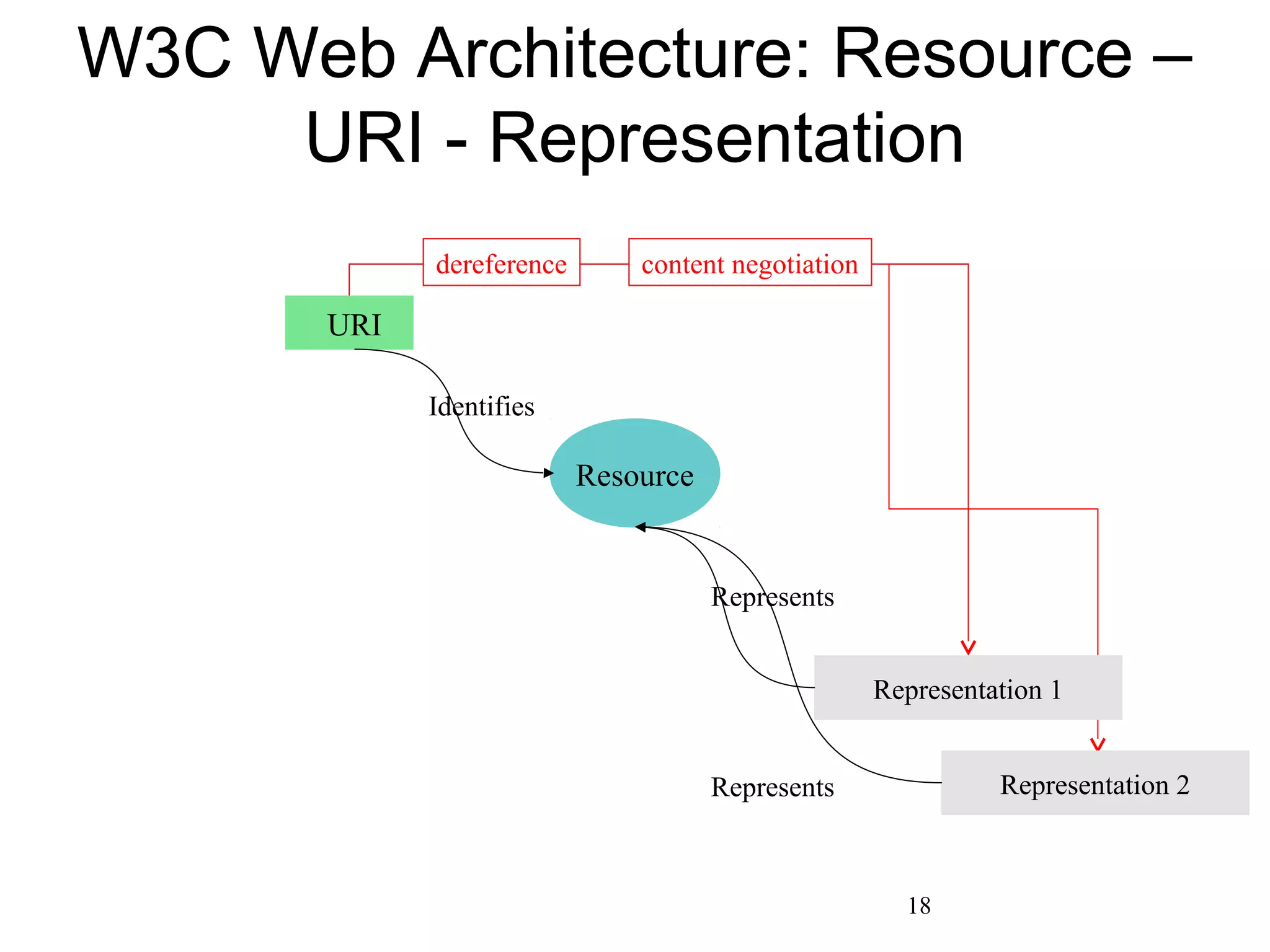

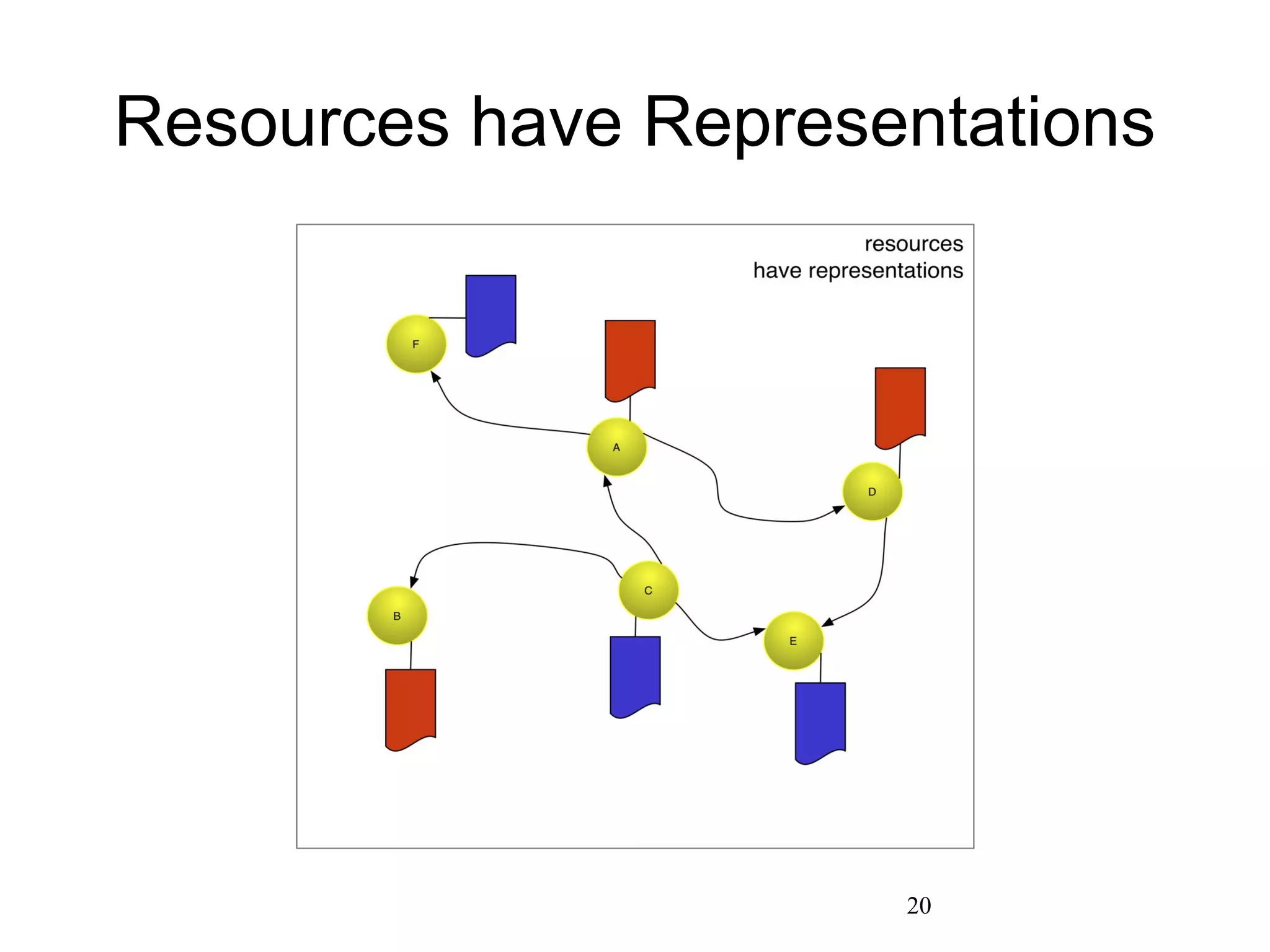
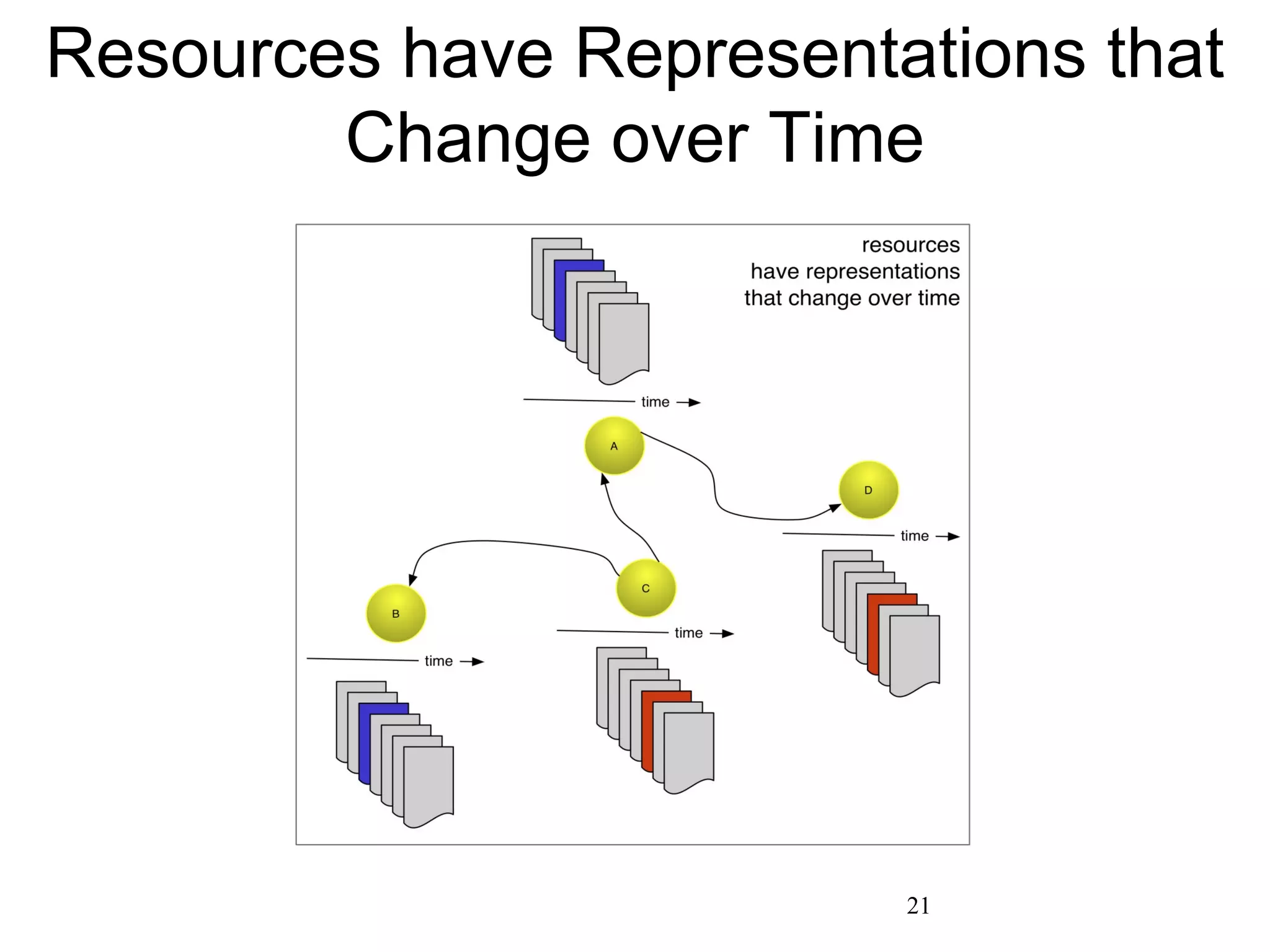

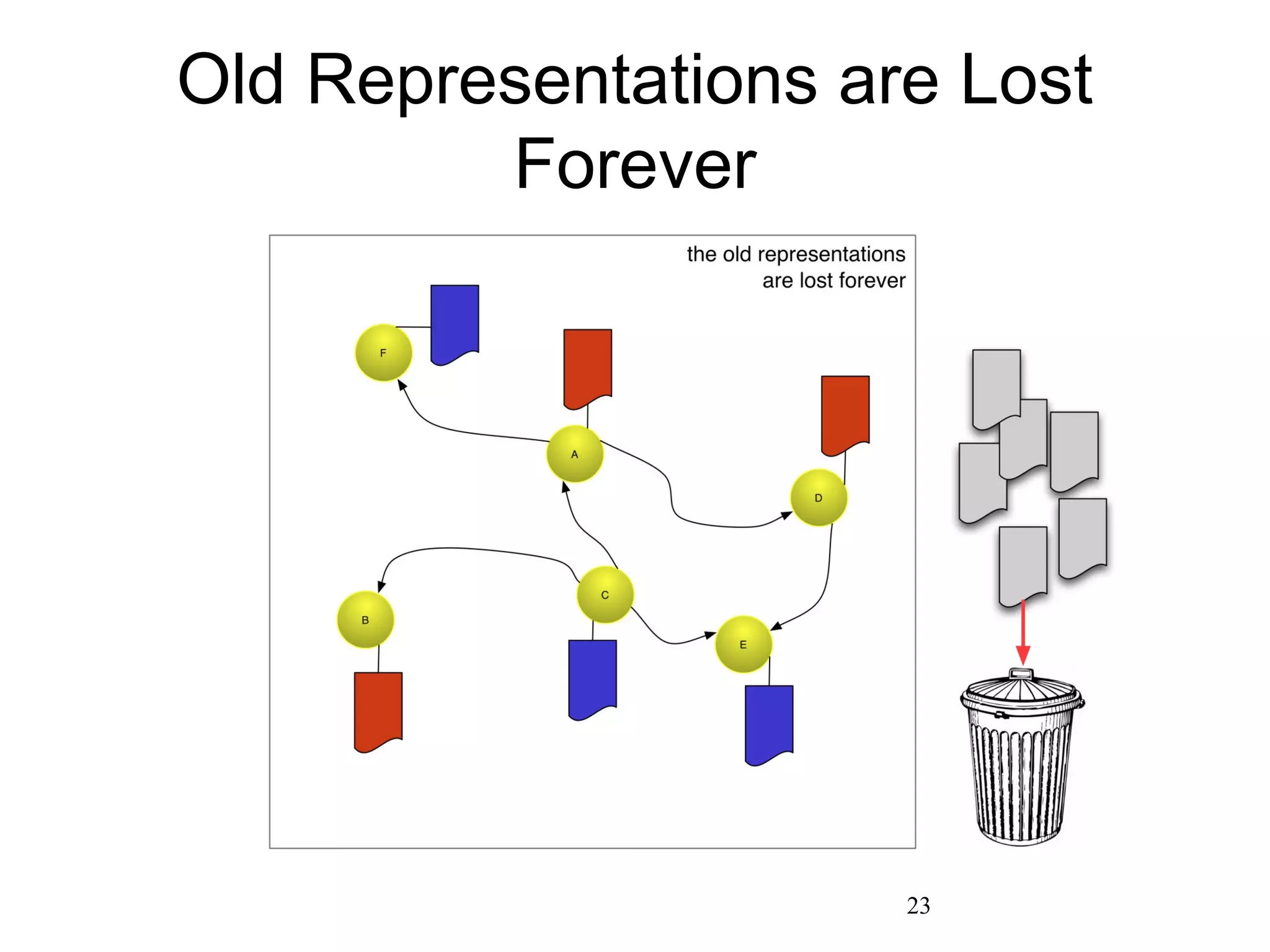
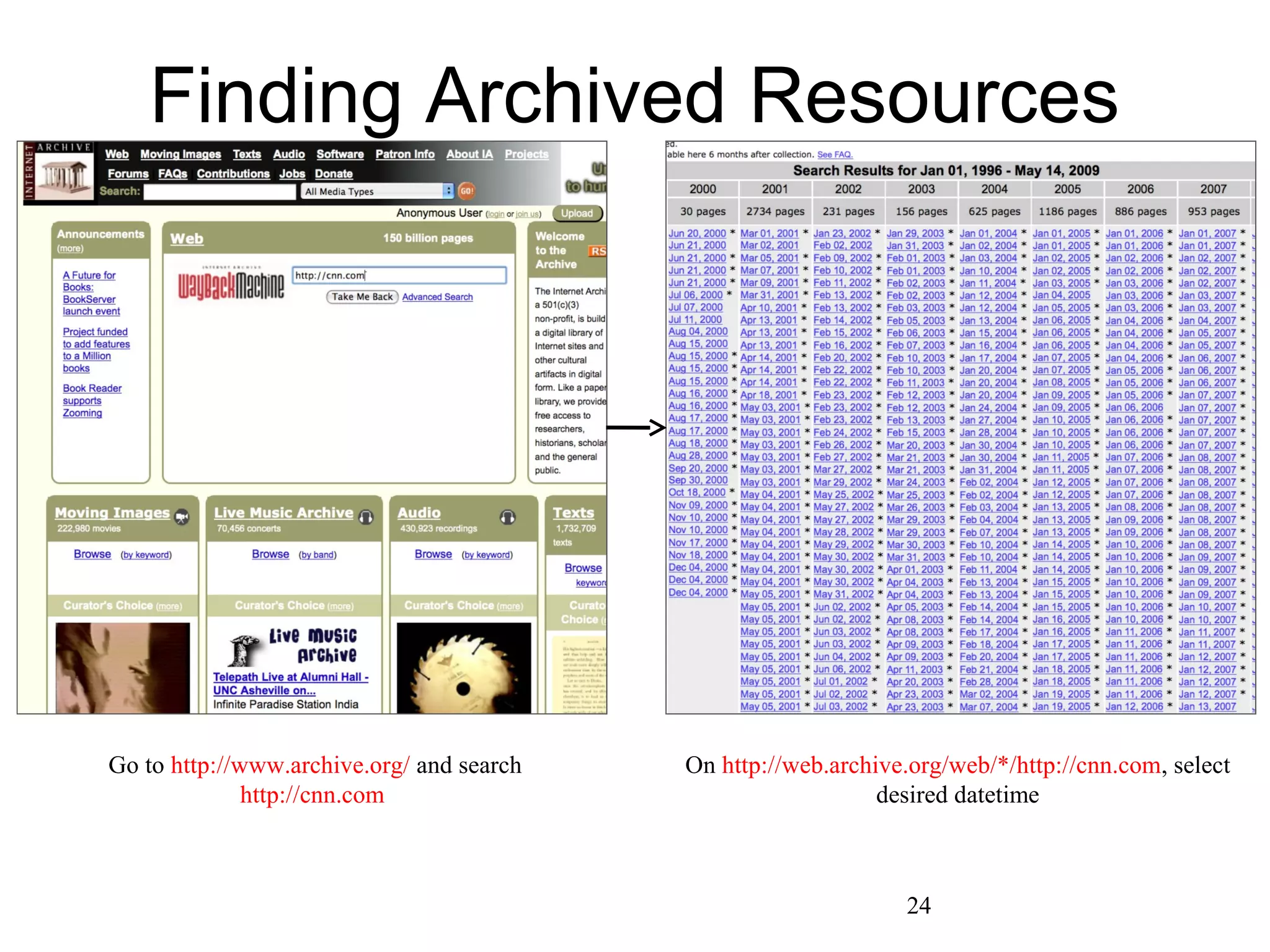
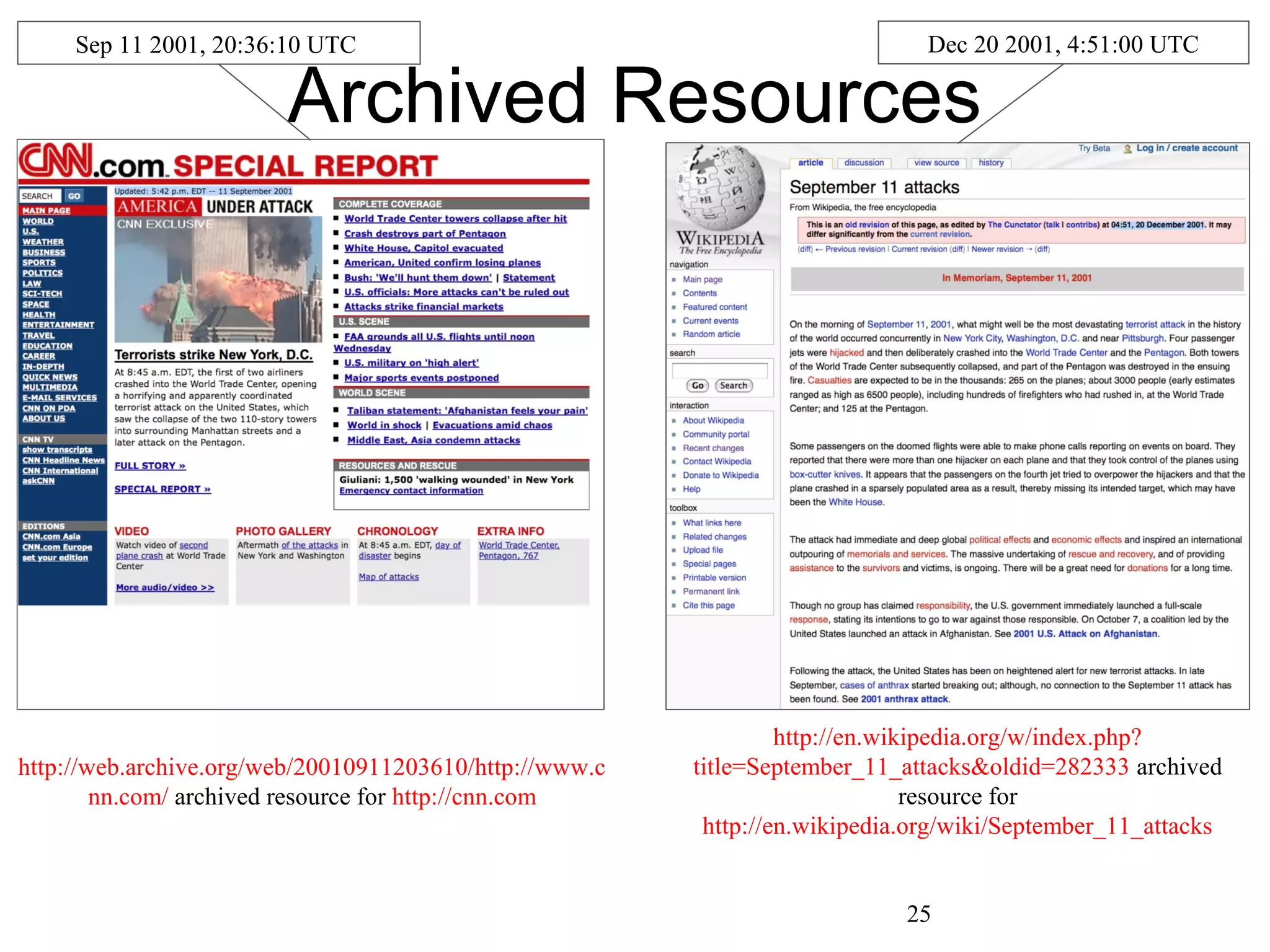

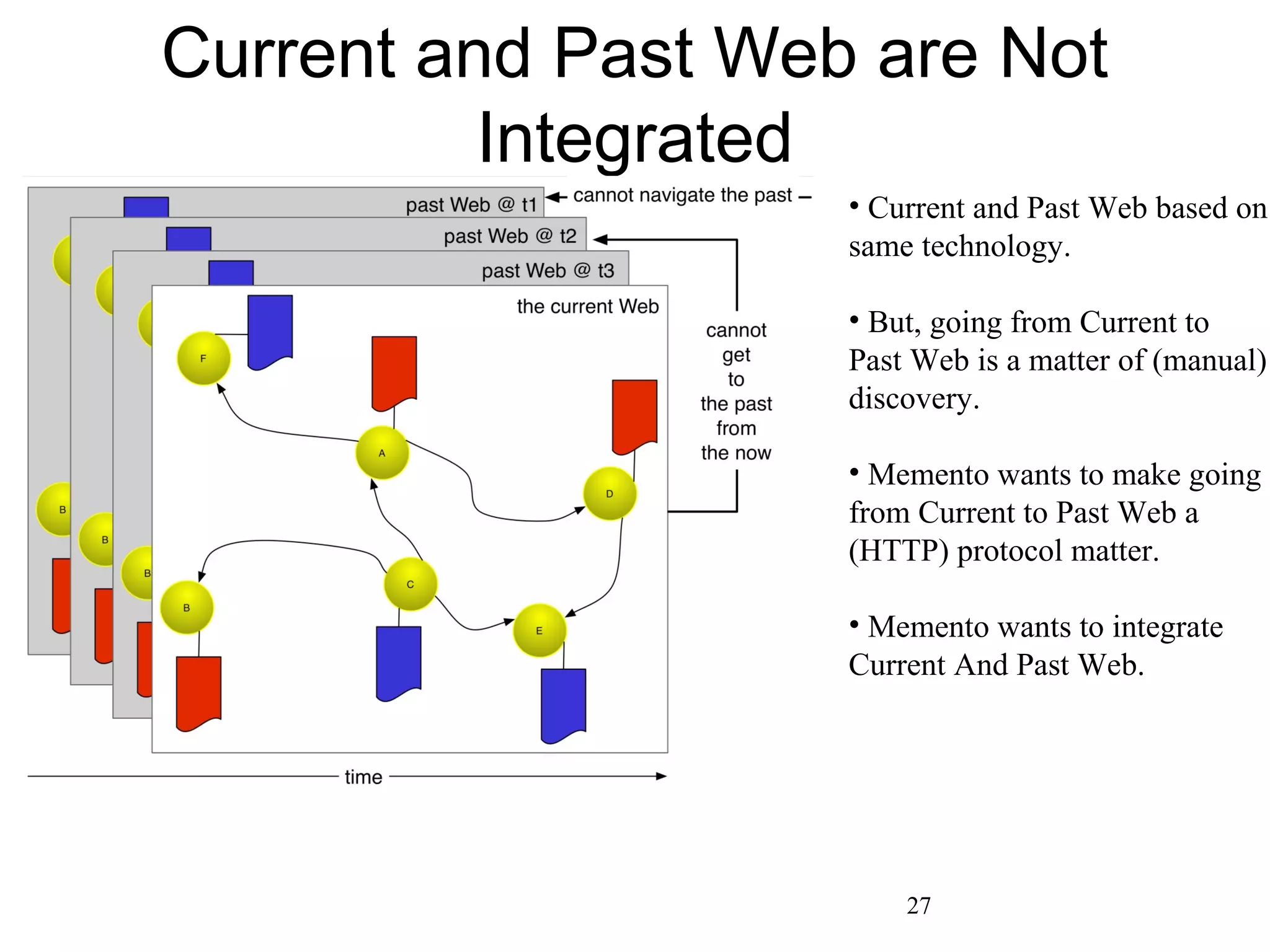

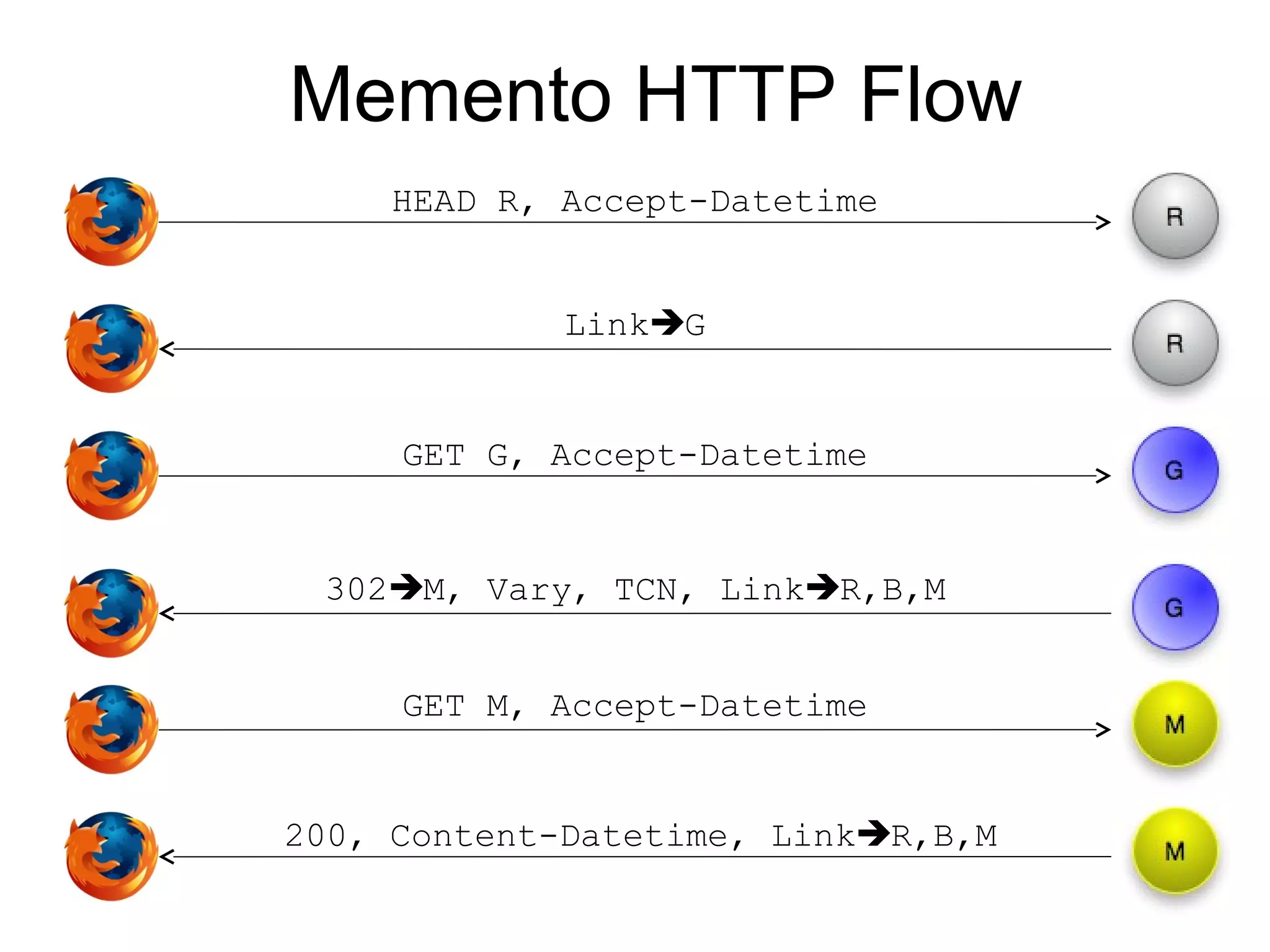

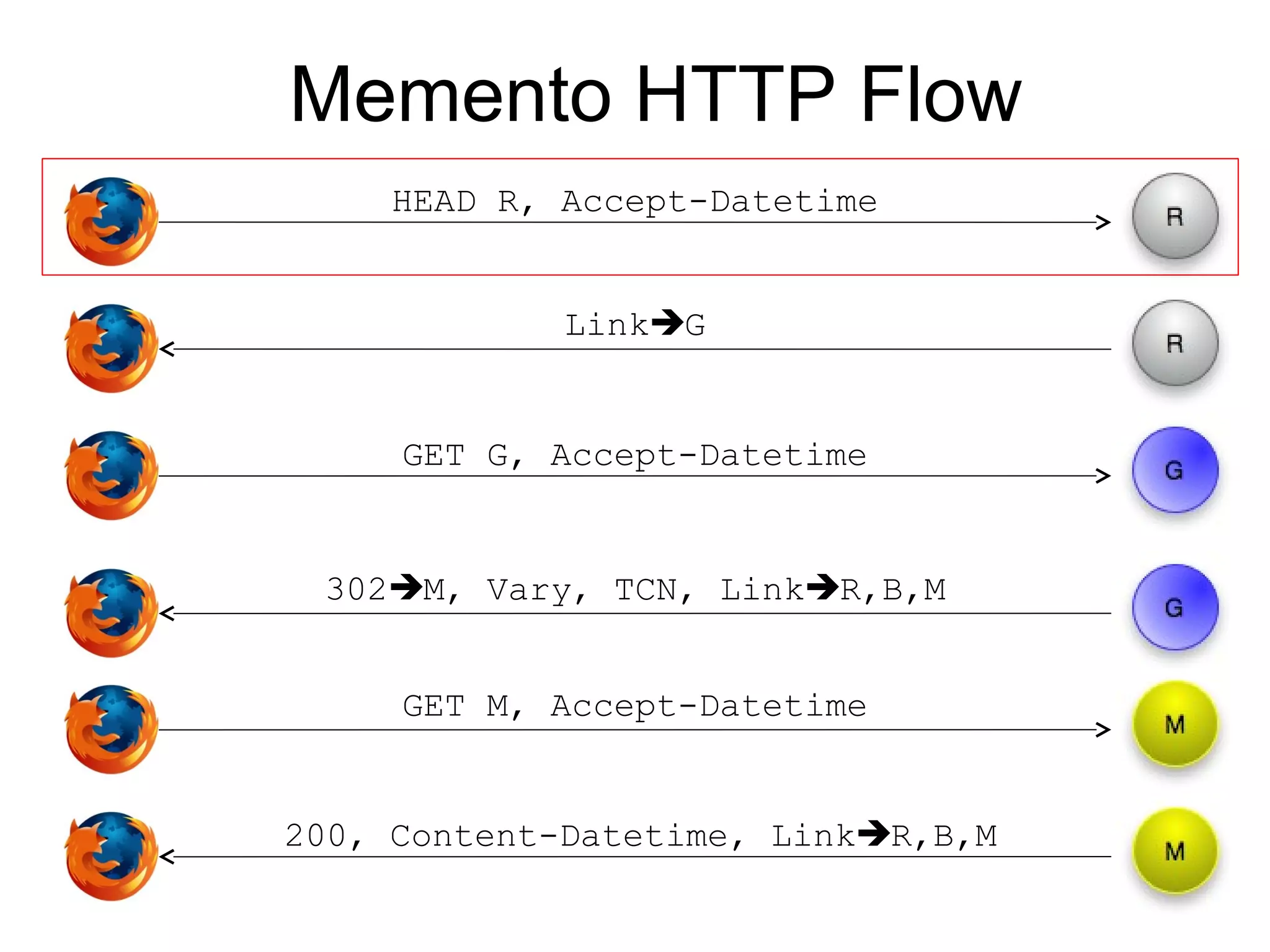
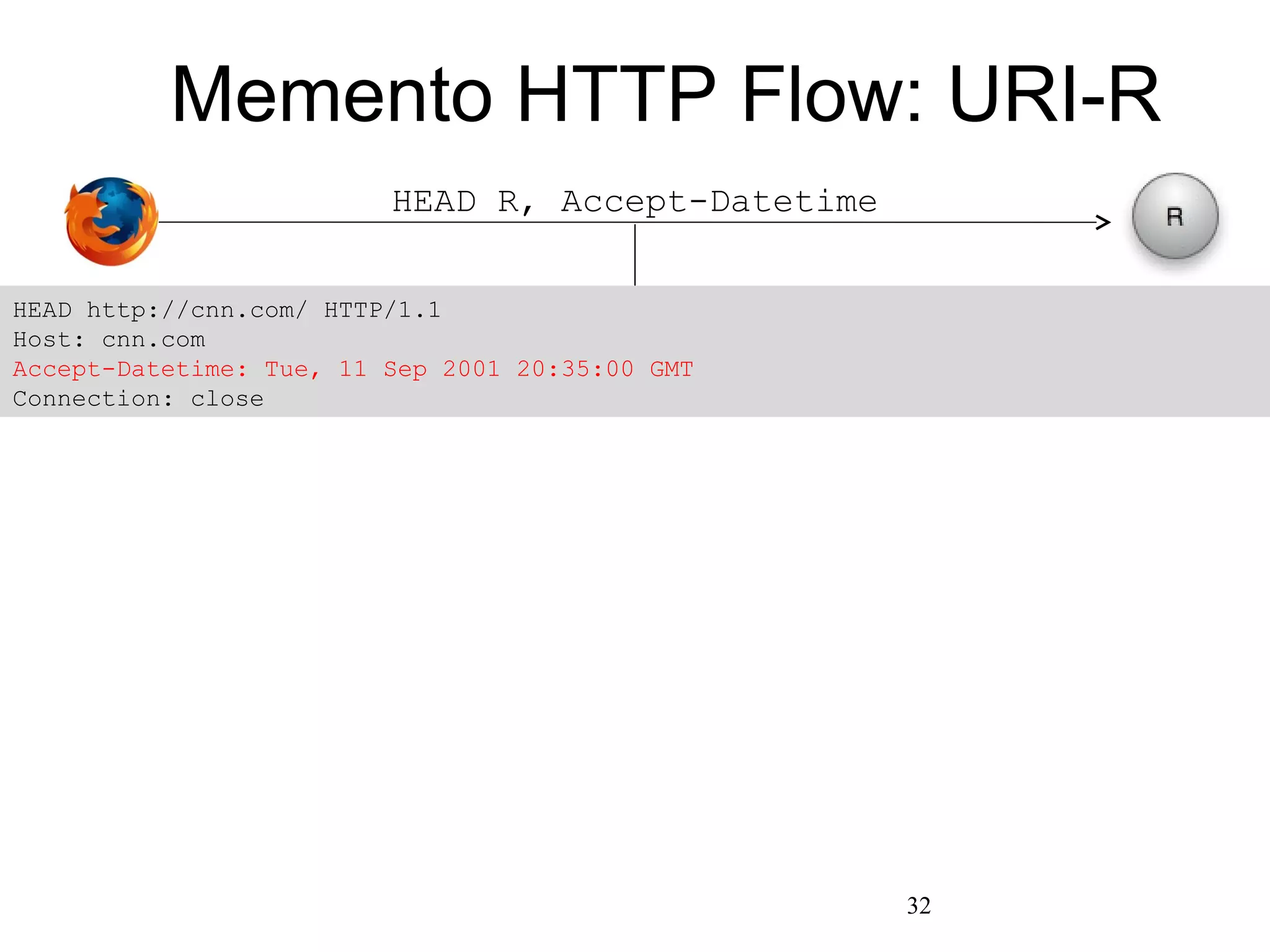
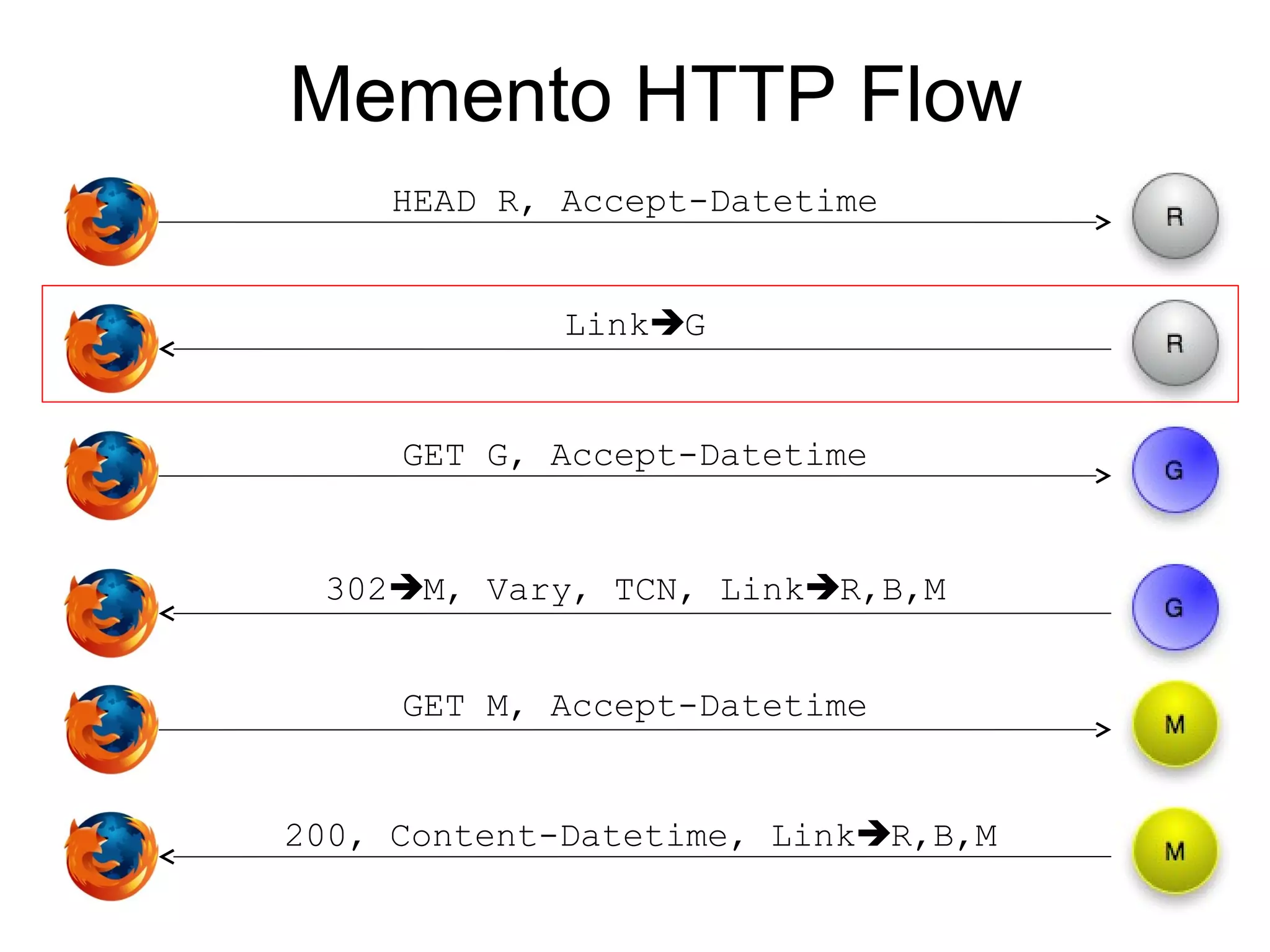



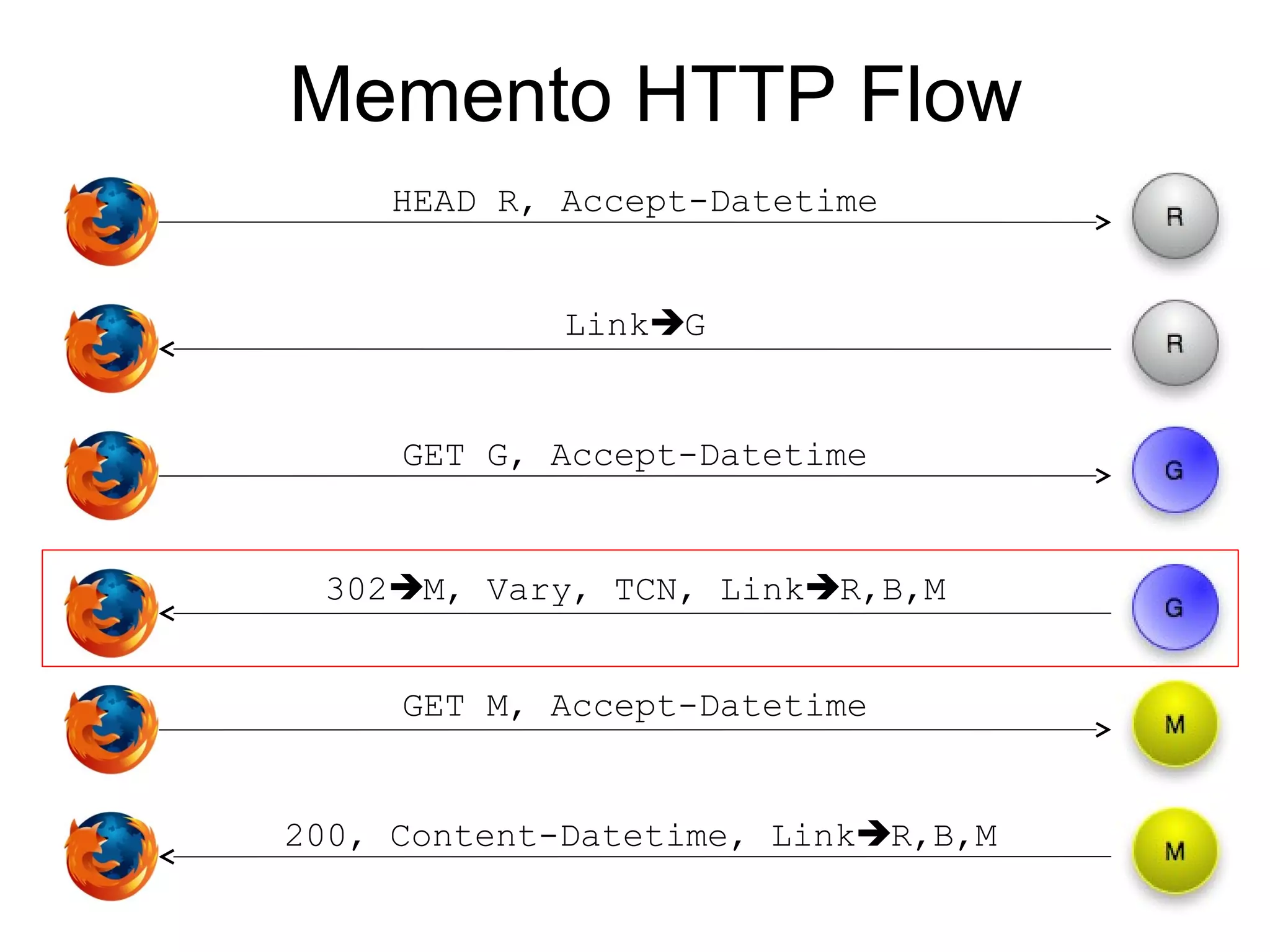
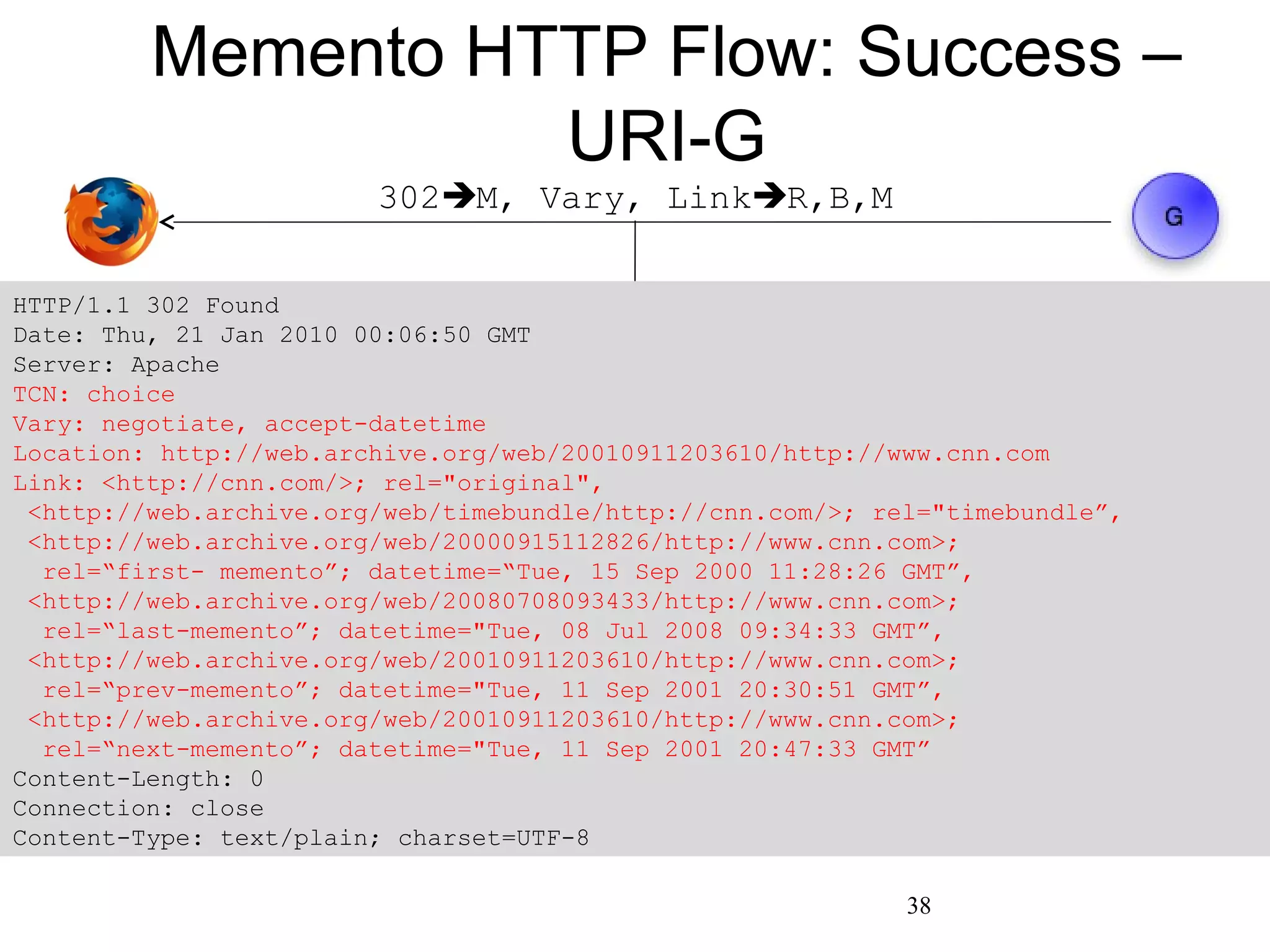
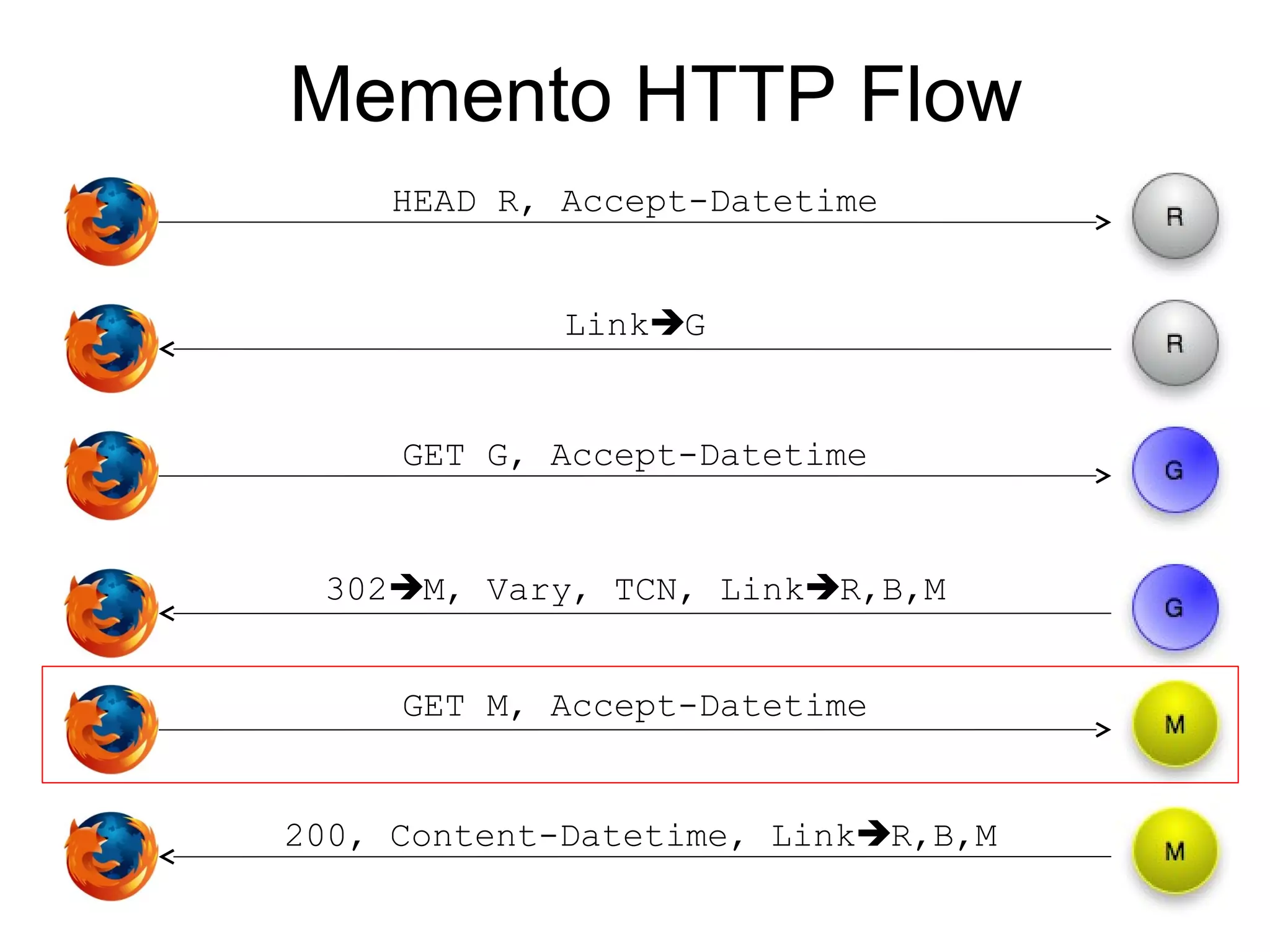
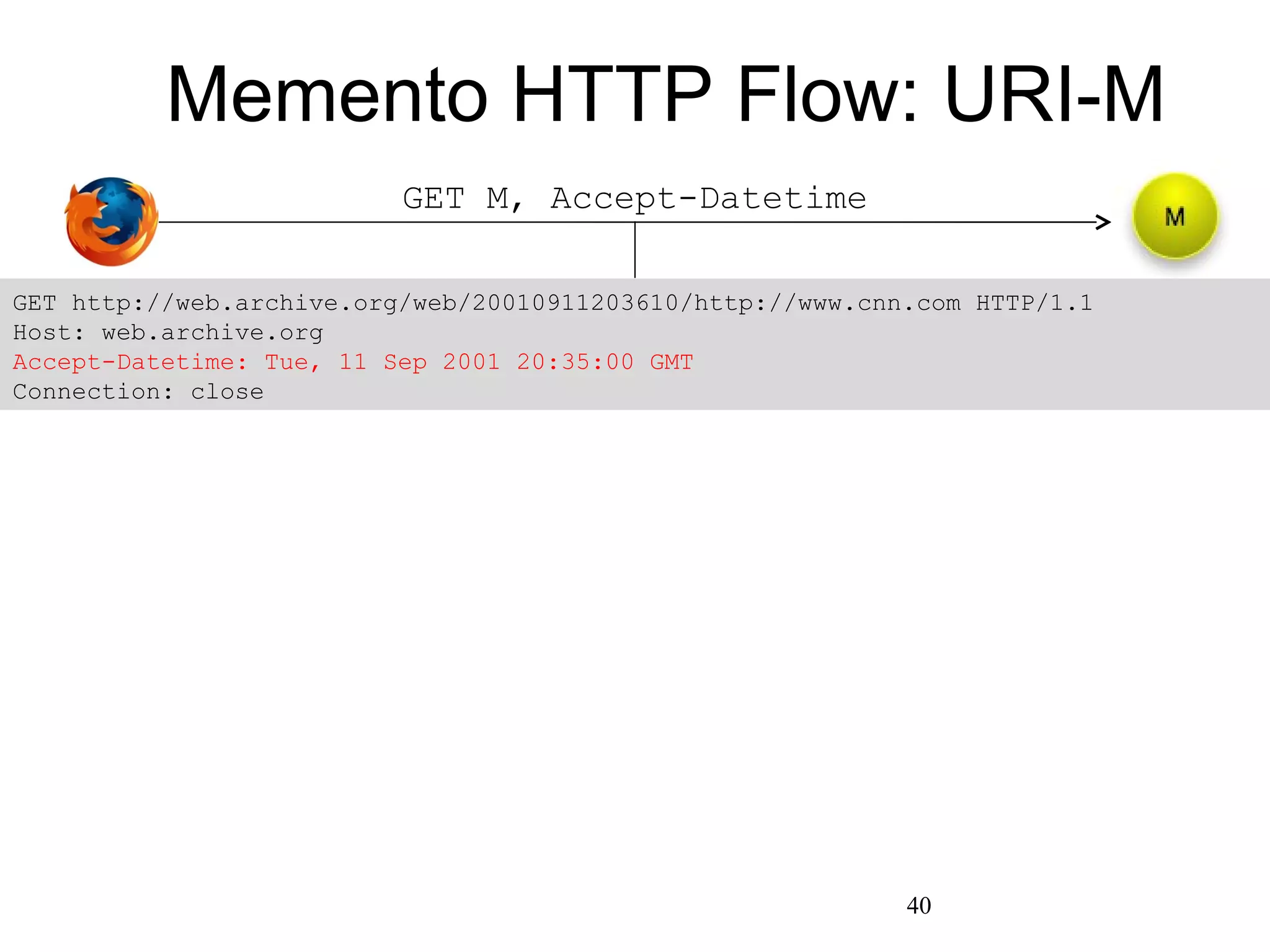
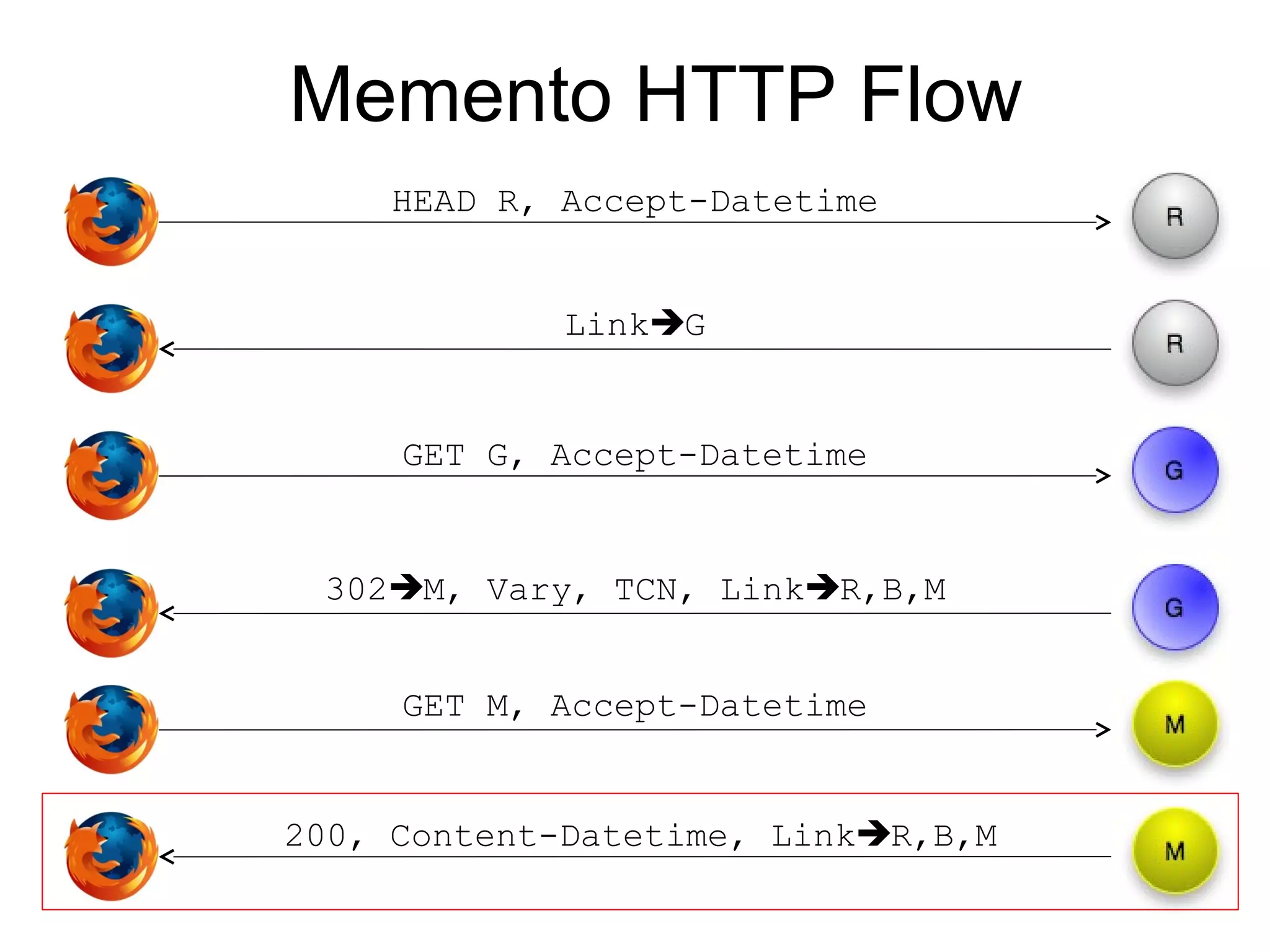
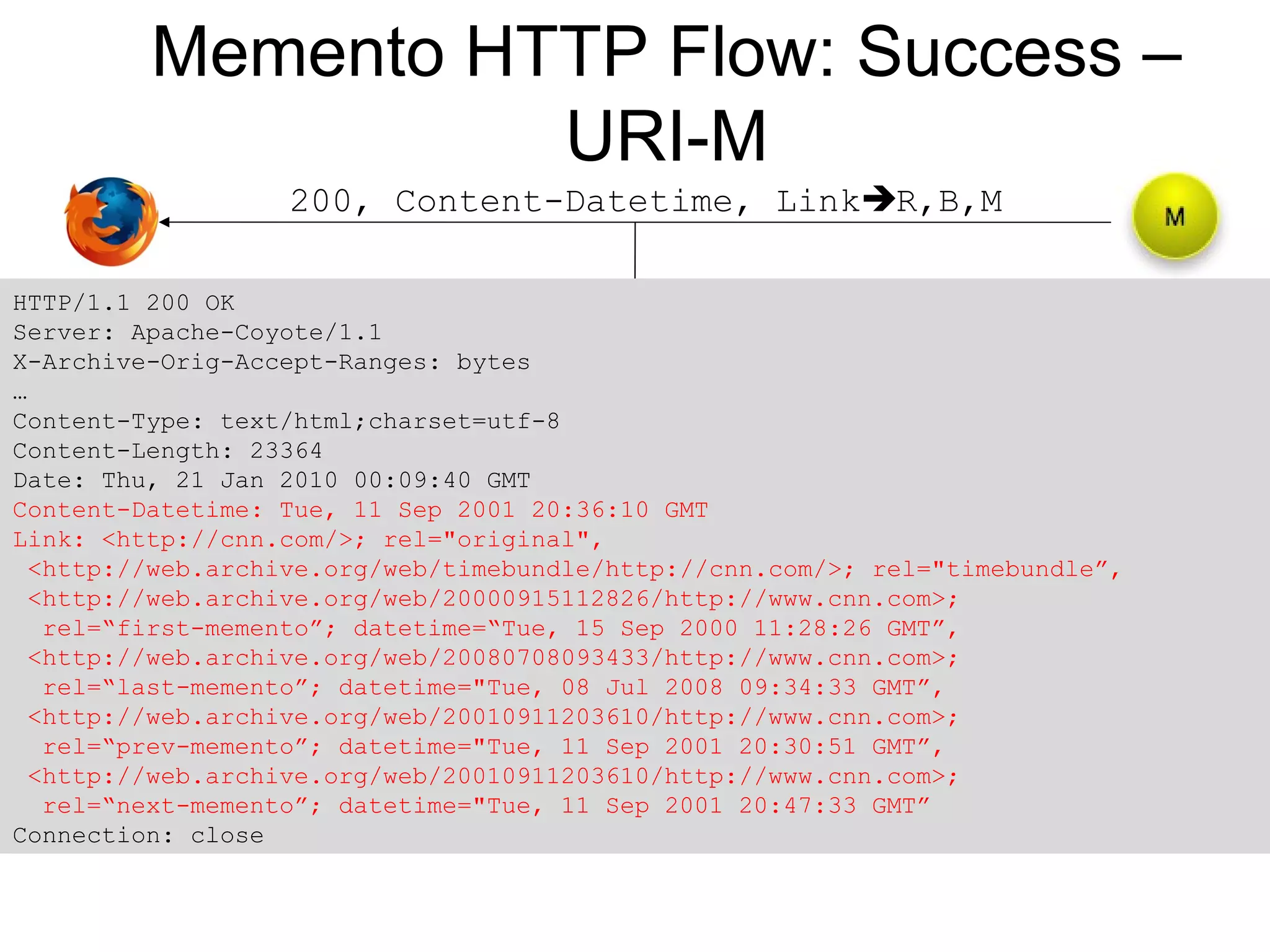




The document presents a research overview from Old Dominion University regarding digital preservation and the challenges of accessing historical web content. It discusses concepts such as temporal browsing, the use of URIs, and various preservation strategies, including Memento, a protocol designed to facilitate navigation between current and archived web content. The research emphasizes the importance of integrating the past and current web to enhance accessibility and preserve digital resources.

























































