Rule Based Architecture System
•
3 likes•6,359 views

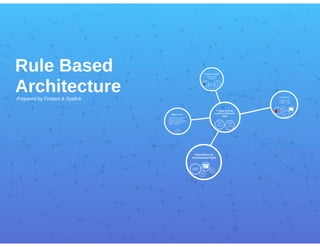
Rule-based systems are used as a way to store and manipulate knowledge to interpret information in a useful way. Often used in artificial intelligence applications and research.
Report
Share
Report
Share
Download to read offline

Recommended
Distributed & parallel system
The document defines distributed and parallel systems. A distributed system consists of independent computers that communicate over a network to collaborate on tasks. It has features like no common clock and increased reliability. Examples include telephone networks and the internet. Advantages are information sharing and scalability, while disadvantages include difficulty developing software and security issues. A parallel system uses multiple processors with shared memory to solve problems. Examples are supercomputers and server clusters. Advantages are concurrency and saving time, while the main disadvantage is lack of scalability between memory and CPUs.
Distributed Database Management System
This presentation several topics of subjects RDBMS and DBMS including Distributed Database Design,Architecture of Distributed database processing system,Data Communication concept,Concurrency control and recovery. All the topics are briefly described according to syllabus of BCA II and BCA III year subjects.
Lecture 3 general problem solver
This lecture is all about General problem Solver, a universal Problem Solving Machine using Same Base Algorithm.
and is for BS computer Science Students.
it is only for learning purpose, is not that much professional, there may be errors or mistakes, therefore corrections and suggestions are welcome.
File system structure
The document discusses the structure of file systems. It explains that a file system provides mechanisms for storing and accessing files and data. It uses a layered approach, with each layer responsible for specific tasks related to file management. The logical file system contains metadata and verifies permissions and paths. It maps logical file blocks to physical disk blocks using a file organization module, which also manages free space. The basic file system then issues I/O commands to access those physical blocks via device drivers, with I/O controls handling interrupts.
Lec 7 query processing
This document discusses distributed query processing. It begins by defining what a query and query processor are. It then outlines the main problems in query processing, characteristics of query processors, and layers of query processing. The key layers are query decomposition, data localization, global query optimization, and distributed execution. Query decomposition takes a query expressed on global relations and decomposes it into an algebraic query on global relations.
Distributed shred memory architecture
Distributed shared memory (DSM) is a memory architecture where physically separate memories can be addressed as a single logical address space. In a DSM system, data moves between nodes' main and secondary memories when a process accesses shared data. Each node has a memory mapping manager that maps the shared virtual memory to local physical memory. DSM provides advantages like shielding programmers from message passing, lower cost than multiprocessors, and large virtual address spaces, but disadvantages include potential performance penalties from remote data access and lack of programmer control over messaging.
Machine learning Lecture 2
The document summarizes key concepts in machine learning including concept learning as search, general-to-specific learning, version spaces, candidate elimination algorithm, and decision trees. It discusses how concept learning can be viewed as searching a hypothesis space to find the hypothesis that best fits the training examples. The candidate elimination algorithm represents the version space using the most general and specific hypotheses to efficiently learn from examples.
AI: Learning in AI
Neural networks can be used for machine learning tasks like classification. They consist of interconnected nodes that update their weight values during a training process using examples. Neural networks have been applied successfully to tasks like handwritten character recognition, autonomous vehicle control by observing human drivers, and text-to-speech pronunciation generation. Their architecture is inspired by the human brain but neural networks are trained using computational methods while the brain uses biological processes.
Recommended
Distributed & parallel system
The document defines distributed and parallel systems. A distributed system consists of independent computers that communicate over a network to collaborate on tasks. It has features like no common clock and increased reliability. Examples include telephone networks and the internet. Advantages are information sharing and scalability, while disadvantages include difficulty developing software and security issues. A parallel system uses multiple processors with shared memory to solve problems. Examples are supercomputers and server clusters. Advantages are concurrency and saving time, while the main disadvantage is lack of scalability between memory and CPUs.
Distributed Database Management System
This presentation several topics of subjects RDBMS and DBMS including Distributed Database Design,Architecture of Distributed database processing system,Data Communication concept,Concurrency control and recovery. All the topics are briefly described according to syllabus of BCA II and BCA III year subjects.
Lecture 3 general problem solver
This lecture is all about General problem Solver, a universal Problem Solving Machine using Same Base Algorithm.
and is for BS computer Science Students.
it is only for learning purpose, is not that much professional, there may be errors or mistakes, therefore corrections and suggestions are welcome.
File system structure
The document discusses the structure of file systems. It explains that a file system provides mechanisms for storing and accessing files and data. It uses a layered approach, with each layer responsible for specific tasks related to file management. The logical file system contains metadata and verifies permissions and paths. It maps logical file blocks to physical disk blocks using a file organization module, which also manages free space. The basic file system then issues I/O commands to access those physical blocks via device drivers, with I/O controls handling interrupts.
Lec 7 query processing
This document discusses distributed query processing. It begins by defining what a query and query processor are. It then outlines the main problems in query processing, characteristics of query processors, and layers of query processing. The key layers are query decomposition, data localization, global query optimization, and distributed execution. Query decomposition takes a query expressed on global relations and decomposes it into an algebraic query on global relations.
Distributed shred memory architecture
Distributed shared memory (DSM) is a memory architecture where physically separate memories can be addressed as a single logical address space. In a DSM system, data moves between nodes' main and secondary memories when a process accesses shared data. Each node has a memory mapping manager that maps the shared virtual memory to local physical memory. DSM provides advantages like shielding programmers from message passing, lower cost than multiprocessors, and large virtual address spaces, but disadvantages include potential performance penalties from remote data access and lack of programmer control over messaging.
Machine learning Lecture 2
The document summarizes key concepts in machine learning including concept learning as search, general-to-specific learning, version spaces, candidate elimination algorithm, and decision trees. It discusses how concept learning can be viewed as searching a hypothesis space to find the hypothesis that best fits the training examples. The candidate elimination algorithm represents the version space using the most general and specific hypotheses to efficiently learn from examples.
AI: Learning in AI
Neural networks can be used for machine learning tasks like classification. They consist of interconnected nodes that update their weight values during a training process using examples. Neural networks have been applied successfully to tasks like handwritten character recognition, autonomous vehicle control by observing human drivers, and text-to-speech pronunciation generation. Their architecture is inspired by the human brain but neural networks are trained using computational methods while the brain uses biological processes.
Distributed DBMS - Unit 8 - Distributed Transaction Management & Concurrency ...
Distributed DBMS - Unit 8 - Distributed Transaction Management & Concurrency ...Gyanmanjari Institute Of Technology
Transaction concept, ACID property, Objectives of transaction management, Types of transactions, Objectives of Distributed Concurrency Control, Concurrency Control anomalies, Methods of concurrency control, Serializability and recoverability, Distributed Serializability, Enhanced lock based and timestamp based protocols, Multiple granularity, Multi version schemes, Optimistic Concurrency Control techniquesOLAP & DATA WAREHOUSE
It is a presentation related to the Database management system topics- OLAP (online analytical Processing) and Data Warehouses.
Hope it helps you.
Mining single dimensional boolean association rules from transactional
The document discusses mining frequent itemsets and generating association rules from transactional databases. It introduces the Apriori algorithm, which uses a candidate generation-and-test approach to iteratively find frequent itemsets. Several improvements to Apriori's efficiency are also presented, such as hashing techniques, transaction reduction, and approaches that avoid candidate generation like FP-trees. The document concludes by discussing how Apriori can be applied to answer iceberg queries, a common operation in market basket analysis.
Knowledge representation in AI
The document discusses different types of knowledge that may need to be represented in AI systems, including objects, events, performance, and meta-knowledge. It also discusses representing knowledge at two levels: the knowledge level containing facts, and the symbol level containing representations of objects defined in terms of symbols. Common ways of representing knowledge mentioned include using English, logic, relations, semantic networks, frames, and rules. The document also discusses using knowledge for applications like learning, reasoning, and different approaches to machine learning such as skill refinement, knowledge acquisition, taking advice, problem solving, induction, discovery, and analogy.
Rule based system
A rule-based system uses predefined rules to make logical deductions and choices to perform automated actions. It consists of a database of rules representing knowledge, a database of facts as inputs, and an inference engine that controls the process of deriving conclusions by applying rules to facts. A rule-based system mimics human decision making by applying rules in an "if-then" format to incoming data to perform actions, but unlike AI it does not learn or adapt on its own.
Communication primitives
This document discusses two common models for distributed computing communication: message passing and remote procedure calls (RPC). It describes the basic primitives and design issues for each model. For message passing, it covers synchronous vs asynchronous and blocking vs non-blocking primitives. For RPC, it explains the client-server model and how stubs are used to convert parameters and return results between machines. It also discusses binding, parameter passing techniques, and ensuring error handling and execution semantics.
Register allocation and assignment
This document discusses various strategies for register allocation and assignment in compiler design. It notes that assigning values to specific registers simplifies compiler design but can result in inefficient register usage. Global register allocation aims to assign frequently used values to registers for the duration of a single block. Usage counts provide an estimate of how many loads/stores could be saved by assigning a value to a register. Graph coloring is presented as a technique where an interference graph is constructed and coloring aims to assign registers efficiently despite interference between values.
Distributed DBMS - Unit 6 - Query Processing
Query Processing : Query Processing Problem, Layers of Query Processing Query Processing in Centralized Systems – Parsing & Translation, Optimization, Code generation, Example Query Processing in Distributed Systems – Mapping global query to local, Optimization,
directory structure and file system mounting
This document discusses directory structures and file system mounting in operating systems. It describes several types of directory structures including single-level, two-level, hierarchical, tree, and acyclic graph structures. It notes that directories organize files in a hierarchical manner and that mounting makes storage devices available to the operating system by reading metadata about the filesystem. Mounting attaches an additional filesystem to the currently accessible filesystem, while unmounting disconnects the filesystem.
Code optimization in compiler design
The document discusses code optimization techniques in compilers. It covers the following key points:
1. Code optimization aims to improve code performance by replacing high-level constructs with more efficient low-level code while preserving program semantics. It occurs at various compiler phases like source code, intermediate code, and target code.
2. Common optimization techniques include constant folding, propagation, algebraic simplification, strength reduction, copy propagation, and dead code elimination. Control and data flow analysis are required to perform many optimizations.
3. Optimizations can be local within basic blocks, global across blocks, or inter-procedural across procedures. Representations like flow graphs, basic blocks, and DAGs are used to apply optimizations at
Uml class-diagram
This document provides an overview of UML class diagrams, including their purpose and essential elements. A UML class diagram visually describes the structure of a system by showing classes, attributes, operations, and relationships. Key elements include classes, associations, generalization, dependencies, and notes. The document also provides examples and tips for creating UML class diagrams.
Memory management
The document discusses memory management techniques used in operating systems. It describes logical vs physical addresses and how relocation registers map logical addresses to physical addresses. It covers contiguous and non-contiguous storage allocation, including paging and segmentation. Paging divides memory into fixed-size frames and pages, using a page table and translation lookaside buffer (TLB) for address translation. Segmentation divides memory into variable-sized segments based on a program's logical structure. Virtual memory and demand paging are also covered, along with page replacement algorithms like FIFO, LRU and optimal replacement.
Knowledge representation
Knowledge representation and reasoning (KR) is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can utilize to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language
4.2 spatial data mining
This document discusses spatial data mining and its applications. Spatial data mining involves extracting knowledge and relationships from large spatial databases. It can be used for applications like GIS, remote sensing, medical imaging, and more. Some challenges include the complexity of spatial data types and large data volumes. The document also covers topics like spatial data warehouses, dimensions and measures in spatial analysis, spatial association rule mining, and applications in fields such as earth science, crime mapping, and commerce.
Distributed file system
The document discusses key concepts related to distributed file systems including:
1. Files are accessed using location transparency where the physical location is hidden from users. File names do not reveal storage locations and names do not change when locations change.
2. Remote files can be mounted to local directories, making them appear local while maintaining location independence. Caching is used to reduce network traffic by storing recently accessed data locally.
3. Fault tolerance is improved through techniques like stateless server designs, file replication across failure independent machines, and read-only replication for consistency. Scalability is achieved by adding new nodes and using decentralized control through clustering.
Parallel Database
The document discusses parallel databases and their architectures. It introduces parallel databases as systems that seek to improve performance through parallelizing operations like loading data, building indexes, and evaluating queries using multiple CPUs and disks. It describes three main architectures for parallel databases: shared memory, shared disk, and shared nothing. The shared nothing architecture provides linear scale-up and speed-up but is more difficult to program. The document also discusses measuring performance improvements from parallelization through speed-up and scale-up.
Developing Knowledge-Based Systems
This document discusses knowledge-based systems (KBS), including:
- KBS deal with unstructured knowledge and can justify decisions and learn.
- Developing KBS is difficult due to high costs, limited expert availability, and risky investments.
- A common KBS development model involves requirements, design, implementation, testing, and knowledge acquisition in multiple rounds.
- Knowledge acquisition involves eliciting, representing, and updating knowledge from domain experts.
Web Mining & Text Mining
Web mining is the application of data mining techniques to extract knowledge from web data, including web content, structure, and usage data. Web content mining analyzes text, images, and other unstructured data on web pages using natural language processing and information retrieval. Web structure mining examines the hyperlinks between pages to discover relationships. Web usage mining applies data mining methods to server logs and other web data to discover patterns of user behavior on websites. Text mining aims to extract useful information from unstructured text documents using techniques like summarization, information extraction, categorization, and sentiment analysis.
State Space Representation and Search
- A state space consists of nodes representing problem states and arcs representing moves between states. It can be represented as a tree or graph.
- To solve a problem using search, it must first be represented as a state space with an initial state, goal state(s), and legal operators defining state transitions.
- Different search algorithms like depth-first, breadth-first, A*, and best-first are then applied to traverse the state space to find a solution path from initial to goal state.
- Heuristic functions can be used to guide search by estimating state proximity to the goal, improving efficiency over uninformed searches.
Wireless Technology Proj spec
This document provides specifications for a semester project on wireless technology. Students will work in teams to research and demonstrate proficiency in one of five wireless topics. Each team must create an informational blog and conduct a 15-20 minute demonstration of their assigned topic. Additionally, each student will independently summarize five recent journal papers related to their topic. The project aims to apply theoretical knowledge to practical scenarios and promote team-based and self-directed learning. Teams must register their topic by June 24th and complete all tasks by August dates to contribute to 20% of the overall course grade.
More Related Content
What's hot
Distributed DBMS - Unit 8 - Distributed Transaction Management & Concurrency ...
Distributed DBMS - Unit 8 - Distributed Transaction Management & Concurrency ...Gyanmanjari Institute Of Technology
Transaction concept, ACID property, Objectives of transaction management, Types of transactions, Objectives of Distributed Concurrency Control, Concurrency Control anomalies, Methods of concurrency control, Serializability and recoverability, Distributed Serializability, Enhanced lock based and timestamp based protocols, Multiple granularity, Multi version schemes, Optimistic Concurrency Control techniquesOLAP & DATA WAREHOUSE
It is a presentation related to the Database management system topics- OLAP (online analytical Processing) and Data Warehouses.
Hope it helps you.
Mining single dimensional boolean association rules from transactional
The document discusses mining frequent itemsets and generating association rules from transactional databases. It introduces the Apriori algorithm, which uses a candidate generation-and-test approach to iteratively find frequent itemsets. Several improvements to Apriori's efficiency are also presented, such as hashing techniques, transaction reduction, and approaches that avoid candidate generation like FP-trees. The document concludes by discussing how Apriori can be applied to answer iceberg queries, a common operation in market basket analysis.
Knowledge representation in AI
The document discusses different types of knowledge that may need to be represented in AI systems, including objects, events, performance, and meta-knowledge. It also discusses representing knowledge at two levels: the knowledge level containing facts, and the symbol level containing representations of objects defined in terms of symbols. Common ways of representing knowledge mentioned include using English, logic, relations, semantic networks, frames, and rules. The document also discusses using knowledge for applications like learning, reasoning, and different approaches to machine learning such as skill refinement, knowledge acquisition, taking advice, problem solving, induction, discovery, and analogy.
Rule based system
A rule-based system uses predefined rules to make logical deductions and choices to perform automated actions. It consists of a database of rules representing knowledge, a database of facts as inputs, and an inference engine that controls the process of deriving conclusions by applying rules to facts. A rule-based system mimics human decision making by applying rules in an "if-then" format to incoming data to perform actions, but unlike AI it does not learn or adapt on its own.
Communication primitives
This document discusses two common models for distributed computing communication: message passing and remote procedure calls (RPC). It describes the basic primitives and design issues for each model. For message passing, it covers synchronous vs asynchronous and blocking vs non-blocking primitives. For RPC, it explains the client-server model and how stubs are used to convert parameters and return results between machines. It also discusses binding, parameter passing techniques, and ensuring error handling and execution semantics.
Register allocation and assignment
This document discusses various strategies for register allocation and assignment in compiler design. It notes that assigning values to specific registers simplifies compiler design but can result in inefficient register usage. Global register allocation aims to assign frequently used values to registers for the duration of a single block. Usage counts provide an estimate of how many loads/stores could be saved by assigning a value to a register. Graph coloring is presented as a technique where an interference graph is constructed and coloring aims to assign registers efficiently despite interference between values.
Distributed DBMS - Unit 6 - Query Processing
Query Processing : Query Processing Problem, Layers of Query Processing Query Processing in Centralized Systems – Parsing & Translation, Optimization, Code generation, Example Query Processing in Distributed Systems – Mapping global query to local, Optimization,
directory structure and file system mounting
This document discusses directory structures and file system mounting in operating systems. It describes several types of directory structures including single-level, two-level, hierarchical, tree, and acyclic graph structures. It notes that directories organize files in a hierarchical manner and that mounting makes storage devices available to the operating system by reading metadata about the filesystem. Mounting attaches an additional filesystem to the currently accessible filesystem, while unmounting disconnects the filesystem.
Code optimization in compiler design
The document discusses code optimization techniques in compilers. It covers the following key points:
1. Code optimization aims to improve code performance by replacing high-level constructs with more efficient low-level code while preserving program semantics. It occurs at various compiler phases like source code, intermediate code, and target code.
2. Common optimization techniques include constant folding, propagation, algebraic simplification, strength reduction, copy propagation, and dead code elimination. Control and data flow analysis are required to perform many optimizations.
3. Optimizations can be local within basic blocks, global across blocks, or inter-procedural across procedures. Representations like flow graphs, basic blocks, and DAGs are used to apply optimizations at
Uml class-diagram
This document provides an overview of UML class diagrams, including their purpose and essential elements. A UML class diagram visually describes the structure of a system by showing classes, attributes, operations, and relationships. Key elements include classes, associations, generalization, dependencies, and notes. The document also provides examples and tips for creating UML class diagrams.
Memory management
The document discusses memory management techniques used in operating systems. It describes logical vs physical addresses and how relocation registers map logical addresses to physical addresses. It covers contiguous and non-contiguous storage allocation, including paging and segmentation. Paging divides memory into fixed-size frames and pages, using a page table and translation lookaside buffer (TLB) for address translation. Segmentation divides memory into variable-sized segments based on a program's logical structure. Virtual memory and demand paging are also covered, along with page replacement algorithms like FIFO, LRU and optimal replacement.
Knowledge representation
Knowledge representation and reasoning (KR) is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can utilize to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language
4.2 spatial data mining
This document discusses spatial data mining and its applications. Spatial data mining involves extracting knowledge and relationships from large spatial databases. It can be used for applications like GIS, remote sensing, medical imaging, and more. Some challenges include the complexity of spatial data types and large data volumes. The document also covers topics like spatial data warehouses, dimensions and measures in spatial analysis, spatial association rule mining, and applications in fields such as earth science, crime mapping, and commerce.
Distributed file system
The document discusses key concepts related to distributed file systems including:
1. Files are accessed using location transparency where the physical location is hidden from users. File names do not reveal storage locations and names do not change when locations change.
2. Remote files can be mounted to local directories, making them appear local while maintaining location independence. Caching is used to reduce network traffic by storing recently accessed data locally.
3. Fault tolerance is improved through techniques like stateless server designs, file replication across failure independent machines, and read-only replication for consistency. Scalability is achieved by adding new nodes and using decentralized control through clustering.
Parallel Database
The document discusses parallel databases and their architectures. It introduces parallel databases as systems that seek to improve performance through parallelizing operations like loading data, building indexes, and evaluating queries using multiple CPUs and disks. It describes three main architectures for parallel databases: shared memory, shared disk, and shared nothing. The shared nothing architecture provides linear scale-up and speed-up but is more difficult to program. The document also discusses measuring performance improvements from parallelization through speed-up and scale-up.
Developing Knowledge-Based Systems
This document discusses knowledge-based systems (KBS), including:
- KBS deal with unstructured knowledge and can justify decisions and learn.
- Developing KBS is difficult due to high costs, limited expert availability, and risky investments.
- A common KBS development model involves requirements, design, implementation, testing, and knowledge acquisition in multiple rounds.
- Knowledge acquisition involves eliciting, representing, and updating knowledge from domain experts.
Web Mining & Text Mining
Web mining is the application of data mining techniques to extract knowledge from web data, including web content, structure, and usage data. Web content mining analyzes text, images, and other unstructured data on web pages using natural language processing and information retrieval. Web structure mining examines the hyperlinks between pages to discover relationships. Web usage mining applies data mining methods to server logs and other web data to discover patterns of user behavior on websites. Text mining aims to extract useful information from unstructured text documents using techniques like summarization, information extraction, categorization, and sentiment analysis.
State Space Representation and Search
- A state space consists of nodes representing problem states and arcs representing moves between states. It can be represented as a tree or graph.
- To solve a problem using search, it must first be represented as a state space with an initial state, goal state(s), and legal operators defining state transitions.
- Different search algorithms like depth-first, breadth-first, A*, and best-first are then applied to traverse the state space to find a solution path from initial to goal state.
- Heuristic functions can be used to guide search by estimating state proximity to the goal, improving efficiency over uninformed searches.
What's hot (20)
Distributed DBMS - Unit 8 - Distributed Transaction Management & Concurrency ...
Distributed DBMS - Unit 8 - Distributed Transaction Management & Concurrency ...
Mining single dimensional boolean association rules from transactional
Mining single dimensional boolean association rules from transactional
More from Firdaus Adib
Wireless Technology Proj spec
This document provides specifications for a semester project on wireless technology. Students will work in teams to research and demonstrate proficiency in one of five wireless topics. Each team must create an informational blog and conduct a 15-20 minute demonstration of their assigned topic. Additionally, each student will independently summarize five recent journal papers related to their topic. The project aims to apply theoretical knowledge to practical scenarios and promote team-based and self-directed learning. Teams must register their topic by June 24th and complete all tasks by August dates to contribute to 20% of the overall course grade.
Final Paper UTP Web Development Application July 2008
Web Development Application, UTP, ICT, Software Engineering, Question Paper, Web
Final Paper UTP Algorithm Data Structure July 2008
Algorithm, Data structure, UTP, ICT, Software Engineering, Question Paper, C++
Final Paper UTP Web Development Application January 2010
Web Development Application, UTP, ICT, Software Engineering, Question Paper, Web
Final Paper UTP Web Development Application July 2009
Web Development Application, UTP, ICT, Software Engineering, Question Paper
PHP - Getting good with MySQL part II
This document discusses connecting PHP to a MySQL database. It explains how to connect to a MySQL database, select a database, query and access tables, and perform common SQL commands like INSERT, UPDATE, DELETE from PHP scripts. Examples are provided of connecting to a database, selecting the table, fetching rows from a query result, and using the data to generate an HTML table. The key steps are connecting to the MySQL server, selecting the database, constructing SQL queries to select, update, or delete data, and handling the result rows.
PHP - Getting good with MySQL part I
This document discusses databases and SQL. It defines a database as an integrated collection of data managed by a database management system (DBMS) using SQL. The most popular type is the relational database which organizes data into tables related through primary keys. SQL is used for queries with statements like SELECT, INSERT, DELETE, and UPDATE. Database interfaces like Perl DBI, PHP dbx, and Python DB-API allow access from programming languages. ADO.NET is an API for database access in .NET.
Php - Getting good with session
Session in PHP allows for maintaining and accessing user data across multiple pages of a website. It stores data on the server side and associates it with a unique ID saved in a cookie on the client side. The $_SESSION superglobal array is used to store and retrieve session variables. Session_start() must be called before accessing session variables, and session_destroy() ends the current session and destroys all associated data. Sample code demonstrates registering a session on login and checking for a valid session on subsequent pages.
PHP - Getting good with cookies
Cookies are small files stored on a user's computer that identify the user. PHP allows creation and retrieval of cookie values. To create a cookie, setcookie() must be called before the HTML tag and assigns a name, value, and expiration time. Cookie values are automatically URL encoded when sent and decoded when received. To retrieve a cookie value, check if it is set in the $_COOKIE superglobal array. Cookies can be deleted by setting the expiration time in the past.
Javascript - Getting Good with Object
This document provides an overview of various JavaScript objects including the Math, String, Date, document, and window objects. It describes key properties and methods for each object, and provides examples of how to use the Date and window objects.
Javascript - Getting Good with Loop and Array
This document discusses arrays in JavaScript. It defines arrays as data structures that can store related data and notes that JavaScript arrays are dynamic entities that can change in size after being created. Elements in an array are accessed using indexes in square brackets. The document then provides examples of how to declare, allocate, initialize, and manipulate array values and elements in JavaScript.
Introduction to Javascript
This document provides an overview of JavaScript and DOM for a lecture on internet programming. It outlines the objectives of understanding basic JavaScript concepts and the client-server model. The agenda covers what JavaScript is and why it is useful, where JavaScript code can be located, and how to process user input with DOM. It also gives examples of arithmetic operators in JavaScript and a simple cashier application example.
Additional exercise for apa references
This document provides references for 5 sources in APA style, including books, newspaper articles, and websites. The references are listed alphabetically and provide the author's name, publication year, title, publisher or source, and page numbers when relevant. Proper APA style is followed with indentation of lines after the first for each individual reference.
Chapter 2 summarising
This document provides guidance on summarizing texts effectively in 3 sentences or less. It explains that a summary presents the main ideas and most important information from the original text in a condensed form. The document outlines techniques for summarizing such as understanding the author's purpose and main point, paraphrasing using different vocabulary, and avoiding directly copying phrases from the original text. Readers are advised to focus on topic sentences, supporting details, and omit personal opinions when writing a summary.
American psychological association (apa)
The document discusses the American Psychological Association (APA) style for citing references and formatting papers. APA style provides guidelines for formatting papers, citing references in-text, and constructing reference lists. It describes an author-date citation system where references are listed alphabetically by author's last name and date. Examples are provided for citing different source types, such as books, journal articles, and websites, both in-text and in the reference list. Key components of reference list entries are identified for different source formats.
Referencing and Citing
This document discusses referencing and citing sources in academic writing. It covers creating bibliographies and references, defining plagiarism, and the APA documentation style. The key points are:
- Bibliographies and references list sources used and include author, date, title, publisher details.
- Plagiarism involves using others' words or ideas without proper citation. Sources must be acknowledged using quotation marks or paraphrasing with citation.
- The APA style numbers references in text and provides guidelines for citing different source types and multiple sources.
Chapter 2 paraphrasing
The document discusses techniques for effectively paraphrasing sources in writing. It defines paraphrasing as restating what has been said or written in different words while still conveying the same ideas and information. Paraphrasing is important for avoiding plagiarism and properly attributing ideas that belong to others. Good paraphrasing uses different grammar and vocabulary than the original while maintaining a similar length and all essential ideas. The document outlines techniques for paraphrasing including using synonyms, varying sentence structure, changing the order of ideas, breaking long sentences into shorter ones, and simplifying abstract concepts. It provides examples to illustrate effectively applying these paraphrasing strategies.
More from Firdaus Adib (20)
Final Paper UTP Web Development Application July 2008
Final Paper UTP Web Development Application July 2008
Final Paper UTP Algorithm Data Structure July 2008
Final Paper UTP Algorithm Data Structure July 2008
Final Paper UTP Web Development Application January 2010
Final Paper UTP Web Development Application January 2010
Final Paper UTP Algorithm Data Structure January 2010
Final Paper UTP Algorithm Data Structure January 2010
Final Paper UTP Web Development Application July 2009
Final Paper UTP Web Development Application July 2009
Recently uploaded
BÀI TẬP BỔ TRỢ TIẾNG ANH 8 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2023-2024 (CÓ FI...
BÀI TẬP BỔ TRỢ TIẾNG ANH 8 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2023-2024 (CÓ FI...Nguyen Thanh Tu Collection
https://app.box.com/s/y977uz6bpd3af4qsebv7r9b7s21935vdISO/IEC 27001, ISO/IEC 42001, and GDPR: Best Practices for Implementation and...
Denis is a dynamic and results-driven Chief Information Officer (CIO) with a distinguished career spanning information systems analysis and technical project management. With a proven track record of spearheading the design and delivery of cutting-edge Information Management solutions, he has consistently elevated business operations, streamlined reporting functions, and maximized process efficiency.
Certified as an ISO/IEC 27001: Information Security Management Systems (ISMS) Lead Implementer, Data Protection Officer, and Cyber Risks Analyst, Denis brings a heightened focus on data security, privacy, and cyber resilience to every endeavor.
His expertise extends across a diverse spectrum of reporting, database, and web development applications, underpinned by an exceptional grasp of data storage and virtualization technologies. His proficiency in application testing, database administration, and data cleansing ensures seamless execution of complex projects.
What sets Denis apart is his comprehensive understanding of Business and Systems Analysis technologies, honed through involvement in all phases of the Software Development Lifecycle (SDLC). From meticulous requirements gathering to precise analysis, innovative design, rigorous development, thorough testing, and successful implementation, he has consistently delivered exceptional results.
Throughout his career, he has taken on multifaceted roles, from leading technical project management teams to owning solutions that drive operational excellence. His conscientious and proactive approach is unwavering, whether he is working independently or collaboratively within a team. His ability to connect with colleagues on a personal level underscores his commitment to fostering a harmonious and productive workplace environment.
Date: May 29, 2024
Tags: Information Security, ISO/IEC 27001, ISO/IEC 42001, Artificial Intelligence, GDPR
-------------------------------------------------------------------------------
Find out more about ISO training and certification services
Training: ISO/IEC 27001 Information Security Management System - EN | PECB
ISO/IEC 42001 Artificial Intelligence Management System - EN | PECB
General Data Protection Regulation (GDPR) - Training Courses - EN | PECB
Webinars: https://pecb.com/webinars
Article: https://pecb.com/article
-------------------------------------------------------------------------------
For more information about PECB:
Website: https://pecb.com/
LinkedIn: https://www.linkedin.com/company/pecb/
Facebook: https://www.facebook.com/PECBInternational/
Slideshare: http://www.slideshare.net/PECBCERTIFICATION
Constructing Your Course Container for Effective Communication
Communicating effectively and consistently with students can help them feel at ease during their learning experience and provide the instructor with a communication trail to track the course's progress. This workshop will take you through constructing an engaging course container to facilitate effective communication.
Beyond Degrees - Empowering the Workforce in the Context of Skills-First.pptx
Iván Bornacelly, Policy Analyst at the OECD Centre for Skills, OECD, presents at the webinar 'Tackling job market gaps with a skills-first approach' on 12 June 2024
Wound healing PPT
This document provides an overview of wound healing, its functions, stages, mechanisms, factors affecting it, and complications.
A wound is a break in the integrity of the skin or tissues, which may be associated with disruption of the structure and function.
Healing is the body’s response to injury in an attempt to restore normal structure and functions.
Healing can occur in two ways: Regeneration and Repair
There are 4 phases of wound healing: hemostasis, inflammation, proliferation, and remodeling. This document also describes the mechanism of wound healing. Factors that affect healing include infection, uncontrolled diabetes, poor nutrition, age, anemia, the presence of foreign bodies, etc.
Complications of wound healing like infection, hyperpigmentation of scar, contractures, and keloid formation.
বাংলাদেশ অর্থনৈতিক সমীক্ষা (Economic Review) ২০২৪ UJS App.pdf
বাংলাদেশের অর্থনৈতিক সমীক্ষা ২০২৪ [Bangladesh Economic Review 2024 Bangla.pdf] কম্পিউটার , ট্যাব ও স্মার্ট ফোন ভার্সন সহ সম্পূর্ণ বাংলা ই-বুক বা pdf বই " সুচিপত্র ...বুকমার্ক মেনু 🔖 ও হাইপার লিংক মেনু 📝👆 যুক্ত ..
আমাদের সবার জন্য খুব খুব গুরুত্বপূর্ণ একটি বই ..বিসিএস, ব্যাংক, ইউনিভার্সিটি ভর্তি ও যে কোন প্রতিযোগিতা মূলক পরীক্ষার জন্য এর খুব ইম্পরট্যান্ট একটি বিষয় ...তাছাড়া বাংলাদেশের সাম্প্রতিক যে কোন ডাটা বা তথ্য এই বইতে পাবেন ...
তাই একজন নাগরিক হিসাবে এই তথ্য গুলো আপনার জানা প্রয়োজন ...।
বিসিএস ও ব্যাংক এর লিখিত পরীক্ষা ...+এছাড়া মাধ্যমিক ও উচ্চমাধ্যমিকের স্টুডেন্টদের জন্য অনেক কাজে আসবে ...
BBR 2024 Summer Sessions Interview Training
Qualitative research interview training by Professor Katrina Pritchard and Dr Helen Williams
Solutons Maths Escape Room Spatial .pptx
Solutions of Puzzles of Mathematics Escape Room Game in Spatial.io
RHEOLOGY Physical pharmaceutics-II notes for B.pharm 4th sem students
Physical pharmaceutics notes for B.pharm students
How to Make a Field Mandatory in Odoo 17
In Odoo, making a field required can be done through both Python code and XML views. When you set the required attribute to True in Python code, it makes the field required across all views where it's used. Conversely, when you set the required attribute in XML views, it makes the field required only in the context of that particular view.
How to Create a More Engaging and Human Online Learning Experience
How to Create a More Engaging and Human Online Learning Experience Wahiba Chair Training & Consulting
Wahiba Chair's Talk at the 2024 Learning Ideas Conference. How to deliver Powerpoint Presentations.pptx
"How to make and deliver dynamic presentations by making it more interactive to captivate your audience attention"
The History of Stoke Newington Street Names
Presented at the Stoke Newington Literary Festival on 9th June 2024
www.StokeNewingtonHistory.com
Mule event processing models | MuleSoft Mysore Meetup #47
Mule event processing models | MuleSoft Mysore Meetup #47
Event Link:- https://meetups.mulesoft.com/events/details/mulesoft-mysore-presents-mule-event-processing-models/
Agenda
● What is event processing in MuleSoft?
● Types of event processing models in Mule 4
● Distinction between the reactive, parallel, blocking & non-blocking processing
For Upcoming Meetups Join Mysore Meetup Group - https://meetups.mulesoft.com/mysore/YouTube:- youtube.com/@mulesoftmysore
Mysore WhatsApp group:- https://chat.whatsapp.com/EhqtHtCC75vCAX7gaO842N
Speaker:-
Shivani Yasaswi - https://www.linkedin.com/in/shivaniyasaswi/
Organizers:-
Shubham Chaurasia - https://www.linkedin.com/in/shubhamchaurasia1/
Giridhar Meka - https://www.linkedin.com/in/giridharmeka
Priya Shaw - https://www.linkedin.com/in/priya-shaw
Your Skill Boost Masterclass: Strategies for Effective Upskilling
Your Skill Boost Masterclass: Strategies for Effective UpskillingExcellence Foundation for South Sudan
Strategies for Effective Upskilling is a presentation by Chinwendu Peace in a Your Skill Boost Masterclass organisation by the Excellence Foundation for South Sudan on 08th and 09th June 2024 from 1 PM to 3 PM on each day.BÀI TẬP BỔ TRỢ TIẾNG ANH LỚP 9 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2024-2025 - ...
BÀI TẬP BỔ TRỢ TIẾNG ANH LỚP 9 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2024-2025 - ...Nguyen Thanh Tu Collection
https://app.box.com/s/tacvl9ekroe9hqupdnjruiypvm9rdaneRecently uploaded (20)
spot a liar (Haiqa 146).pptx Technical writhing and presentation skills
spot a liar (Haiqa 146).pptx Technical writhing and presentation skills
B. Ed Syllabus for babasaheb ambedkar education university.pdf
B. Ed Syllabus for babasaheb ambedkar education university.pdf
BÀI TẬP BỔ TRỢ TIẾNG ANH 8 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2023-2024 (CÓ FI...
BÀI TẬP BỔ TRỢ TIẾNG ANH 8 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2023-2024 (CÓ FI...
ISO/IEC 27001, ISO/IEC 42001, and GDPR: Best Practices for Implementation and...
ISO/IEC 27001, ISO/IEC 42001, and GDPR: Best Practices for Implementation and...
Constructing Your Course Container for Effective Communication
Constructing Your Course Container for Effective Communication
Beyond Degrees - Empowering the Workforce in the Context of Skills-First.pptx
Beyond Degrees - Empowering the Workforce in the Context of Skills-First.pptx
বাংলাদেশ অর্থনৈতিক সমীক্ষা (Economic Review) ২০২৪ UJS App.pdf
বাংলাদেশ অর্থনৈতিক সমীক্ষা (Economic Review) ২০২৪ UJS App.pdf
RHEOLOGY Physical pharmaceutics-II notes for B.pharm 4th sem students
RHEOLOGY Physical pharmaceutics-II notes for B.pharm 4th sem students
How to Create a More Engaging and Human Online Learning Experience
How to Create a More Engaging and Human Online Learning Experience
Mule event processing models | MuleSoft Mysore Meetup #47
Mule event processing models | MuleSoft Mysore Meetup #47
Your Skill Boost Masterclass: Strategies for Effective Upskilling
Your Skill Boost Masterclass: Strategies for Effective Upskilling
BÀI TẬP BỔ TRỢ TIẾNG ANH LỚP 9 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2024-2025 - ...
BÀI TẬP BỔ TRỢ TIẾNG ANH LỚP 9 CẢ NĂM - GLOBAL SUCCESS - NĂM HỌC 2024-2025 - ...