Download as PDF, PPTX






![R solution
Matrix interface ( ):
label = audit$Adjusted
features = audit[, !(colnames(audit) %in% c("Adjusted"))]
# Returns a `model` object
audit.model = model(x = features, y = label)
Formula interface ( ):
# Returns a `model.formula` object
audit.model = model(Adjusted ~ . + I(Income / (Hours * 52)), data = audit)](https://image.slidesharecdn.com/convertingrtopmml-171116200739/75/Converting-R-to-PMML-7-2048.jpg)










![Bucketization (2/2)
<DerivedField name="cut(Income)" optype="categorical" dataType="string">
<Extension>cut(Income, breaks = 3)</Extension>
<Discretize field="Income">
<DiscretizeBin binValue="(129,1.61e+05]">
<Interval closure="openClosed" leftMargin="129.0" rightMargin="161000.0"/>
</DiscretizeBin>
<DiscretizeBin binValue="(1.61e+05,3.21e+05]">
<Interval closure="openClosed" leftMargin="161000.0" rightMargin="321000.0"/>
</DiscretizeBin>
<DiscretizeBin binValue="(3.21e+05,4.82e+05]">
<Interval closure="openClosed" leftMargin="321000.0" rightMargin="482000.0"/>
</DiscretizeBin>
</Discretize>
</DerivedField>](https://image.slidesharecdn.com/convertingrtopmml-171116200739/75/Converting-R-to-PMML-19-2048.jpg)











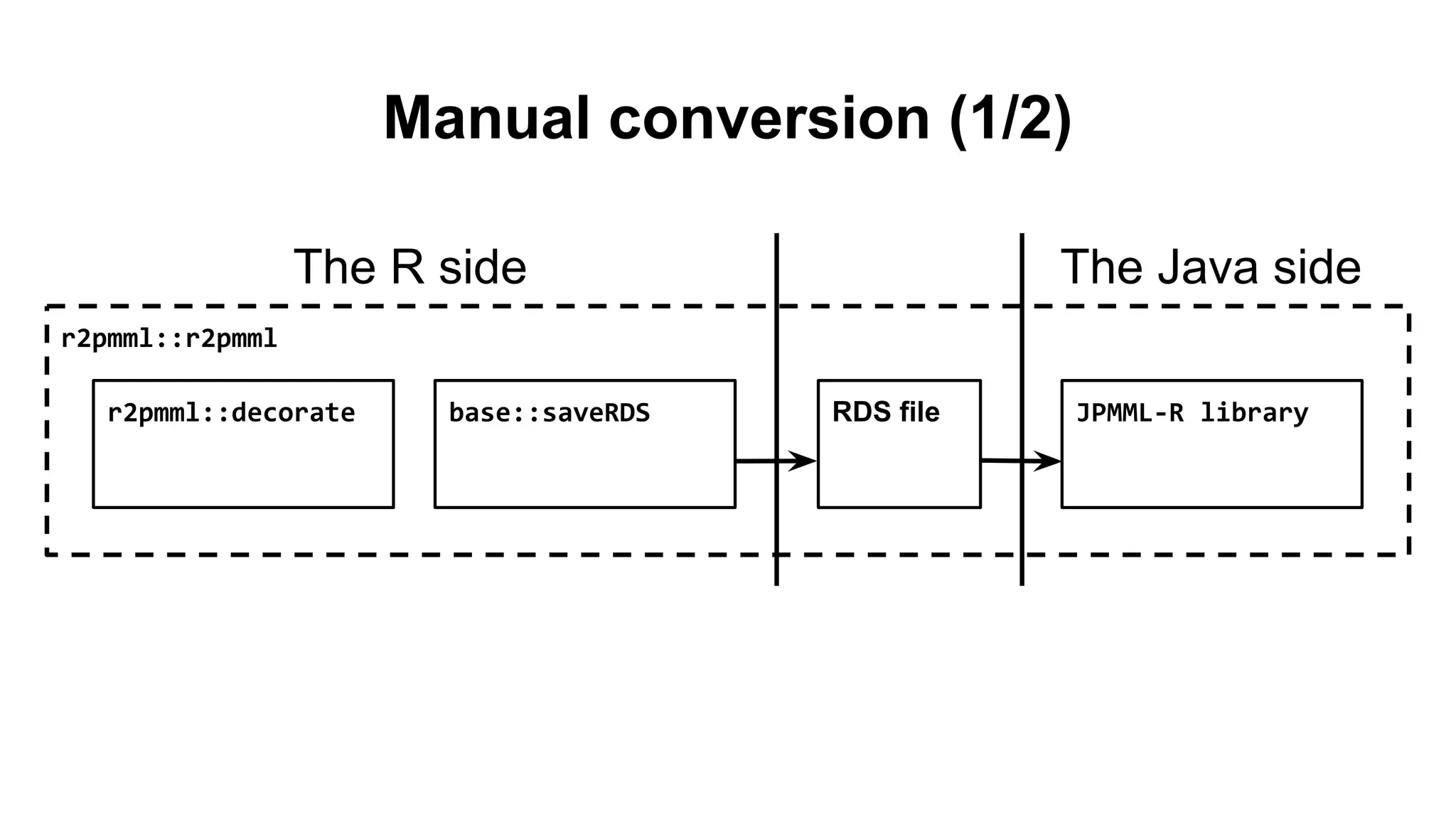
The document discusses challenges in converting R models to PMML format and solutions using the r2pmml package. Specifically, it addresses issues like tightly coupled R scripts and model objects, lack of standardization, and inability to deploy models outside of R. The r2pmml package allows decorating model objects with supporting information and converting them to PMML, addressing these issues. This standardized format represents the R workflow and data using PMML structures, enabling "train once, deploy anywhere". The document provides examples of converting various R models like GLM and transforming features to PMML.














![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)








![[C++ Korea 2nd Seminar] Ranges for The Cpp Standard Library](https://cdn.slidesharecdn.com/ss_thumbnails/rangesforthecppstdlib-180427163625-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



