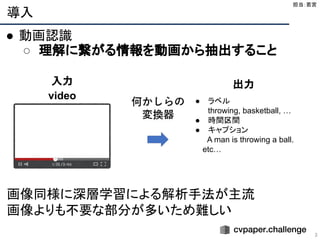
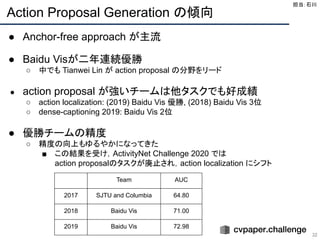
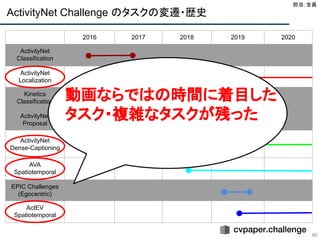
Action Proposal Generation
26
●どんなタスク?
○ CVPR workshop ActivityNet Challenge にて開催
○ 動画中の action が起こっていそうな時間区間 (Action Proposal) を予
測
○ action localization や dense-captioning のタスクにも使われる
● データセット
○ ActivityNet
■ 動画数 : 20k動画
■ 計 648 時間
● 評価指標
○ The area under the Average Recall vs Average Number of
Proposals per Video (AR-AN) with tIoU thresholds
担当:石川
27.
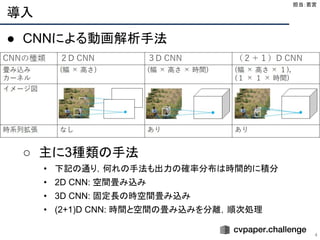
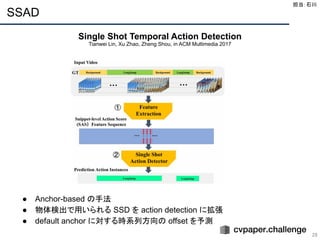
Action Proposal Generationの主な手法 (1/2)
27
Anchor-based Approaches
● マルチスケールな anchor を用いて proposal を生成
● 主な手法
○ SSAD[1]
, CBR[2]
, TURN TAP[3]
● 長所
○ マルチスケールの proposal を効果的に生成できる
○ 全ての anchor の情報を同時に捉えるため,
○ confidence score が信頼できることが多い
● 短所
○ anchor の設計が難しい
○ 正確でないことが多い
○ 様々な時系列区間を捉えるのが難しい
担当:石川
[1] T. Lin, “Single Shot Temporal Action Detection”, in ACM Multimedia 2017
[2] J. Gao, “Cascaded Boundary Regression for Temporal Action Detection”, in BMVC 2017
[3] J. Gao, “TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals” in ICCV2017
28.
Action Proposal Generationの主な手法 (2/2)
28
Anchor-free Approaches
● action boundary や actioness を評価して,proposal を生成
● 主な手法
○ TAG[1]
, BSN[2]
, BMN[3]
● 長所
○ 時系列方向の区間を柔軟に,かつ正確に proposal を生成可能
○ BSP (Boundary Sensitive Proposal) features を用いれば,
○ confidence score の信頼性が上がる
● 短所
○ feature の設計と confidence score の評価が別々で
行われるため,非効率的である
○ 特徴量が単純になりがちで,時系列方向のコンテキストを捉えるには不
十分である場合がある
○ multi-stage で,end2end なフレームワークではない
担当:石川
[1] Yue Zhao et al., “Temporal Action Detection with Structured Segment Networks” in ICCV 2017
[2] T. Lin et al., “BSN: Boundary Sensitive Network for Temporal Action Proposal Generation” in ECCV 2018
[3] T. Lin et al., “BMN: Boundary-Matching Network for Temporal Action Proposal Generation”, in ICCV 2019
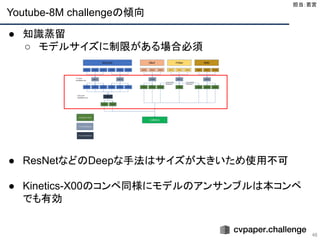
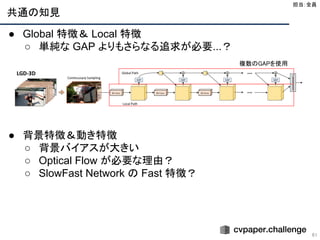
Building a SizeConstrained Predictive Model for Video Classification
[Skalic+, ECCV 2018 WS]
43
● 学会・順位
○ The 2nd YouTube-8M Large-Scale Video Understanding Challenge
の動画認識コンペの1位
● 手法
○ NetVLAD, Deep Bag of Frames, FVNet, RNNのモデルとモデルの蒸
留によって親と子を最小化するように学習
● 結果
○ GAP(評価方法) : 0.89053
担当:若宮
http://openaccess.thecvf.com/content_eccv_2018_workshops/w22/html/Skalic_Buildin
g_a_Size_Constrained_Predictive_Model_for_Video_Classification_ECCVW_2018_pa
per.html
44.
Label Denoising withLarge Ensembles of Heterogeneous Neural
Networks [Ostyakov+, ECCV 2018 WS]
44
● 学会・順位
○ The 2nd YouTube-8M
Large-Scale Video
Understanding Challengeの動
画認識コンペの2位
● 手法
○ 様々なモデルのアンサンブルし
た結果をLGBM勾配加速モデ
ルに入れて蒸留ラベルの生成
後に蒸留することで高い精度を
算出
● 結果
○ GAP : 0.88729
担当:若宮
https://arxiv.org/abs/1809.04403
45.
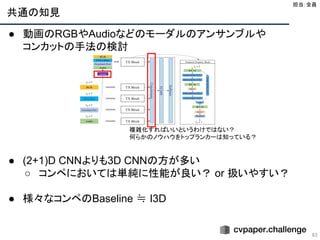
NeXtVLAD: An EfficientNeural Network to Aggregate Frame-level Features for
Large-scale Video Classification [Lin+, ECCV 2018 WS]
45
● 学会・順位
○ The 2nd YouTube-8M Large-Scale Video Understanding Challenge
の動画認識コンペの3位
● 手法
○ 高速かつ効率的な NeXtVLAD を提案
● 結果
○ GAP : 0.8798 (val)
担当:若宮
https://arxiv.org/abs/1811.05014
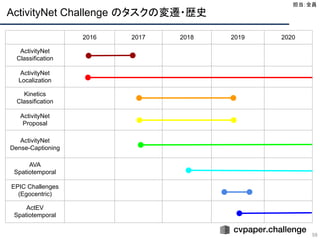
強者たち
65
● Ting Yao(ActivityNet)
○中国北京 JD AI Research
○ 様々なコンペでトップ
Rank 1 in Multi-Source Domain Adaptation Track and Rank 2 in Semi-Supervised Domain Adaptation Track of Visual Domain
Adaptation Challenge at ICCV 2019.
Rank 1 in Trimmed Activity Recognition (Kinetics) of ActivityNet Large Scale Activity Recognition Challenge at CVPR 2019.
Rank 1 in both Open-set Classification Track and Detection Track of Visual Domain Adaptation Challenge at ECCV 2018.
Rank 2 in three tasks of Dense-Captioning Events in Videos, Temporal Action Localization, and Trimmed Activity Recognition
(Kinetics) of ActivityNet Large Scale Activity Recognition Challenge at CVPR 2018.
Rank 1 in Segmentation Track of Visual Domain Adaptation Challenge at ICCV 2017.
Rank 1 in Dense-Captioning Events in Videos and Rank 2 in Temporal Action Proposals of ActivityNet Large Scale Activity
Recognition Challenge at CVPR 2017.
Rank 1 in COCO Image Captioning.
担当:全員
● JD AI Researchとは?
○ JD.COM が支持する研究団体
○ 特に最先端の AI を研究して実用化を図
るための団体
○ すでに実績はいくつか存在






![導入
10
● Kinetics: The Kinetics Human Action Video
Dataset [Key+, arXiv]
○ 行動クラス → 400 クラス!!
○ 動画数 → 300K+ 動画!!
圧倒的なデータ量!
→ 2D CNNと比較してパラメータ数が
膨大な3Dの学習を成功!!
担当:若宮
https://arxiv.org/abs/1705.06950](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-10-320.jpg)
![導入
11
● Can Spatiotemporal 3D CNNs Retrace the
History of 2D CNNs and ImageNet? [Hara+ ,
CVPR 2018]
○ 3D CNNが Kinetics を過学習せずに学習可能
○ Kinetics の学習済みモデルを使えば
UCF-101/HMDB-51やActivityNet も学習が可
能
事実上の 動画 × 3D CNN が可能となり、
動画認識の時代の開幕
担当:若宮
https://arxiv.org/abs/1711.09577](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-11-320.jpg)







![A Short Note on the Kinetics-700 Human Action Dataset
[Carreira+, arXiv]
19
● ActivityNet 2019 Kinetics-700 Challengeのタスク・データセットの
提案論文
● 手法
○ RGB のみを用いた I3D(ベースの手法として提案)
● 結果
○ Top-1 acc : 57.3%(ベースライン)
担当:若宮
https://arxiv.org/abs/1907.06987](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-19-320.jpg)
![Exploiting Spatial-Temporal Modelling and Multi-Modal Fusion for
Human Action Recognition [He+, arXiv]
20
● 学会・順位
○ ActivityNet 2018 Kinetics-600 Challenge の1位論文
● 手法
○ 従来の手法よりも空間方向と時間方向から総合的に動画を認識できる
spatial-temporal network (StNet) の提案
○ RGB・TVL1 Flow・Farneback Flow・Audio を結合する improved
temporal Xception network (iTXN) を提案
● 結果
○ Top-1 acc : 82.4%
○ モデルのアンサンブルにより Top-1 acc : 85.0%
担当:若宮
https://arxiv.org/abs/1806.10319](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-20-320.jpg)
![YH Technologies at ActivityNet Challenge 2018 [Yao+, ICCV 2018]
21
● 学会・順位
○ ActivityNet 2018 Kinetics-600 Challenge の2位論文(Ting Yao はすべ
てのコンペに参加した強者)
● 手法
○ 2D 空間畳み込みと 1D 時間方向を組み合わせた Pseudo-3D Residual
Network (P3D) を使用
○ Audio は MFCC に変換, RGB と Optical Flow では Compact Bilinear
Pooling (CBP) を使用
● 結果
○ Top-1 acc : 83.75%
担当:若宮
https://arxiv.org/abs/1807.00686](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-21-320.jpg)
![Qiniu Submission to ActivityNet Challenge 2018 [Zhang+, arXiv]
22
● 学会・順位
○ ActivityNet 2018 Kinetics-600 Challenge の3位論文 (MiT も3位)
● 手法
○ 動画から一定数のフレームをクリップする手法である temporal segment
network (TSN) とある注目点の値を特徴マップ中全てに重み付き和とし
て与えることでグローバルな特徴を学習する non-local neural network
を構成し,マルチモーダルな動画認識の方法を提案
● 結果
○ Top-1 acc : 83.5%
担当:若宮
https://arxiv.org/abs/1806.04391](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-22-320.jpg)
![Learning Spatio-Temporal Representation with Local and Global
Diffusion [Qiu+, CVPR2019]
23
● 学会・順位
○ ActivityNet 2019 Kinetics-700 Challenge の1位論文
● 手法
○ 時空間特徴学習を促進するために Local 表現と Global 表現を平行に
学習するニューラルネットワークアーキテクチャである Local and Global
Diffusion (LGD) を提案
● 結果
○ Kinetics-400 Top-1 acc : 81.2%
○ Kinetics-600 Top-1 acc : 82.7%
担当:若宮
https://arxiv.org/abs/1906.05571](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-23-320.jpg)



![Action Proposal Generation の主な手法 (1/2)
27
Anchor-based Approaches
● マルチスケールな anchor を用いて proposal を生成
● 主な手法
○ SSAD[1]
, CBR[2]
, TURN TAP[3]
● 長所
○ マルチスケールの proposal を効果的に生成できる
○ 全ての anchor の情報を同時に捉えるため,
○ confidence score が信頼できることが多い
● 短所
○ anchor の設計が難しい
○ 正確でないことが多い
○ 様々な時系列区間を捉えるのが難しい
担当:石川
[1] T. Lin, “Single Shot Temporal Action Detection”, in ACM Multimedia 2017
[2] J. Gao, “Cascaded Boundary Regression for Temporal Action Detection”, in BMVC 2017
[3] J. Gao, “TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals” in ICCV2017](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-27-320.jpg)
![Action Proposal Generation の主な手法 (2/2)
28
Anchor-free Approaches
● action boundary や actioness を評価して,proposal を生成
● 主な手法
○ TAG[1]
, BSN[2]
, BMN[3]
● 長所
○ 時系列方向の区間を柔軟に,かつ正確に proposal を生成可能
○ BSP (Boundary Sensitive Proposal) features を用いれば,
○ confidence score の信頼性が上がる
● 短所
○ feature の設計と confidence score の評価が別々で
行われるため,非効率的である
○ 特徴量が単純になりがちで,時系列方向のコンテキストを捉えるには不
十分である場合がある
○ multi-stage で,end2end なフレームワークではない
担当:石川
[1] Yue Zhao et al., “Temporal Action Detection with Structured Segment Networks” in ICCV 2017
[2] T. Lin et al., “BSN: Boundary Sensitive Network for Temporal Action Proposal Generation” in ECCV 2018
[3] T. Lin et al., “BMN: Boundary-Matching Network for Temporal Action Proposal Generation”, in ICCV 2019](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-28-320.jpg)



![Dense Captioning Events in Videos
34
● どんなタスク?
○ 与えられた動画に対して複数イベントのタイムスタンプ・キャプションを出
力するタスク
○ 動画理解に深くアプローチする!
● データセット: ActivityNet Captions [Krishna+, ICCV 2017]
● 評価方法:tIoU 閾値ごとの METEOR の平均
担当:笠井](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-34-320.jpg)
![Dense Captioning Events in Videos [Krishna+, ICCV 2017]
35
● タスク・データセットの提案論文
● 手法
○ 行動候補領域の表現に、他のイベントの表現を付加した過去・未来の情
報を追加してキャプショニングを行う
● 結果
○ METEOR : 4.82 (この数値がベースラインとなる)
担当:笠井
https://arxiv.org/abs/1705.00754](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-35-320.jpg)
![RUC+CMU: System Report for Dense Captioning Events in Videos
[Shizhe+, CVPR WS 2018]
36
● 学会・順位
○ 2018 Challenge にて優勝手法となった論文
● 手法
○ クリップ分割ののち特徴抽出・スライディングウィンドウで候補領域取得・
尤度 s_p 算出
○ キャプションモデルのアンサンブルで尤度 s_c 算出、SCST 使用
○ 最後にキャプション・候補領域を s = s_p * s_c を用いてリランキングを行
い最終的な予測結果を得る
● 結果
○ METEOR : 8.524
担当:笠井
https://arxiv.org/abs/1806.08854](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-36-320.jpg)
![End-to-End Dense Video Captioning with Masked Transformer [Zhou+,
CVPR 2018]
37
担当:笠井
● 学会・順位
○ CVPR 2018 (Challenge には載っていない?)
● 手法
○ Transformer を用いて End-to-end Dense Captioning を達成
○ Action Proposal を微分可能にしてキャプションの情報をフィードバックし
ている
● 結果
○ (val METEOR : 9.56)
https://arxiv.org/abs/1804.00819](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-37-320.jpg)
![Streamlined Dense Video Captioning [Mun+, CVPR 2019]
38
● 学会・順位
○ CVPR 2019
● 手法
○ Action Proposal, Event Sequence Detection, Captioning のフロー
○ Event Sequence Generation Network が Pointer Networks を使用
● 結果
○ (val METEOR : 13.07)
担当:笠井
https://arxiv.org/abs/1904.03870](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-38-320.jpg)
![Exploring Contexts for Dense Captioning Events in Videos
[Shizhe+, CVPR WS 2019]
39
● 学会・順位
○ CVPR 2019 Challenge 優勝手法
● 手法
○ Intra-event や Inter-event のキャプショニングモデルを採用して イベント
間の関係をモデリング
○ 特徴量としては時間情報や物体情報・マルチモーダル情報を活用
● 結果
○ METEOR : 9.90
担当:笠井
https://arxiv.org/abs/1907.05092](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-39-320.jpg)



![Building a Size Constrained Predictive Model for Video Classification
[Skalic+, ECCV 2018 WS]
43
● 学会・順位
○ The 2nd YouTube-8M Large-Scale Video Understanding Challenge
の動画認識コンペの1位
● 手法
○ NetVLAD, Deep Bag of Frames, FVNet, RNNのモデルとモデルの蒸
留によって親と子を最小化するように学習
● 結果
○ GAP(評価方法) : 0.89053
担当:若宮
http://openaccess.thecvf.com/content_eccv_2018_workshops/w22/html/Skalic_Buildin
g_a_Size_Constrained_Predictive_Model_for_Video_Classification_ECCVW_2018_pa
per.html](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-43-320.jpg)
![Label Denoising with Large Ensembles of Heterogeneous Neural
Networks [Ostyakov+, ECCV 2018 WS]
44
● 学会・順位
○ The 2nd YouTube-8M
Large-Scale Video
Understanding Challengeの動
画認識コンペの2位
● 手法
○ 様々なモデルのアンサンブルし
た結果をLGBM勾配加速モデ
ルに入れて蒸留ラベルの生成
後に蒸留することで高い精度を
算出
● 結果
○ GAP : 0.88729
担当:若宮
https://arxiv.org/abs/1809.04403](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-44-320.jpg)
![NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for
Large-scale Video Classification [Lin+, ECCV 2018 WS]
45
● 学会・順位
○ The 2nd YouTube-8M Large-Scale Video Understanding Challenge
の動画認識コンペの3位
● 手法
○ 高速かつ効率的な NeXtVLAD を提案
● 結果
○ GAP : 0.8798 (val)
担当:若宮
https://arxiv.org/abs/1811.05014](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-45-320.jpg)


![Moments in Time Dataset: one million videos for event understanding
[Monfort+, IEEE 2019]
49
● 学会・順位
○ Moments in Time Challenge 2018 のタスク・データセットの提案論文
● 手法
○ 様々な手法を実験(右図)
● 結果
○ Top-1 acc : 0.3116
担当:若宮
https://arxiv.org/abs/1801.03150](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-49-320.jpg)
![Team DEEP-HRI Moments in Time Challenge 2018 Technical Report
[Li+, CVPR 2018 WS]
50
● 学会・順位
○ Moments in Time Challenge 2018の動画認識コンペの1位
● 手法
○ 提案するMV-CNNと2018年にSoTAであった手法のモデルアンサンブル
○ モデルアンサンブル時にはオプティカルフローは未使用
○ AudioはResNetを用いて認識
● 結果
○ Top-1 acc : 0.3864
担当:若宮
http://moments.csail.mit.edu/challenge2018/DEEP_HRI.pdf](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-50-320.jpg)
![Submission to Moments in Time Challenge 2018
[Li+, CVPR 2018 WS]
51
● 学会・順位
○ Moments in Time Challenge 2018の動画認識コンペの2位
● 手法
○ RGB情報をI3D ResNet50, Xception, SENetで認識, 動き情報をTV-L1
で Optical Flow を取得してから BN-Inception で認識, 音情報を
VGG16 で認識してそれぞれ5つのモデルをアンサンブルにすることで高
い認識精度を出力
● 結果
○ Top-1 acc : 0.3750
担当:若宮
http://moments.csail.mit.edu/challenge2018/Megvii.pdf](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-51-320.jpg)
![Multi-Moments in Time: Learning and Interpreting Models for
Multi-Action Video Understanding [M. Monfort+, arXiv]
52
● 学会・順位
○ Moments in Time Challenge
2019 のタスク・データセットの
提案論文
● 手法
○ I3D を軸に様々な手法を実験
(右図)
● 結果
○ Top-1 acc : 0.593
担当:若宮
https://arxiv.org/abs/1911.00232](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-52-320.jpg)
![Alibaba-Venus at ActivityNet Challenge 2018 - Task C Trimmed Event
Recognition (Moments in Time) [Chen+, CVPR 2018 WS]
53
● 学会・順位
○ Moments in Time Challenge
2018 の動画認識コンペの4位
● 手法
○ 様々なモデルを実験し、TRN
(下図)に時間方向のアテンショ
ン機構を追加
● 結果
○ Top-1 acc : 0.3551
担当:若宮
http://moments.csail.mit.edu/challenge2018/Alibaba_Venus.pdf](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-53-320.jpg)
![Team Efficient Multi-Moments in Time Challenge 2019 Technical Report
[Zhang+, ICCV 2019 WS]
54
● 学会・順位
○ Moments in Time Challenge 2019 の動画認識コンペの1位
● 手法
○ TSN, TRN以外にも新たにシフト距離と特定の入力データとの関係を学
習するネットワークである Temporal Interlacing Network (TIN) を提案
○ SlowFast やその改良型も実験
● 結果
○ mAP : 0.6077
担当:若宮
http://moments.csail.mit.edu/challenge2019/efficient_challenge_report.pdf](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-54-320.jpg)
![Alibaba-AIC: Submission to Multi-Moments in Time Challenge 2019
[Li+, ICCV 2019 WS]
55
● 学会・順位
○ Moments in Time Challenge 2019 の動画認識コンペの2位
● 手法
○ マルチラベルタスクのラベルに着目したことから焦点損失関数とラベル相
関関数を結合した損失関数を使用
● 結果
○ mAP : 0.6051
担当:若宮
http://moments.csail.mit.edu/challenge2019/Alibaba-AIC_challenge_report.pdf](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-55-320.jpg)
![Team SPEEDY Multi Moments in Time Challenge 2019 Technical Report [Liu+,
ICCV 2019 WS]
56
● 学会・順位
○ Moments in Time Challenge 2019 の動画認識コンペの3位
● 手法
○ 各モダリティ情報の集合からコンテキスト情報を抽出して最大限に動画認
識に使う speed expert を新たに提案
● 結果
○ mAP : 0.5810
担当:若宮
http://moments.csail.mit.edu/challenge2019/speedy_challenge_report.pdf](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-56-320.jpg)
![Continuous Tracks CNN and Non-local Gating for Multi-class Video
Understanding [Yu+, ICCV 2019 WS]
57
● 学会・順位
○ Moments in Time Challenge
2019 の動画認識コンペの4位
● 手法
○ SlowFast を改良した新たなモデ
ルである CT-CNN と短時間の動
画から複数の行動ラベルを出力
するためのNon-Local Gating モ
デルを提案
● 結果
○ mAP : 0.4858
担当:若宮
http://moments.csail.mit.edu/challenge2019/SNUVL-RIPPLE_challenge_report.pdf](https://image.slidesharecdn.com/2020metavideorecogv4-200408091537/85/Towards-Performant-Video-Recognition-57-320.jpg)

















![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)





















