第53回 コンピュータビジョン勉強会@関東 CVPR2019読み会(前編) 発表資料。 Speaker Deck版: https://speakerdeck.com/shinya7y/neural-rejuvenation


![LWC (Learning both Weights and Connections) [Song Han+, NIPS2015]
• DNNは無駄にでかいので小さくしたい
• 絶対値が小さい重み(シナプス)をpruning
• あるニューロンの 入力シナプス全て or 出力シナプス全て が 0 なら
そのニューロンもpruning可能
・pruning後の構造が不規則
- 専用のハードウェア・ライブラリが無いと効果が薄い
- conv層の削減に向かない](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-4-2048.jpg)
![Pruning Filters for Efficient ConvNets [Hao Li+, ICLR2017]
・pruningに対する各層のsensitivityを分析し、
pruning比率を決める必要がある
[Huizi Mao+, CVPRW2017]
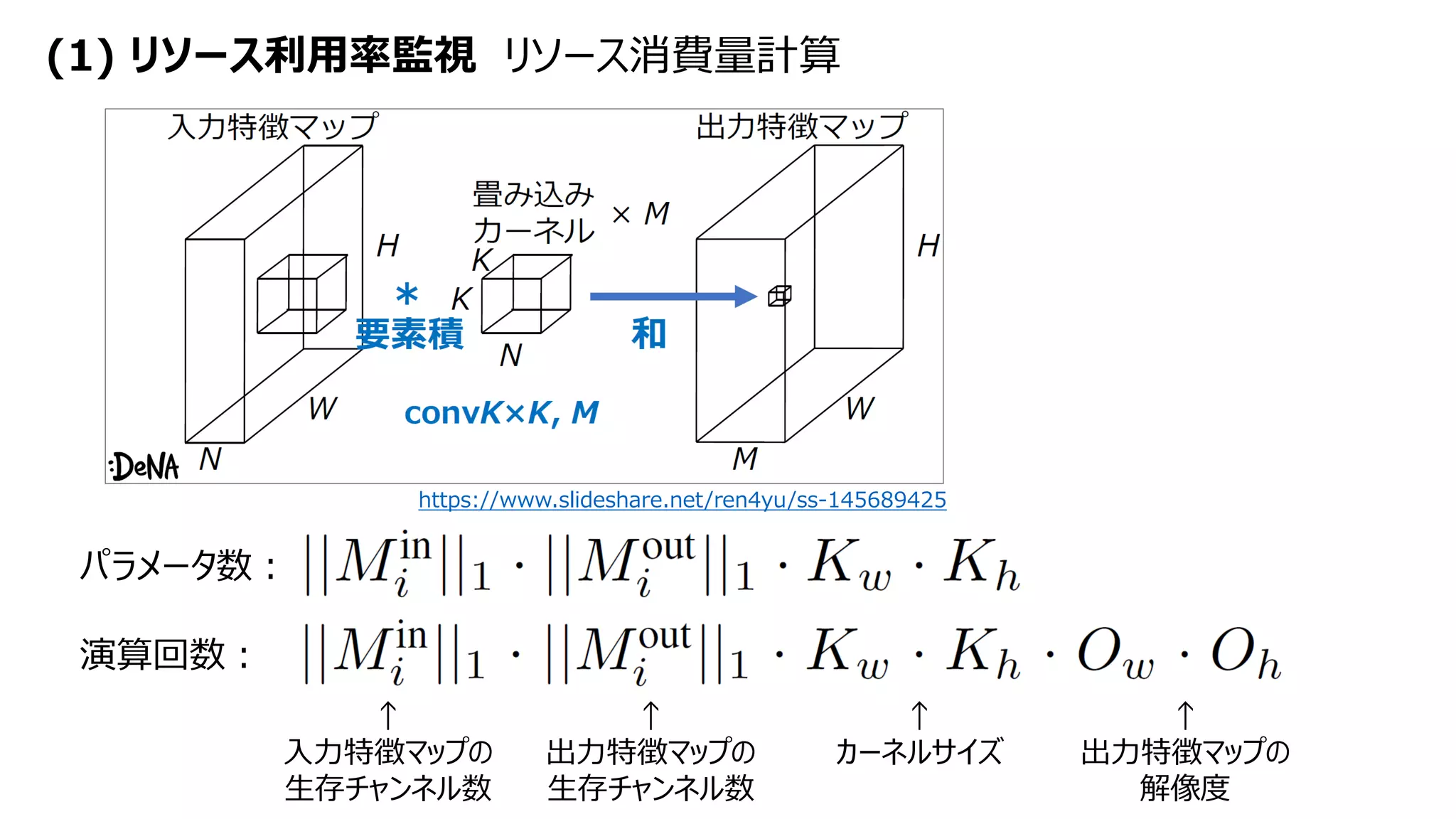
• フィルタのL1ノルム(フィルタ内の重みの絶対値の総和)σ ℱ𝑖,𝑗 が小さいフィルタをpruning
𝑛𝑖 : 入力特徴マップチャンネル数
𝑛𝑖+1 : 出力特徴マップチャンネル数(=フィルタ数)
フィルタ(kernel matrixの青いカーネル4枚)を
削れれば出力特徴マップも削れる
pruningの粒度(の一部)](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-5-2048.jpg)
![Network Slimming [Zhuang Liu+, ICCV2017]
・特定のリソースを狙って小さくできない
・小さくする方向だけ
- リソースが不足している部分を大きくできない
- 精度向上が主目的ではない
• Batch Normalization の scaling factor 𝛾 が小さいチャンネルをpruning
• L1正則化で 𝛾 がスパースになるよう仕向ける
𝛾
罰則項](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-6-2048.jpg)
![MorphNet FLOP/Size regularizer
誤ったら許さない
というお気持ち
[Ariel Gordon+, CVPR2018]
FLOPs(演算回数)増やすんじゃねぇぞ
というお気持ちを追加すると・・・
パラメータ数増やすんじゃねぇぞ
というお気持ちを追加すると・・・
• 何を小さくしたいかに応じて罰則項を変更](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-7-2048.jpg)
![MorphNet shrink-and-expand(収縮拡張法)
収縮
Network Slimming
拡張
width multiplier
図は [Ariel Gordon+, CVPR2018] を元に作成
・チャンネル数を決定したネットワークをスクラッチで学習し直す必要あり
- 学習の効率が悪い
- 拡張時にパラメータをどう引き継ぐべきか不明
• 収縮・拡張によりチャンネル数を自動決定](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-8-2048.jpg)
![DSD: Dense-Sparse-Dense Training
[Song Han+, ICLR2017]
・ガチャっぽくない
・ランダム性を活用したキャパシティ増加を行っていない
• 一度pruningした重みを 0 初期化で復活させる](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-9-2048.jpg)
![RandomOut
[Joseph Paul Cohen+, ICLRW2016]
• 重要でないフィルタをランダム初期化し直し、訓練継続
探索するフィルタを増やし、ネットワークサイズを大きくすることなく精度を向上させる](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-10-2048.jpg)
![MorphNet + RandomOut
収縮
Network Slimming
拡張
width multiplier
図は [Ariel Gordon+, CVPR2018] を元に作成
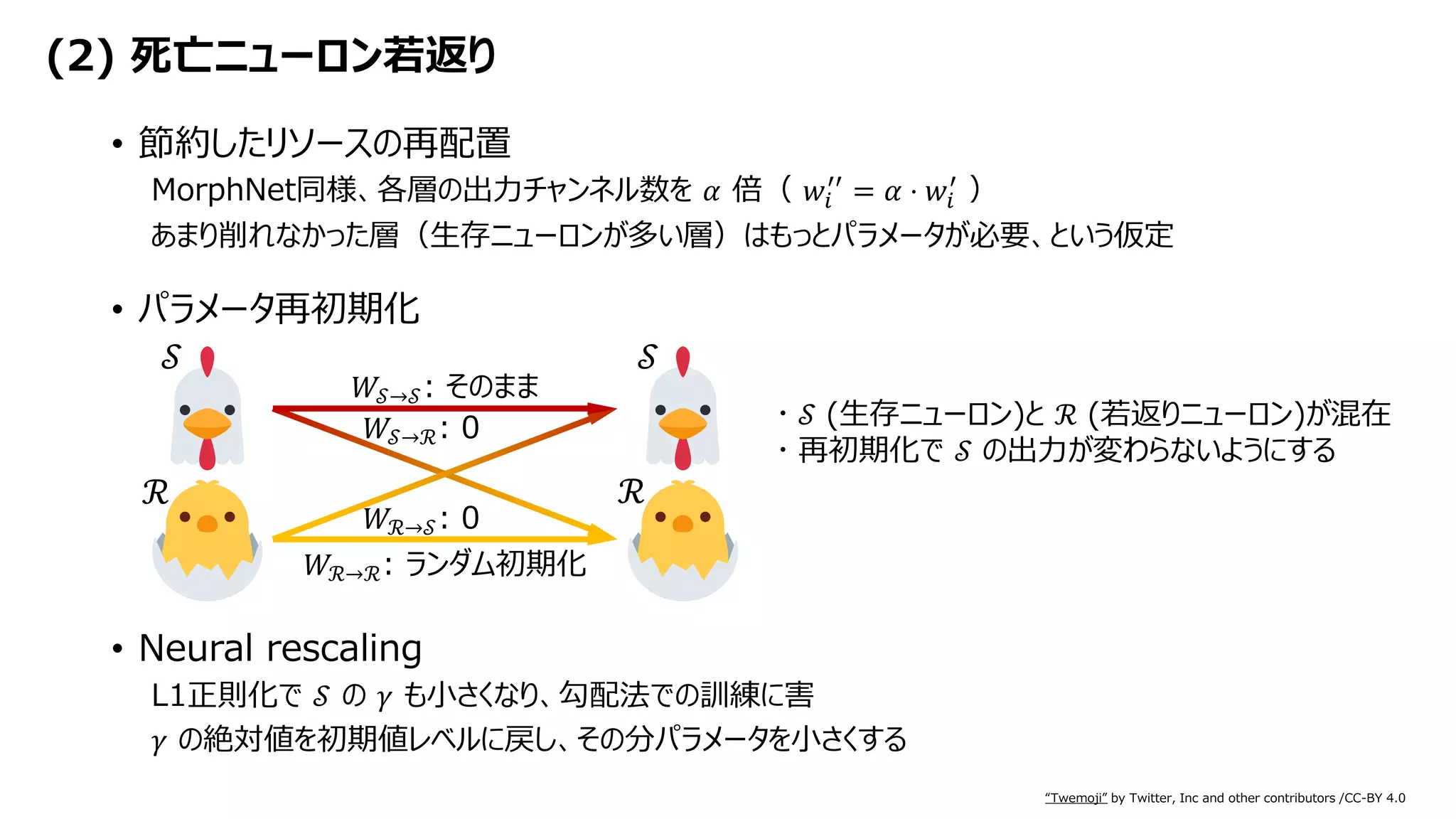
これが Neural Rejuvenation の肝
• MorphNetの拡張部分の重みにランダム初期化を使用し、訓練を継続](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-11-2048.jpg)









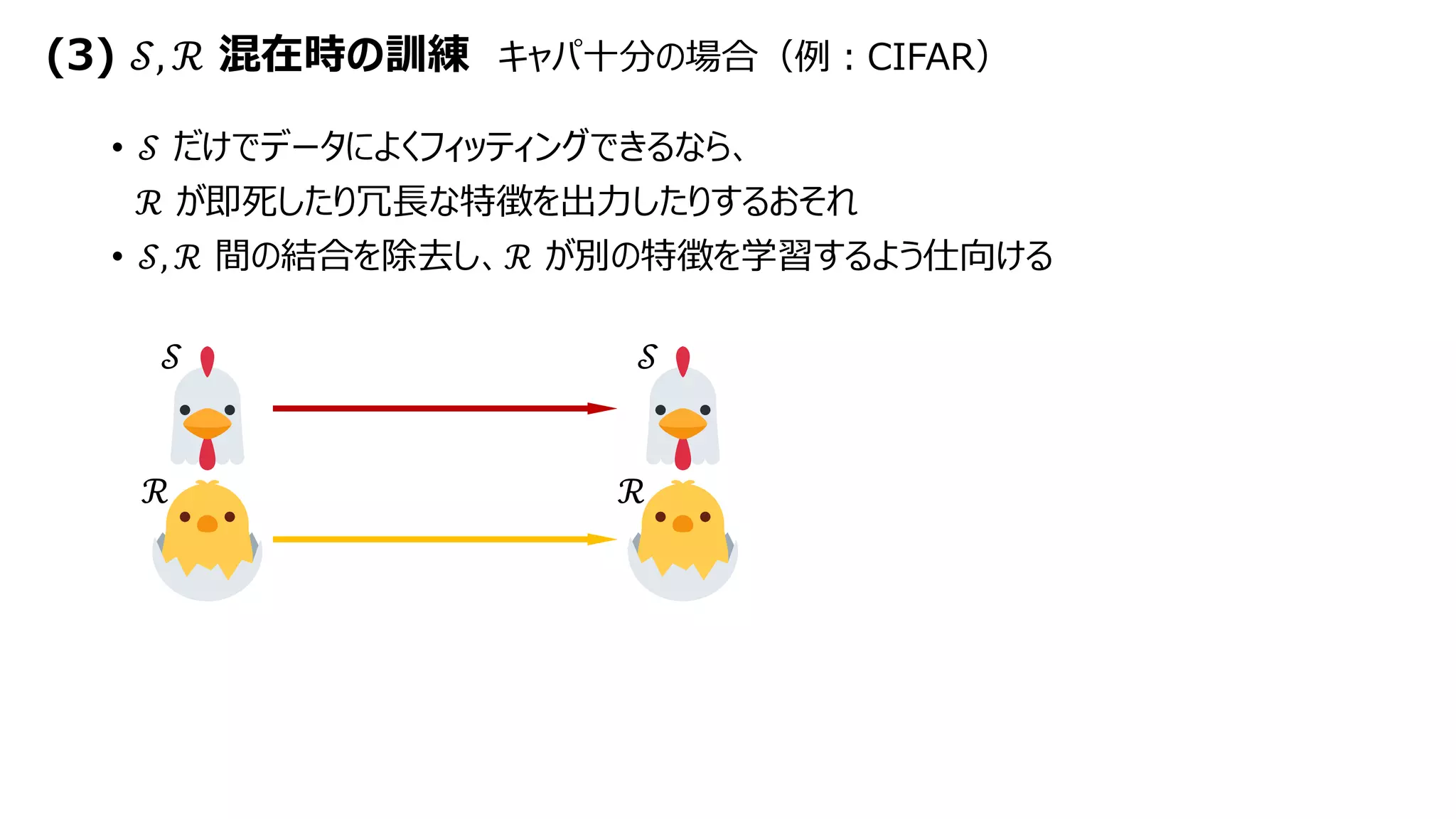
![(3) 𝒮, ℛ 混在時の訓練 キャパ不足の場合(例:ImageNet)
• SORTをベースとしたcross attentionでキャパシティ増加
パラメータ数は増えず、演算回数もあまり増えない
• attentionの先行研究との差異
・チャンネルの1グループで他のチャンネル用のアテンションを生成
・キャパシティ増加のために使用
SORT: Second-Order Response Transform
[Yan Wang+, ICCV2017]
二次の項を追加し非線形性・表現力を向上
⊙ : 要素積
𝜎 : シグモイド関数](https://image.slidesharecdn.com/neuralrejuvenation20190630-190630045157/75/Neural-Rejuvenation-Improving-Deep-Network-Training-by-Enhancing-Computational-Resource-Utilization-24-2048.jpg)

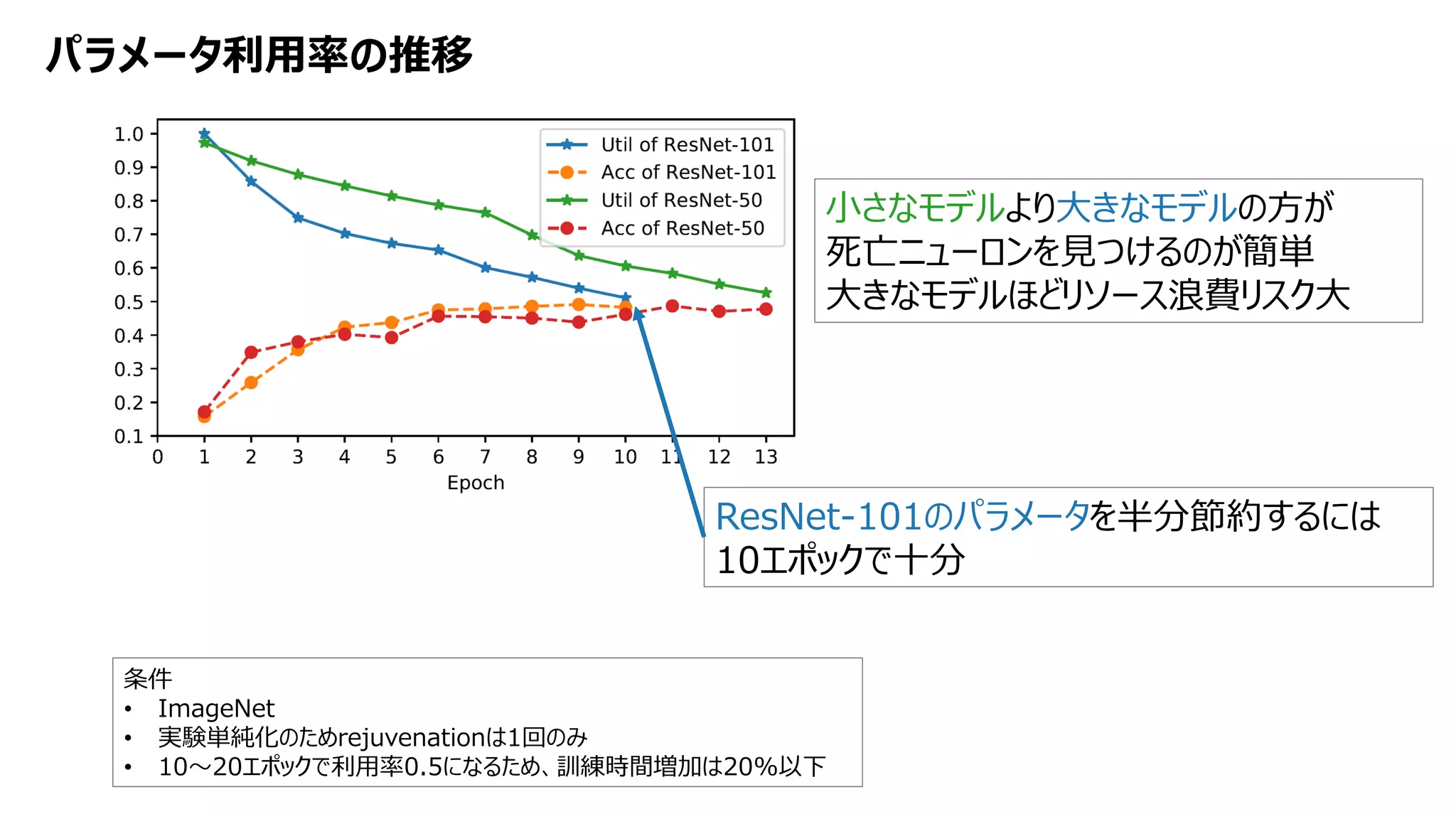
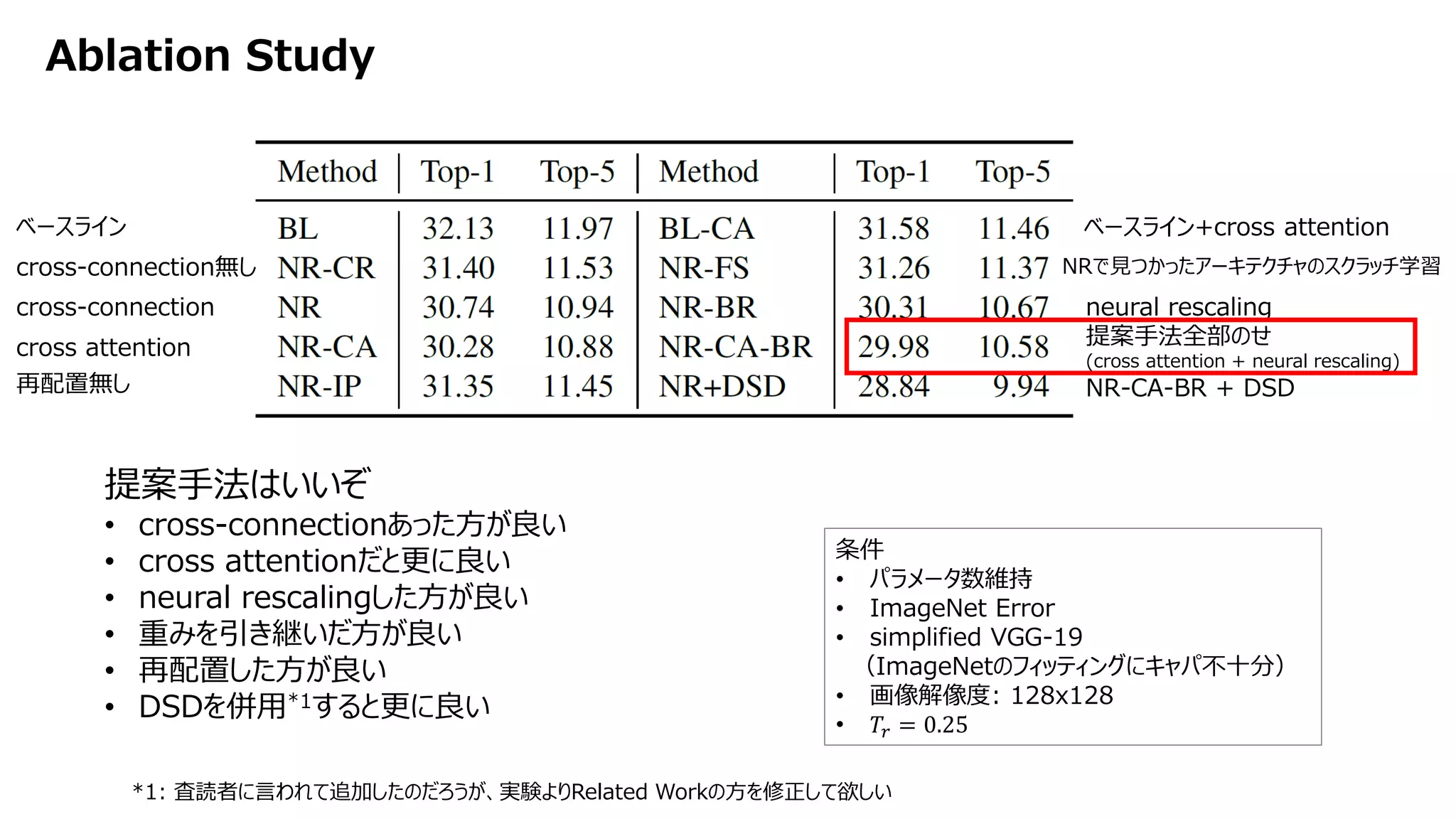
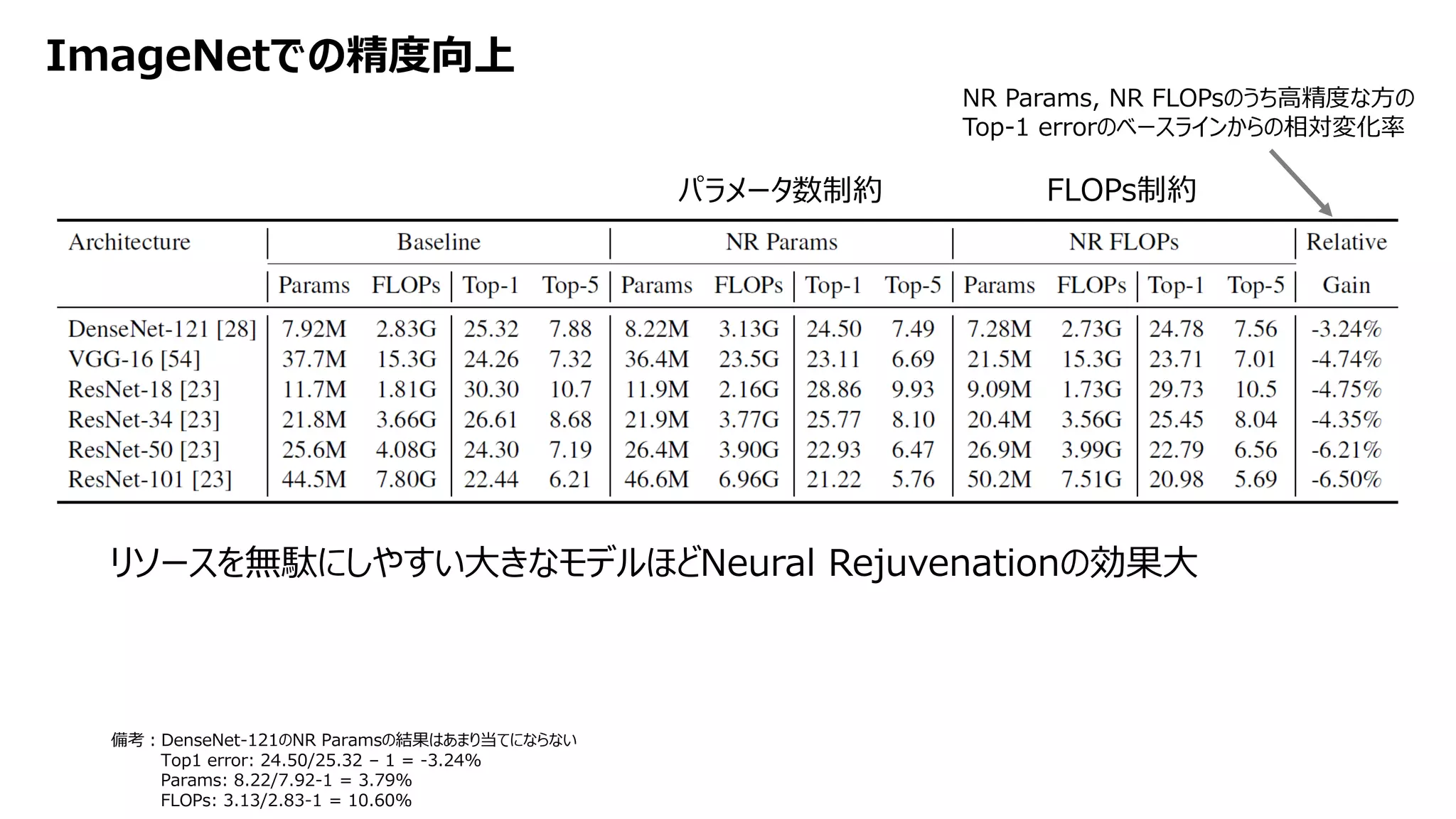
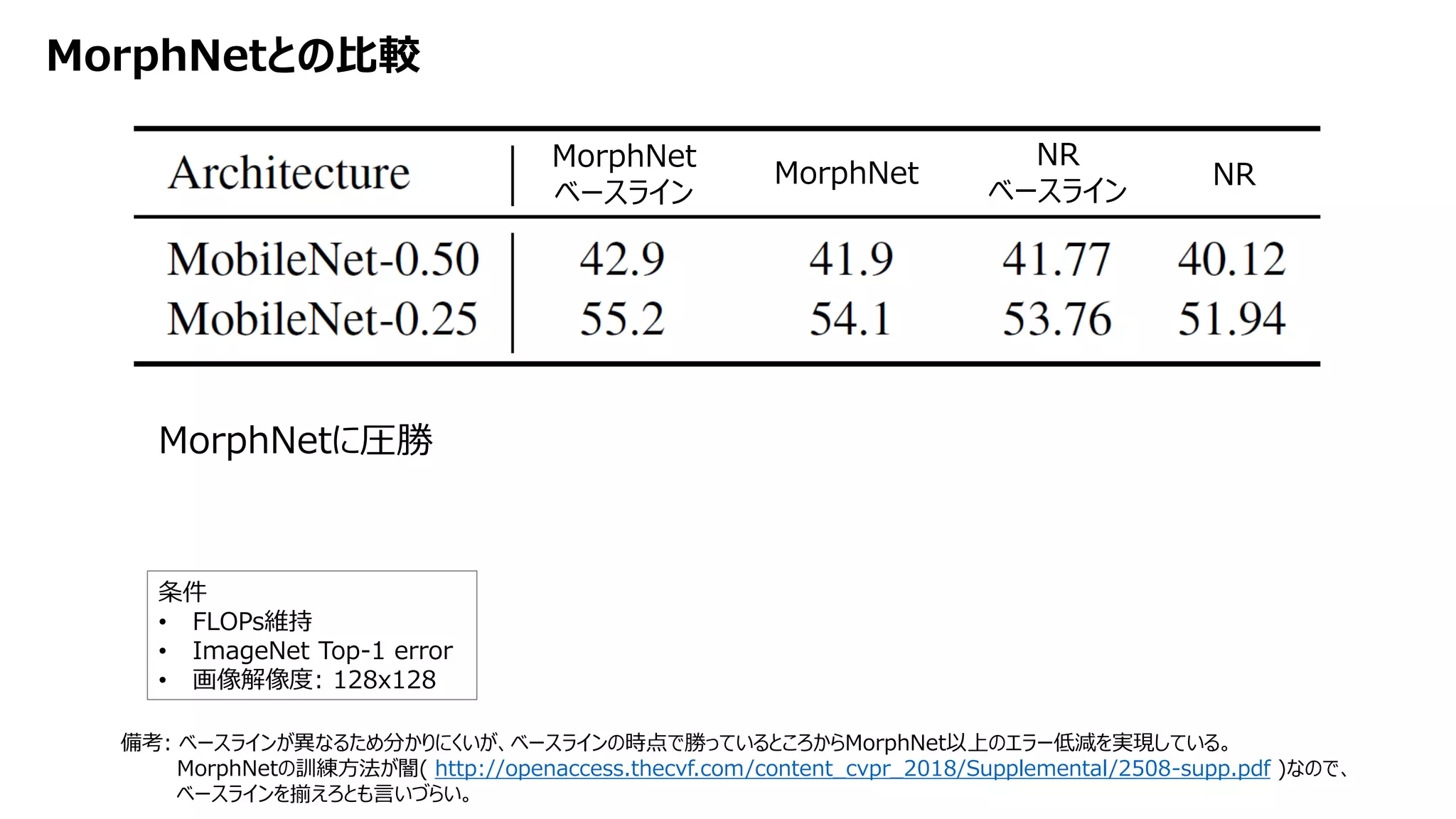


![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/2017-06-22-170623004409-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...](https://cdn.slidesharecdn.com/ss_thumbnails/20181005misono2-181009052706-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Understanding and Controlling Memory in Recurrent Neural Networks (ICM...](https://cdn.slidesharecdn.com/ss_thumbnails/190719nonaka-190808100959-thumbnail.jpg?width=640&height=640&fit=bounds)

























