Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Yuta Imai
9,496 views
Hadoop and Kerberos
Security Recap and Updates for Hadoop. it's all based on Kerberos.
Software
◦
Read more
17
Save
Share
Embed
Embed presentation
Download
Downloaded 164 times
1
/ 66
2
/ 66
3
/ 66
4
/ 66
5
/ 66
6
/ 66
7
/ 66
8
/ 66
9
/ 66
10
/ 66
11
/ 66
12
/ 66
13
/ 66
14
/ 66
15
/ 66
16
/ 66
17
/ 66
18
/ 66
19
/ 66
20
/ 66
21
/ 66
22
/ 66
23
/ 66
24
/ 66
25
/ 66
26
/ 66
27
/ 66
28
/ 66
29
/ 66
30
/ 66
31
/ 66
32
/ 66
33
/ 66
34
/ 66
35
/ 66
36
/ 66
37
/ 66
38
/ 66
39
/ 66
40
/ 66
41
/ 66
42
/ 66
43
/ 66
44
/ 66
45
/ 66
46
/ 66
47
/ 66
48
/ 66
49
/ 66
50
/ 66
51
/ 66
52
/ 66
53
/ 66
54
/ 66
55
/ 66
56
/ 66
57
/ 66
58
/ 66
59
/ 66
60
/ 66
61
/ 66
62
/ 66
63
/ 66
64
/ 66
65
/ 66
66
/ 66
More Related Content
PDF
AWS Database Migration Service ご紹介
by
Amazon Web Services Japan
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PPTX
事例で学ぶApache Cassandra
by
Yuki Morishita
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PDF
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
AWS Database Migration Service ご紹介
by
Amazon Web Services Japan
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
事例で学ぶApache Cassandra
by
Yuki Morishita
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
What's hot
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Kafka vs Pulsar @KafkaMeetup_20180316
by
Nozomi Kurihara
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PDF
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
Elasticsearchを使うときの注意点 公開用スライド
by
崇介 藤井
PDF
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS...
by
Amazon Web Services Japan
PDF
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
PPTX
サンプルアプリケーションで学ぶApache Cassandraを使ったJavaアプリケーションの作り方
by
Yuki Morishita
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
S3 整合性モデルと Hadoop/Spark の話
by
Noritaka Sekiyama
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
Kafka vs Pulsar @KafkaMeetup_20180316
by
Nozomi Kurihara
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
Elasticsearchを使うときの注意点 公開用スライド
by
崇介 藤井
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS...
by
Amazon Web Services Japan
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
サンプルアプリケーションで学ぶApache Cassandraを使ったJavaアプリケーションの作り方
by
Yuki Morishita
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
S3 整合性モデルと Hadoop/Spark の話
by
Noritaka Sekiyama
Viewers also liked
PDF
MyRocks introduction and production deployment
by
Yoshinori Matsunobu
PDF
第37回「Dockerのユースケースと将来」(2014/10/30 on しすなま!)
by
System x 部 (生!) : しすなま! @ Lenovo Enterprise Solutions Ltd.
PDF
ネットワークでなぜ遅延が生じるのか
by
Jun Kato
PPTX
HDFSネームノードのHAについて #hcj13w
by
Cloudera Japan
PDF
Docker勉強会2017 実践編 スライド
by
Shiojiri Ohhara
PDF
Simplify and Secure your Hadoop Environment with Hortonworks and Centrify
by
Hortonworks
PDF
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
PDF
Dockerイメージの理解とコンテナのライフサイクル
by
Masahito Zembutsu
PDF
5分でわかるブロックチェーンの基本的な仕組み
by
Ryo Shimamura
PDF
Docker入門 - 基礎編 いまから始めるDocker管理
by
Masahito Zembutsu
MyRocks introduction and production deployment
by
Yoshinori Matsunobu
第37回「Dockerのユースケースと将来」(2014/10/30 on しすなま!)
by
System x 部 (生!) : しすなま! @ Lenovo Enterprise Solutions Ltd.
ネットワークでなぜ遅延が生じるのか
by
Jun Kato
HDFSネームノードのHAについて #hcj13w
by
Cloudera Japan
Docker勉強会2017 実践編 スライド
by
Shiojiri Ohhara
Simplify and Secure your Hadoop Environment with Hortonworks and Centrify
by
Hortonworks
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
Dockerイメージの理解とコンテナのライフサイクル
by
Masahito Zembutsu
5分でわかるブロックチェーンの基本的な仕組み
by
Ryo Shimamura
Docker入門 - 基礎編 いまから始めるDocker管理
by
Masahito Zembutsu
Similar to Hadoop and Kerberos
PDF
HDP Security Overview
by
Yifeng Jiang
PPTX
認証/認可が実現する安全で高速分析可能な分析処理基盤
by
Masahiro Kiura
PDF
マルチテナント化に向けたHadoopの最新セキュリティ事情 #hcj2014
by
Cloudera Japan
PDF
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
PDF
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
PDF
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
クラウドにおけるビッグデータ分析環境
by
Kimihiko Kitase
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
PDF
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
PDF
IAM & Consolidated Billing -ほぼ週刊AWSマイスターシリーズ第4回
by
SORACOM, INC
PPT
Yahoo! JAPANでのHadoop利用について
by
Yahoo!デベロッパーネットワーク
PDF
Yifeng hadoop-present-public
by
Yifeng Jiang
PDF
20120201 aws meister-reloaded-iam-and-billing-public
by
Amazon Web Services Japan
PPTX
データ活用を効率化するHadoop WebUIと権限管理改善事例
by
Masahiro Kiura
PDF
Data Lake Security on AWS
by
Amazon Web Services Japan
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PDF
AWS Black Belt Techシリーズ AWS IAM
by
Amazon Web Services Japan
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
HDP Security Overview
by
Yifeng Jiang
認証/認可が実現する安全で高速分析可能な分析処理基盤
by
Masahiro Kiura
マルチテナント化に向けたHadoopの最新セキュリティ事情 #hcj2014
by
Cloudera Japan
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
クラウドにおけるビッグデータ分析環境
by
Kimihiko Kitase
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
IAM & Consolidated Billing -ほぼ週刊AWSマイスターシリーズ第4回
by
SORACOM, INC
Yahoo! JAPANでのHadoop利用について
by
Yahoo!デベロッパーネットワーク
Yifeng hadoop-present-public
by
Yifeng Jiang
20120201 aws meister-reloaded-iam-and-billing-public
by
Amazon Web Services Japan
データ活用を効率化するHadoop WebUIと権限管理改善事例
by
Masahiro Kiura
Data Lake Security on AWS
by
Amazon Web Services Japan
Osc2012 spring HBase Report
by
Seiichiro Ishida
AWS Black Belt Techシリーズ AWS IAM
by
Amazon Web Services Japan
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
More from Yuta Imai
PPTX
Node-RED on device to Apache NiFi on cloud, via SORACOM Canal, with no Internet
by
Yuta Imai
PDF
HDP2.5 Updates
by
Yuta Imai
PDF
Deep Learning On Apache Spark
by
Yuta Imai
PDF
Hadoop in adtech
by
Yuta Imai
PDF
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
PDF
IoTアプリケーションで利用するApache NiFi
by
Yuta Imai
PDF
OLAP options on Hadoop
by
Yuta Imai
PDF
Apache ambari
by
Yuta Imai
PDF
Spark at Scale
by
Yuta Imai
PDF
Dynamic Resource Allocation in Apache Spark
by
Yuta Imai
PDF
Apache Hiveの今とこれから - 2016
by
Yuta Imai
PDF
Benchmark and Metrics
by
Yuta Imai
PDF
Spark Streaming + Amazon Kinesis
by
Yuta Imai
PDF
オンラインゲームの仕組みと工夫
by
Yuta Imai
PDF
Amazon Machine Learning
by
Yuta Imai
PDF
Global Gaming On AWS
by
Yuta Imai
PDF
Digital marketing on AWS
by
Yuta Imai
PDF
EC2のストレージどう使う? -Instance Storageを理解して高速IOを上手に活用!-
by
Yuta Imai
PPTX
クラウドネイティブなアーキテクチャでサクサク解析
by
Yuta Imai
PPTX
CloudFront経由でのCORS利用
by
Yuta Imai
Node-RED on device to Apache NiFi on cloud, via SORACOM Canal, with no Internet
by
Yuta Imai
HDP2.5 Updates
by
Yuta Imai
Deep Learning On Apache Spark
by
Yuta Imai
Hadoop in adtech
by
Yuta Imai
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
IoTアプリケーションで利用するApache NiFi
by
Yuta Imai
OLAP options on Hadoop
by
Yuta Imai
Apache ambari
by
Yuta Imai
Spark at Scale
by
Yuta Imai
Dynamic Resource Allocation in Apache Spark
by
Yuta Imai
Apache Hiveの今とこれから - 2016
by
Yuta Imai
Benchmark and Metrics
by
Yuta Imai
Spark Streaming + Amazon Kinesis
by
Yuta Imai
オンラインゲームの仕組みと工夫
by
Yuta Imai
Amazon Machine Learning
by
Yuta Imai
Global Gaming On AWS
by
Yuta Imai
Digital marketing on AWS
by
Yuta Imai
EC2のストレージどう使う? -Instance Storageを理解して高速IOを上手に活用!-
by
Yuta Imai
クラウドネイティブなアーキテクチャでサクサク解析
by
Yuta Imai
CloudFront経由でのCORS利用
by
Yuta Imai
Hadoop and Kerberos
1.
Page 1 ©
Hortonworks Inc. 2014 Hadoop Security Recap Yuta Imai Hadoop + Kerberos
2.
Page 2 ©
Hortonworks Inc. 2014 この発表について • 今⽇はおもにKerberosとHadoopの関係性につい ての話をします。 • KerberosはHadoopにとって、とても重要ですが、 とても複雑です。 • Kerberosやらなきゃなのはわかってるんだけど、 意味がわからん!という⼈に向けての発表です。
3.
Page 3 ©
Hortonworks Inc. 2014 Background
4.
Page 4 ©
Hortonworks Inc. 2014 Background: YARNによるHadoopのマルチテナント化 • Hadoop2で導⼊されたYARNにより、Hadoopクラ スタを複数のひとや組織、ワークロードによって 共⽤することが容易になった。 • 巨⼤なHDFSクラスタに様々なデータを格納してお き、そのデータに対して様々な処理を⾛らせるこ とが可能に。
5.
Page 5 ©
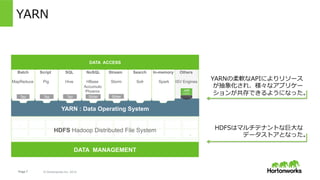
Hortonworks Inc. 2014 1 ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° N HDFS Hadoop Distributed File System DATA MANAGEMENT ストレージ(HDFS)とコンピュー ティング(MapReduce)が結合して いた Before YARN MapReduce クラスタ全体のリソース管理や、 多数のアプリケーション起動時の 性能的なボトルネックなどいくつ かの課題があった
6.
Page 6 ©
Hortonworks Inc. 2014 Others ISV Engines YARN : Data Operating System DATA ACCESS 1 ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° N Batch MapReduce Script Pig Search Solr SQL Hive NoSQL HBase Accumulo Phoenix Stream Storm In-memory Spark TezTez Tez Slider Slider HDFS Hadoop Distributed File System DATA MANAGEMENT YARNの柔軟なAPIによりリソース が抽象化され、様々なアプリケー ションが共存できるようになった。 HDFSはマルチテナントな巨⼤な データストアとなった。 YARN
7.
Page 7 ©
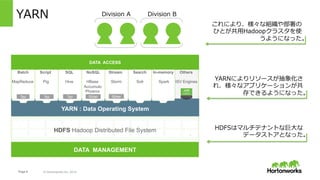
Hortonworks Inc. 2014 YARN Others ISV Engines YARN : Data Operating System DATA ACCESS 1 ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° ° N Batch MapReduce Script Pig Search Solr SQL Hive NoSQL HBase Accumulo Phoenix Stream Storm In-memory Spark TezTez Tez Slider Slider HDFS Hadoop Distributed File System DATA MANAGEMENT YARNによりリソースが抽象化さ れ、様々なアプリケーションが共 存できるようになった。 HDFSはマルチテナントな巨⼤な データストアとなった。 これにより、様々な組織や部署の ひとが共⽤Hadoopクラスタを使 うようになった。 Division A Division B
8.
Page 8 ©
Hortonworks Inc. 2014 マルチテナント環境の運⽤で注意するべき3つの項⽬ ● Shared Compute & Memory Capacity - 誰がどのくらいの計算リソースを使えるのか ● Shared Storage Capacity - 誰がどのくらいのストレージを使えるのか ● Security Controls - 誰が何をできるのか。
9.
Page 9 ©
Hortonworks Inc. 2014 マルチテナント環境の運⽤で注意するべき3つの項⽬ ● Shared Compute & Memory Capacity - 誰がどのくらいの計算リソースを使えるのか ● Shared Storage Capacity - 誰がどのくらいのストレージを使えるのか ● Security Controls - 誰が何をできるのか。
10.
Page 10 ©
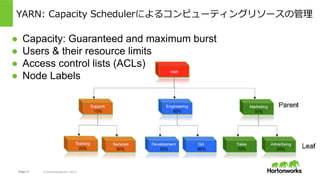
Hortonworks Inc. 2014 YARN Queue: Key to Scheduling ● Capacity: Guaranteed and maximum burst ● Users & their resource limits ● Access control lists (ACLs) ● Node Labels YARN: Capacity Schedulerによるコンピューティングリソースの管理
11.
Page 11 ©
Hortonworks Inc. 2014 HDFS Storage Limits Page 11 Hadoop ClusterSpace Quotas • Applied to directories • Associated with users and groups • Space quotas applied to a user directory will limit the growth of that directory, not the amount of data a user can place in the cluster • The amount of data a single user can place in the cluster is limited by space quotas on their home directory, directories common to the user’s groups, and any common directories the user has access to A tenant consists of users and groups. Each tenant can consume the sum of space allocated to directories associated with its users and groups. Additionally, tenants can consume space in directories that are shared across Tenants. The sum of all space quotas should equal the total amount of available space in the cluster, unless oversubscription is anticipated and consumption is monitored. Remember to account for replication factors! HDFSのQuota制御
12.
Page 12 ©
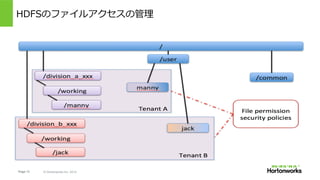
Hortonworks Inc. 2014 HDFS Storage Allocation - Directories & PermissionHDFSのファイルアクセスの管理
13.
Page 13 ©
Hortonworks Inc. 2014 who? ユーザーを正しく認証するということが⾮ 常に重要 いずれのケースにおいても
14.
Page 14 ©
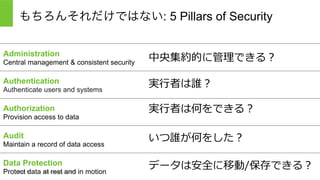
Hortonworks Inc. 2014 もちろんそれだけではない: 5 Pillars of Security Administration Central management & consistent security Authentication Authenticate users and systems Authorization Provision access to data Audit Maintain a record of data access Data Protection Protect data at rest and in motion 実⾏者は誰? 実⾏者は何をできる? いつ誰が何をした? データは安全に移動/保存できる? 中央集約的に管理できる?
15.
Page 15 ©
Hortonworks Inc. 2014 Hadoop Security Recap
16.
Page 16 ©
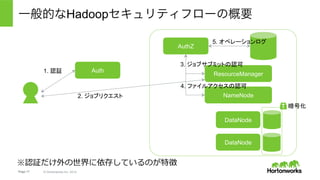
Hortonworks Inc. 2014 一般的なHadoopセキュリティフローの概要 AuthZ Auth NameNode 1. 認証 2. ジョブリクエスト 5. オペレーションログ DataNode DataNode 暗号化 ResourceManager 3. ジョブサブミットの認可 4. ファイルアクセスの認可 ※認証だけ外の世界に依存しているのが特徴
17.
Page 17 ©
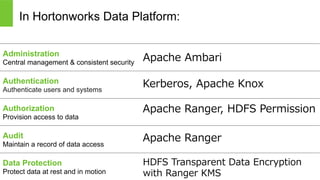
Hortonworks Inc. 2014 In Hortonworks Data Platform: Administration Central management & consistent security Authentication Authenticate users and systems Authorization Provision access to data Audit Maintain a record of data access Data Protection Protect data at rest and in motion Kerberos, Apache Knox Apache Ranger, HDFS Permission Apache Ranger HDFS Transparent Data Encryption with Ranger KMS Apache Ambari
18.
Page 18 ©
Hortonworks Inc. 2014 Typical Access Control Flow - SQL Page 18 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
19.
Page 19 ©
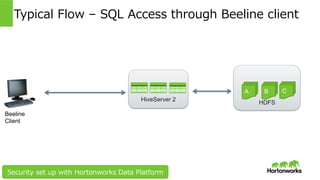
Hortonworks Inc. 2014 HDFS Typical Flow – SQL Access through Beeline client HiveServer 2 A B C Beeline Client Security set up with Hortonworks Data Platform
20.
Page 20 ©
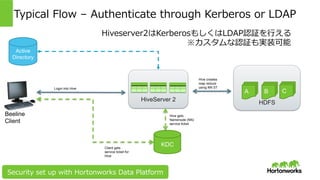
Hortonworks Inc. 2014 HDFS Typical Flow – Authenticate through Kerberos or LDAP HiveServer 2 A B C KDC Login into Hive Hive gets Namenode (NN) service ticket Hive creates map reduce using NN ST Client gets service ticket for Hive Beeline Client Security set up with Hortonworks Data Platform Active Directory Hiveserver2はKerberosもしくはLDAP認証を⾏える ※カスタムな認証も実装可能
21.
Page 21 ©
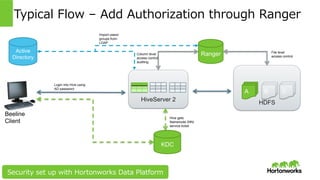
Hortonworks Inc. 2014 HDFS Typical Flow – Add Authorization through Ranger HiveServer 2 A B C KDC Hive gets Namenode (NN) service ticket Column level access control, auditing Ranger Beeline Client File level access control Active Directory Import users/ groups from LDAP Login into Hive using AD password Security set up with Hortonworks Data Platform
22.
Page 22 ©
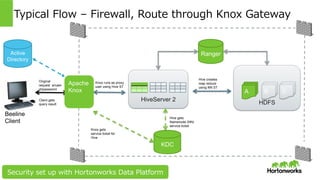
Hortonworks Inc. 2014 HDFS Typical Flow – Firewall, Route through Knox Gateway HiveServer 2 A B C KDC Use Hive ST, submit query Hive gets Namenode (NN) service ticket Hive creates map reduce using NN ST Ranger Knox gets service ticket for Hive Knox runs as proxy user using Hive ST Original request w/user id/password Client gets query result Beeline Client Apache Knox Active Directory Security set up with Hortonworks Data Platform
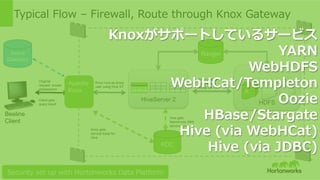
23.
Page 23 ©
Hortonworks Inc. 2014 HDFS Typical Flow – Firewall, Route through Knox Gateway HiveServer 2 A B C KDC Use Hive ST, submit query Hive gets Namenode (NN) service ticket Hive creates map reduce using NN ST Ranger Knox gets service ticket for Hive Knox runs as proxy user using Hive ST Original request w/user id/password Client gets query result Beeline Client Apache Knox Active Directory Security set up with Hortonworks Data Platform Knoxがサポートしているサービス YARN WebHDFS WebHCat/Templeton Oozie HBase/Stargate Hive (via WebHCat) Hive (via JDBC)
24.
Page 24 ©
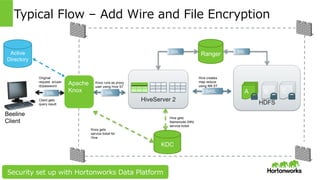
Hortonworks Inc. 2014 HDFS Typical Flow – Add Wire and File Encryption HiveServer 2 A B C KDC Use Hive ST, submit query Hive gets Namenode (NN) service ticket Hive creates map reduce using NN ST Ranger Knox gets service ticket for Hive Knox runs as proxy user using Hive ST Original request w/user id/password Client gets query result SSL Beeline Client SSL SASL SSL SSL Apache Knox Active Directory Security set up with Hortonworks Data Platform
25.
Page 25 ©
Hortonworks Inc. 2014
26.
Page 26 ©
Hortonworks Inc. 2014
27.
Page 27 ©
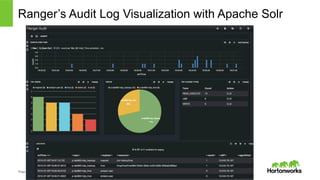
Hortonworks Inc. 2014 Ranger’s Audit Log Visualization with Apache Solr
28.
Page 28 ©
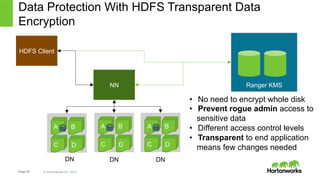
Hortonworks Inc. 2014 Ranger KMS Data Protection With HDFS Transparent Data Encryption NN A B C D HDFS Client A B C D A B C D DN DN DN • No need to encrypt whole disk • Prevent rogue admin access to sensitive data • Different access control levels • Transparent to end application means few changes needed
29.
Page 29 ©
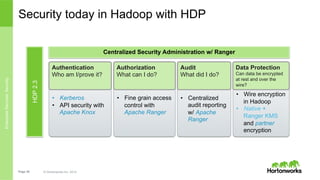
Hortonworks Inc. 2014 • Wire encryption in Hadoop • Native + Ranger KMS and partner encryption • Centralized audit reporting w/ Apache Ranger • Fine grain access control with Apache Ranger Security today in Hadoop with HDP Authorization What can I do? Audit What did I do? Data Protection Can data be encrypted at rest and over the wire? • Kerberos • API security with Apache Knox Authentication Who am I/prove it? HDP2.3 Centralized Security Administration w/ Ranger EnterpriseServices:Security
30.
Page 30 ©
Hortonworks Inc. 2014 In Hotonworks Data Platform: • Apache Rangerが認可と監査、Ranger KMSがHDFS 暗号化の鍵管理、そしてApache Ambariがそれらの統 合的な設定管理を提供する。 • これらはすべて、ユーザーの認証が済んでからの話。セ キュアな認証はKerberosが担当。 who? -> Kerberos ※一部コンポーネントはADやLDAPでの認証をサポートしているものもある。
31.
Page 31 ©
Hortonworks Inc. 2014 Kerberos: You MUST do it! “By default Hadoop runs in non-secure mode in which no actual authentication is required” – Apache Hadoop Documentation https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ SecureMode.html
32.
Page 32 ©
Hortonworks Inc. 2014 Here we are as the user ‘baduser’ $ whoami baduser $ hadoop fs -ls /tmp drwx------ - hdfs hdfs 0 2015-07-14 20:33 /tmp/secure $ hadoop fs -ls /tmp/secure ls: Permission denied: user=baduser, access=READ_EXECUTE, inode="/tmp/ secure":hdfs:hdfs:drwx------ Good right? Kerberos: You MUSTdo it!
33.
Page 33 ©
Hortonworks Inc. 2014 Kerberos: You MUST do it! Here we are as the user ‘baduser’ $ whoami baduser $ hadoop fs -ls /tmp drwx------ - hdfs hdfs 0 2015-07-14 20:33 /tmp/secure $ hadoop fs -ls /tmp/secure ls: Permission denied: user=baduser, access=READ_EXECUTE, inode="/tmp/ secure":hdfs:hdfs:drwx------ Good right? Look again! $ HADOOP_USER_NAME=hdfs hadoop fs -ls /tmp/secure drwxr-xr-x - hdfs hdfs 0 2015-07-14 20:35 /tmp/secure/blah Oh my!
34.
Page 34 ©
Hortonworks Inc. 2014 Hadoop is Unix-like but… • HadoopのセキュリティモデルはUserとGroupに基づいた 管理であり、⾮常にUnixライクであり⾮常にシンプル。 • デフォルトでは実⾏者のUnixユーザーがHadoop内部でも そのままUser(とGroup)として扱う。 • Kerberos化されたクラスタの場合、ユーザーのKerberos PrincipalをもとにUserとGroupを判断する。
35.
Page 35 ©
Hortonworks Inc. 2014 Kerberos - You MUST do it!
36.
Page 36 ©
Hortonworks Inc. 2014 Kerberos化(Kerberize) • Hadoopの認証周りの各種設定をKerberosを利⽤するように設定 する。 • 各サービスが利⽤するkeytab(後述)を⽣成して配布する。 • 詳細 • https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ SecureMode.html • 様々な設定や作業が必要だが、AmbariやCloudera Managerなど を使っていれば簡単に設定が可能。
37.
Page 37 ©
Hortonworks Inc. 2014 Kerberos化(Kerberize) • Hadoopの認証周りの各種設定をKerberosを利⽤するように設定 する。 • 各サービスが利⽤するkeytab(後述)を⽣成して配布する。 • 詳細 • https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ SecureMode.html • 様々な設定や作業が必要だが、AmbariやCloudera Managerなど を使っていれば簡単に設定が可能。 基本的にはトランスペアレントに利⽤できるKerberos。 今⽇はその裏側を⾒てみましょう。
38.
Page 38 ©
Hortonworks Inc. 2014 What is Kerberos? ● ネットワーク上の分散システムを想定して作られた認証システム ● 3つの登場⼈物 ● ユーザー(User Principal, UPN): 認証される側の⼈。サービスにアクセスする⼈。 ● サービス(Service Principal, SPN): アクセスされる側のサービス。アクセスする側に回ることも。 ● Kerberosインフラストラクチャ(AS,TGS): 認証のためのサービス群。 ● 共有鍵ベースの認証 ● よく知られている実装としては下記のとおり ● MIT Kerberos ● Active Directory • yuta@EXAMPLE.COM • nn/revo1.example.com@EXAMPLE.COM
39.
Page 39 ©
Hortonworks Inc. 2014 Kerberos is NOT ● ディレクトリサービス ● KerberosはユーザーのUIDやGroup情報などは管理しない ● ただし、Active DirectoryやFreeIPAはKerberosとディレクトリサービス (LDAP)を統合して提供する。 ● 認可サービス ● Kerberosはユーザーの認証のみを提供し、認可は提供しない。
40.
Page 40 ©
Hortonworks Inc. 2014 コンセプト • REALMS – Kerberosが管理する対象のドメイン。慣習的にDNSのドメイン と同じ⽂字列を使うことが多い。 • Host: revo1.example.com • REALM: EXAMPLE.COM • Principals • ユーザーやサービスを表すエンティティ。ユーザーを表すUser Principal(UPN)とサービスを表す Service Principal(SPN)に別れる。 • {name of entity}/{instance}@{REALM} • yuta@EXAMPLE.COM • nn/revo1.example.com@EXAMPLE.COM • Instances • ユーザーの役割やサービスの位置を表す • yuta/admin@EXAMPLE.COM • nn/revo1.example.com@EXAMPLE.COM
41.
Page 41 ©
Hortonworks Inc. 2014 コンポーネント KDC (Key Distribution Center) 1. Principal/Key Database • Principalとそれらに紐づくkeyやmetadataを管理 2. Authentication Server (AS) • TGT(Ticket Granting Ticket)の発⾏を⾏う。 • TGTをユーザーのパスワードを使って暗号化したものをクライアントに返すので、それによって認 証がなされる。 3. Ticket Granting Server (TGS) • ST(Service Ticket)の発⾏を⾏う。 • クライアントからのリクエスト(TGS_REQ)には“アクセスしたいサービスのPrincipal”とTGTが含 まれており、TGTの検証が正しくなされれば、当該サービスへアクセスを許可するSTを発⾏する。
42.
Page 42 ©
Hortonworks Inc. 2014 チケット 1. TGT(Ticket Granting Ticket) • STを要求するためのチケット。チケットのためのチケット。 • リクエスト時に⽣成されるsession keyという⽂字列を、TGSのキーで暗号化したもの。 2. ST(Service Ticket) • 実際にサービスへのアクセスに利⽤されるチケット。 • アクセス先のサービスのService Principal(nn/revo1.example.com@EXAMPLE.COM)を含む。
43.
Page 43 ©
Hortonworks Inc. 2014 チケットについての補足 チケットの持つメタ情報: • 利⽤スコープについてのフラグ • Lifetime, Forwardable, Renewable (max renew lifetime) • フィールド • Requesting Principal Name • Service Principal Name • Validity Period • Session key 発⾏されたチケットはクライアントにキャッシュされる。
44.
Page 44 ©
Hortonworks Inc. 2014 • アクセスしたい⼈: yuta@EXAMPLE.COM • アクセスしたいサービス: nn/revo1.example.com@EXAMPLE.COM ゴール • yuta@EXAMPLE.COMを使って、nn/ revo1.example.com@EXAMPLE.COMのService Ticketを取得する。 First Step: • Authentication ServerからTicket Granting Ticket(TGT)を取得する 例えばNameNodeへのアクセス時には・・・ ※これはKerberosの仕組みを説明するために簡略化されたワークフロー。 実際にHadoopの実装利⽤される際には若⼲の際があるので注意。詳細は後述。
45.
Page 45 ©
Hortonworks Inc. 2014 1. クライアント: Authentication Server(AS)へリクエスト(AS_REQ)を送 信 – これにはユーザーのPrincipal、ローカルタイム、Ticket Granting Server(TGS)のPrincipal Namee.g. krbtgt/ EXAMPLE.COM@EXAMPLE.COM)が含まれる。Instance名の EXAMPLE.COMが、どのTGSが処理できるかを⽰す。 2. AS: ユーザーのPrincipalが存在し、ローカルタイムに問題がないことを確 認 - 問題なければ、ランダムなsession_key⽂字列を⽣成し、2つのコ ピーをつくる。ひとつはユーザーのパスワードで暗号化し、もうひとつは TGSのパスワードで暗号化する(これがTGT)。そして両者をまとめてク ライアントに返す。 例えばNameNodeへのアクセス時には・・・ ※これはKerberosの仕組みを説明するために簡略化されたワークフロー。 実際にHadoopの実装利⽤される際には若⼲の際があるので注意。詳細は後述。
46.
Page 46 ©
Hortonworks Inc. 2014 3. クライアント:AS_REP内のsession_keyを復号化 – クライアントがユー ザーに対してパスワードを求め、⼊⼒されたものを使ってAS_REPの復号化 を⾏う。問題なく復号化されたら、sesison_keyとTGTはクライアントの キャッシュに保存される。 例えばNameNodeへのアクセス時には・・・ ※これはKerberosの仕組みを説明するために簡略化されたワークフロー。 実際にHadoopの実装利⽤される際には若⼲の際があるので注意。詳細は後述。
47.
Page 47 ©
Hortonworks Inc. 2014 Ticket Cache: • AS Session Key • Ticket Granting Ticket (krbtgt/EXAMPLE.COM@EXAMPLE.COM) Next Steps: • 実際のサービスとやりとりするためのチケット(ST, Service Ticket)を Ticket Granting Serverに要求する。 例えばNameNodeへのアクセス時には・・・ ※これはKerberosの仕組みを説明するために簡略化されたワークフロー。 実際にHadoopの実装利⽤される際には若⼲の際があるので注意。詳細は後述。
48.
Page 48 ©
Hortonworks Inc. 2014 1. クライアント: TGS requestを準備 • TGS Request – 下記を含む: • 利⽤したいサービスのService Principle(の名前)。 • Ticket Granting Ticket (TGT) • Authenticator – タイムスタンプをsession keyで暗号化したもの。リプレイ攻撃を防ぐためと、ASとの共有 鍵を持っていることを証明するために使われる。 2. TGS: TGS reply – TGS Session Keyを⽣成し、やはり2つのコピーをつ くる。1つはクライアント⽤にAS Session Keyで暗号化。もうひとつは サービス⽤にそのサービスのパスワードで暗号化し、Service Ticketに埋め 込む。そしてリプライ全体はAS Session Keyで暗号化する。 3. クライアント: TGS replyを処理 – AS Session Keyを使ってメッセージを 復号化。TGS Session KeyとService Ticketをticket cacheに保存する。 例えばNameNodeへのアクセス時には・・・ ※これはKerberosの仕組みを説明するために簡略化されたワークフロー。 実際にHadoopの実装利⽤される際には若⼲の際があるので注意。詳細は後述。
49.
Page 49 ©
Hortonworks Inc. 2014 Ticket Cache: • AS Session Key • Ticket Granting Ticket (krbtgt/EXAMPLE.COM@EXAMPLE.COM) • TGS Session Key • Service Ticket 例えばNameNodeへのアクセス時には・・・ ※これはKerberosの仕組みを説明するために簡略化されたワークフロー。 実際にHadoopの実装利⽤される際には若⼲の際があるので注意。詳細は後述。
50.
Page 50 ©
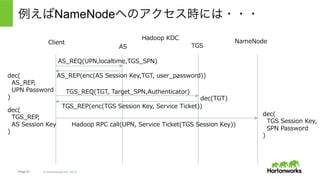
Hortonworks Inc. 2014 ※これはKerberosの仕組みを説明するために簡略化されたワークフロー。 実際にHadoopの実装利⽤される際には若⼲の際があるので注意。詳細は後述。 例えばNameNodeへのアクセス時には・・・ Hadoop KDC AS TGS Client NameNode AS_REQ(UPN,localtime,TGS_SPN) AS_REP(enc(AS Session Key,TGT, user_password)) TGS_REQ(TGT, Target_SPN,Authenticator) TGS_REP(enc(TGS Session Key, Service Ticket)) Hadoop RPC call(UPN, Service Ticket(TGS Session Key)) dec(TGT) dec( AS_REP, UPN Password ) dec( TGS_REP, AS Session Key ) dec( TGS Session Key, SPN Password )
51.
Page 51 ©
Hortonworks Inc. 2014 Kerberos + Hadoop HadoopにおけるKerberosの組み込み
52.
Page 52 ©
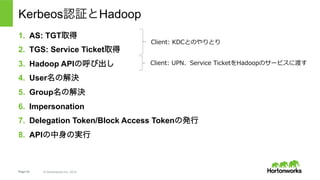
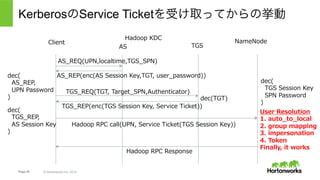
Hortonworks Inc. 2014 Kerbeos認証とHadoop 1. AS: TGT取得 2. Hadoop APIの呼び出し 3. TGS: Service Ticket取得 4. User名の解決 5. Group名の解決 6. Delegation Token/ Block Access Tokenの発行 7. Impersonation 8. APIの中身の実行 Client: KDCとのやりとり Client: UPN、TGT、Service TicketをHadoopのサービスに渡す User Resolution。KerberosのPrincipalから、実際の処理の 実⾏ユーザーを決めるための⼀連の処理。 Hadoop: TGTを使ってSTを取得 ※実際のHadoopの実装ではSTはClientではなくHadoopが要求 上記⾚字の補⾜にあるとおり、実際のHadoop内でのKerberos利⽤の際は、ST取得は クライアントではなくHadoop側で⾏われるので注意。
53.
Page 53 ©
Hortonworks Inc. 2014 Kerberos認証とHadoop $ hdfs dfs –ls /user/yuta $ kinit yuta@EXAMPLE.COM $ hdfs dfs –ls /user/yuta Before After
54.
Page 54 ©
Hortonworks Inc. 2014 KerberosのService Ticketを受け取ってからの挙動 Hadoop KDC AS TGS Client NameNode AS_REQ(UPN,localtime,TGS_SPN) AS_REP(enc(AS Session Key,TGT, user_password)) TGS_REQ(TGT, Target_SPN,Authenticator) TGS_REP(enc(TGS Session Key, Service Ticket)) Hadoop RPC call(UPN, Service Ticket(TGS Session Key)) Hadoop RPC Response auto_to_local group mapping Get required ST (Create Token) (Impersonate) works!
55.
Page 55 ©
Hortonworks Inc. 2014 User Resolution User名とGroup名の解決
56.
Page 56 ©
Hortonworks Inc. 2014 User名の解決 – auth_to_local • RPC Call/API Callとともに渡されるService TicketにはService Principalが 含まれている。しかし、このPrincipal名そのままをHadoopは扱えない。 • Hadoopの各サービスはここから利⽤可能なUser名に変換する。⼀般的に OSのユーザー名に変換をしてやる。 • hadoop.security.auth_to_local yuta@EXAMPLE.COM -> yuta admin/admin@EXAMPLE.COM -> admin nn/revo1.example.com@EXAMPLE.COM -> hdfs
57.
Page 57 ©
Hortonworks Inc. 2014 Auth To Local Rules RULE:[1:$1@$0](ambari-qa-HDP1@HORTONWORKS.LOCAL)s/.*/ambari-qa/ RULE:[1:$1@$0](hbase-HDP1@HORTONWORKS.LOCAL)s/.*/hbase/ RULE:[1:$1@$0](hdfs-HDP1@HORTONWORKS.LOCAL)s/.*/hdfs/ RULE:[1:$1@$0](.*@HORTONWORKS.LOCAL)s/@.*// RULE:[2:$1@$0](amshbase@HORTONWORKS.LOCAL)s/.*/ams/ RULE:[2:$1@$0](amszk@HORTONWORKS.LOCAL)s/.*/ams/ RULE:[2:$1@$0](dn@HORTONWORKS.LOCAL)s/.*/hdfs/ RULE:[2:$1@$0](hbase@HORTONWORKS.LOCAL)s/.*/hbase/ RULE:[2:$1@$0](hive@HORTONWORKS.LOCAL)s/.*/hive/
58.
Page 58 ©
Hortonworks Inc. 2014 Group名の解決 – User Group Mapping • User名が解決されたので、次はGroup名を解決したい。 • しかし、HadoopはそもそもGroupという概念を内部に持っていないので、 User名に対応するOSのGroup名を利⽤する。 • hadoop.security.group.mapping • Unix /etc/passwd • LDAP • ということは、Hadoopクラスタのすべてのマシンは同じUser/Groupを 持っている必要がある! • このへんでActive DirectoryやOpenLDAPが必要になってくる。
59.
Page 59 ©
Hortonworks Inc. 2014 User/Groupを統⼀管理するためのツール Open Source: • SSSD • pam_ldap/pam_kerberos Commercial: • Centrify • QAS
60.
Page 60 ©
Hortonworks Inc. 2014 Delegation Token/Block Access Token • MapReduceやTezなど、ひとつのジョブで複数回のNameNodeへのアクセ スを要求するようなアプリケーションの場合は、毎回Kerberos認証を⾏う 代わりに、NameNodeがDelegation Tokenというものを払い出し、2回め 以降のアクセスにはこれを使うことができる。 • これを使うか使わないかはアプリケーションの実装に依存。 • 更にDataNodeのBlockに対するオペレーションについてはNameNodeが Block Access Tokenというブロックへのアクセス認証Tokenを払い出す。
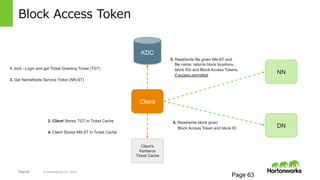
61.
Page 61 ©
Hortonworks Inc. 2014 Block Access Token Page 61 Client KDC NN DN 1. kinit - Login and get Ticket Granting Ticket (TGT) 3. Get NameNode Service Ticket (NN-ST) 2. Client Stores TGT in Ticket Cache 4. Client Stores NN-ST in Ticket Cache 5. Read/write file given NN-ST and file name; returns block locations, block IDs and Block Access Tokens if access permitted 6. Read/write block given Block Access Token and block ID Client’s Kerberos Ticket Cache
62.
Page 62 ©
Hortonworks Inc. 2014 Impersonation • User名の解決はUPNをauth_to_localしたものが利⽤される。 • しかし、場合によっては別のユーザーとしてジョブを実⾏したい場合もある。 • 例: Oozieのようなスケジューラはoozieユーザーでスケジューリングをしつ つ、実際のジョブはyutaやadmin、もしくはhdfs、yarnなどで実⾏したい。 • これを実現してくれるのがImpersonation(物真似、なりすまし)。 • 利⽤するかどうかはアプリケーション側に依存。 • Proxy, Proxy Userとも呼ばれる。設定項⽬ • hadoop.proxyuser.${user}.groups <- ${user}がimpersonateできるgroup • hadoop.proxyuser.${user}.hosts <- ${user}がimpersonateできるhost
63.
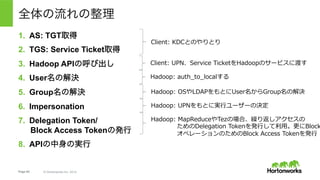
Page 63 ©
Hortonworks Inc. 2014 全体の流れの整理 1. AS: TGT取得 2. Hadoop APIの呼び出し 3. TGS: Service Ticket取得 4. User名の解決 5. Group名の解決 6. Delegation Token/ Block Access Tokenの発行 7. Impersonation 8. APIの中身の実行 Client: KDCとのやりとり Client: UPN、TGT、Service TicketをHadoopのサービスに渡す Hadoop: auth_to_localする Hadoop: OSやLDAPをもとにUser名からGroup名の解決 Hadoop: UPNをもとに実⾏ユーザーの決定 Hadoop: MapReduceやTezの場合、繰り返しアクセスの ためのDelegation Tokenを発⾏して利⽤。更にBlock オペレーションのためのBlock Access Tokenを発⾏ Hadoop: TGTを使ってSTを取得 ※実際のHadoopの実装ではSTはClientではなくHadoopが要求
64.
Page 64 ©
Hortonworks Inc. 2014 まとめ • YARNによってHadoopのマルチテナント化が進んでいる • 認証、認可、監査、暗号化の4点と統合された管理、が考えるべ きセキュリティの柱。 • 認可、監査、暗号化(の鍵管理)はいずれも「正しい認証」に依 存する。 • Hadoopは認証にKerberosを採⽤している。 • Kerberosの利⽤⾃体はクラスタマネージャを使えば容易。 • ただしKerberosとHadoopの組み合わせはとても複雑。 • 理解しておくと、うれしいことがあるかも・・・?笑
65.
Page 65 ©
Hortonworks Inc. 2014 プレゼントが当たる抽選やってます! and, of course,We are hiring! ご興味ある方はぜひ声をかけてね。 • 特等賞(1名様) – Bose QuietComfort 20 ノイズキャンセリングヘッドホン • Hortonworks賞(20名様) – Hortonworksロゴ入りソックス • Hadoop賞(参加者全員) – Hortonworksステッカー ※応募時に名刺を1枚頂きます。後日、弊社より様々な情報をお送りさせていただく場合があります。ご了承下さい。 ※Bose QuietComfort 20は後日発送いたします。
66.
Page 66 ©
Hortonworks Inc. 2014 Field Notes: Kerberos (AD or MIT KDC) Challenges: • HDP requires several SPNs (typically 3-5 per datanode) • Most AD admins are not happy with that Recommendations: a) Integrate directly with Active Directory i) At >100 nodes, provide dedicated AD replica for the cluster b) MIT KDC in the cluster for SPNs. Cross-realm trust to AD for UPNs (users) Note on Users/Groups: • Users/Groups from your directoy should exist in the Hadoop nodes • Common implementations: SSSD, Centrify, VAS
Download




































s/.*/ambari-qa/
RULE:[1:$1@$0](hbase-HDP1@HORTONWORKS.LOCAL)s/.*/hbase/
RULE:[1:$1@$0](hdfs-HDP1@HORTONWORKS.LOCAL)s/.*/hdfs/
RULE:[1:$1@$0](.*@HORTONWORKS.LOCAL)s/@.*//
RULE:[2:$1@$0](amshbase@HORTONWORKS.LOCAL)s/.*/ams/
RULE:[2:$1@$0](amszk@HORTONWORKS.LOCAL)s/.*/ams/
RULE:[2:$1@$0](dn@HORTONWORKS.LOCAL)s/.*/hdfs/
RULE:[2:$1@$0](hbase@HORTONWORKS.LOCAL)s/.*/hbase/
RULE:[2:$1@$0](hive@HORTONWORKS.LOCAL)s/.*/hive/](https://image.slidesharecdn.com/hadooppluskerberos-160208144651/85/Hadoop-and-Kerberos-57-320.jpg)











![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)









































































