Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Yuta Imai
PPTX, PDF
6,904 views
クラウドネイティブなアーキテクチャでサクサク解析
発表資料@ 第27回 データマイニング+WEB@東京( #TokyoWebmining 27th) -WEB解析・オープンデータ・クラウド 祭り-
Technology
◦
Read more
14
Save
Share
Embed
Embed presentation
Download
Downloaded 33 times
1
/ 54
2
/ 54
3
/ 54
4
/ 54
5
/ 54
6
/ 54
7
/ 54
8
/ 54
9
/ 54
10
/ 54
11
/ 54
12
/ 54
13
/ 54
14
/ 54
15
/ 54
16
/ 54
17
/ 54
18
/ 54
19
/ 54
20
/ 54
21
/ 54
22
/ 54
23
/ 54
24
/ 54
25
/ 54
26
/ 54
27
/ 54
28
/ 54
29
/ 54
30
/ 54
31
/ 54
32
/ 54
33
/ 54
34
/ 54
35
/ 54
36
/ 54
37
/ 54
38
/ 54
39
/ 54
40
/ 54
41
/ 54
42
/ 54
43
/ 54
44
/ 54
45
/ 54
46
/ 54
47
/ 54
48
/ 54
49
/ 54
50
/ 54
51
/ 54
52
/ 54
53
/ 54
54
/ 54
More Related Content
PDF
クラウド・アプリケーションの作り方
by
Tomoharu ASAMI
PPTX
クラウドネイティブが行なういまどきWebサービス開発
by
Yuuji Arakaki
PDF
AWSで実現するクラウドネイティブなアプリ開発のポイント
by
Keisuke Nishitani
PDF
AWSにおける モバイル向けサービス及び事例紹介(20151211)
by
Keisuke Nishitani
PDF
UnityとAmazon Web Servicesで生み出す新しい価値
by
Keisuke Nishitani
PDF
Introducing Serverless Computing (20160802)
by
Keisuke Nishitani
PDF
クラウド時代のソフトウェアアーキテクチャ
by
Keisuke Nishitani
PDF
クラウドネイティブ化する未来
by
Keisuke Nishitani
クラウド・アプリケーションの作り方
by
Tomoharu ASAMI
クラウドネイティブが行なういまどきWebサービス開発
by
Yuuji Arakaki
AWSで実現するクラウドネイティブなアプリ開発のポイント
by
Keisuke Nishitani
AWSにおける モバイル向けサービス及び事例紹介(20151211)
by
Keisuke Nishitani
UnityとAmazon Web Servicesで生み出す新しい価値
by
Keisuke Nishitani
Introducing Serverless Computing (20160802)
by
Keisuke Nishitani
クラウド時代のソフトウェアアーキテクチャ
by
Keisuke Nishitani
クラウドネイティブ化する未来
by
Keisuke Nishitani
What's hot
PDF
Serverless Architecture on AWS(20151121版)
by
Keisuke Nishitani
PDF
AWS クラウドで構築するスマホアプリ バックエンド
by
kaki_k
PDF
Serverless Revolution
by
Keisuke Nishitani
PDF
Scale Your Business without Servers
by
Keisuke Nishitani
PDF
プログラマに贈るクラウドとの上手な付き合い方
by
Keisuke Nishitani
PDF
モバイル開発者から見た サーバーレスアーキテクチャ
by
Takaaki Tanaka
PDF
IoTデザインパターン 2015 JAWS沖縄
by
Toshiaki Enami
PDF
AWS Introduction for Startups
by
akitsukada
PDF
Big DataとContainerとStream - AWSでのクラスタ構成とストリーム処理 -
by
Amazon Web Services Japan
PDF
Amazon Cognito Deep Dive @ JAWS DAYS 2016
by
akitsukada
PPTX
AWS & Google Cloudを使ったシステム開発/技術選定のはなし
by
修一 高橋
PDF
5分でわかるAWS IoT! - あなたも今日からIoT生活 -
by
Toshiaki Enami
PDF
iOSアプリ開発者から見たMobile Hub
by
Jun Kato
PDF
Automated Testing on AWS Device Farm
by
Keisuke Nishitani
PDF
モバイル開発を支えるAWS Mobile Services
by
Keisuke Nishitani
PDF
JAWSDAYS2017 新訳 とあるアーキテクトのクラウドデザインパターン目録 AMI Maintenance Environment
by
Jin k
PPTX
成長していくサービスとAWS
by
Mitsuharu Hamba
PDF
Serverless Architecture on AWS(20151023版)
by
Keisuke Nishitani
PDF
Serverless Architecture on AWS (20151201版)
by
Keisuke Nishitani
PDF
AWS Lambda / Amazon API Gateway Deep Dive
by
Keisuke Nishitani
Serverless Architecture on AWS(20151121版)
by
Keisuke Nishitani
AWS クラウドで構築するスマホアプリ バックエンド
by
kaki_k
Serverless Revolution
by
Keisuke Nishitani
Scale Your Business without Servers
by
Keisuke Nishitani
プログラマに贈るクラウドとの上手な付き合い方
by
Keisuke Nishitani
モバイル開発者から見た サーバーレスアーキテクチャ
by
Takaaki Tanaka
IoTデザインパターン 2015 JAWS沖縄
by
Toshiaki Enami
AWS Introduction for Startups
by
akitsukada
Big DataとContainerとStream - AWSでのクラスタ構成とストリーム処理 -
by
Amazon Web Services Japan
Amazon Cognito Deep Dive @ JAWS DAYS 2016
by
akitsukada
AWS & Google Cloudを使ったシステム開発/技術選定のはなし
by
修一 高橋
5分でわかるAWS IoT! - あなたも今日からIoT生活 -
by
Toshiaki Enami
iOSアプリ開発者から見たMobile Hub
by
Jun Kato
Automated Testing on AWS Device Farm
by
Keisuke Nishitani
モバイル開発を支えるAWS Mobile Services
by
Keisuke Nishitani
JAWSDAYS2017 新訳 とあるアーキテクトのクラウドデザインパターン目録 AMI Maintenance Environment
by
Jin k
成長していくサービスとAWS
by
Mitsuharu Hamba
Serverless Architecture on AWS(20151023版)
by
Keisuke Nishitani
Serverless Architecture on AWS (20151201版)
by
Keisuke Nishitani
AWS Lambda / Amazon API Gateway Deep Dive
by
Keisuke Nishitani
Viewers also liked
PDF
大規模ログ分析におけるAmazon Web Servicesの活用
by
Shintaro Takemura
PDF
オープンデータ・パーソナルデータビジネス最前線
by
直之 伊藤
PDF
サイト/ブログから本文抽出する方法
by
Takuro Sasaki
PPTX
Webクローリング&スクレイピングの最前線 公開用
by
Lumin Hacker
PDF
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京
by
Koichi Hamada
PDF
Objective Front-End JavaScript
by
Muyuu Fujita
PDF
Js祭り
by
Yoshihiko Hoshino
PDF
Svgアニメーションを実装してみよう 20150207
by
Kanako Kobayashi
PPT
BuddyPressで街のポータルサイトを作ろう
by
松田 千尋
PPTX
Webスクレイピング用の言語っぽいものを作ったよ
by
Takaichi Ito
PDF
頑張らないクラウド最適化 〜クラウドネイティブだけでないAWS活用〜
by
宗 大栗
PDF
20141022 リサーチ向け・ブラウザだけでスクレイピング(浅野)
by
Hirosuke Asano
PPTX
ソーシャル・スクレイピング(2014年10月Webスクレイピング勉強会資料)
by
yuzoakakura
PPTX
第3回Webスクレイピング勉強会@東京 happyou.info
by
Shogo Okamoto
PDF
JAWS-UG 東京 #25 CLI専門支部紹介
by
Nobuhiro Nakayama
PDF
Scraping withawsAWSを利用してスクレイピングの悩みを解決するチップス
by
Takuro Sasaki
PDF
React.jsでHowManyPizza
by
松田 千尋
PDF
JAWS-UG アーキテクチャ専門支部(ハイブリッド分科会) #9 EC2 Run Commnadのいいところ
by
Nobuhiro Nakayama
PDF
サービス改善はログデータ分析から
by
Kenta Suzuki
PDF
アポ前15分で詰め込む!ログ解析
by
CAPS Association, Inc.
大規模ログ分析におけるAmazon Web Servicesの活用
by
Shintaro Takemura
オープンデータ・パーソナルデータビジネス最前線
by
直之 伊藤
サイト/ブログから本文抽出する方法
by
Takuro Sasaki
Webクローリング&スクレイピングの最前線 公開用
by
Lumin Hacker
オープニングトーク - 創設の思い・目的・進行方針 -データマイニング+WEB勉強会@東京
by
Koichi Hamada
Objective Front-End JavaScript
by
Muyuu Fujita
Js祭り
by
Yoshihiko Hoshino
Svgアニメーションを実装してみよう 20150207
by
Kanako Kobayashi
BuddyPressで街のポータルサイトを作ろう
by
松田 千尋
Webスクレイピング用の言語っぽいものを作ったよ
by
Takaichi Ito
頑張らないクラウド最適化 〜クラウドネイティブだけでないAWS活用〜
by
宗 大栗
20141022 リサーチ向け・ブラウザだけでスクレイピング(浅野)
by
Hirosuke Asano
ソーシャル・スクレイピング(2014年10月Webスクレイピング勉強会資料)
by
yuzoakakura
第3回Webスクレイピング勉強会@東京 happyou.info
by
Shogo Okamoto
JAWS-UG 東京 #25 CLI専門支部紹介
by
Nobuhiro Nakayama
Scraping withawsAWSを利用してスクレイピングの悩みを解決するチップス
by
Takuro Sasaki
React.jsでHowManyPizza
by
松田 千尋
JAWS-UG アーキテクチャ専門支部(ハイブリッド分科会) #9 EC2 Run Commnadのいいところ
by
Nobuhiro Nakayama
サービス改善はログデータ分析から
by
Kenta Suzuki
アポ前15分で詰め込む!ログ解析
by
CAPS Association, Inc.
Similar to クラウドネイティブなアーキテクチャでサクサク解析
PDF
AWSが誕生するまでの秘話
by
Yasuhiro Horiuchi
PDF
CloudFrontのリアルタイムログをKibanaで可視化しよう
by
Eiji KOMINAMI
PDF
Lt4 aws@loft #11 aws io-t for smart building
by
Amazon Web Services Japan
PDF
1000人規模で使う分析基盤構築 〜redshiftを活用したeuc
by
Kazuhiro Miyajima
PDF
AWS サービスアップデートまとめ 2014年7月
by
Yasuhiro Horiuchi
PDF
データ投入からインサイトまで、簡単になったインフラ監視
by
Elasticsearch
PPTX
アーキテクトが主導するコンテナ/マイクロサービス/サーバーレスのセキュリティ
by
Eiji Sasahara, Ph.D., MBA 笹原英司
PDF
AWSの様々なアーキテクチャ
by
Kameda Harunobu
PDF
JAWS DAYS 2015
by
陽平 山口
PPTX
いまさら聞けない Amazon EC2
by
Yasuhiro Matsuo
PDF
Aws summits2014 エンタープライズ向けawscdpネットワーク編
by
Boss4434
PDF
PCCC23:日本オラクル株式会社 テーマ1「OCIのHPC基盤技術と生成AI」
by
PC Cluster Consortium
PDF
Azure and cloud native approach.v0.6.19.0807
by
Ayumu Inaba
PDF
デフォルトAWS時代にインフラエンジニアはどう向き合うべきか?
by
Yasuhiro Horiuchi
PPT
アマゾンクラウドの真価
by
kaminashi
PPTX
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
PDF
AWS Black Belt Online Seminar 2017 IoT向け最新アーキテクチャパターン
by
Amazon Web Services Japan
PDF
01 citynet awsセミナー_awsを簡単にご紹介
by
充博 大崎
PDF
01 にしうち awsを簡単にご紹介_001
by
充博 大崎
PDF
Aws summit tokyo 2016
by
Shotaro Motomura
AWSが誕生するまでの秘話
by
Yasuhiro Horiuchi
CloudFrontのリアルタイムログをKibanaで可視化しよう
by
Eiji KOMINAMI
Lt4 aws@loft #11 aws io-t for smart building
by
Amazon Web Services Japan
1000人規模で使う分析基盤構築 〜redshiftを活用したeuc
by
Kazuhiro Miyajima
AWS サービスアップデートまとめ 2014年7月
by
Yasuhiro Horiuchi
データ投入からインサイトまで、簡単になったインフラ監視
by
Elasticsearch
アーキテクトが主導するコンテナ/マイクロサービス/サーバーレスのセキュリティ
by
Eiji Sasahara, Ph.D., MBA 笹原英司
AWSの様々なアーキテクチャ
by
Kameda Harunobu
JAWS DAYS 2015
by
陽平 山口
いまさら聞けない Amazon EC2
by
Yasuhiro Matsuo
Aws summits2014 エンタープライズ向けawscdpネットワーク編
by
Boss4434
PCCC23:日本オラクル株式会社 テーマ1「OCIのHPC基盤技術と生成AI」
by
PC Cluster Consortium
Azure and cloud native approach.v0.6.19.0807
by
Ayumu Inaba
デフォルトAWS時代にインフラエンジニアはどう向き合うべきか?
by
Yasuhiro Horiuchi
アマゾンクラウドの真価
by
kaminashi
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
AWS Black Belt Online Seminar 2017 IoT向け最新アーキテクチャパターン
by
Amazon Web Services Japan
01 citynet awsセミナー_awsを簡単にご紹介
by
充博 大崎
01 にしうち awsを簡単にご紹介_001
by
充博 大崎
Aws summit tokyo 2016
by
Shotaro Motomura
More from Yuta Imai
PPTX
Node-RED on device to Apache NiFi on cloud, via SORACOM Canal, with no Internet
by
Yuta Imai
PDF
HDP2.5 Updates
by
Yuta Imai
PDF
Deep Learning On Apache Spark
by
Yuta Imai
PDF
Hadoop in adtech
by
Yuta Imai
PDF
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
PDF
IoTアプリケーションで利用するApache NiFi
by
Yuta Imai
PDF
OLAP options on Hadoop
by
Yuta Imai
PDF
Apache ambari
by
Yuta Imai
PDF
Spark at Scale
by
Yuta Imai
PDF
Dynamic Resource Allocation in Apache Spark
by
Yuta Imai
PDF
Apache Hiveの今とこれから - 2016
by
Yuta Imai
PDF
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
PDF
Benchmark and Metrics
by
Yuta Imai
PDF
Hadoop and Kerberos
by
Yuta Imai
PDF
Spark Streaming + Amazon Kinesis
by
Yuta Imai
PDF
オンラインゲームの仕組みと工夫
by
Yuta Imai
PDF
Amazon Machine Learning
by
Yuta Imai
PDF
Global Gaming On AWS
by
Yuta Imai
PDF
Digital marketing on AWS
by
Yuta Imai
PDF
EC2のストレージどう使う? -Instance Storageを理解して高速IOを上手に活用!-
by
Yuta Imai
Node-RED on device to Apache NiFi on cloud, via SORACOM Canal, with no Internet
by
Yuta Imai
HDP2.5 Updates
by
Yuta Imai
Deep Learning On Apache Spark
by
Yuta Imai
Hadoop in adtech
by
Yuta Imai
Hadoop/Spark セルフサービス系の事例まとめ
by
Yuta Imai
IoTアプリケーションで利用するApache NiFi
by
Yuta Imai
OLAP options on Hadoop
by
Yuta Imai
Apache ambari
by
Yuta Imai
Spark at Scale
by
Yuta Imai
Dynamic Resource Allocation in Apache Spark
by
Yuta Imai
Apache Hiveの今とこれから - 2016
by
Yuta Imai
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
Benchmark and Metrics
by
Yuta Imai
Hadoop and Kerberos
by
Yuta Imai
Spark Streaming + Amazon Kinesis
by
Yuta Imai
オンラインゲームの仕組みと工夫
by
Yuta Imai
Amazon Machine Learning
by
Yuta Imai
Global Gaming On AWS
by
Yuta Imai
Digital marketing on AWS
by
Yuta Imai
EC2のストレージどう使う? -Instance Storageを理解して高速IOを上手に活用!-
by
Yuta Imai
クラウドネイティブなアーキテクチャでサクサク解析
1.
クラウドネイティブな アーキテクチャでサクサク解析 @imai_factory 第27回 データマイニング+WEB @東京
( #TokyoWebmining 27th)
2.
自己紹介 • 名前 – 今井雄太(
@imai_factory ) • 仕事 – ソリューションアーキテクトという仕事をし ていて、主にアド、デジタルマーケティン グ、スタートアップのお客様のアーキテク ティングのお手伝いをしています。 2
3.
今日のアジェンダ • Amazon流のAWSの使い方 • クラウドネイティブなアーキテク チャとは? •
AWS上でデータ解析を行うために理 解しておくべきコンセプト 3
4.
Amazon流 AWSの使い方
5.
5 Werner Vogels CTO of
Amazon.com
6.
平均11.6秒ごとにデプロイ 1時間で最大1,079回のデプロイ 1回で平均1万台のホストへデプロイ 最大で3万台のホストへ同時にデプロイ
7.
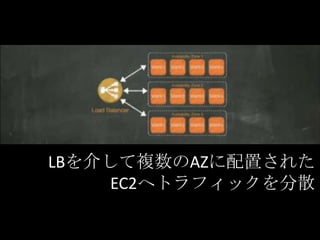
LBを介して複数のAZに配置された EC2へトラフィックを分散
8.
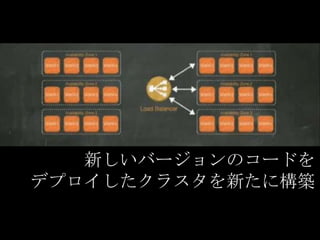
新しいバージョンのコードを デプロイしたクラスタを新たに構築
9.
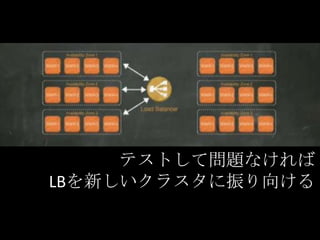
テストして問題なければ LBを新しいクラスタに振り向ける
10.
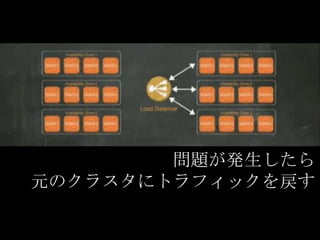
問題が発生したら 元のクラスタにトラフィックを戻す
11.
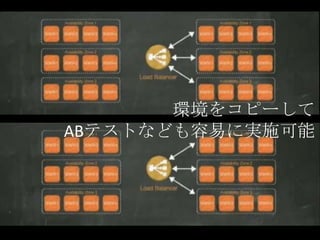
環境をコピーして ABテストなども容易に実施可能
12.
12 デプロイのスピードが早く て、リスクも少ないと フィードバックループを より多く回せる
13.
クラウドネイティブな アーキテクチャ
14.
14 Controllable - 柔軟なコントロール Resilient
- 高い耐障害性 Adaptive - 状況の変化への追従性 Data Driven - フィードバックループを回す
15.
15 Controllable 柔軟なコントロール
16.
柔軟なコントロール • システムを小さなコンポーネ ントにわけて疎結合に • 常にコストを意識したアーキ テクチャを 16
17.
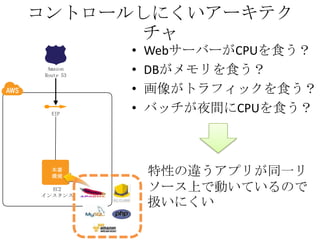
コントロールしにくいアーキテク チャ • WebサーバーがCPUを食う? • DBがメモリを食う? •
画像がトラフィックを食う? • バッチが夜間にCPUを食う? EC2 インスタンス 本番 環境 Amazon Route 53 EIP 特性の違うアプリが同一リ ソース上で動いているので 扱いにくい
18.
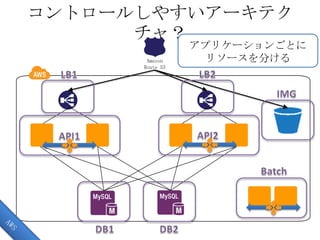
コントロールしやすいアーキテク チャ? Amazon Route 53 アプリケーションごとに リソースを分ける
19.
USD0/ hr USD17/ hr USD35/
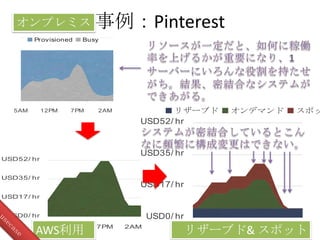
hr USD52/ hr 5AM 12PM 7PM 2AM USD0/ hr USD17/ hr USD35/ hr USD52/ hr 5AM 12PM 7PM 2AM リザーブド オンデマンド スポッ 事例:Pinterest 19 5AM 12PM 7PM 2AM Provisioned Busy AWS利用 リザーブド& スポット オンプレミス
20.
コンポーネントを小さくわける と・・ • 各コンポーネントごとに適切なス ケーリングが可能なので無駄が出に くい • スケールするときに他のコンポーネ ントとの兼ね合いを気にする必要が ないので要求に迅速に対応できる 20
21.
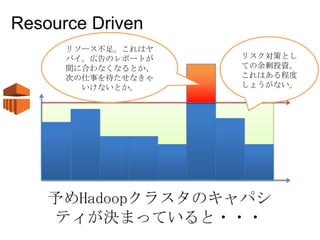
21 Resilient 高い耐障害性
22.
高い耐障害性 • 障害を例外として捉えない • 障害が起こる前提でシステム を考える 22
23.
事例:S3(Simple Storage Service) 23
24.
NetFlixにはいたずらな猿たち が・・ 24
25.
25 Adaptive 状況変化への追従性
26.
状況変化への追従性 • 何も仮定しない • キャパシティプランニングは 後から精緻にすればよい 26
27.
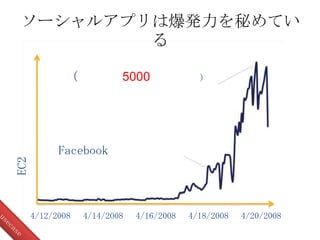
EC2 4/12/2008 Facebook ( 5000 ) 4/14/2008
4/16/2008 4/18/2008 4/20/2008 ソーシャルアプリは爆発力を秘めてい る
28.
AWSなら • スモールスタートはもちろん • ラージスタートもできる 28
29.
Data Driven フィードバックループを回 す
30.
フィードバックループを回す • すべての事象をロギングする • データはリアルタイム性が高 いほど価値が高くなる •
フィードバックループは小さ く 30
31.
31 Controllable - 柔軟なコントロール Resilient
- 高い耐障害性 Adaptive - 状況の変化への追従性 Data Driven - フィードバックループを回す
32.
AWS上で データ解析を行うために 理解しておくべきコンセプト
33.
AWSで解析や計算を行う際に メリットを最大限にレバ レッジするための3つのコ ンセプト 1. Data First 2.
AWS is software 3. Workflow driven 33
34.
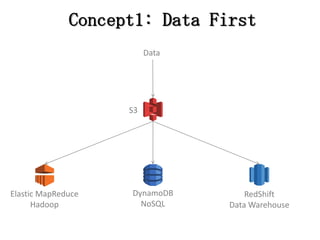
Concept1: Data First
35.
S3: Simple Storage
Service • AWSの最初のサービスのひと つ。(もうひとつはSQS) • データの堅牢性が高く、格納 容量に制限がないのが大きな 特徴。 • 様々な他のAWSサービスから も利用されている。 35 Storage
36.
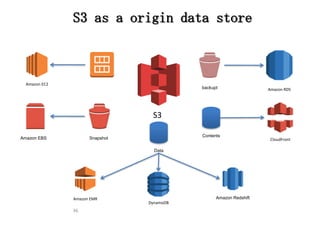
36 S3 S3 as a
origin data store Amazon RDS SnapshotAmazon EBS Amazon EC2 DynamoDB Amazon EMR Amazon Redshift backupt Data CloudFront Contents
37.
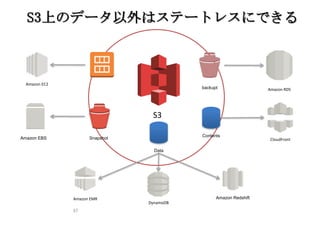
37 S3 S3上のデータ以外はステートレスにできる Amazon RDS SnapshotAmazon EBS Amazon
EC2 DynamoDB Amazon EMR Amazon Redshift backupt Data CloudFront Contents
38.
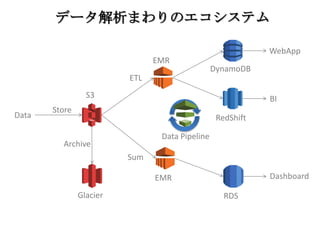
Glacier RDS EMR EMR RedShift DynamoDB Data Pipeline S3 Data ETL Sum WebApp BI Dashboard データ解析まわりのエコシステム Store Archive
39.
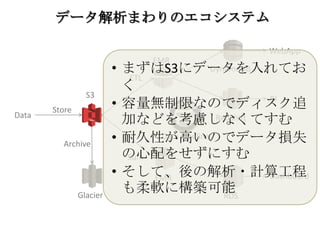
Glacier RDS EMR EMR RedShift DynamoDB Data Pipeline S3 Data ETL Sum WebApp BI Dashboard データ解析まわりのエコシステム Store Archive •
まずはS3にデータを入れてお く • 容量無制限なのでディスク追 加などを考慮しなくてすむ • 耐久性が高いのでデータ損失 の心配をせずにすむ • そして、後の解析・計算工程 も柔軟に構築可能
40.
RedShift Data Warehouse DynamoDB NoSQL S3 Data Elastic MapReduce Hadoop Concept1:
Data First
41.
Concept2: AWS is software
42.
42 AWSは様々な リソースやアプリケーショ ンを提供してくれます が・・
43.
43 すべてソフトウェアとして 扱える コントロール
44.
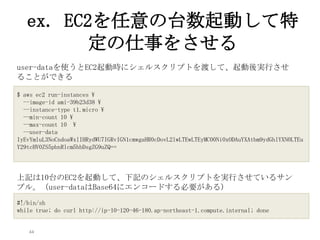
44 ex. EC2を任意の台数起動して特 定の仕事をさせる $ aws
ec2 run-instances --image-id ami-39b23d38 --instance-type t1.micro --min-count 10 --max-count 10 --user-data IyEvYmluL3NoCndoaWxlIHRydWU7IGRvIGN1cmwgaHR0cDovL2lwLTEwLTEyMC00Ni0xODAuYXAtbm9ydGhlYXN0LTEu Y29tcHV0ZS5pbnRlcm5hbDsgZG9uZQ== #!/bin/sh while true; do curl http://ip-10-120-46-180.ap-northeast-1.compute.internal; done user-dataを使うとEC2起動時にシェルスクリプトを渡して、起動後実行させ ることができる 上記は10台のEC2を起動して、下記のシェルスクリプトを実行させているサン プル。(user-dataはBase64にエンコードする必要がある)
45.
45 ex. Hadoopクラスタを立ちあげて特定の仕 事をさせて終わったらクラスタを捨てる $ elastic-mapreduce
--create --stream --num-instances 4 --slave-instance-type m1.large --master-instance-type m2.4xlarge --input s3://YOUR_INPUT_BUCKET --output s3://YOUR_OUTPUT_BUCKET --mapper s3://YOUR_MAPPER_PROGRAM_FILE --reducer s3://YOUR_REDUCER_PROGRAM_FILE Elastic MapReduceでは下記のように仕事の内容(streamingのmapperと reducerを指定)と、データのin/outを指定してクラスタを起動することによ り、クラスタ起動->ジョブを処理->クラスタを破棄 というパイプラインを 自動化できる 上記はElastic MapReduceのコマンドラインクライアントから実施している が、APIやSDK経由でも実行可能。
46.
46 AWSはソフトェアなので自動 化が容易 SSHやRDPしたら負け (本番環境の話。笑) Concept2: AWS is
software
47.
Concept3: Workload driven
48.
Resource Driven リスク対策とし ての余剰投資。 これはある程度 しょうがない。 リソース不足。これはヤ バイ。広告のレポートが 間に合わなくなるとか、 次の仕事を待たせなきゃ いけないとか。 予めHadoopクラスタのキャパシ ティが決まっていると・・・
49.
49 もちろんResource Drivenが 最適な環境もありますが、 クラウドを利用すると・・
50.
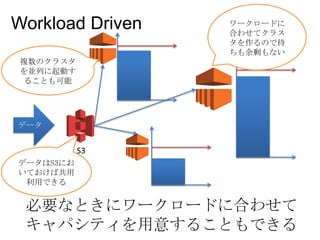
S3 データ Workload Driven 必要なときにワークロードに合わせて キャパシティを用意することもできる ワークロードに 合わせてクラス タを作るので待 ちも余剰もない 複数のクラスタ を並列に起動す ることも可能 データはS3にお いておけば共用 利用できる
51.
51 AWSでは時間とリソースが等 価交換できる。 S3にデータがあれば複数の クラスタから共有資源とし て利用できる。 Concept3: Workflow Driven
52.
まとめ
53.
フィードバックループを回す • クラウド外のアーキテクチャをそ のままクラウド上で再現してもあ まりメリットがない • Hadoop
、SQL等使われる技術のコ ンセプトは変わらない。 • 変わるのはインフラに対しての考 え方。より柔軟に。 53
Download