Download as PDF, PPTX








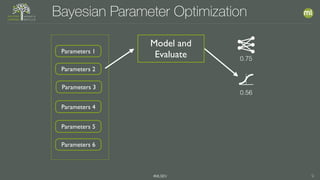





















1) Bayesian parameter optimization uses machine learning to predict the performance of untrained models based on parameters from previous models to efficiently search the parameter space. 2) However, there are still important issues like choosing the right evaluation metric, ensuring no information leakage between training and test data, and selecting the appropriate model for the problem and available data. 3) Automated model selection requires sufficient data to make accurate predictions; with insufficient data, the process can fail.























































































