Downloaded 247 times












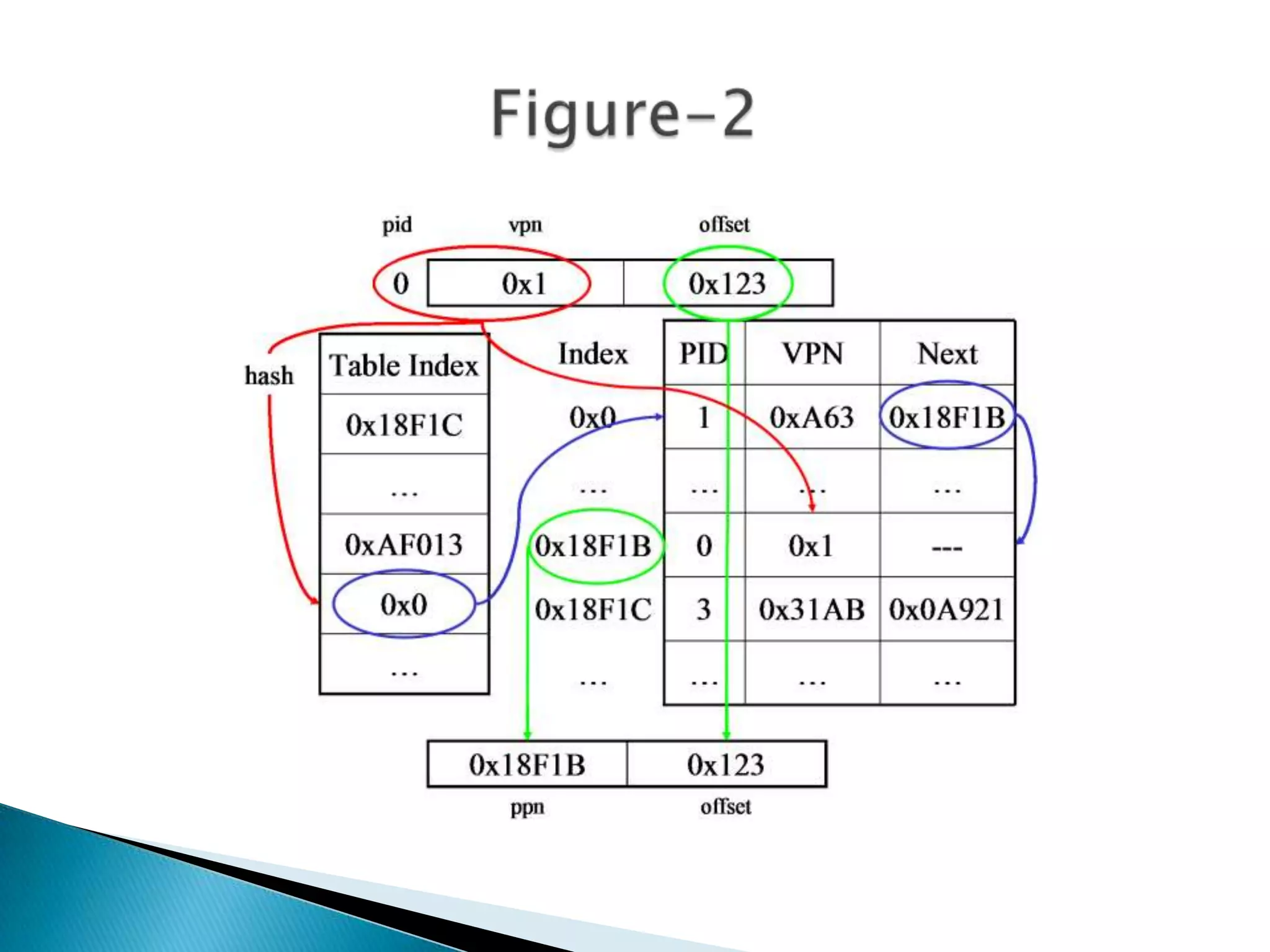
![Figure 1: Translation procedure using a linear inverted
page table. Info bits exist in each entry, though they
are not shown.
If a chain is exhausted by hitting an invalid next pointer, a
page fault results. The translation process is
illustrated in figure 2.
Assuming a good hash function, the average chain length
should be about 1.5, so only 2.5 memory
accesses are required on average to translate an address
[1]. This is pretty good, considering a two-level page
table requires 2 accesses. Caching can still improve the
access time considerably.](https://image.slidesharecdn.com/assignment-2rizwansir-131027044612-phpapp02/75/Operating-System-Multilevel-Paging-Inverted-Page-Table-16-2048.jpg)
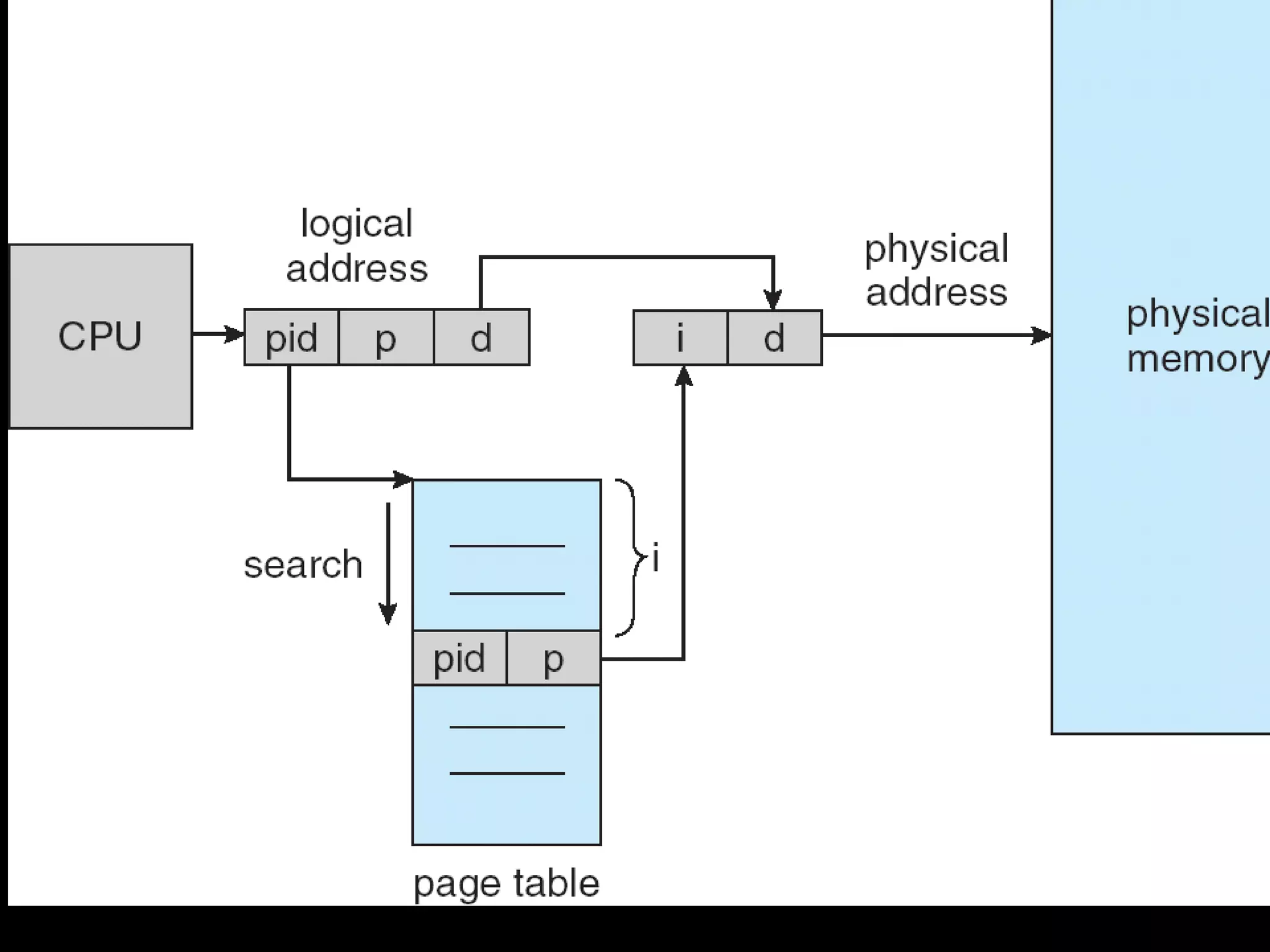



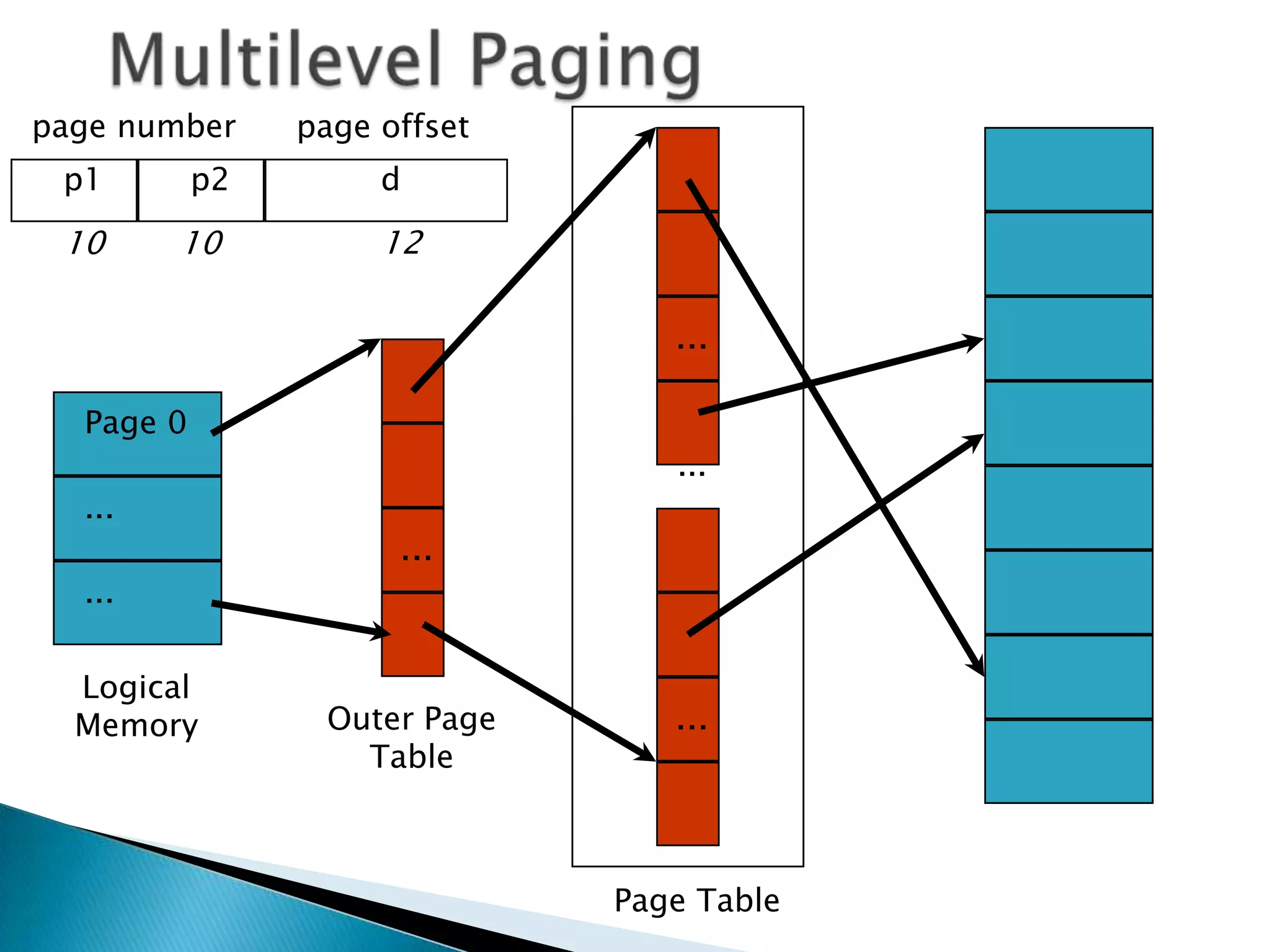
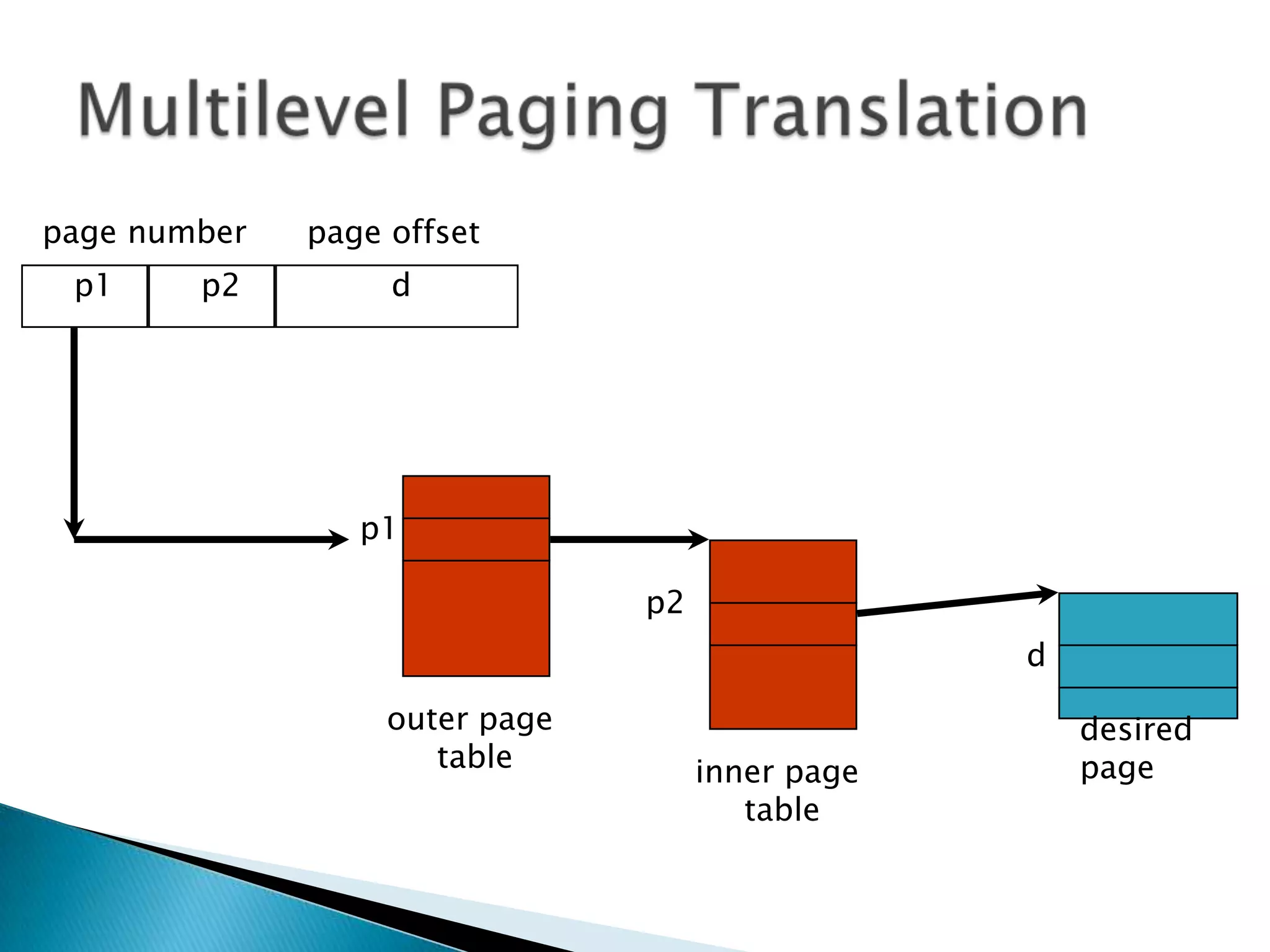
Two-level paging is used to divide the large page table into smaller pieces called page tables. A logical address is divided into a page number and page offset, and the page number is further divided to index the outer page table and inner page table. Inverted page tables store one entry per physical page with the owning process and virtual page number instead of physical addresses. This reduces the page table size significantly but increases translation time. Hashed inverted page tables add a hash table to map process/virtual page number pairs to page table entries, reducing average translation time.



































































