Download as PDF, PPTX






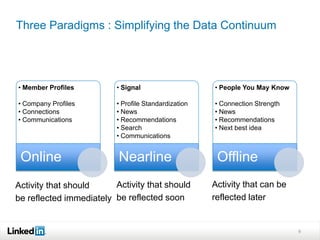
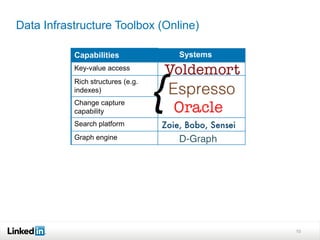
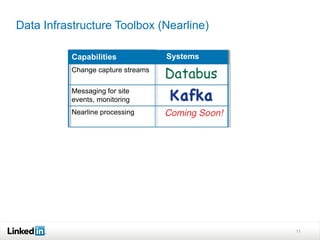

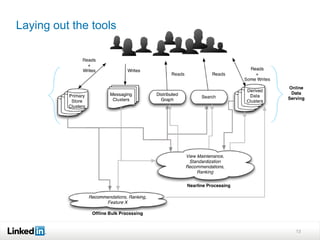

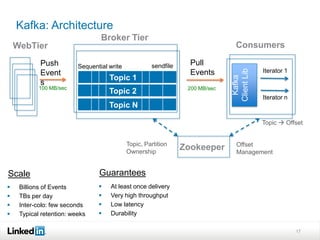

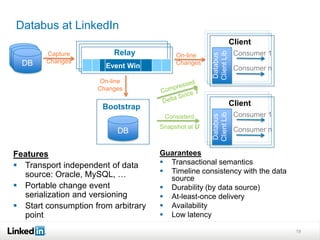
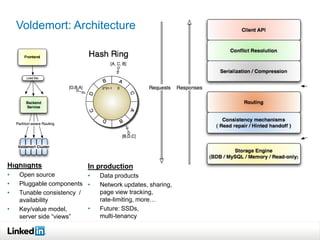



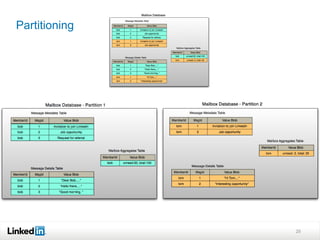
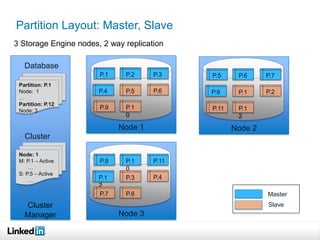
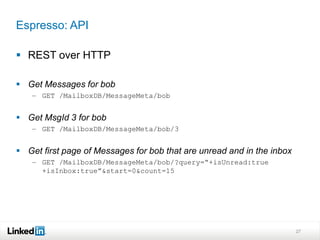
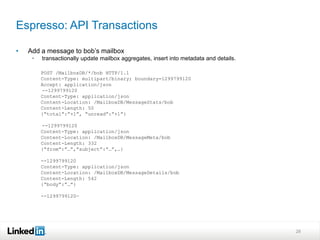
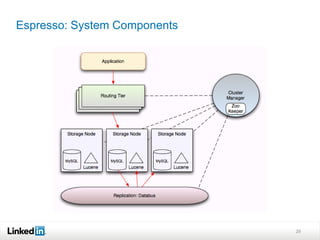

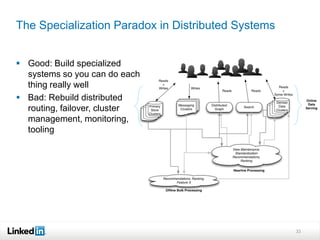
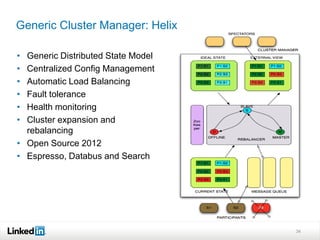





This document discusses LinkedIn's data infrastructure. It describes how LinkedIn handles large volumes of user data across online, nearline and offline systems. Key systems discussed include Kafka for messaging, Databus for change data capture, Voldemort for online key-value storage, and Espresso for indexed, timeline-consistent distributed storage. Espresso provides a rich data model and APIs for applications to access user data.






















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



