Downloaded 192 times





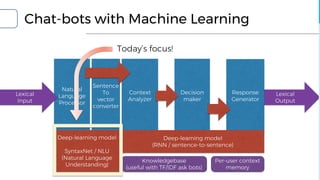
![Today’s focus
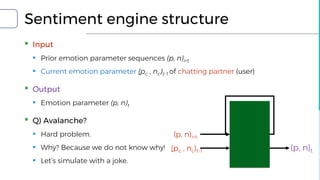
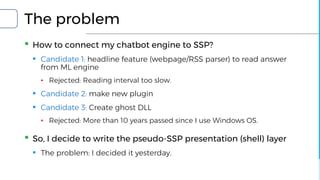
▪ NLP and Sentiment: Big problems when making chatbots
▪ Natural Language Understanding
▪ SyntaxNet and DRAGNN
▪ Emotion reading
▪ SentiWordNet and SentiSpace[1]
▪ Emotion simulation
▪ ML Sentiment engine
[1] Our own definition for sentimental state space
Illust: http://www.eetimes.com/document.asp?doc_id=1324302](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-5-320.jpg)







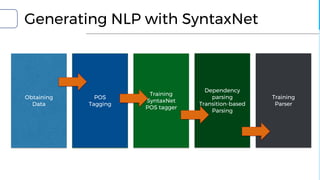


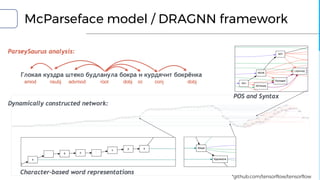
![Model differences
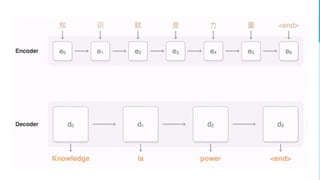
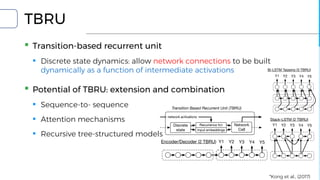
▪ DRAGNN[1]: End-to-end, deep recurrent models
▪ Use to extend SyntaxNet[2] to be end-to-end deep learning model
▪ TBRU: Transition-Based Recurrent Unit
▪ Uses both encoder and decoder
▪ TBRU-based multi-task learning : DRAGNN
▪ SyntaxNet: Transition-based NLP
▪ Can train SyntaxNet using DRAGNN framework
[1] Kong et al., (2017)
[2] Andor et al., (2016)](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-21-320.jpg)











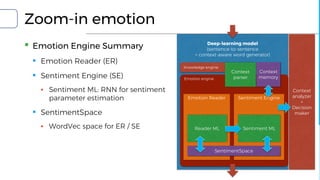
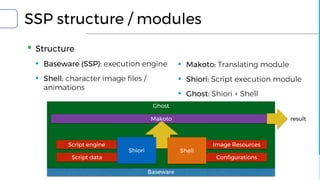
![Emotion engine
▪ Input: text sequence
▪ Output: Emotion flag (6-type / 3bit)
▪ Training set
▪ Sentences with 6-type categorized emotion
▪ Positivity (2), negativity (2), objectivity (2)
▪ Uses senti-word-net to extract emotion
▪ 6-axis emotion space by using Word2Vec model
▪ Current emotion indicator: the most weighted emotion axis using
Word2Vec model
Illustration *(c) http://ontotext.fbk.eu/
[0.95, 0.05, 0.11, 0.89, 0.92, 0.08]
[1, 0, 0, 0, 0, 0] 0x01
index: 1 2 3 4 5 6
Position in senti-space:](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-37-320.jpg)
![Making emotional context locator
▪ Get emotional flag from sentence
Sample test routine for Sentimental state
from nltk.corpus import sentiwordnet as swn
def get_senti_vector(sentence, pos=None):
result = dict()
for s in sentence.split(' '):
if s not in result.keys():
senti = list(swn.senti_synsets(s.lower(),
pos))
if len(senti) > 0:
mostS = senti[0]
result[s] = [mostS.pos_score(), 1.0-
mostS.pos_score(), mostS.neg_score(), 1.0-
mostS.neg_score(), mostS.obj_score(), 1.0 -
mostS.obj_score()]
return result
{'I': [0.0, 1.0, 0.25, 0.75, 0.75, 0.25],
'happy': [0.875, 0.125, 0.0, 1.0, 0.125, 0.875],
'super': [0.625, 0.375, 0.0, 1.0, 0.375, 0.625],
'surprised': [0.125, 0.875, 0.25, 0.75, 0.625,
0.375]}
{'Hello': [0.0, 1.0, 0.0, 1.0, 1.0, 0.0],
'I': [0.0, 1.0, 0.0, 1.0, 1.0, 0.0],
'am': [0.0, 1.0, 0.0, 1.0, 1.0, 0.0],
'happy': [0.875, 0.125, 0.0, 1.0, 0.125, 0.875],
'was': [0.0, 1.0, 0.0, 1.0, 1.0, 0.0],
'super': [0.0, 1.0, 0.0, 1.0, 1.0, 0.0],
'surprised': [0.125, 0.875, 0.0, 1.0, 0.875, 0.125]}
sentence = "Hello I am happy I was super
surprised"
result = get_senti_vector(sentence)
Adj. only
All morpheme](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-39-320.jpg)
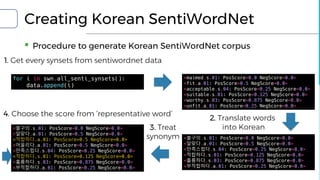

![Reading emotion with SentimentSpace
▪ Creating emotion space
▪ 1. Generate word space using word2vec model
▪ 2. Substitute word to SentiWordNet set
▪ 3. Now we get SentimentSpace!
▪ 4. Get the emotion state by giving disintegrated
word set into SentimentSpace
▪ Focuses on reading emotion
▪ Final location on WordVec space = Average
sentivector of nearest neighbors
*SentimentSpace: our definition / approach to simulate emotion.
SentimentSpace:
WordVec Space with
folded 2-sentiment dimension
[.85, .15, .0]
[.75, .05, .20]
[.65, .15, .20]
[.25, .10, .65]](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-42-320.jpg)
![Unfolding SentimentSpace
▪ Unfolded SentimentSpace
▪ Near nodes = Similar
sentiments
▪ Great representation with
serious problem
▪ Value resolution
▪ `Forgotten emotion`
[.85, .15, .0]
[.75, .05, .20]
[.25, .15, .20]
[.25, .10, .65]
acceptable
fit
Unfavorable
unsatisfactory
objectivity](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-43-320.jpg)

![Tips for SentimentSpace
▪ When picking the best match from candidates
▪ e.g. fit ➜
▪ 1. Just pick the first candidate from senti sets
▪ 2. Calc the average Pos/Neg scores- [ 0.25, 0 ]
▪ When generating Korean SentiWordNet corpus
▪ 1. Do not believe the result. You will need tremendous amount of pre /
postprocessing
▪ SentimentSpace is very rough. Keep in mind to model the emotion
engine
<fit.a.01: PosScore=0.5 NegScore=0.0>
<acceptable.s.04: PosScore=0.25 NegScore=0.0>
<suitable.s.01: PosScore=0.125 NegScore=0.0>
<worthy.s.03: PosScore=0.875 NegScore=0.0>](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-45-320.jpg)











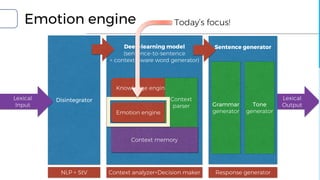
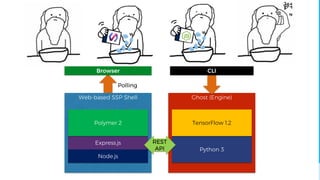
![Are you caring me now?
You / Care / I / Now
You / Look / Tired /Yesterday
You looked tired yesterday.
Ah, you looked very tired yesterday.
[GUESS] I [CARE] [PRESENT]
Disintegrator
Context analyzer
Decision maker
Grammar generator
Tone generator
Lexical
Output
Sentence generator
Deep-learning model
(sentence-to-sentence
+ context-aware word generator)
Grammar generator
Context
memory
Knowledge engine
Emotion engine
Context
parser
Tone generator
Disintegrator
Response
generator
NLP + StV
Context
analyzer
+
Decision
maker
Lexical
Input](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-58-320.jpg)


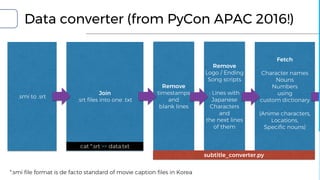
![Extract Conversations
Conversation data
for sequence-to-sequence
Bot model
Reformat
merge
sliced captions
into one line
if last_sentence [-1] == '?':
conversation.add((
last_sentence,
current_sentence))
Remove
Too short sentences
Duplicates
Sentence data
for
disintegrator
grammar model
tone model
Train
disintegrator
integrator with
grammar model
tone model
Train
bot model
subtitle_converter.py
Pandas + DBMS
pandas
https://github.com/inureyes/pycon-kr-2017-demo-nanika](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-63-320.jpg)


![2017-08-11 14:44:17.817210: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't
compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU
computations.2017-08-11 14:44:17.817250: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow
library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up
CPU computations.2017-08-11 14:44:17.817262: W tensorflow/core/platform/cpu_feature_guard.cc:45] The
TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could
speed up CPU computations.2017-08-11 14:44:17.817271: W tensorflow/core/platform/cpu_feature_guard.cc:45] The
TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could
speed up CPU computations.2017-08-11 14:44:17.817280: W tensorflow/core/platform/cpu_feature_guard.cc:45] The
TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could
speed up CPU computations.2017-08-11 14:44:18.826396: I
tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:893] successful NUMA node read from SysFS had negative
value (-1), but there must be at least one NUMA node, so returning NUMA node zero2017-08-11 14:44:18.827380: I
tensorflow/core/common_runtime/gpu/gpu_device.cc:940] Found device 0 with properties:name: Tesla K80major: 3
minor: 7 memoryClockRate (GHz) 0.8235pciBusID 0000:00:17.0Total memory: 11.17GiBFree memory: 11.11GiB
…
2017-08-11 14:44:19.804221: I tensorflow/core/common_runtime/gpu/gpu_device.cc:940] Found device 7 with
properties:name: Tesla K80major: 3 minor: 7 memoryClockRate (GHz) 0.8235pciBusID 0000:00:1e.0Total memory:
11.17GiBFree memory: 11.11GiB
2017-08-11 14:44:19.835747: I tensorflow/core/common_runtime/gpu/gpu_device.cc:961] DMA: 0 1 2 3 4 5 6 7
2017-08-11 14:44:19.835769: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0: Y Y Y Y Y Y Y Y
2017-08-11 14:44:19.835775: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 1: Y Y Y Y Y Y Y Y
2017-08-11 14:44:19.835781: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 2: Y Y Y Y Y Y Y Y
2017-08-11 14:44:19.835785: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 3: Y Y Y Y Y Y Y Y
2017-08-11 14:44:19.835790: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 4: Y Y Y Y Y Y Y Y
2017-08-11 14:44:19.835794: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 5: Y Y Y Y Y Y Y Y
2017-08-11 14:44:19.835800: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 6: Y Y Y Y Y Y Y Y
2017-08-11 14:44:19.835805: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 7: Y Y Y Y Y Y Y Y
Bot training procedure (initialization)](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-66-320.jpg)










![Summary
▪ Today
▪ Dive into SyntaxNet and DRAGNN
▪ Emotion reading procedure using SentiWordNet and deep learning
▪ Emotion simulating with Sentiment Engine
▪ My contributions / insight to you
▪ Dodging Korean-specific problems when using SyntaxNet
▪ My own emotion reading / simulation algorithm]
▪ Dig into communication with multiple chat-bots
▪ And heartbreaking demonstration!](https://image.slidesharecdn.com/20170812-withoutappendix-170812065138/85/Let-Android-dream-electric-sheep-Making-emotion-model-for-chat-bot-with-Python3-NLTK-and-TensorFlow-81-320.jpg)






The document discusses the development of an emotional model for chatbots using Python, NLTK, and TensorFlow, focusing on natural language processing and understanding emotions. It covers various methods like SyntaxNet and Dragnn for language understanding, as well as techniques for reading and simulating emotions in conversation. The challenges faced by chatbots, including limitations in handling continuous conversational context and generating human-like interactions, are also highlighted.





![Random Thoughts on Paper Implementations [KAIST 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/kaist2018-180426031539-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)




























































