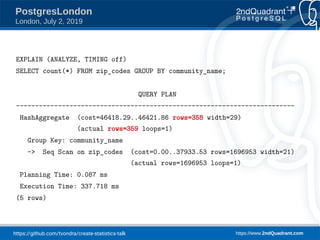
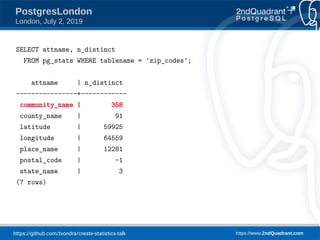
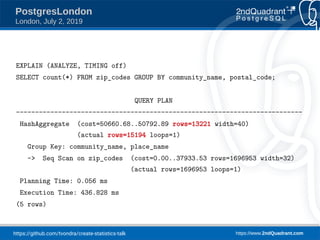
This document presents a talk by Tomas Vondra on creating statistics in PostgreSQL, focusing on estimation improvements for queries involving correlated columns. It includes practical examples using a 'zip_codes' table to analyze functional dependencies and present various query plans demonstrating the effective use of statistics for better database performance. The presentation outlines plans for future improvements and the pitfalls of not respecting functional dependencies in query optimization.



















![https://github.com/tvondra/create-statistics-talk https://www.2ndQuadrant.com
PostgresLondon
London, July 2, 2019
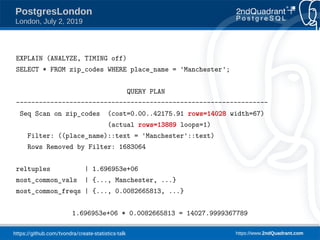
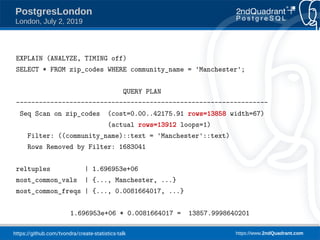
place → community: 0.697633 = d
P(place = 'Manchester' & community = 'Manchester') =
P(place = 'Manchester') * [d + (1-d) * P(community = 'Manchester')]
1.696953e+06 * 0.008266581 * (0.697633 + (1.0 - 0.697633) * 0.0081664017)
= 9281.03](https://image.slidesharecdn.com/create-statistics-what-is-it-190702090147/85/CREATE-STATISTICS-What-is-it-for-PostgresLondon-21-320.jpg)













![[TechPlayConf]Rekognition導入事例](https://cdn.slidesharecdn.com/ss_thumbnails/techplayconfrekognition-170820072435-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)











