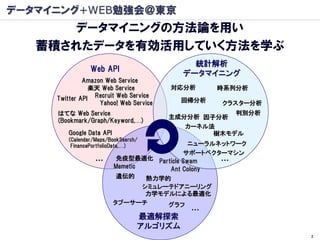
データマイニング+WEB勉強会@東京
データマイニングの方法論を用い
蓄積されたデータを有効活用していく方法を学ぶ
統計解析
Web API
データマイニング
Amazon Web Service
楽天 Web Service 対応分析 時系列分析
Twitter API Recruit Web Service 回帰分析
Yahoo! Web Service クラスター分析
はてな Web Service 判別分析
主成分分析 因子分析
(Bookmark/Graph/Keyword,…)
カーネル法
Google Data API 樹木モデル
(Calendar/Maps/BookSearch/
FinancePortfolioData,…) ニューラルネットワーク
サポートベクターマシン
… 免疫型最適化 Particle Swam …
Memetic Ant Colony
遺伝的 熱力学的
シミュレーテドアニーリング
力学モデルによる最適化
タブーサーチ グラフ
…
最適解探索
アルゴリズム
2
3.
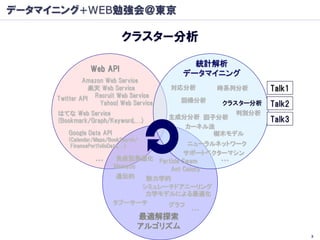
データマイニング+WEB勉強会@東京
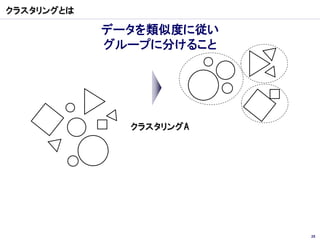
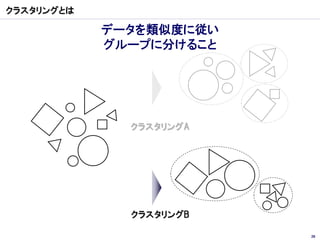
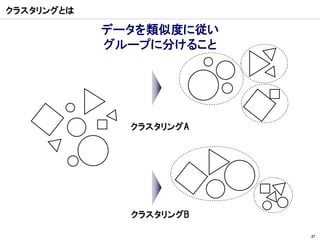
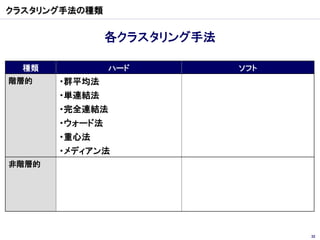
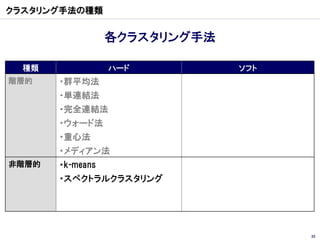
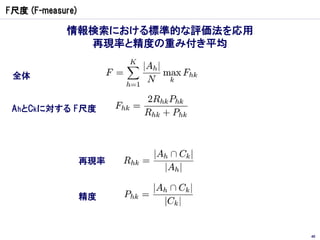
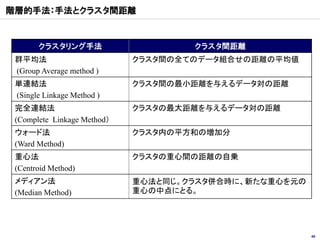
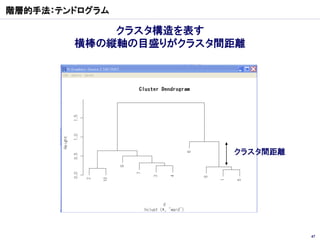
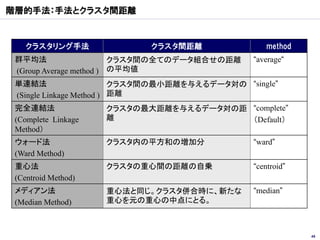
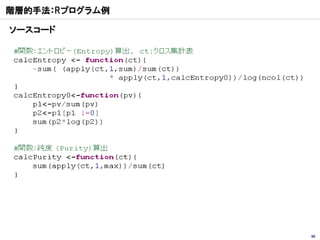
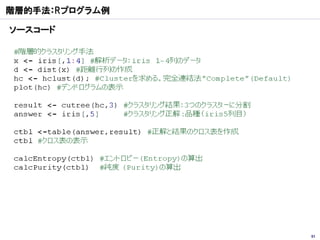
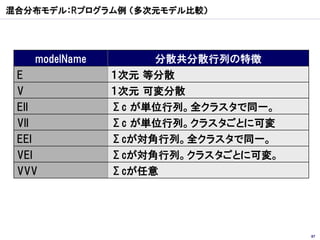
クラスター分析
統計解析
Web API
データマイニング
Amazon Web Service
楽天 Web Service 対応分析 時系列分析 Talk1
Twitter API Recruit Web Service 回帰分析
Yahoo! Web Service クラスター分析 Talk2
はてな Web Service 判別分析
主成分分析 因子分析 Talk3
(Bookmark/Graph/Keyword,…)
カーネル法
Google Data API 樹木モデル
(Calendar/Maps/BookSearch/
FinancePortfolioData,…) ニューラルネットワーク
サポートベクターマシン
… 免疫型最適化 Particle Swam …
Memetic Ant Colony
遺伝的 熱力学的
シミュレーテドアニーリング
力学モデルによる最適化
タブーサーチ グラフ
…
最適解探索
アルゴリズム
3
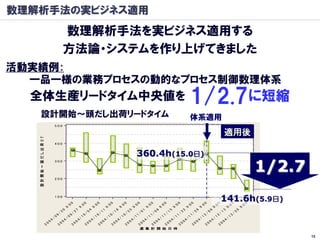
数理解析手法の実ビジネス適用
数理解析手法を実ビジネス適用する
方法論・システムを作り上げてきました
主な領域
◆活動の数理モデル化・解析手法
◆業務プロセス分析手法・再構築手法
◆業務プロセス実行制御・実績解析システム
…
K. Hamada, F.Kimura,
M.Nakao, N. Kobayashi, K.Hamada, T.Totsuka, S.Yamada,
"Unified graph representation of processes
“Decoupling Executions in Navigating Manufacturing
for scheduling with flexible resource
Processes for Shortening Lead Time and Its Implementation
assignment",
to an Unmanned Machine Shop”,
to be published in CIRP ICMS (2010).
CIRP Annals - Manufacturing Technology Volume 56, Issue 1,
Pages 171-174 (2007) 14
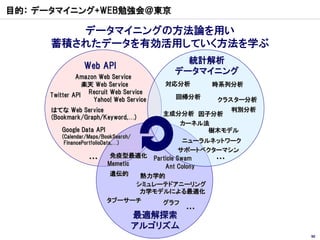
目的: データマイニング+WEB勉強会@東京
データマイニングの方法論を用い
蓄積されたデータを有効活用していく方法を学ぶ
統計解析
Web API
データマイニング
Amazon Web Service
楽天 Web Service 対応分析 時系列分析
Twitter API Recruit Web Service 回帰分析
Yahoo! Web Service クラスター分析
はてな Web Service 判別分析
主成分分析 因子分析
(Bookmark/Graph/Keyword,…)
カーネル法
Google Data API 樹木モデル
(Calendar/Maps/BookSearch/
FinancePortfolioData,…) ニューラルネットワーク
サポートベクターマシン
… 免疫型最適化 Particle Swam …
Memetic Ant Colony
遺伝的 熱力学的
シミュレーテドアニーリング
力学モデルによる最適化
タブーサーチ グラフ
…
最適解探索
アルゴリズム
98





































































![心理学者のためのJASP入門(操作編)[説明文をよんでください]](https://cdn.slidesharecdn.com/ss_thumbnails/test-180307053956-thumbnail.jpg?width=640&height=640&fit=bounds)































![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる R言語によるクラスター分析 - 似ているものをグループ化する-](https://cdn.slidesharecdn.com/ss_thumbnails/webmining2cluster-100319212743-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[R勉強会][データマイニング] R言語による時系列分析](https://cdn.slidesharecdn.com/ss_thumbnails/r-100423232629-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[データマイニング+WEB勉強会][R勉強会] 創設の思い・目的・進行方針](https://cdn.slidesharecdn.com/ss_thumbnails/opeining-100416225629-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[R勉強会][データマイニング] プロセス・リソース・グラフと数理統計解析](https://cdn.slidesharecdn.com/ss_thumbnails/tmpok-100326232112-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































