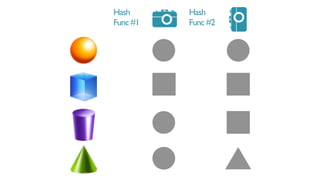
A B C
r11 0 1
r2 0 1 1
r3 0 0 1
r4 1 1 0
r5 1 0 0
r6 0 1 1
A B C
h1 2 4 1
h2 2 1 1
h3 1 2 3
r3
r5
r1
r2
r4
r6
r6
r1
r3
r2
r4
r5
hash1 hash2
random permutation
r5
r4
r6
r2
r1
r3
hash3
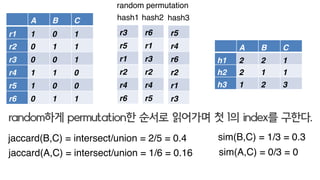
random하게 permutation한 순서로 읽어가며 첫 1의 index를 구한다.
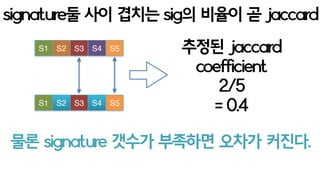
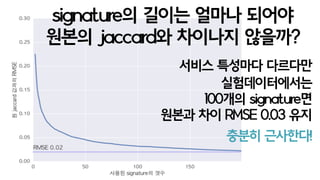
jaccard(B,C) = 2/5 = 0.4
jaccard(A,C) = 1/6 = 0.16
sim(B,C) = 1/3 = 0.3
sim(A,C) = 0/3 = 0
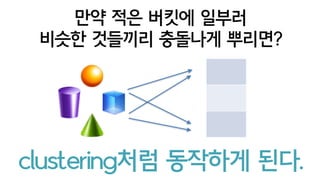
jaccard = intersect/union sim = intersect/length
37.
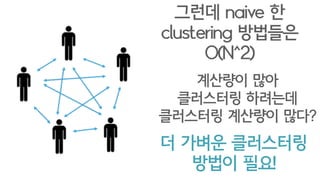
실제로는 random permutation을만드는 것도
계산량이 많이 필요하게 되므로
universal hash를 잔뜩 random generation
이를 random permutation의 대리자(proxy)로
사용하곤 한다.
뭔가 말이 어려워 보이지만
하여간 저렴한 계산으로
minhash를 얻을 수 있습니다.
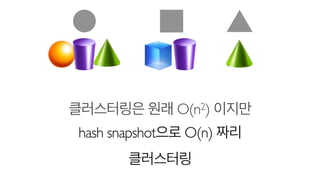
38.
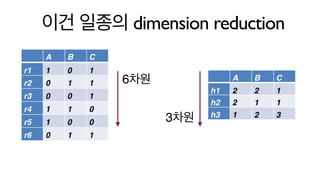
이건 일종의 dimensionreduction
A B C
r1 1 0 1
r2 0 1 1
r3 0 0 1
r4 1 1 0
r5 1 0 0
r6 0 1 1
A B C
h1 2 2 1
h2 2 1 1
h3 1 2 3
6차원
3차원
39.
Q P RS
s1 1 2 2 1
s2 3 1 3 1
s3 1 2 1 2
s4 4 1 1 4
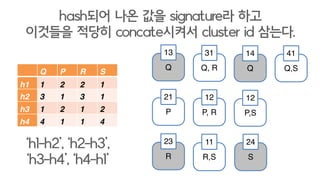
hash되어 나온 값을 signature라 하고
이것들을 적당히 concate시켜서 cluster id 삼는다.
‘s1-s2’, ‘s2-s3’,
‘s3-s4’, ‘s4-s1’
Q
13
Q, R
31
Q
14
Q,S
41
P
21
P, R
12
P,S
12
R
23
R,S
11
S
24
minhash로 클러스터 만들기
for후보 in 모든 후보들:
그 후보의 모든 click stream 로딩하기
로딩한 것으로 minhash signature 생성하기
signature들을 concate해서 다량의 cluster id
이 후보를 해당 cluster id들에 집어넣기
for cluster in 만들어진 클러스터들:
if length(클러스터) > threshold:
클러스터의 멤버십 정보 저장
42.
클러스터 정보로 추천하기
타겟item이 존재함
그 타겟 item의 minhash값을 가져옴
minhash값을 concate해서 해당되는 cluster 들 다 찾음
for cluster in 타겟이 포함된 클러스터들:
클러스터에 포함된 다른 뽑은 item들 로딩
그 item들의 click stream을 로딩
click stream정보를 기초로 모든 pair 유사도 계산
각 클러스터로 부터 모여온 것중 유사도 top N들을 선출
Heavy I/O 가잦다 : 빨간색이 I/O
유저의 액션 우리의 반응
느려!
minhash로 클러스터링
for 후보 in 모든 후보들:
그 후보의 모든 click stream 로딩하기
로딩한 것으로 minhash signature 생성하기
signature들을 concate해서 다량의 cluster id
이 후보를 해당 cluster id들에 집어넣기
for cluster in 만들어진 클러스터들:
if length(클러스터) > threshold:
클러스터의 멤버십 정보 저장
클러스터 정보로 추천하기
타겟 item이 존재함
그 타겟 item의 minhash값을 가져옴
minhash값을 concate해서 cluster id 리스트작성
위를 통해 타겟이 포함된 cluster들을 다 찾음
for cluster in 타겟이 포함된 클러스터들:
클러스터에 포함된 다른 item들 로딩
그 item들의 click stream을 로딩
click stream정보를 기초로 모든 pair 유사도 계산
각 클러스터로 부터 모여온 것중 유사도 top N들을 선출
그중 적절히 소팅하여 추천
47.
- speed gain
후보를한정한다.
후보를 한정한다.
- quality loss
장점 :
단점 :
클러스터를 쓴다
구글 논문과 반대의어프로치
구글 논문 새로운 방법
signature를 소량 생성
적절히 충돌시켜
미리 clustering 하자
실제 계산은
click stream을 사용함
signature를 대량 생성
충돌을 피하고
실제 계산은
click stream대신
signature overlap을 사용함
61.
이 방법의 장점
다량의건수를 in-memory에 fit가능
자료구조상 실시간 반영 추천이 가능
62.
+다량의 건수를 in-memory에fit가능
+메모리 얼마가 필요한지 예측 가능
예전에는 인기아이템의 클릭스트림이
얼마나 용량을 차지 할지 몰랐다.
앵간하면 전부 disk io없이 계산
63.
item한개가 4byte짜리 시그니처100개
100 x 4 + 200 = 600 byte
개당 부가 공간 200 byte 더 있다 치자
메모리 1G가 있으면 1024^3 / 800 = 1,789,569
1기가당 180만 종류 item의 click stream을
메모리에 들고 있을 수 있다! (그런 규모 많이 없다)
64.
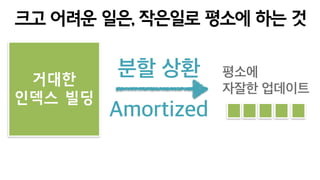
+우리를 느리게 만드는건 대량 배치 Job
“이거 다 돌아야 반영되어요”
+빚은 쌓지 말고 짬짬히 분할상환하는게 좋다.
“새로운 클릭이 쌓이면
그거 포함해서 다시 전부 돌려야
하지 않나요?”, “방법이 있습니다”
65.
새로운 click이 일어나면
기존에계산해 놓은 signature버리고
다 새로 계산 해야 하나?
No!
minhash는 ‘min 함수’의 ‘chain’이다.
때문에 좋은 성질을 가지고 있다.
처음부터 지금까지 배치로돌린것
= 맘 편하게 계속 누적시켜 적용한 것
전체 배치는 부담되지만, 조각들은 가볍고 빠르다!
click이 들어올때마다 지금 적용하자!
69.
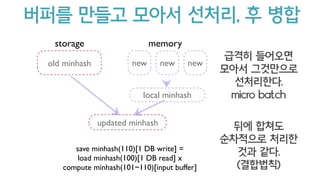
이 성질을 이용하면high TPS도 대응
save minhash(110)[1 DB write] =
load minhash(100)[1 DB read] x
compute minhash(101~110)[input buffer]
old minhash new new new
local minhash
memorystorage
updated minhash
급격히 들어오면
모아서 그것만으로
선처리한다.
micro batch
뒤에 합쳐도
순차적으로 처리한
것과 같다.
(결합법칙)
item A
item B
itemC
923 1032 58 74
87 1032 123 80
923 872 58 80
Sig1 Sig2 Sig3 Sig4
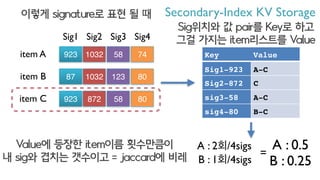
이렇게 signature로 표현 될 때 Secondary-Index KV Storage
Sig위치와 값 pair를 Key로 하고
그걸 가지는 item리스트를 Value
Key Value
Sig1-923 A-C
Sig2-872 C
sig3-58 A-C
sig4-80 B-C
A : 2회/4sigs
B : 1회/4sigs
A : 0.5
B : 0.25
Value에 등장한 item이름 횟수만큼이
내 sig와 겹치는 갯수이고 = jaccard에 비레 =
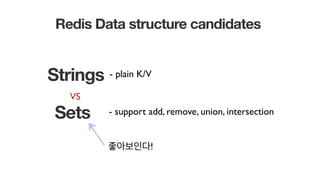
Redis Data structurecandidates
Strings
Sets - support add, remove, union, intersection
- plain K/V
좋아보인다!
VS
79.
사실 멤버십 정보를string으로 만들어 저장하는 건 귀찮다.
sig45 Tom Jerry Robert Jack
string으로 만들어 저장
“[Tom, Jerry, Robert, Jack]”
가져온 것 다시 복호화
json.dumps(data)
json.loads(data_str)
[write] [read]
“[Tom, Jerry, Robert, Jack]”
80.
하지만 승자는 String이다.왜?!
Order! O(1) vs O(N)
In [24]: %time gs.load_benchmark('user','key')
CPU times: user 0.32 s, sys: 0.03 s, total: 0.34 s
Wall time: 0.42 s
In [25]: %time gs.load_benchmark('user','set')
CPU times: user 32.34 s, sys: 0.13 s, total: 32.47 s
Wall time: 33.88 s
1)
이 경우에서는 String이 Set보다 훨씬 좋다.
string set
81.
‘redis string’ 은mget 명령이 있습니다.
(multiple get at once)
N call round trip -> 1 call
In [9]: %timeit [redis.get(s) for s in sigs]
100 loops, best of 3: 9.99 ms per loop
In [10]: %timeit redis.mget(sigs)
1000 loops, best of 3: 759 us per loop
2)
82.
3)
string 은 압축을적용하기에도 편합니다.
= 메모리에 더 많이 들고 있을 수 있단 듯이죠
compress speed(μs)
0.0
35.0
70.0
105.0
140.0
snappy zlib
134.0
17.3
size(%)
0%
25%
50%
75%
100%
snappy zlib
40%
70%
snappy쓰면
압축했는지 표도
안날정도로 빠름
83.
redis 는 pipe기능을이용해 transaction 이 됩니다.
요걸로 set의 기능들을 흉내 내는게 가능하죠
4)
item A 923 1032 58 74
item B 87 1032 123 80
item C 923 973 58 80
sig2-1032
sig2-973
A-B
C
Secondary-Index
973
sig2-1032
sig2-973
B
A-C
sig1 sig2 sig3 sig4 key:
pos-value
value:
member
case) sig2-1032의 A가 빠지면서 sig2-973에 추가 - atomic하게
minhash signature 업데이트
84.
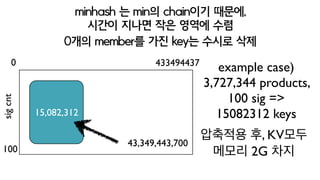
가질 수 있는궁금증
2nd index key space가 걱정입니다?
이론적으로는 hash max val * sig cnt의 key가 필요
hash max를 433,494,437인 Fibonacci primes을 쓰고
100개의 signature를 만드는 경우
이론적으론 433,494,437,00 개의 key영역 필요. 하지만.
85.
minhash 는 min의chain이기 때문에,
시간이 지나면 작은 영역에 수렴
100
15,082,312
4334944370
sigcnt
43,349,443,700
0개의 member를 가진 key는 수시로 삭제
example case)
3,727,344 products,
100 sig =>
15082312 keys
압축적용 후, KV모두
메모리 2G 미만 차지
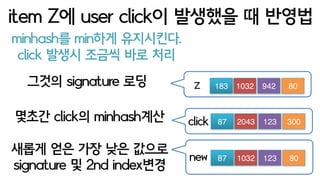
minhash를 min하게 유지시킨다.
itemZ에 user click이 발생했을 때 반영법
Z 183 1032 942 80그것의 signature 로딩
click 의 minhash계산 87 2043 123 300click
새롭게 얻은 가장 낮은 값으로
signature 및 2nd index변경
new 87 1032 123 80
click 발생시 조금씩 바로 처리
89.
어떤 item Z와닮은 것을 찾아야 한다면?
Secondary Index 가 있을 때 추천 flow
item Z 87 1032 123 80
그것의 signature 로딩 Sig1 - 87
Sig2 - 1032
Sig3 - 123
Sig4 - 80
A-B-D-F-Z
C-G-Z
A-B-D-Z
B-D-F-Zredis.mget으로 한방에 가져옴
갯수만 카운트하면, 찾기끝 A:2/4 =0.5 B:3/4 =0.75
C:1/4 =0.25 D:3/4 =0.75



















































![이 성질을 이용하면 high TPS도 대응
save minhash(110)[1 DB write] =
load minhash(100)[1 DB read] x
compute minhash(101~110)[input buffer]
old minhash new new new
local minhash
memorystorage
updated minhash
급격히 들어오면
모아서 그것만으로
선처리한다.
micro batch
뒤에 합쳐도
순차적으로 처리한
것과 같다.
(결합법칙)](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-69-320.jpg)







![사실 멤버십 정보를 string으로 만들어 저장하는 건 귀찮다.
sig45 Tom Jerry Robert Jack
string으로 만들어 저장
“[Tom, Jerry, Robert, Jack]”
가져온 것 다시 복호화
json.dumps(data)
json.loads(data_str)
[write] [read]
“[Tom, Jerry, Robert, Jack]”](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-79-320.jpg)
![하지만 승자는 String이다. 왜?!
Order! O(1) vs O(N)
In [24]: %time gs.load_benchmark('user','key')
CPU times: user 0.32 s, sys: 0.03 s, total: 0.34 s
Wall time: 0.42 s
In [25]: %time gs.load_benchmark('user','set')
CPU times: user 32.34 s, sys: 0.13 s, total: 32.47 s
Wall time: 33.88 s
1)
이 경우에서는 String이 Set보다 훨씬 좋다.
string set](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-80-320.jpg)
![‘redis string’ 은 mget 명령이 있습니다.
(multiple get at once)
N call round trip -> 1 call
In [9]: %timeit [redis.get(s) for s in sigs]
100 loops, best of 3: 9.99 ms per loop
In [10]: %timeit redis.mget(sigs)
1000 loops, best of 3: 759 us per loop
2)](https://image.slidesharecdn.com/216-150915054828-lva1-app6891/85/261-81-320.jpg)


















![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)







![[부스트캠프 Tech Talk] 진명훈_datasets로 협업하기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkjinmyunghoon-211210113319-thumbnail.jpg?width=640&height=640&fit=bounds)


![오딘: 발할라 라이징 MMORPG의 성능 최적화 사례 공유 [카카오게임즈 - 레벨 300] - 발표자: 김문권, 팀장, 라이온하트 스튜디오...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s1-221108101729-c6b32f4f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2D4]Python에서의 동시성_병렬성](https://cdn.slidesharecdn.com/ss_thumbnails/2d4pythondeview2014-140929211011-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[D2대학생세미나]산넘어 산, 음원서비스 세이렌 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/d2-140827015147-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)










![[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB](https://cdn.slidesharecdn.com/ss_thumbnails/124mongodb-181011042943-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)