Downloaded 131 times




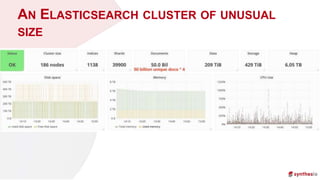



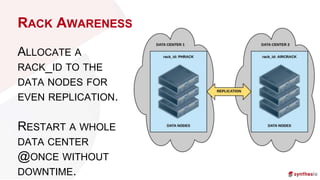
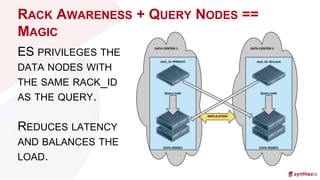
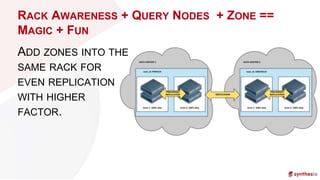
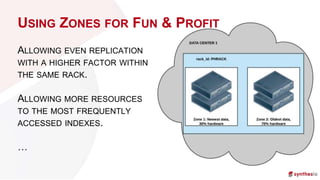



































The document discusses running and scaling large Elasticsearch clusters, detailing infrastructure specifications and strategies for avoiding downtime and optimizing performance. Key topics include memory management, index design, monitoring best practices, and troubleshooting techniques. Recommendations include using proper node configurations, garbage collectors, and monitoring tools to ensure high availability and efficient data handling.












































































