Download as PDF, PPTX




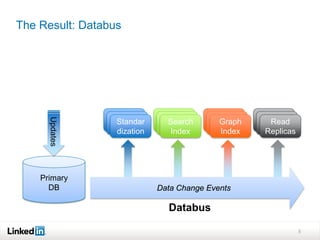


















The LinkedIn Databus is a change data capture pipeline designed to ensure consistent data flow while addressing challenges like database pressure and data extraction complexity. It features key design decisions including logical clocks for data portability and a pull model for consumer management, aiming to scale for high availability and low latency. The implementation uses Avro for schema management and has demonstrated both benefits and challenges in production, with ongoing efforts to enhance performance and scalability.












































































