Download as PDF, PPTX





![cvpaper.challengeの論⽂ @CVPR 2019
5
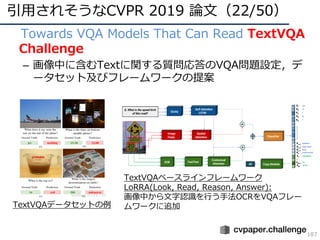
– Yue Qiu, Yutaka Satoh, Hirokatsu Kataoka, Ryota Suzuki, "Incorporating Depth into Visual
Question Answering", in CVPR 2019 Workshop on Visual Question Answering and Dialog.
– Yue Qiu, Yutaka Satoh, Hirokatsu Kataoka, Ryota Suzuki, "Visual Question Answering with
RGB-D Images", in CVPR 2019 Workshop on Women in Computer Vision (WiCV).
– Kota Yoshida, Munetaka Minoguchi, Kazuki Tsubura, Kazushige Okayasu, Seito Kasai, Akio
Nakamura, Hirokatsu Kataoka, “Which generates better jokes, hand-crafted features or deep
features,” CVPR 2019 Language & Vision Workshop, 2019.
– Hirokatsu Kataoka, Kaori Abe, Munetaka Minoguchi, Akio Nakamura, Yutaka Satoh, "Ten-
million-order Human Database for World-wide Fashion Culture Analysis", in CVPR 2019
Workshop on Understanding Subjective Attributes of Data, Focus on Fashion and Subjective
Search (FFSS-USAD). (Oral) [PDF] [Oral] [Poster]
– Seito Kasai, Yuchi Ishikawa, Tenga Wakamiya, Kensho Hara, Hirokatsu Kataoka, “AIST Team
submission for Task 3: Dense-Captioning Events in Videos,” CVPR 2019 Workshop,
International Challenge on ActivityNet Challenge, 2019.
– Tenga Wakamiya, Kensho Hara, Yuchi Ishikawa, Seito Kasai, Hirokatsu Kataoka, “AIST
Submission for ActivityNet Challenge 2019 in Trimmed Activity Recognition (Kinetics),” CVPR
2019 Workshop, International Challenge on ActivityNet Challenge, 2019.
– 論⽂/プレゼン資料等のダウンロードこちら http://hirokatsukataoka.net/](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-5-320.jpg)







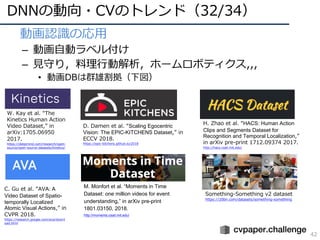
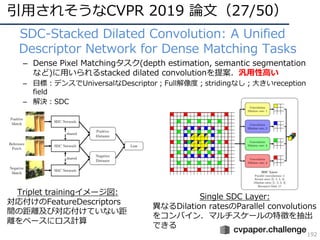
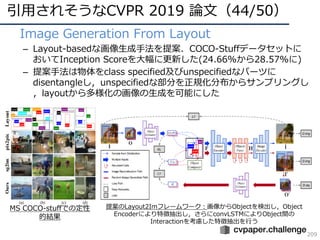
![DNNの動向・CVのトレンド(7/34)
17
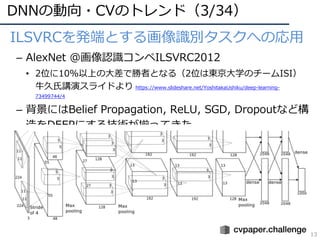
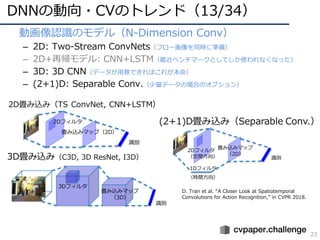
• 構造の深化(2014〜2016)
– 2014年頃から「構造をより深くする」ための知⾒が整う
– 現在(主に画像識別で)主流なのはResidual Network
AlexNet [Krizhevsky+, ILSVRC2012]
VGGNet [Simonyan+, ILSVRC2014]
GoogLeNet [Szegedy+, ILSVRC2014/CVPR2015]
ResNet [He+, ILSVRC2015/CVPR2016]
ILSVRC2012 winner,DLの⽕付け役
16/19層ネット,deeperモデルの知識
ILSVRC2014 winner,22層モデル
ILSVRC2015 winner, 152層!(実験では103+層も)](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-17-320.jpg)

![DNNの動向・CVのトレンド(9/34)
19
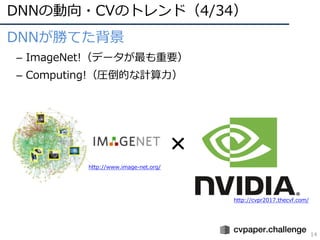
• 他タスクへの応⽤(画像認識・動画認識)
– 物体検出: R-CNN, Fast/Faster R-CNN, YOLO, SSD,,,
– 領域分割: FCN, SegNet, U-Net,,,
– Vision & Language: 画像説明⽂, VQA, Visual Dialog,,,
– 動画認識: Two-stream ConvNets, 3D Conv., (2+1)D Conv. ,,,
Person
Uma
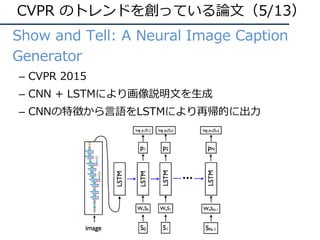
Show and Tell [Vinyals+, CVPR15]
R-CNN [Girshick+, CVPR14]
FCN [Long+, CVPR15]
Two-Stream CNN [Simonyan+, NIPS14]](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-19-320.jpg)
![DNNの動向・CVのトレンド(10/34)
20
Hito
Uma
Haar-like [Viola+, CVPR01]
+ AdaBoost
Fast R-CNN [Girshick, ICCV15]
ROI Pooling, Multi-task Loss Faster R-CNN [Ren+, NIPS15]
RPN
・・・
・・・
R-CNN時代(それ以前は”Hand-crafted” ObjectNess)⾼速化 & ⾼精度化
One-shot Detector時代 兎にも⾓にも(精度を保ちつつ)⾼速化
YOLO(v1)/v2/v3 [Redmon+,
CVPR16/CVPR17/arXiv18]
One-shot detector, w/ full-connect layer
・・・
Latest Algorithm 精度重視,⾼速
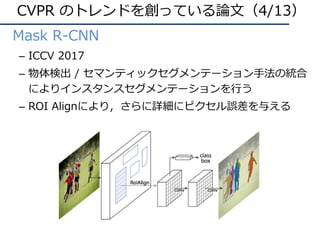
Mask R-CNN [He+, ICCV17]
RoI Align, Det+Seg
・・・
bbox+segmentationのラ
ベルが同時に⼿に⼊るなら
Mask R-CNNを試そう
41.8AP@MSCOCO
bboxのみが⼿に⼊
るならRetinaNetを
⽤いるのがベター
40.8AP@MSCOCO
SSD [Liu+, ECCV16]
One-shot detector, Anchor Box
Hand-crafted feature時代 基礎/枠組みの構築
HOG [Dalal+, CVPR05]
+ SVM
ICF [Dollár+, BMVC09]
+ Soft-cascade
DPM [Felzenszwalb+,
TPAMI12]
+ Latent SVM
・・・
• 物体検出の流れ
R-CNN [Girshick, CVPR14]
Selective Search + CNN](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-20-320.jpg)
![DNNの動向・CVのトレンド(11/34)
21
• セマンティック/インスタンスセグメンテーション
• ・・・ピクセルごとにラベルを回帰
– デファクトスタンダードはまだ覇権争い?
– 問題を細分化して解いている印象
• ⽂脈把握, スケール変動, データ不⾜
FCN [Long, CVPR2015]
全層畳み込み,チャネル和
SegNet [Kendall, arXiv2015]
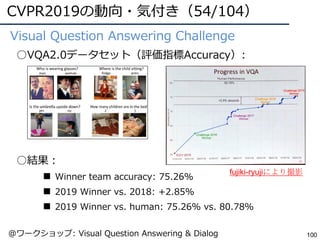
U-Net [Ronneberger, MICCAI2015]
位置情報保持,チャネル連結
・・・ ベースアルゴリズム ・・・
精度重視
Mask R-CNN [He, ICCV2017]
RoI Align, Det+Seg
・・・
物体検出とインスタンスセグメ
ンテーションのタスクを同時に
学習することで双⽅を相補的に
改善している
DeepLab(v1,v2,v3) [Chen, TPAMI2017]
Dilated Conv, 特徴マップの並列化
※下はセマンティック/インスタンスセグメンテーションを両⽅含む](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-21-320.jpg)

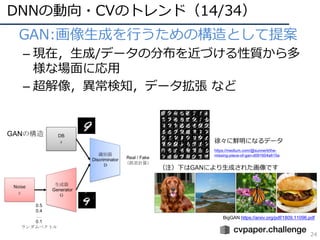
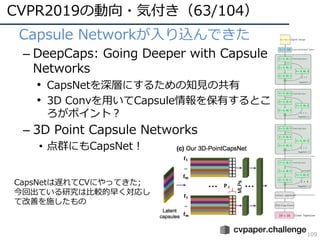
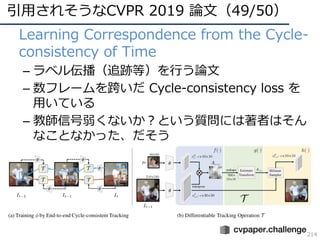
![DNNの動向・CVのトレンド(15/34)
25
• GANの主要な流れ
1. GAN(オリジナルのGAN)
• [Goodfellow, NIPS2014] https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
2. DCGAN(畳み込み層の使⽤)
• [Radford, ICLR2016] https://arxiv.org/abs/1511.06434
3. Pix2Pix(pixel同⼠が対応付くという意味でConditionalなGAN)
• [Isola, CVPR2017] https://arxiv.org/abs/1611.07004
4. CycleGAN(pix2pixの教師なし版)
• [Zhu, ICCV2017] https://arxiv.org/pdf/1703.10593.pdf
5. ACGAN(カテゴリ識別も同時に実施してコンディションとした)
• [Odera, ICML2017] https://arxiv.org/abs/1610.09585
6. WGAN/SNGAN(学習安定化)
• [Arjovsky, ICML2017] http://proceedings.mlr.press/v70/arjovsky17a.html
• [Miyato, ICLR2018] https://arxiv.org/abs/1802.05957
7. PGGAN(⾼精度化)
• [Karras, ICLR2018] https://arxiv.org/abs/1710.10196
8. Self-Attention GAN(アテンション機構を採⽤)
• [Zhang, arXiv 1805.08318] https://arxiv.org/abs/1805.08318
9. BigGAN(超⾼精細GAN)
• [Brock, ICLR2019] https://arxiv.org/abs/1809.11096
# 2018年10⽉時点での調査](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-25-320.jpg)



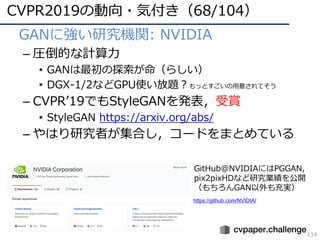
![DNNの動向・CVのトレンド(19/34)
29
転移学習(Transfer Learning)の網羅的調査
– Taskonomy [Zamir, CVPR2018]
• CVPR 2018 Best Paper Award
• 26種のタスク間の関連性を調べる
– CVの歴史の中で別々に議論されたいたサブタスクを繋げる
– 効果を最⼤化する転移学習の関係性を明らかにした
http://taskonomy.stanford.edu/
データセットは26タスクに対しラベル付け
Task Similarity Tree: 類似するタスク間の関
係性を可視化](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-29-320.jpg)
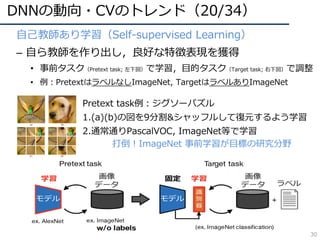
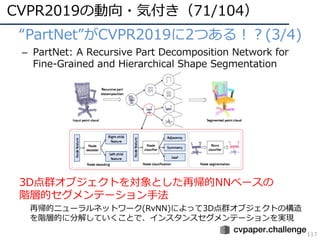
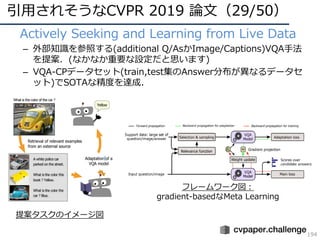
![DNNの動向・CVのトレンド(21/34)
31
• 教師あり学習 vs. 無教師/弱教師
– 少量/無 ラベルで教師あり学習に勝つ!
• How good is my GAN?: 勝てなかったがGANによるデータ拡張の⽅針を⽰す
• 6D Object Detection: 条件付だがこの⽂脈で勝利(ECCVʼ18 BestPaper)
• Cut/Paste Learn: 9割くらいの精度まで来た
[Sundermeyer, ECCV2018]Oral,BP
ラベル無しCGデータで実時間6D検出,
さらに教師有りを倒した
[Remez, ECCV2018]Oral
Cut/Pasteで既存セグメントラベルを増
加,教師有りに接近する精度
[Shmelkov, ECCV2018]
GANの評価法提案,追加実験のデー
タ拡張がポイント](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-31-320.jpg)


![DNNの動向・CVのトレンド(24/34)
34
• 超越(Beyond)/再考(Rethink) ImageNet
学習回数が多くなると
scratch/ pre-trainの精度が
同等に
通常の学習回数ではImageNet Pre-
trainが強く⾒えている、、、
[Mahajan, ECCV2018]
FBはSNSのHashtagでラベル付けなし,弱教師付きの3.5B枚画像DB構築
【超越】
Top-1: 85% w/ ResNeXt-101
ラベルはSNSの再利⽤
https://venturebeat.com/2018/05/02/facebook-is-using-instagram-photos-and-hashtags-to-improve-its-computer-vision/
ImageNetは他のタスクの精度向上に貢献する?
• しない(左図参照)
• スクラッチで⻑く学習すれば同等の精度まで到達
– ただし,10K以上のラベルは必要
• 収束は早くなったので,研究ペース促進に寄与
無/弱/半教師付きの⽂脈で⼤量画像とその教
師を与えられればモデルを強化できる
【再考】 [He, arXiv2018]
タスクに即した事前学習をする(物体検知なら物体検知の事前学習)](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-34-320.jpg)
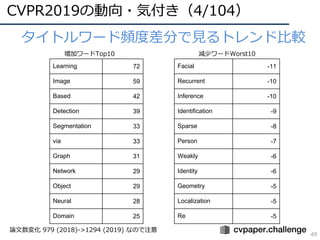
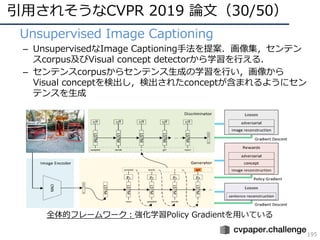
![DNNの動向・CVのトレンド(25/34)
35
• 動画DBの⼤規模化
– 動画共有サイトのタグ付け
– 画像識別の動画版
Kinetics [Kay, arXiv2017]
Moments in Time [Monfort, arXiv2018] YouTube-8M
Kinetics-700 Moments in Time
700カテゴリ/650,000+動画 339カテゴリ/1,000,000+動画 3,862カテゴリ/6,000,000+動画
YouTube-
8M
【最近の代表的な動画データセット】
10万/100万を超える動画数のデータセットが登場,画像
識別に変わるネクストトレンドとして位置づけられる
https://research.google.com/youtube8m/](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-35-320.jpg)



![DNNの動向・CVのトレンド(29/34)
39
• ⾃動運転/ADAS(Self-Driving Cars/ADAS)
– 国際会議の研究(検知など単純タスク)は減少傾向, 実利⽤に向け開発?
– 数年前はKITTI datasetに対しての精度競争が盛ん
– 現在は⾃動運転の解釈性,ニアミスシーンの解析等
KITTI: Autonomous driving benchmark
物体検出,ステレオ視,セグメンテ
ーション問題を提供Optical Flow Stereo Matching Object Detection
Road Odometry Semantic Segmentation
[Geiger, CVPR2012]
[Kim, ICCV2017]
⾃動運転時の解釈性,物体検知の際
にどこを参照したか?
事故に近いシーンを認識,予測
[Suzuki&Kataoka,
CVPR2018]](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-39-320.jpg)
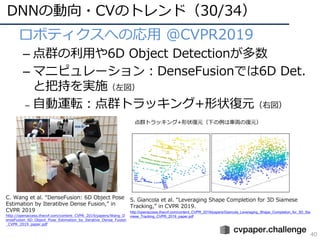






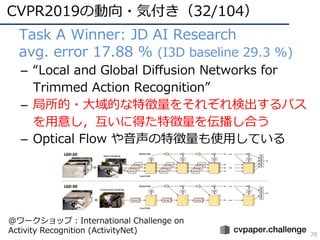
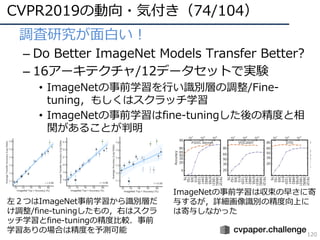
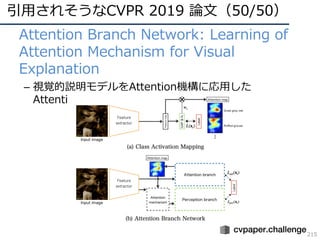
![CVPR2019の動向・気付き(5/104)
50
論⽂増加分⽐率考慮版タイトルワード増減
増加ワードTop10 減少ワード
Worst10
Based 23.3
Graph 21.0
Adaptive 14.2
Image 13.7
Representation 12.7
Detection 12.7
Metric 12.4
Search 12.1
Domain 12.1
via 11.8
Scene 11.0
Deep -25.9
Identification -15.1
Person -14.8
Recurrent -13.2
Pose -13.0
Facial -12.9
Video -12.5
Visual -12.3
Inference -11.7
Weakly -11.6
Re -11.6
更に
常識化?
中身を
見たい?
内部表現を
見たい?
記号化?
よりDNNの内部的な部分への興味シフト?ドメイン適応が⼈気か
※計算:[2019]*979/1293 - [2018]](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-50-320.jpg)























































![CVPR2019の動向・気付き(67/104)
113
• 認識系だとFAIRが強い (2/2)
– アーキテクチャ/物体検出のトレンドを創出
• さらに積み上げて次のトレンドを創造
• Faster R-CNN, ResNetの考案者
-> ResNeXt (CVPRʼ17), Focal Loss (ICCVʼ17 Student
Best), Mask R-CNN (ICCVʼ17 Marr Prize)提案
– Facebookのデータ基盤
• Instagramからのデータ収集(Instagram-3.5B)
[Mahajan+, ECCV18]
FBはSNSのHashtagでラベル付けなし,弱教
師付きの3.5B枚画像DB構築
Instagramからの⾼速なデータ収集に
よりモデルの更新なしにImageNetの
SOTA達成](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-113-320.jpg)












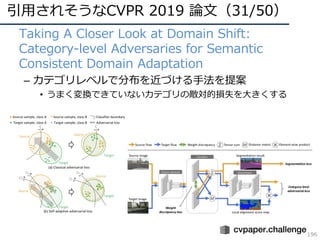
![CVPR2019の動向・気付き(83/104)
129
• Alexei Efros(UC Berkeley)
– Potential Liabilities / Future Regrets...
• Explanability
– Explanations are subjective
– Unreasonable Effectiveness of Data [Halevy et al.,
2009]
– Magic of Data
• Datasets
– 同じ画像は⼆度⾒ない,起こらない(データセットによりズ
ルしてしまう)
– 何度もOverfit / Cheating してしまう
– どうすればよい?
• ⽉に向かってハシゴを登るか,遠吠えを続けるか?
• いや,後悔を少なくして最⾼にノスタルジア(後から
良かった) を感じよう!](https://image.slidesharecdn.com/cvpr19reportfinalize-190621010557/85/CVPR-2019-129-320.jpg)































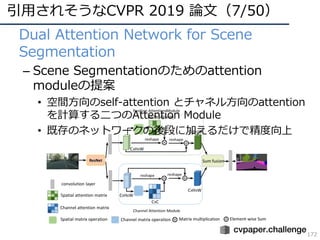

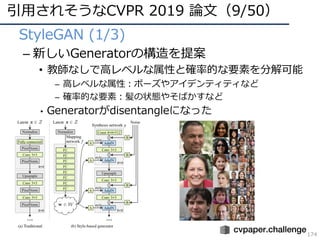
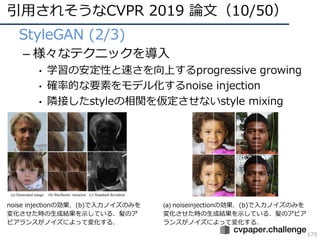


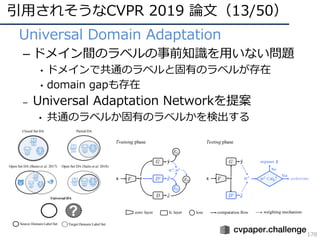







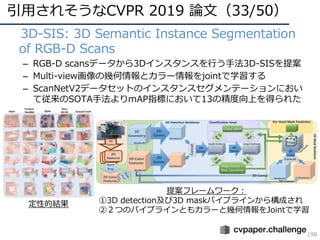
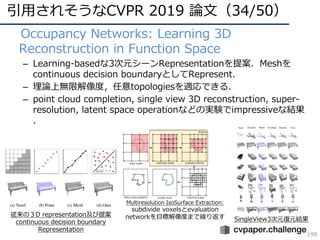

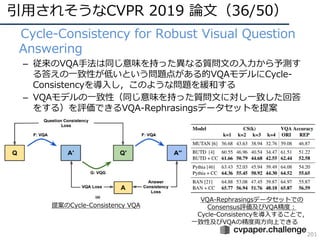

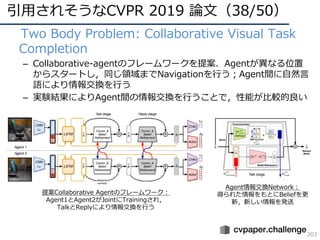



















CVPR 2019 ( http://cvpr2019.thecvf.com/ )の参加速報を書きました。 この資料には下記の項目が含まれています。 ・DNNの動向・CVのトレンド(DNNの流れとCVにおけるトレンドの変遷) ・CVPR 2019での動向や気付き ・最近のトレンドを創っている/引用されそうな論文 ・今後の方針 (・CVPR 2019の論文まとめはこちらにあります Link: http://xpaperchallenge.org/cv/survey/cvpr2019_summaries/ ) cvpaper.challengeはコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有しています。 http://xpaperchallenge.org/cv/



![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)



















