2022년 11월 30일 코엑스에서 개최한 베스트콘2022(Better Software Testing Conference 2022)에서 발표한 강연 자료입니다.
대규모 장애를 막기 위해 소프트웨어/품질 엔지니어가 알아야 할 내결함성의 개념과 설계 기법을 공유드립니다.
생생한 강연 영상으로 확인해 보세요!
https://youtu.be/OLsv7oG0VPo
5
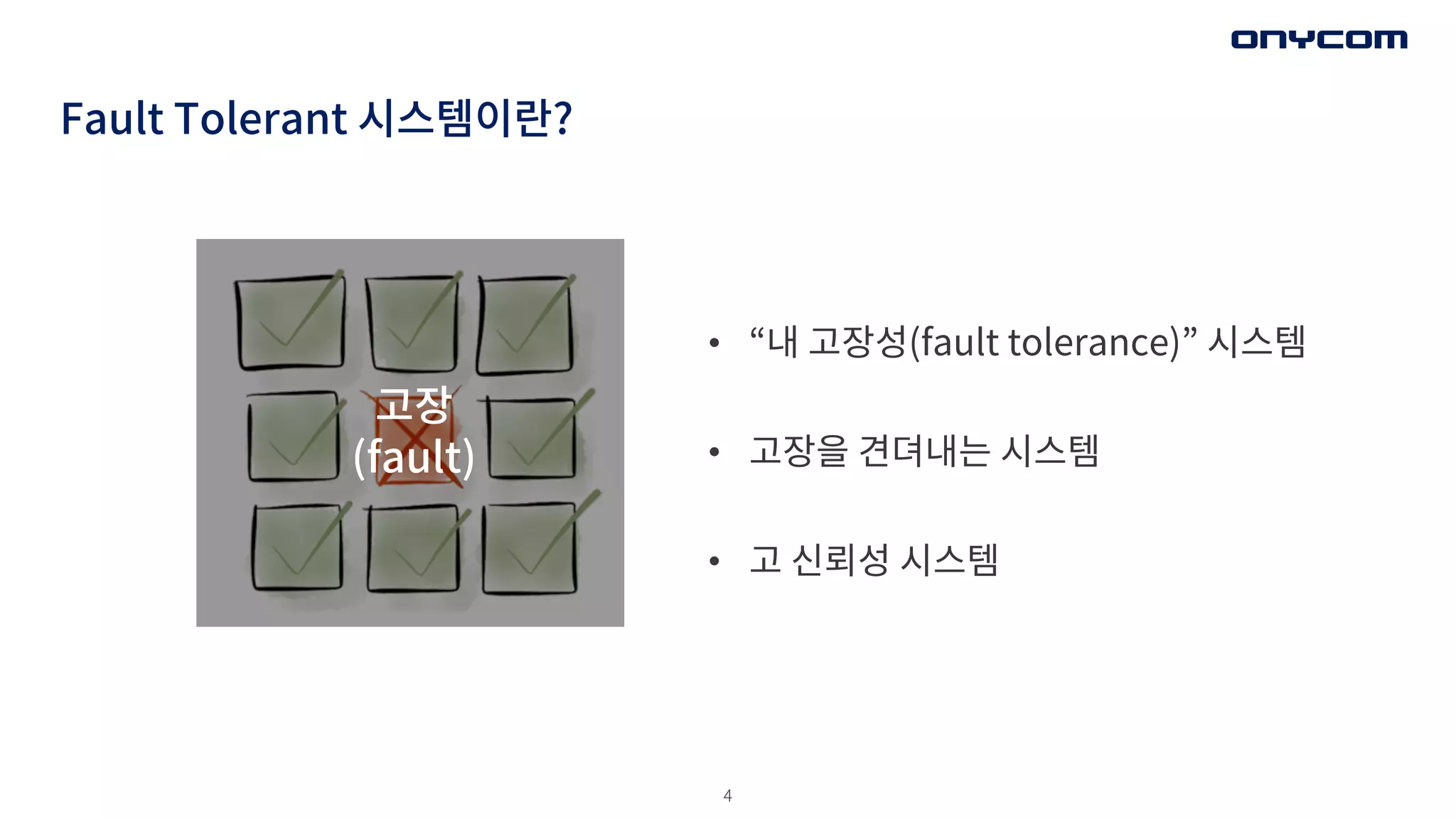
• 다운이 허용될수 없는 시스템 (은행이나 e-Commerce)
• 실시간 프로세스 제어시스템 (좌석 예약시스템 )
• 고장이 인명 손실에 영향을 주는 시스템(자동차, 병원)
• 년 중 보수작업이 불가능한 시스템(우주 항해 시스템)
• 고장이 막대한 경제적 손실을 야기하는 시스템 (원전 시스템)
Fault Tolerant 시스템이란?
7
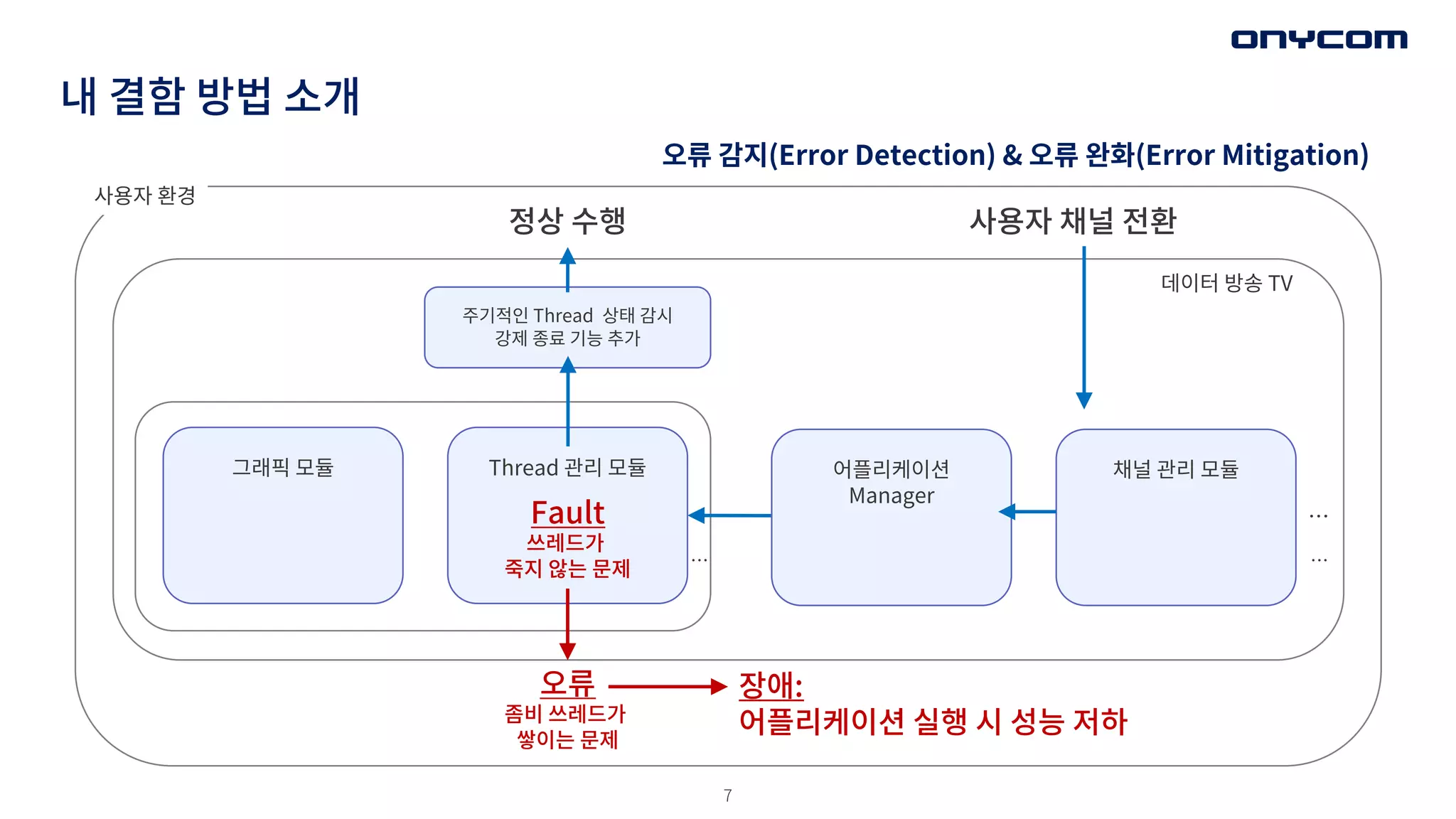
내 결함 방법소개
주기적인 Thread 상태 감시
강제 종료 기능 추가
Fault
쓰레드가
죽지 않는 문제
Thread 관리 모듈
그래픽 모듈 채널 관리 모듈
오류
좀비 쓰레드가
쌓이는 문제
장애:
어플리케이션 실행 시 성능 저하
정상 수행
사용자 환경
사용자 채널 전환
데이터 방송 TV
어플리케이션
Manager
오류 감지(Error Detection) & 오류 완화(Error Mitigation)
…
…
…
8.
8
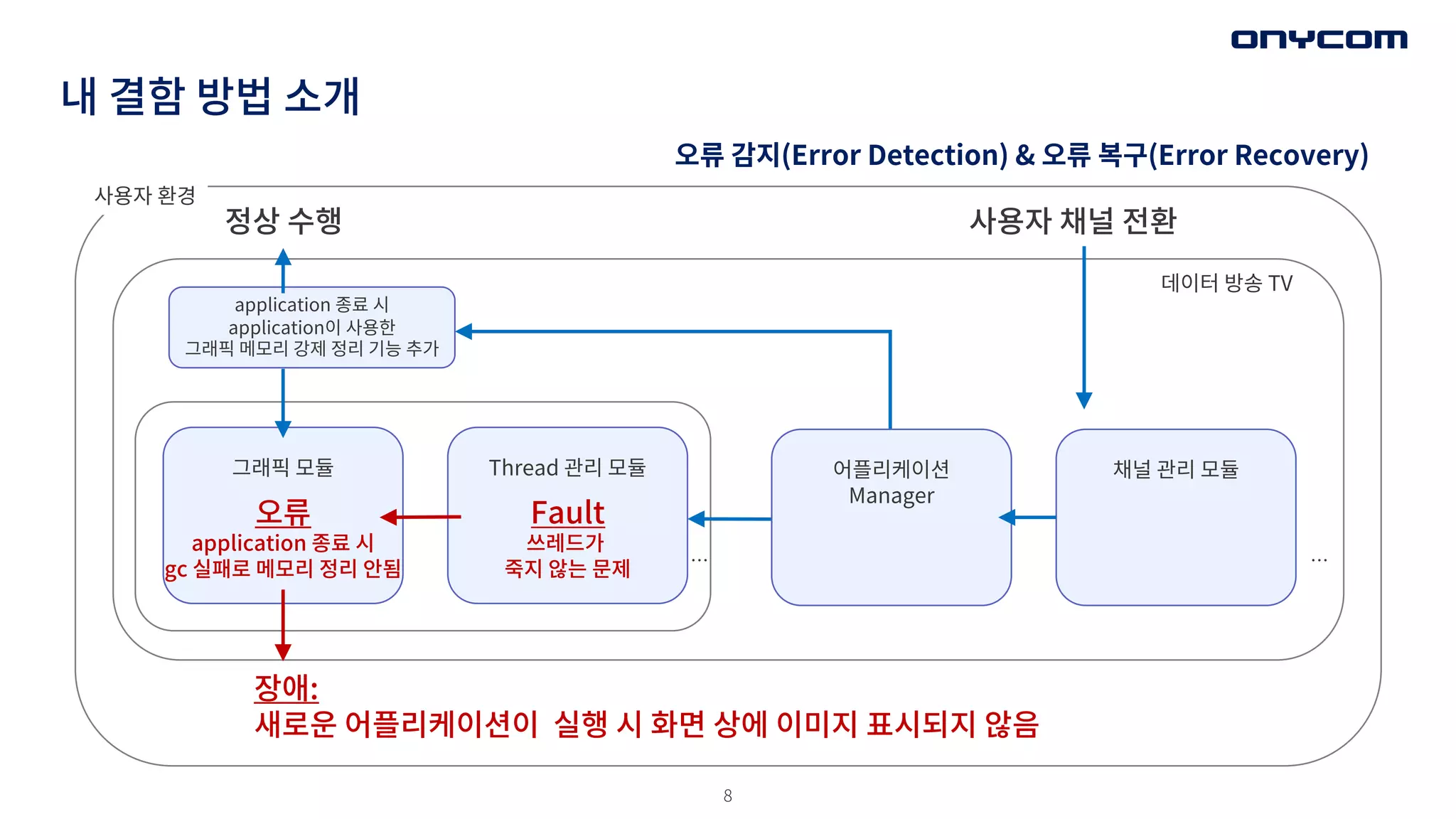
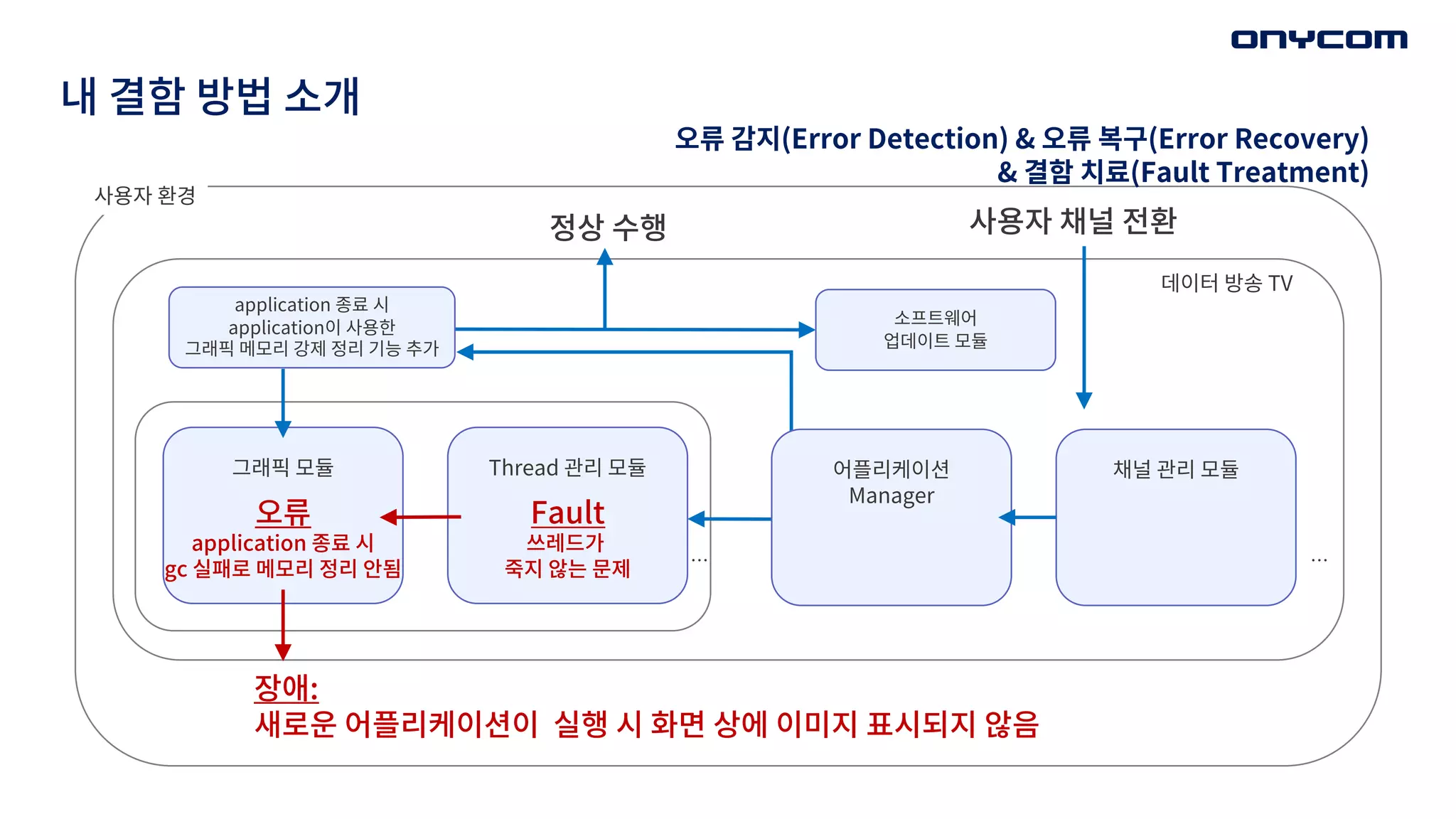
내 결함 방법소개
application 종료 시
application이 사용한
그래픽 메모리 강제 정리 기능 추가
Fault
쓰레드가
죽지 않는 문제
Thread 관리 모듈
그래픽 모듈 채널 관리 모듈
장애:
새로운 어플리케이션이 실행 시 화면 상에 이미지 표시되지 않음
정상 수행
사용자 환경
사용자 채널 전환
데이터 방송 TV
어플리케이션
Manager
오류
application 종료 시
gc 실패로 메모리 정리 안됨 …
…
오류 감지(Error Detection) & 오류 복구(Error Recovery)
9.
9
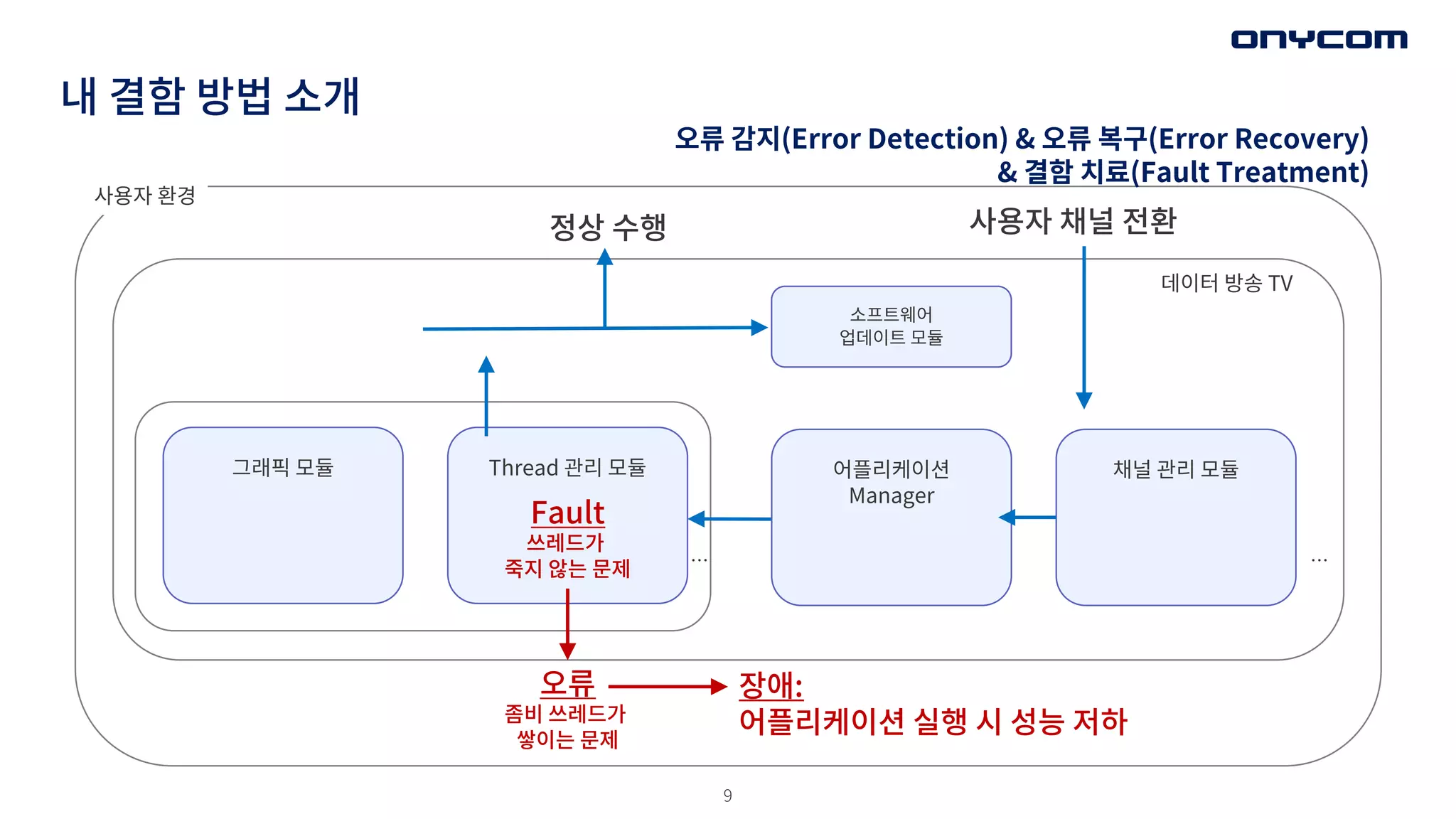
내 결함 방법소개
Fault
쓰레드가
죽지 않는 문제
Thread 관리 모듈
그래픽 모듈 채널 관리 모듈
정상 수행
사용자 환경
사용자 채널 전환
데이터 방송 TV
어플리케이션
Manager
…
…
오류
좀비 쓰레드가
쌓이는 문제
장애:
어플리케이션 실행 시 성능 저하
소프트웨어
업데이트 모듈
오류 감지(Error Detection) & 오류 복구(Error Recovery)
& 결함 치료(Fault Treatment)
10.
내 결함 방법소개
application 종료 시
application이 사용한
그래픽 메모리 강제 정리 기능 추가
Fault
쓰레드가
죽지 않는 문제
Thread 관리 모듈
그래픽 모듈 채널 관리 모듈
장애:
새로운 어플리케이션이 실행 시 화면 상에 이미지 표시되지 않음
사용자 환경
사용자 채널 전환
데이터 방송 TV
어플리케이션
Manager
오류
application 종료 시
gc 실패로 메모리 정리 안됨 …
…
정상 수행
소프트웨어
업데이트 모듈
오류 감지(Error Detection) & 오류 복구(Error Recovery)
& 결함 치료(Fault Treatment)
12
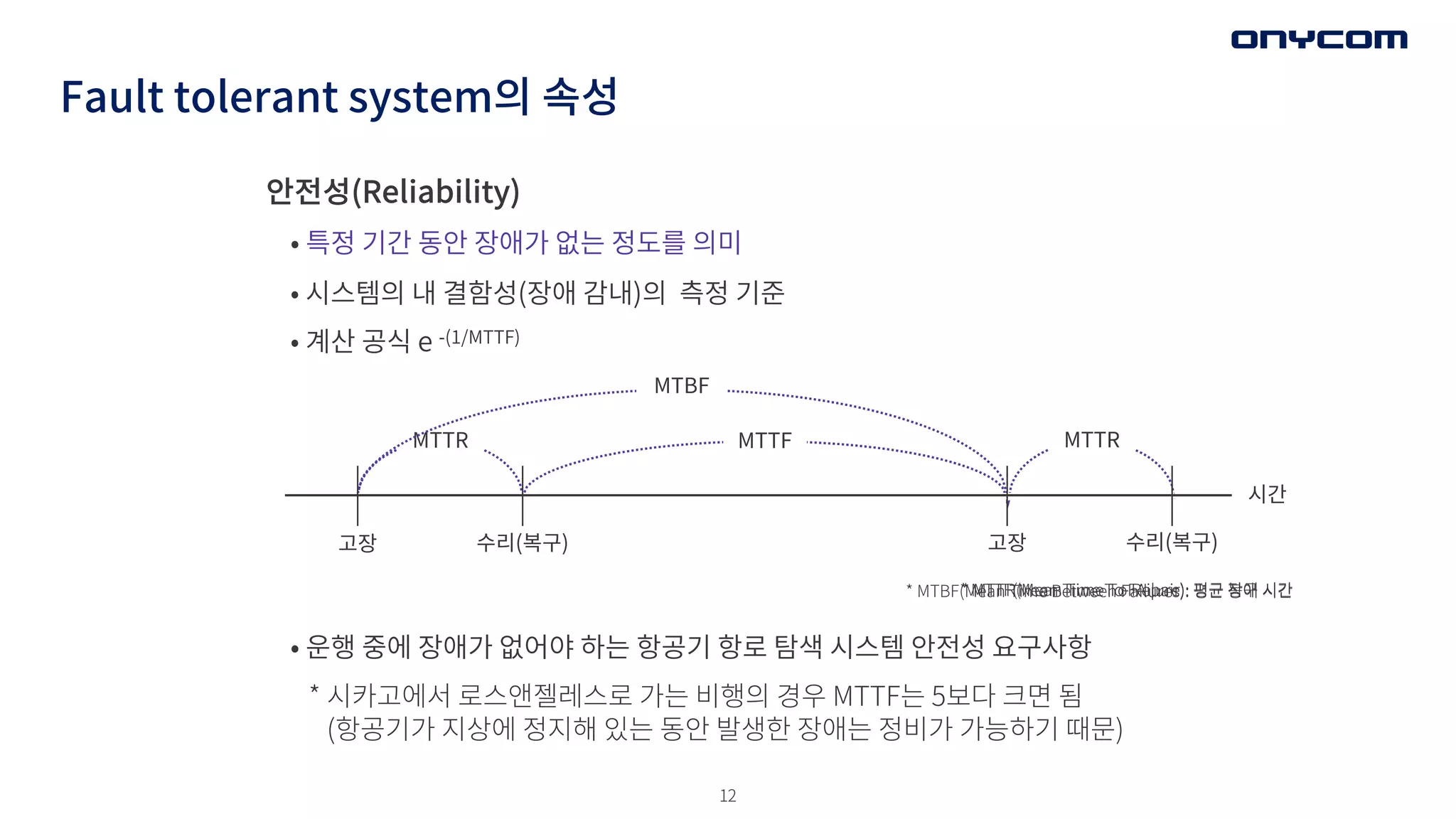
Fault tolerant system의속성
안전성(Reliability)
• 특정 기간 동안 장애가 없는 정도를 의미
• 시스템의 내 결함성(장애 감내)의 측정 기준
• 계산 공식 e -(1/MTTF)
• 운행 중에 장애가 없어야 하는 항공기 항로 탐색 시스템 안전성 요구사항
* 시카고에서 로스앤젤레스로 가는 비행의 경우 MTTF는 5보다 크면 됨
(항공기가 지상에 정지해 있는 동안 발생한 장애는 정비가 가능하기 때문)
MTTF
MTTR MTTR
* MTTR(Mean Time To Repair): 평균 복구 시간
* MTTF(Mean Time To FAilure): 평균 장애 시간
MTBF
* MTBF(Mean Time Between Failures): 평균 장애 시간
고장 수리(복구) 고장 수리(복구)
시간
13.
13
Fault tolerant system의속성
가용성(Availability)
• 시스템이 특정 기간 동안에 장애 없이 동작할 수 있는 확률
• 시스템의 내 결함성(장애 감내)의 측정 기준
• 계산 공식 = MTTF / MTTF+MTTR
• Alcatel-Lucent 사의 4ESS™ 스위치의 가용성 요구사항
* 40년간 고장시간은 2시간만 허용한다 즉 가용할 수 없는 시간이 연간 3분이라는 의미
MTTF
MTTR MTTR
* MTTR(Mean Time To Repair): 평균 복구 시간
* MTTF(Mean Time To FAilure): 평균 장애 시간
MTBF
* MTBF(Mean Time Between Failures): 평균 장애 시간
고장 수리(복구) 고장 수리(복구)
시간
14.
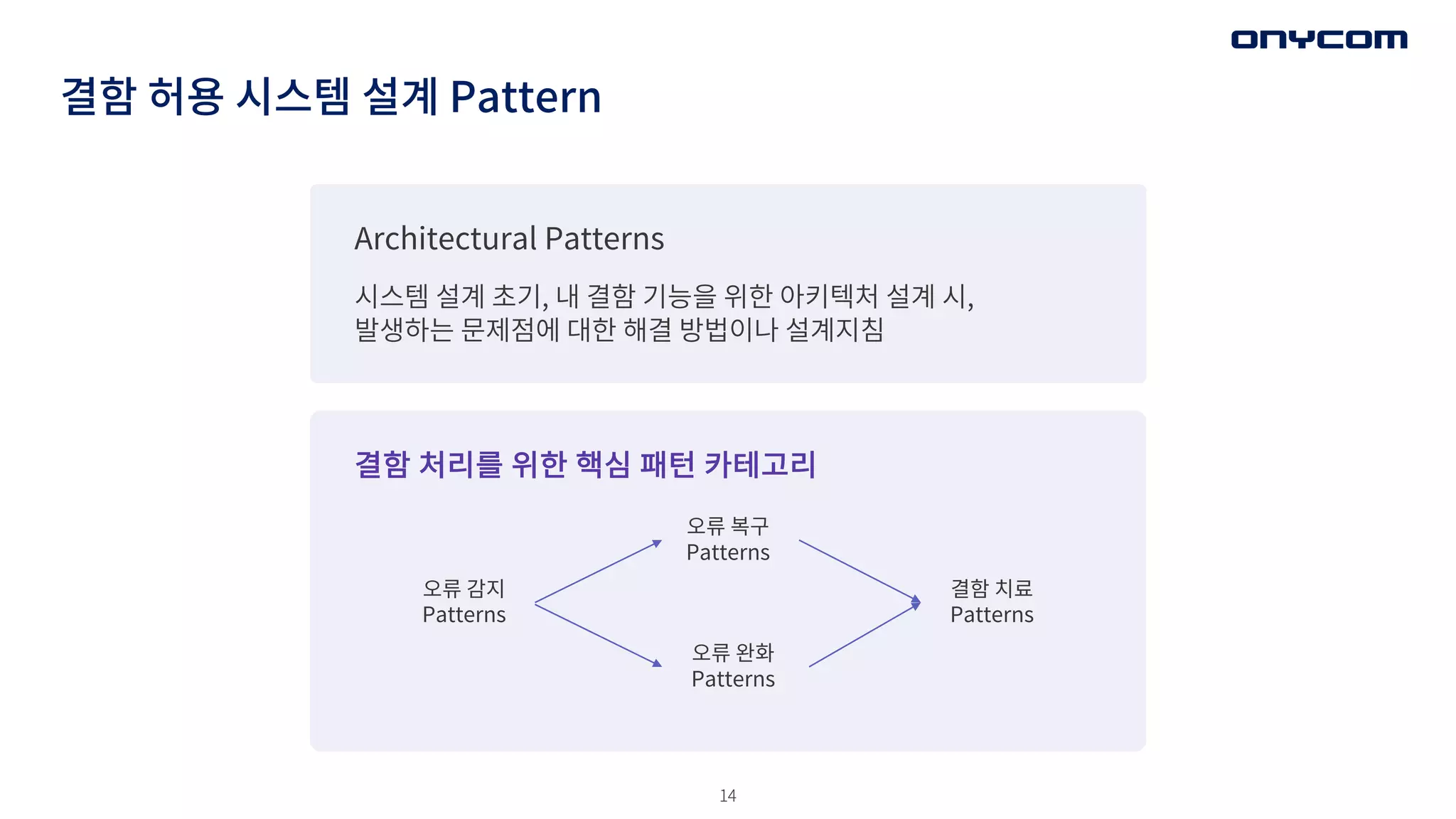
결함 허용 시스템설계 Pattern
Architectural Patterns
시스템 설계 초기, 내 결함 기능을 위한 아키텍처 설계 시,
발생하는 문제점에 대한 해결 방법이나 설계지침
결함 처리를 위한 핵심 패턴 카테고리
오류 감지
Patterns
오류 복구
Patterns
오류 완화
Patterns
결함 치료
Patterns
14
16
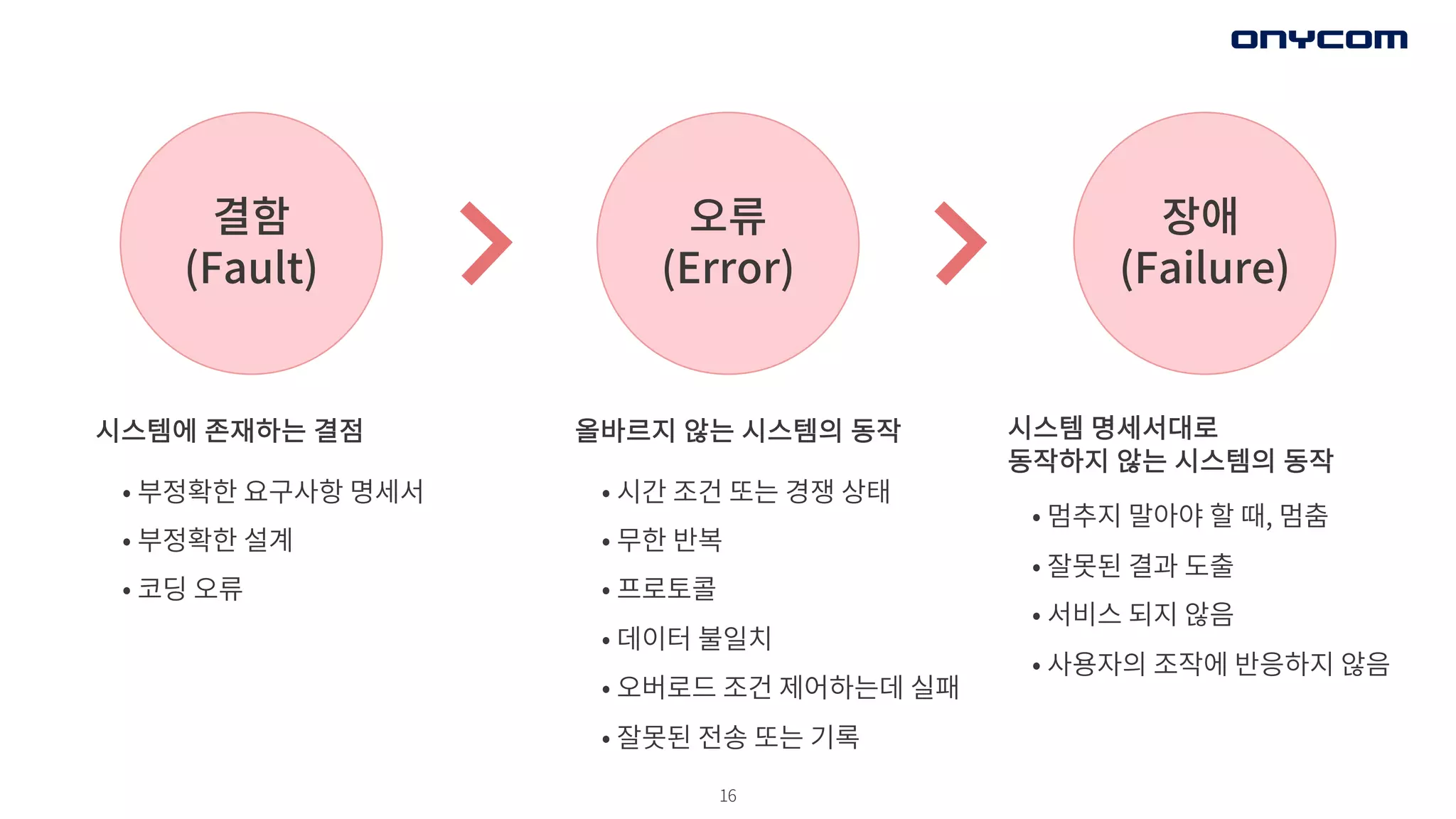
장애
(Failure)
오류
(Error)
결함
(Fault)
시스템 명세서대로
동작하지 않는시스템의 동작
• 멈추지 말아야 할 때, 멈춤
• 잘못된 결과 도출
• 서비스 되지 않음
• 사용자의 조작에 반응하지 않음
올바르지 않는 시스템의 동작
• 시간 조건 또는 경쟁 상태
• 무한 반복
• 프로토콜
• 데이터 불일치
• 오버로드 조건 제어하는데 실패
• 잘못된 전송 또는 기록
시스템에 존재하는 결점
• 부정확한 요구사항 명세서
• 부정확한 설계
• 코딩 오류
18
용 어
주요 속성
•안정성(reliability): 특정 기간동안 장애가 나지 않는 능력
• 가용성(availability): 언제라도 무정지로 시스템이 돌아가는 능력
• 안정(safety): 시스템이 죽지 않고 유지될 수 있느냐,
큰 재앙 없이 비상식적은 경로로 접근해도 죽지 않을 수 있는 능력
• 보안(security): 해킹이 들어와도 보안될 수 있는 능력
시스템의 신뢰성(Dependability)
소프트웨어의 요구사항 명세에 따라, 시스템이 정확히 돌아가는 능력
(의도한 기능을 수행하는데 필요한 시스템의 신용도)
19.
19
용 어
시스템의 신뢰성향상을 위한 방법
• 결함 회피(Fault Avoidance)
시스템 고장발생 확률을 줄이는 방법. 코드 설계 시 실수나 피해의 가능성을
최소화할 수 있도록 하는 방법. 설계 재검토, 소자 조사, 시험 등의 방식임
• 결함 은폐(Fault Masking)
fault가 드러나는 것을 숨기는 방법 여러 대의 동일한 기능을 하는
시스템을 두고 다수결로 서로 다른 결과를 낸 시스템에 대해서 차폐 시킴
• 결함 허용(Fault Tolerance)
결함이 일어난 후에 시스템의 임무를 중단하지 않고 연속적으로
수행하도록 하는 방법
20.
20
용 어
Fault tolerancesystem
소프트웨어, 하드웨어 구조와 시스템의 일부가 올바르게 동작하지 않더라도
그 기능을 지속할 수 있도록 설계된 시스템
시스템 명세서
시스템 동작에 대한 요구사항을 정의
Failure(장애)
시스템 명세서대로 동작하지 않는 시스템의 동작
21.
21
용 어
Error(오류)
• 일으킬수 있는 올바르지 않은 시스템의 동작. 장애의 원인
- 시간적인 오류
- 값의 오류
Fault(결함)
• 시스템에 존재하는 결점. 모든 시스템에 존재함
• 잠재된 결함 : 숨어 문제를 일으키지 않음
• 활성화된 결함 : 잠재되어 있는 결함이 발생할 조건이 되어
잘못된 기능을 수행한 경우로, 오류로 나타남
22.
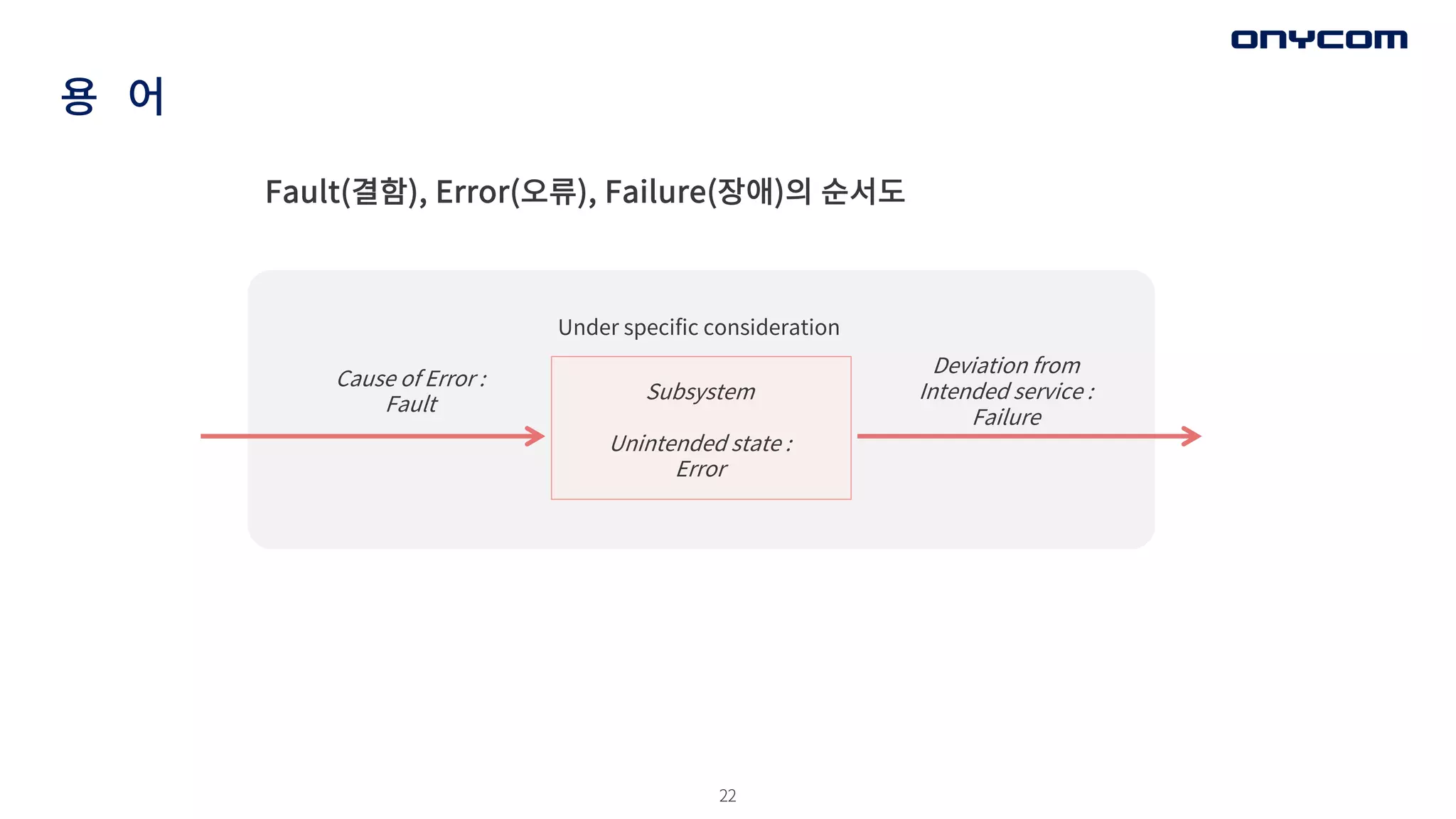
22
용 어
Fault(결함), Error(오류),Failure(장애)의 순서도
Cause of Error :
Fault
Subsystem
Unintended state :
Error
Deviation from
Intended service :
Failure
Under specific consideration
24
Error(오류)의 예
오류의 타입내 용
시간 조건 또는
경쟁 상태
서로 통신하는 프로세스들이 동기화를 하지 못하여 자원을 서로 요청하는 일이 발생
무한 반복 정지 조건도 없고 공유한 자원에 대해 요청한 응답이 없어 반복문(loop)이 계속 수행
프로토콜
• 사용하고 있는 프로토콜의 규약을 따르지 않아 메시지를 전송하는 스트림에 오류가 있는 경우
• 잘못된 메시지가 전송되거나, 메시지가 적절하지 못한 때에 전송되거나, 순서가 맞지 않을 수 있음
데이터 불일치 두 위치(예를 들어, 메모리와 디스크, 또는 네트워크 상의 서로 다른 장치)에 있는 데이터가 서로 일치하지 않음
오버로드 조건을
제어하는데 실패
시스템이 작업량을 제어할 수 없는 경우
잘못된 전송
또는 기록
시스템의 결함으로 메모리의 잘못된 위치에 데이터를 쓰거나, 전송하는 경우
25.
25
소프트웨어 결함 발생의원인
원인의 타입 내 용
부정확한
요구사항 명세서
소프트웨어 설계자와 개발자가 잘못된 요구사항을 전달받는 경우
부정확한 설계
• 순수하게 소프트웨어 입장에서만 작업한 경우
• 요구사항을 설계로 옮기는 과정이 정확하지 않은 경우
코딩 오류
설계를 코드로 옮기는 과정에서 결함이 발생
- 문법적 결함
- 문법적으로 올바른 코드지만, 의도한 기능을 수행 하지 못하는 경우
26.
26
결함-> 오류 ->장애의 예
요구사항 우주선의 안테나는 지구 방향을 가리켜야 한다
결 함 업데이트 설계 담당자가 업데이트 할 메모리 범위를 잘못 계산함
오 류
지구 기지의 새로운 프로그램은
우주선 프로그램의 잘못된 메모리 범위를 업데이트 시키고,
이는 우주선의 다른 프로그램 또한 손상시켜 우주선의 명령어를 손상시킴
장 애
우주선의 안테나가 지구 방향이 아닌 다른 곳을 가리켜
지구 기지와 우주선과의 통신이 두절되어 임무를 수행하지 못함
지구 기지에서 프로그램을 업데이트 받는 우주선
27.
27
결함(Fault) -> 오류(Error) -> 장애 (Failure)의 예
요구사항 비행기는 계획한 비행 경로에서 벗어나선 안 된다
결 함
Ariane 4와 Ariane 5의
서로 다른 비행 경로 선택 기준 요구사항들
오 류 수평 속도를 급격하게 증가시킴
장 애
관성 기준 시스템에 장애를 일으켜
비행 경로에서 벗어나게 되고, 자폭 회로를 가동시킴
예시: 유럽 우주국에서 개발한 Ariane 5 로켓
(다수 결함에 의한 장애)
• 다수 결함의 장애
Fault_1
Fault_5
Fault_2
Fault_3
Fault_4
Fault_6
Error_1
Error_2
Error_2
28.
28
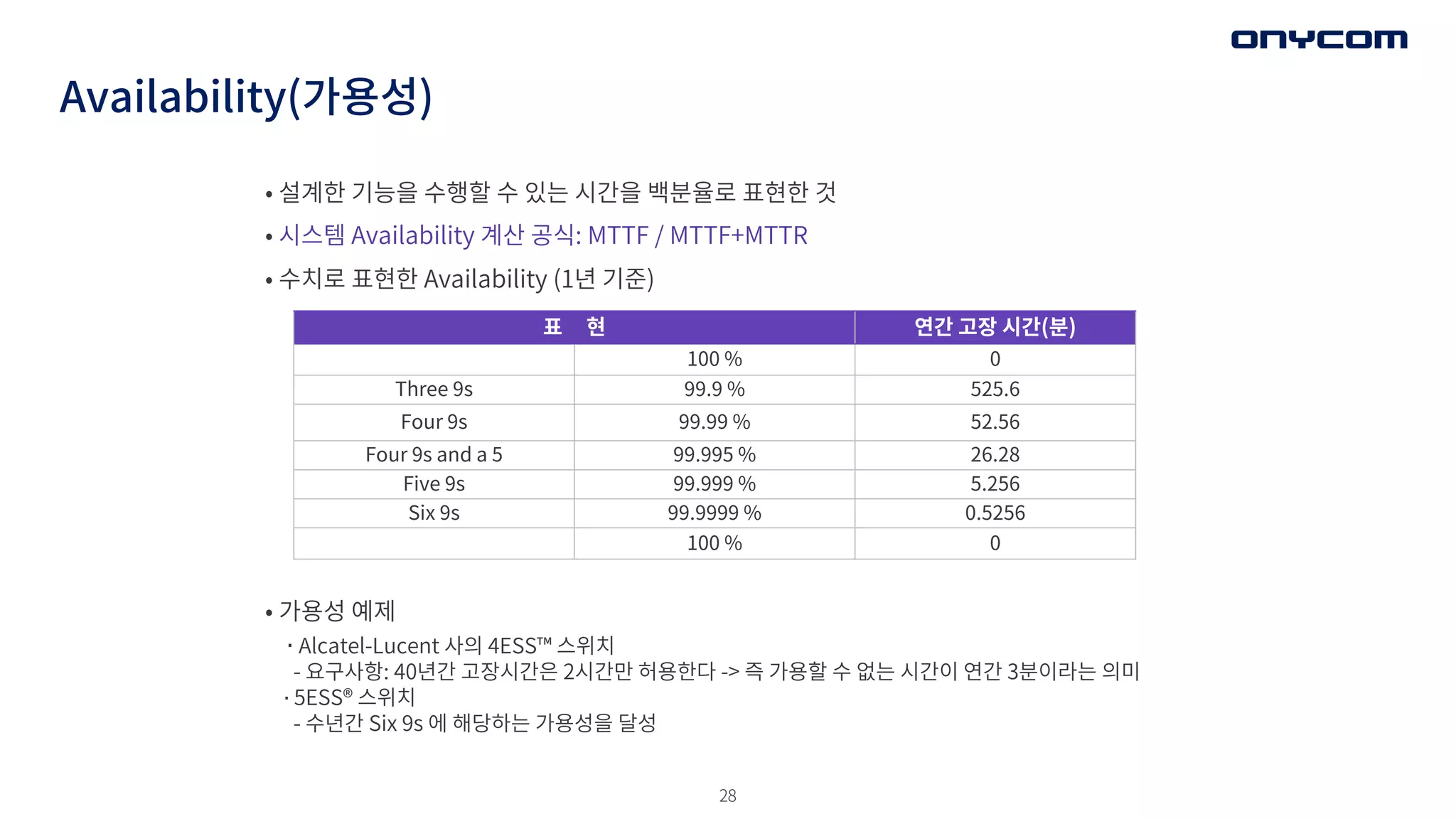
Availability(가용성)
• 설계한 기능을수행할 수 있는 시간을 백분율로 표현한 것
• 시스템 Availability 계산 공식: MTTF / MTTF+MTTR
• 수치로 표현한 Availability (1년 기준)
표 현 연간 고장 시간(분)
100 % 0
Three 9s 99.9 % 525.6
Four 9s 99.99 % 52.56
Four 9s and a 5 99.995 % 26.28
Five 9s 99.999 % 5.256
Six 9s 99.9999 % 0.5256
100 % 0
• 가용성 예제
∙ Alcatel-Lucent 사의 4ESS™ 스위치
- 요구사항: 40년간 고장시간은 2시간만 허용한다 -> 즉 가용할 수 없는 시간이 연간 3분이라는 의미
∙ 5ESS® 스위치
- 수년간 Six 9s 에 해당하는 가용성을 달성
29.
29
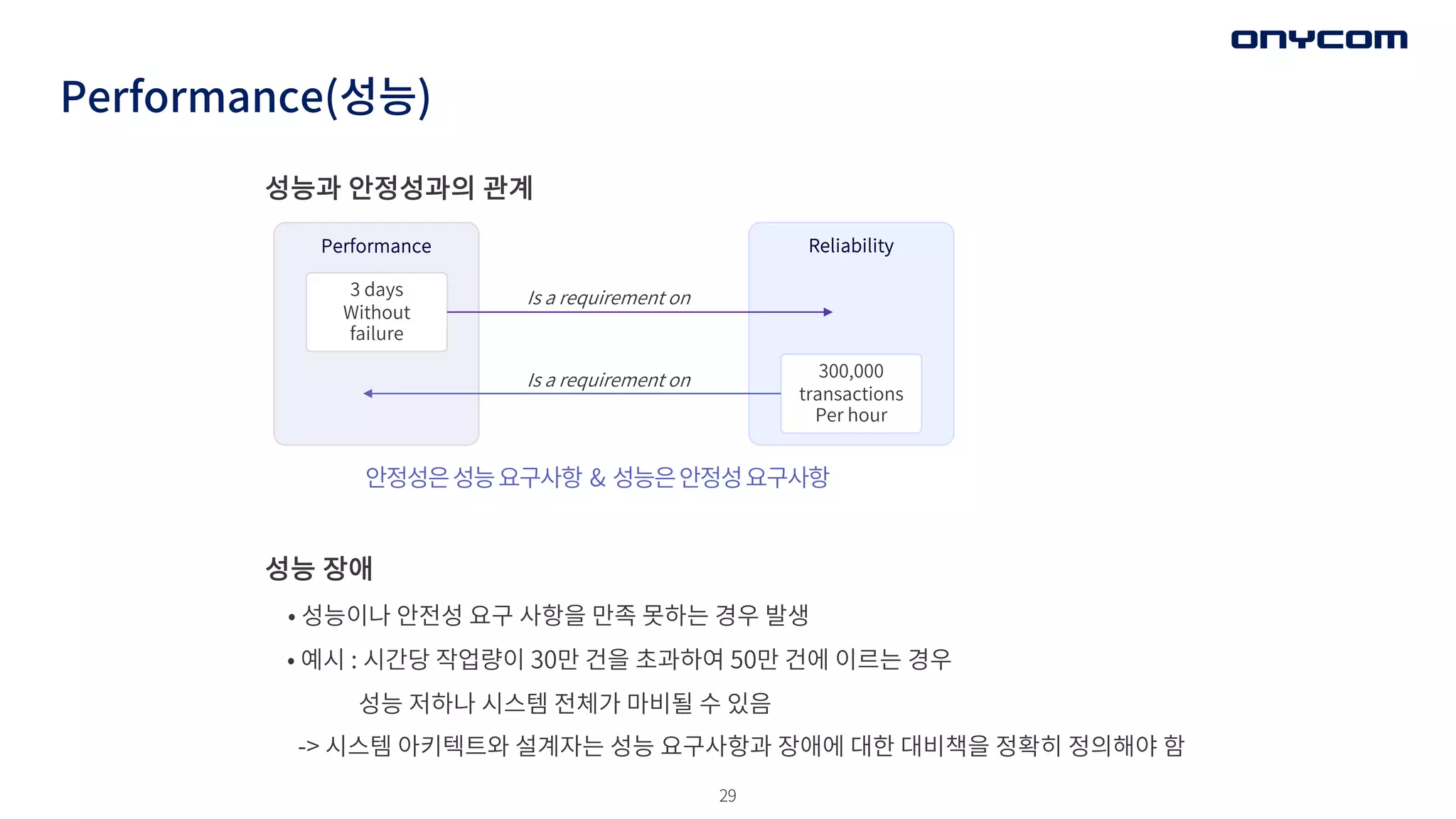
Performance(성능)
성능과 안정성과의 관계
성능장애
• 성능이나 안전성 요구 사항을 만족 못하는 경우 발생
• 예시 : 시간당 작업량이 30만 건을 초과하여 50만 건에 이르는 경우
성능 저하나 시스템 전체가 마비될 수 있음
-> 시스템 아키텍트와 설계자는 성능 요구사항과 장애에 대한 대비책을 정확히 정의해야 함
안정성은성능요구사항 & 성능은안정성요구사항
Performance Reliability
3 days
Without
failure
300,000
transactions
Per hour
Is a requirement on
Is a requirement on
32
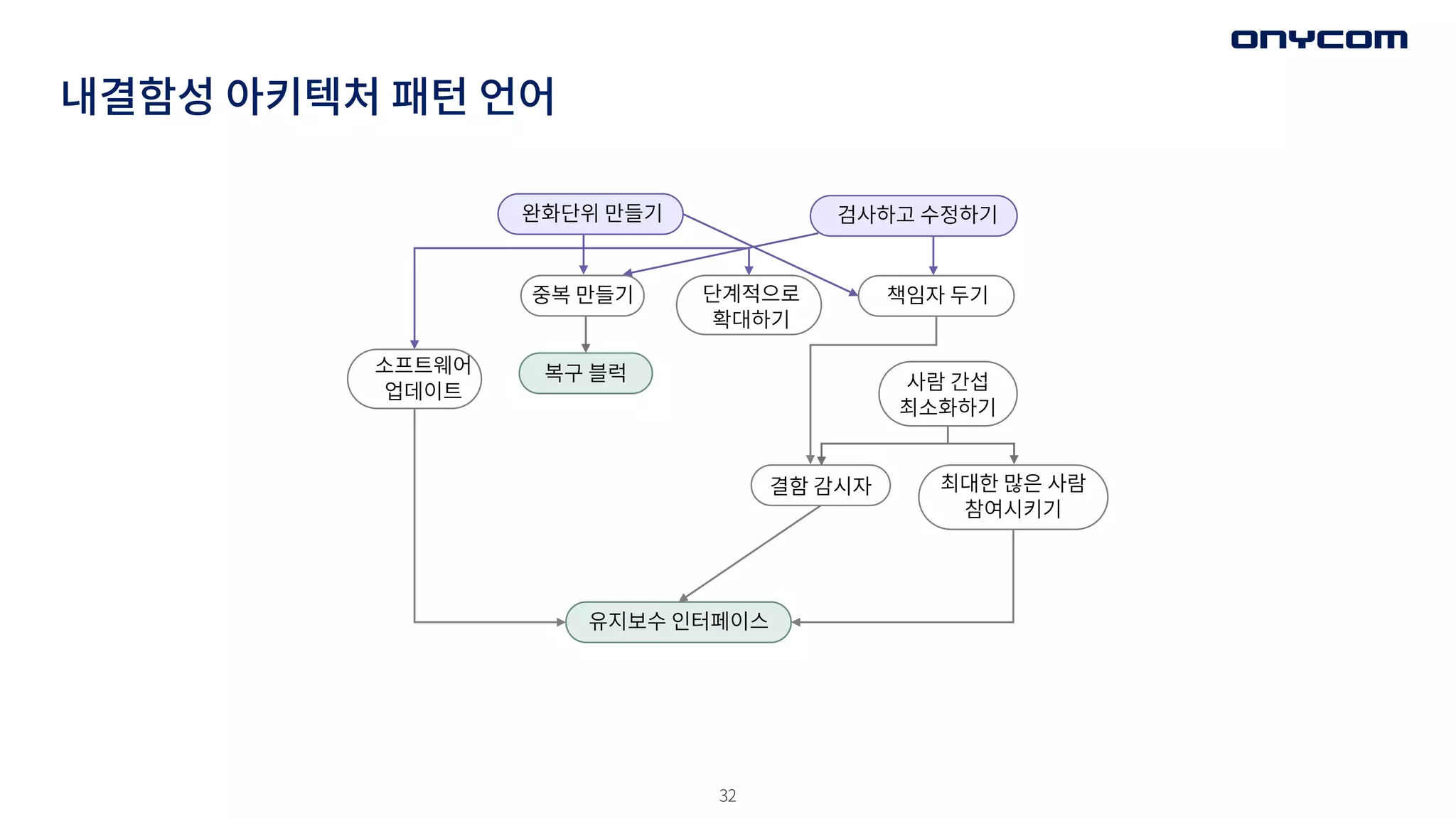
내결함성 아키텍처 패턴언어
완화단위 만들기
책임자 두기
결함 감시자
유지보수 인터페이스
검사하고 수정하기
단계적으로
확대하기
중복 만들기
소프트웨어
업데이트
복구 블럭
최대한 많은 사람
참여시키기
사람 간섭
최소화하기
33.
33
설계(초기)단계 고려(아키텍처) 패턴
•완화 단위 만들기
(UNITS OF MITIGATION)
• 검사하고 수정하기
(CORRECTING AUDITS )
• 중복된 컴포넌트 및 기능 만들기
(REDUNDANCY)
• 복구 블럭 (Recovery Block)
• 단계적으로 확대하기 (ESCALATION)
• 소프트웨어 업데이트
(SOFTWARE UPDATE)
• 유지보수 인터페이스 만들기
(MAINTENANCE INTERFACE )
• 책임자 두기
(SOMEONE IN CHARGE)
• 최대한 많은 사람 참여시키기
(MAXIMIZE HUMAN PARTICIPATION)
• 사람 간섭을 최소화하기
(MINIMIZE HUMAN INTERVENTION)
• 결함 감시자 (FAULT OBSERVER)
34.
34
완화 단위 (UNITOF MITIGATION)
• 충격을 흡수할 수 있는 모듈화
• 유닛의 구분
- 에러가 발생하는 유닛
- 에러를 감지하는 유닛
- 에러를 처리하는 유닛
• 트레이드 오프 관계
- 컴포넌트의 크기 (작을수록 완화하기 쉽다 vs 성능)
- 증감변화 (히스토리) 기록의 오버헤드
- 내 고장성의 다양한 옵션들 (복제, 롤백 등)
• 적절한 크기에 대한 조언
- 아키텍처 스타일 (3 ‒ Tier)
- 함수 또는 자원 (메모리, CPU) 단위로 경계 만들기
- 복구 액션 전략의 선택 (재시작, 롤백, 복제본 교체 등)
• 스스로 체크하고 조용히 실패하기 (fail silently)
35.
35
Failure를 대처하는 방법
•Fail Passive
고장이 발생하면 정지 시킴
• Fail Operational
고장이 발생하더라도
안전하게 기능을 유지
• Fail Silent
- 고장이 난 기능을 비활성화한후
Reset 시킨다
-> Fail Passive와 유사한 개념
- Fail Silent가 항상 좋을까?
- 많은 전장품으로 되어 있는
자동차는 적절치 않다. 주행 중 차가
멈추거나 비활성화, 리셋이 되면 더
큰 사고를 유발 할 수 있다.
- 그래서 고장이 나더라도 동작하는
Fail Operational이 중요하다
• Fail Passive
고장이 발생하면 경보를 울리고,
짧은 시간 동안 동작
System
capability
off
emergency time
0
t
fault
System
capability
off
emergency time
> 10s
t
fault
36.
36
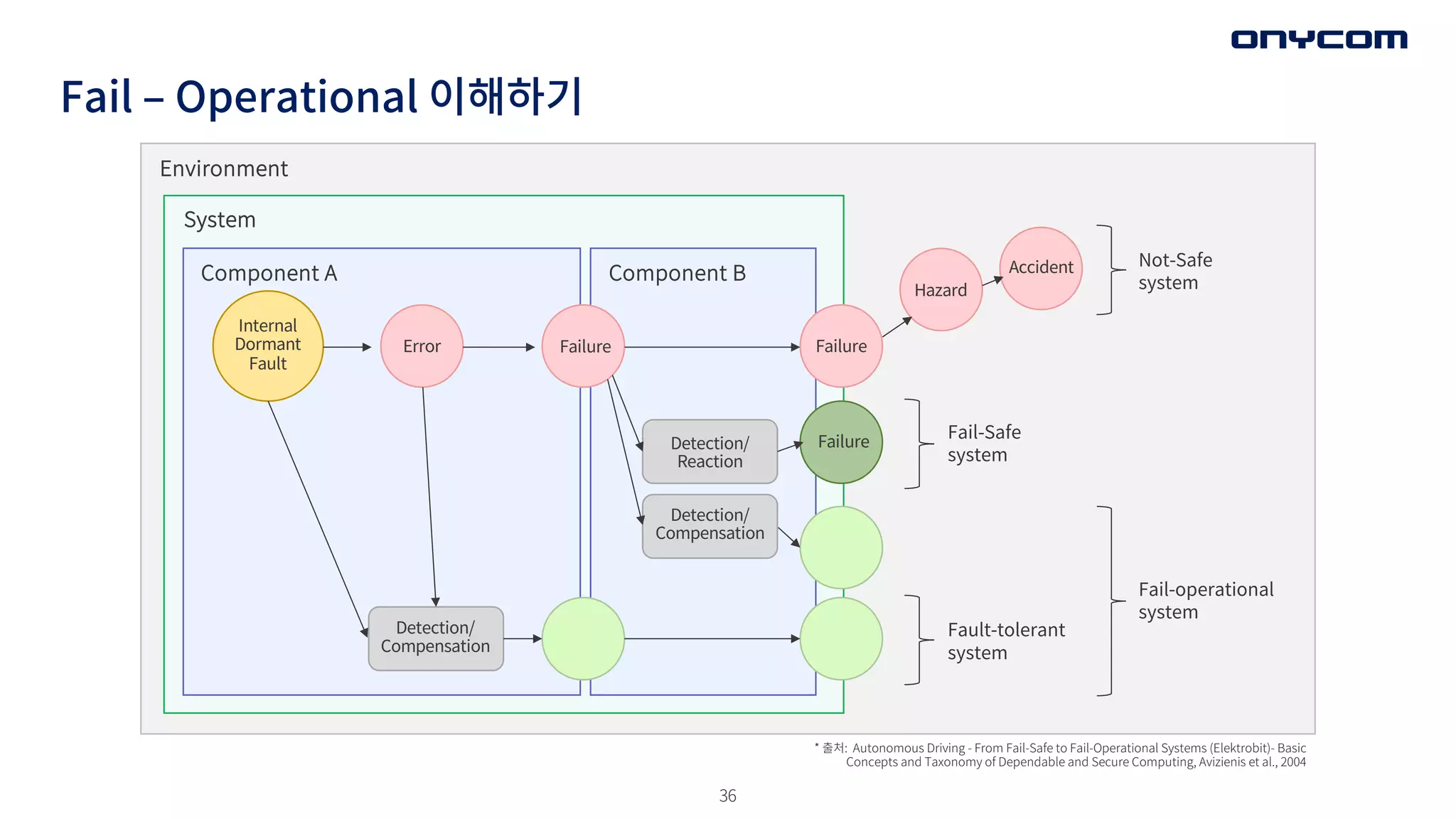
Fail ‒ Operational이해하기
Environment
System
Component A Component B
Internal
Dormant
Fault
Error Failure Failure
Hazard
Accident
Failure
Detection/
Reaction
Detection/
Compensation
Detection/
Compensation
Fail-Safe
system
Fault-tolerant
system
Fail-operational
system
Not-Safe
system
* 출처: Autonomous Driving - From Fail-Safe to Fail-Operational Systems (Elektrobit)- Basic
Concepts and Taxonomy of Dependable and Secure Computing, Avizienis et al., 2004
37.
37
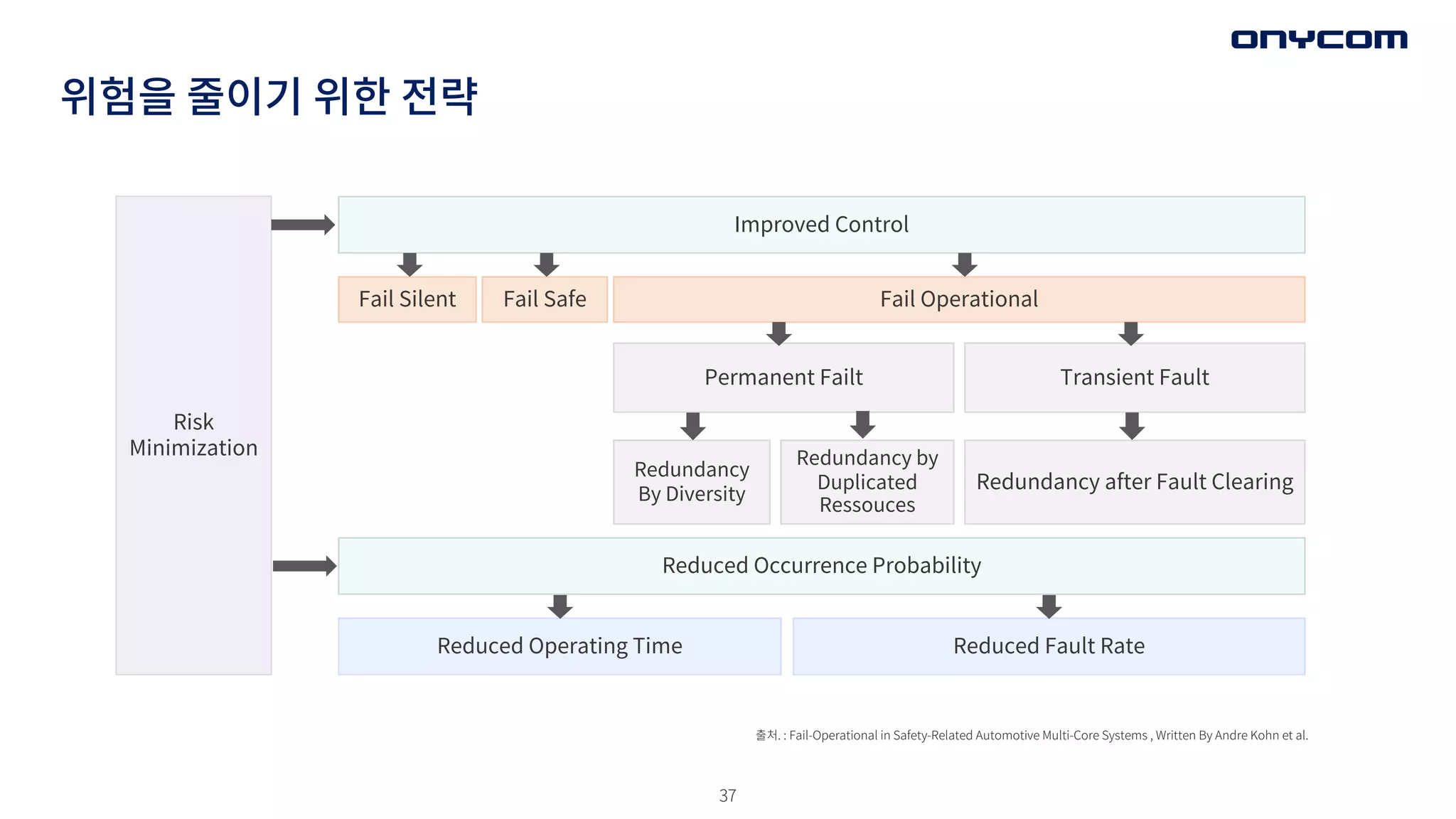
위험을 줄이기 위한전략
출처. : Fail-Operational in Safety-Related Automotive Multi-Core Systems , Written By Andre Kohn et al.
Risk
Minimization
Improved Control
Reduced Occurrence Probability
Fail Operational
Fail Safe
Fail Silent
Permanent Failt Transient Fault
Redundancy after Fault Clearing
Reduced Operating Time Reduced Fault Rate
Redundancy by
Duplicated
Ressouces
Redundancy
By Diversity
38.
38
잘못된 것 바로잡기 - 시정 감사
(CORRECTING AUDITS )
• 데이터의 손상은 하드웨어 또는 소프트웨어에서 발생
• 데이터 검사에는 정확한 기준이 필요
- 데이터 구조의 구조적 속성 (linked lists, pointer 경계...)
- 알려진 상관관계
(변환계수 ‒섭씨및 화씨, 교차연결 ‒ 링크드 리스트, 동일한 데이터가 여러 곳에 저장)
- 온전성 검사 (Sanity checks) - 예상 값 범위, 체크섬
- 직접 비교 (중복검사 , 대부분 Static 데이터 .. )
• 조치(Actions): 수정, 로그 남기기, 재실행 (resume execution)
39.
39
잘못된 것 바로잡기 - 시정 감사
(CORRECTING AUDITS )
• 도구의 힘 + 경험이 더해져야 함
• 런타임 Fault는 정말 찾기 힘듦
+ 도메인 이슈는 더 어려움
40.
40
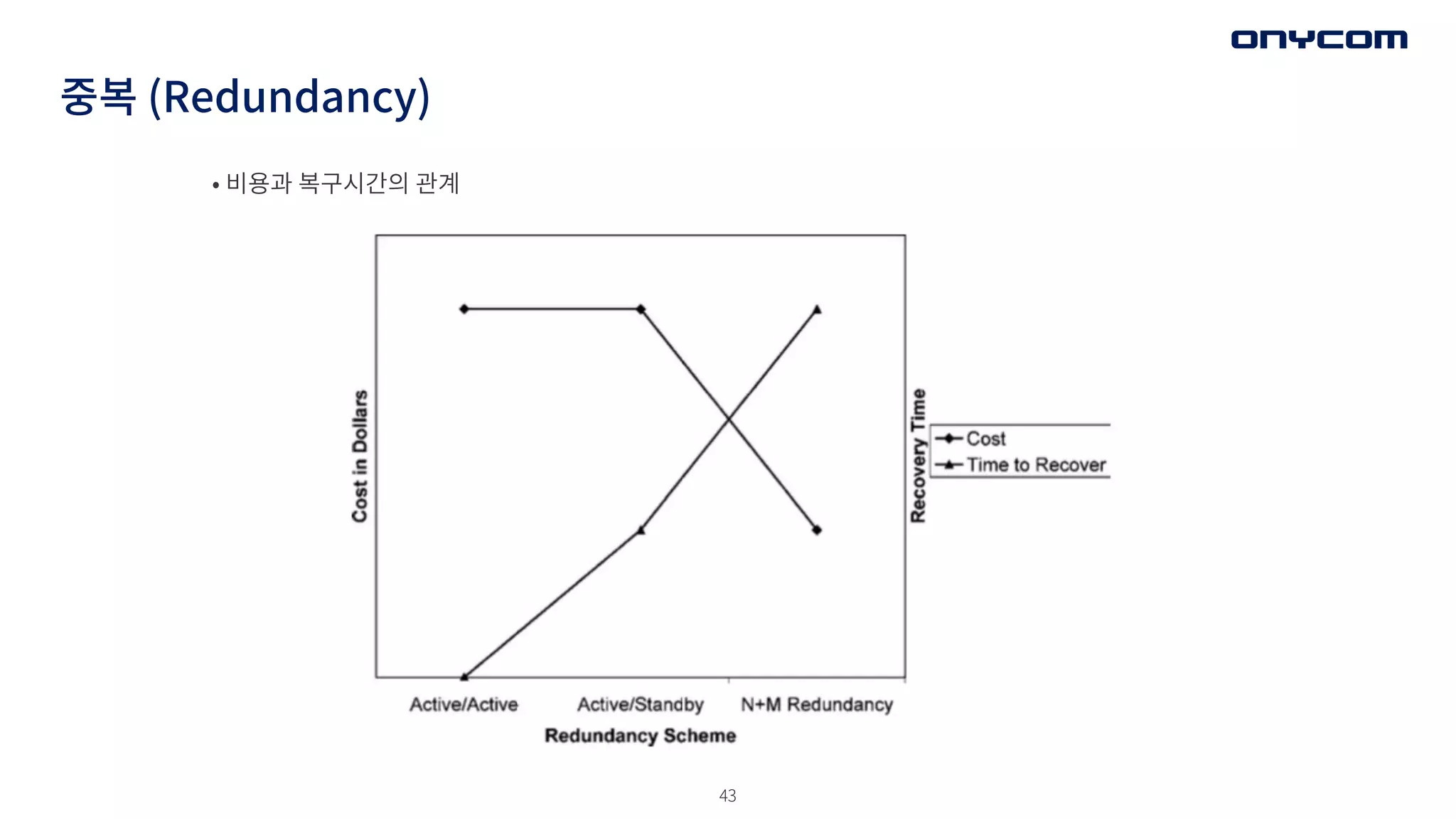
중복 (Redundancy)
• MTTR(복구시간)을줄여 가용성을 향상시키는 것은 가장 쉬운 방법
• 오류 복구는 시스템을 오류없는 상태로 돌림
- Fault를 빠르게 감지 (Fault Observer 패턴) 하는 것이 것이 중요함
- 복구하는데 걸리는 시간을 고려해야함. CheckPoint , Rollback (패턴) 전략은
많은 양의 메모리를 복사하는 등 복구에 상대적으로 시간이 더 걸림
• 아이디어 : 동일한 복사본을 사용하여 오류가 발생하기 이전으로, 실행 재개
- 다른 하드웨어/소프트웨어에서 동일한 작업 수행
- 동일한 기능을 의미하는 것이 아니라 동일한 작업을 수행하는 전략
- 중복 기능의 빠른 활성화 필요
41.
41
중복 (Redundancy)
• 중복성을제공하는 방법
• 공간 중복성: 시스템에 중복된 여러 복사본이 존재 (다른 위치)
- 중복성이 항상 동일한 기능을 의미하지 않음
- 시스템의 다른 부분이 고장난 부분의 작업을 수행할 수 있음
- 다양한 변형이 존재함
- 5개의 컴퓨터 : 동일한 기능을 수행하는 4대의 머신, Voting을 하는 1개의 머신
N ‒ Version , Voting 패턴과 연관되어 있음
• 임시적인 중복 (Recovery Block)
- Recovery Block 패턴 : 중간 중간 데이터를 저장하는 전략
- 게임의 Save Point가 좋은 예
- Error Handling 패턴 으로 처리가 되지 않을 때 사용
• 정보 중복성 : 시스템에 동일한 데이터를 여러 버전에 사용할 수 있도록 제공
- 어떤 데이터는 디스크에, 어떤 데이터는 메모리에 저장 가능
42.
42
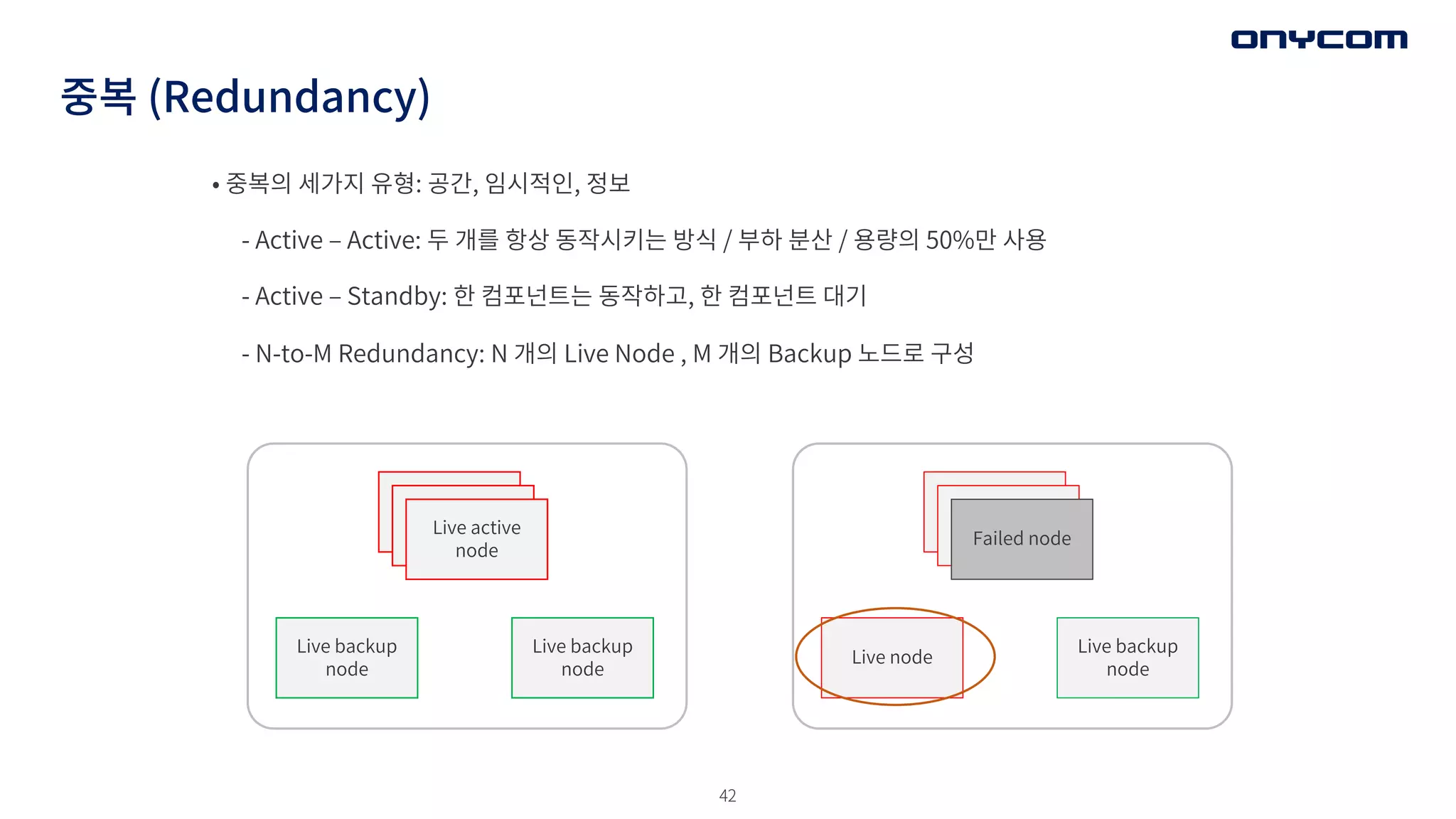
중복 (Redundancy)
• 중복의세가지 유형: 공간, 임시적인, 정보
- Active ‒ Active: 두 개를 항상 동작시키는 방식 / 부하 분산 / 용량의 50%만 사용
- Active ‒ Standby: 한 컴포넌트는 동작하고, 한 컴포넌트 대기
- N-to-M Redundancy: N 개의 Live Node , M 개의 Backup 노드로 구성
Live active
node
Live active
node
Live active
node
Live backup
node
Live backup
node
Live active
node
Live active
node
Failed node
Live node
Live backup
node
45
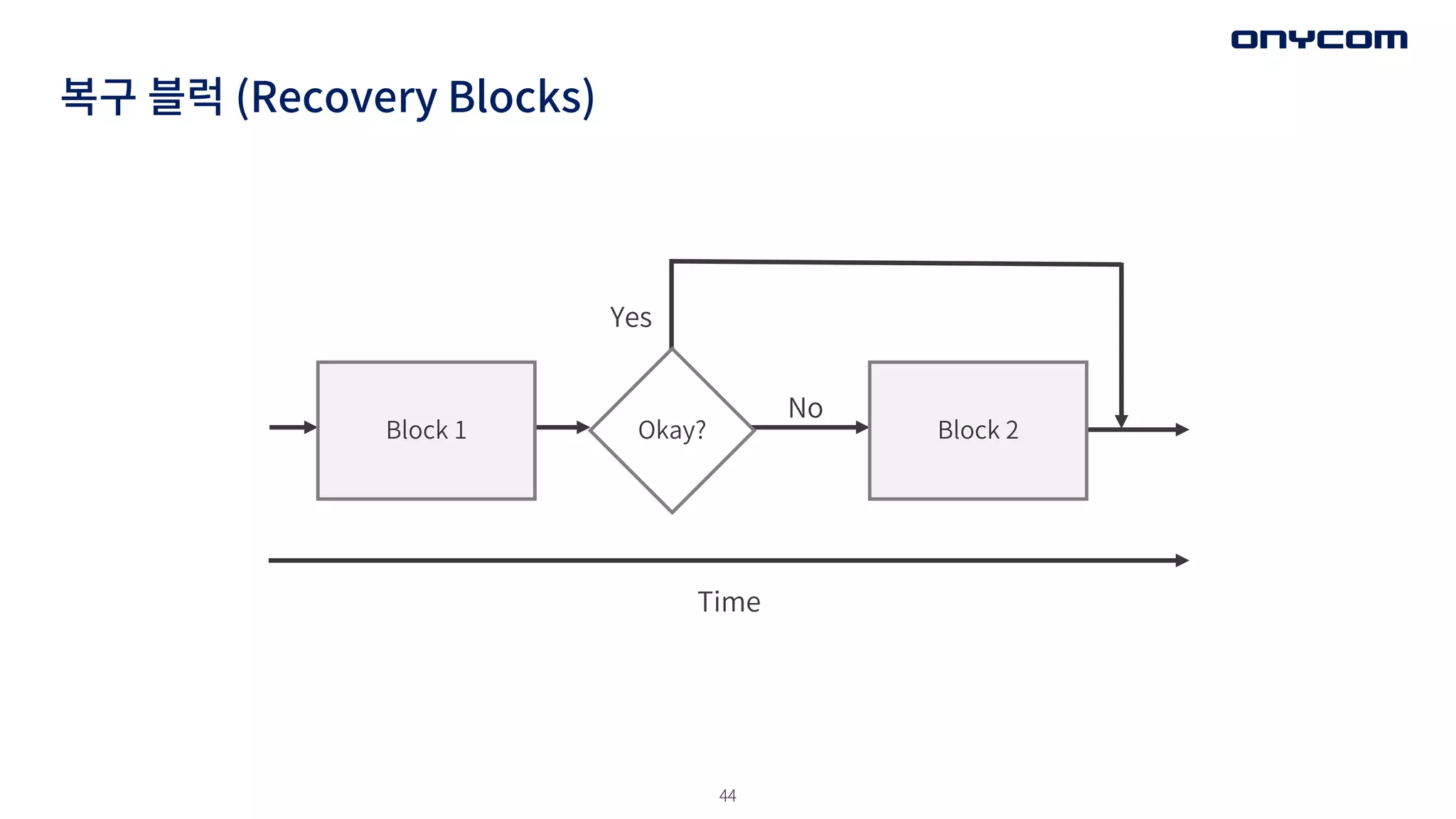
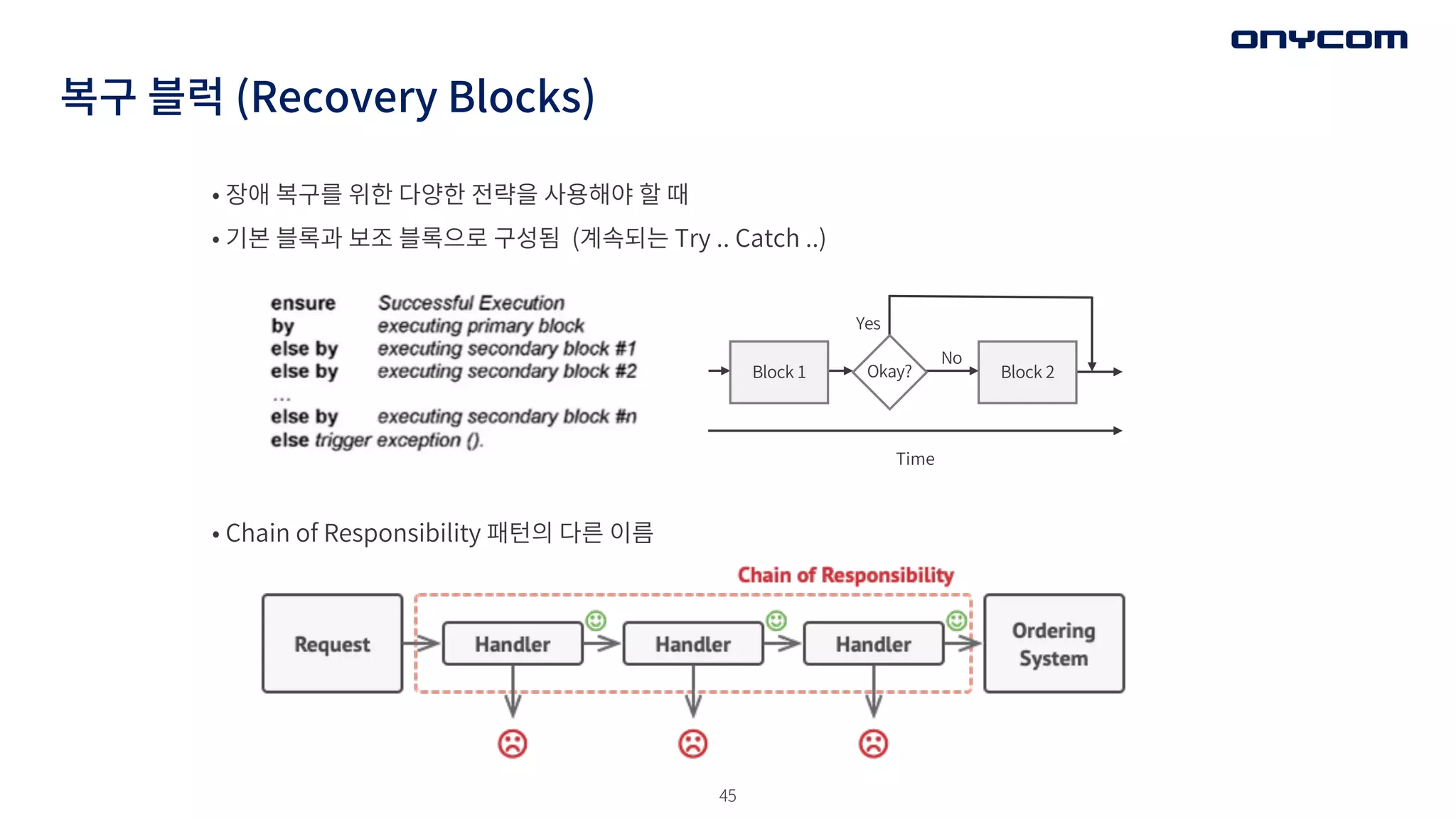
복구 블럭 (RecoveryBlocks)
• 장애 복구를 위한 다양한 전략을 사용해야 할 때
• 기본 블록과 보조 블록으로 구성됨 (계속되는 Try .. Catch ..)
Block 1 Block 2
Time
Okay?
Yes
No
• Chain of Responsibility 패턴의 다른 이름
46.
46
복구 블럭 (RecoveryBlocks)
• 첫번째 복구 블럭의 책임
가능한 많은 문제를 풀 수 있는 해결책을 전진 배치 시켜라
• 복구 블럭 배치 순서
장애를 해결할 확률이 높은 녀석을 전진 배치 시켜라
여러 개의 복구 블럭을 거쳐도, 분위기가 심상치 못하면 Escalation (패턴)을 해서 알려라
Escalation 단계가 올라갈 때마다, 참여하는 사람의 레벨이 높아짐
• 마지막 복구 블럭의 책임
어떻게 든 문제를 해결해야 한다
-> 전문가 참여(Maximize Human Participation 패턴) 시켜서라도 긴급하게 해결해라
47.
47
유지 관리를 위한별도의 인터페이스 구축하기
(Maintenance Interface)
• 유지 관리 명령을 입력하는 것은 서비스의 중요한 시점
- 과부하를 제어 (Circuit Breaker, Shed Load)
- 서버를 늘린다거나 (Auto Scaling)
- 서비스의 상태 확인 ( 설정, 로깅, 상태 확인)
- 어플리케이션의 입력을 통해 제어할 경우, 장애에 취약함
(보안, 테이블 전체 스캔, 파일, 폴더 지우기..)
• 별도의 유지 관리 인터페이스 만들기
- 별도의 운영/장애관련 유지관리 인터페이스는 구축은 가용성을 증대함
- 제한된 사용자만 사용하게 함 (보안 문제 해결)
- 작업자가 올바른 경로를 안내하여 실수를 줄이게 함 (Minimize Human Interface)
48.
48
유지 관리를 위한별도의 인터페이스 구축하기
(Maintenance Interface)
서비스 장애가 예측되는 경우.
예상치 못하게 과도한 트래픽, 데이터가 들어올 때,
• 데이터 수집 비율 축소
• 수집 주기 제어
• 로그 저장 시간 축소
• 저장하는 로그정보 제어
• 단 관리자만 접근 가능하게 권한 제어
49.
49
단계별로 더 강하게처리하기(Escalation)
• 일시적인 오류인지 파악하기 (Riding over Transients)
-일시적인 오류인지 아닌지 판단하는게 중요
: 일시적인 오류에 너무 민감하게 반응하면 일이 커짐
- 일시적인 오류는 반복되는 복구를 시도하는게 유효할 때도 있다.
- 반복되는 복구 전략이 안먹히면.. 더큰 장애가 발생할수 있다.
- 재시도를 제한(Limit Retries) 해라
50.
50
단계별로 더 강하게처리하기(Escalation)
• 해결 방법 (다양한 단계 두기)
- 1단계 : Checkpoint, Rollback 시도하기 (이전 상태로 돌리기)
- 2단계 : Restarted (재시작) 하기
- 3단계 : FailOver ‒ 중복된 프로세스/컴포넌트로 수행하기
• 사례 (Known Use) - 최초의 디지털 전화 스위치 4ESS
- 오류감지 : 간헐적인 데이터 오류 -> 일시적인 오류인지 체크 / 빈도수가 특정 시간에 여러 번
발생하는지 체크 (Leaky Bucket Counter 패턴)
- 1단계 : 데이터 구조를 초기화 -> 몇 번해도 안되면..
- 2단계 : 복구 전략 시도 -> 몇 번해도 안되면..
- 3단계 : 가능한 모든 수단을 동원하여, SW,HW 상태 보정
- 4단계 : 모든 동적인 데이터 값을 초기화 함(DATA RESET 패턴)
• 부하가 많아 발생하는 장애라면,
성능을 차별적으로 제한하는 Slow It Down (계단식 제한)도 Escalation 전략도 있음
51.
51
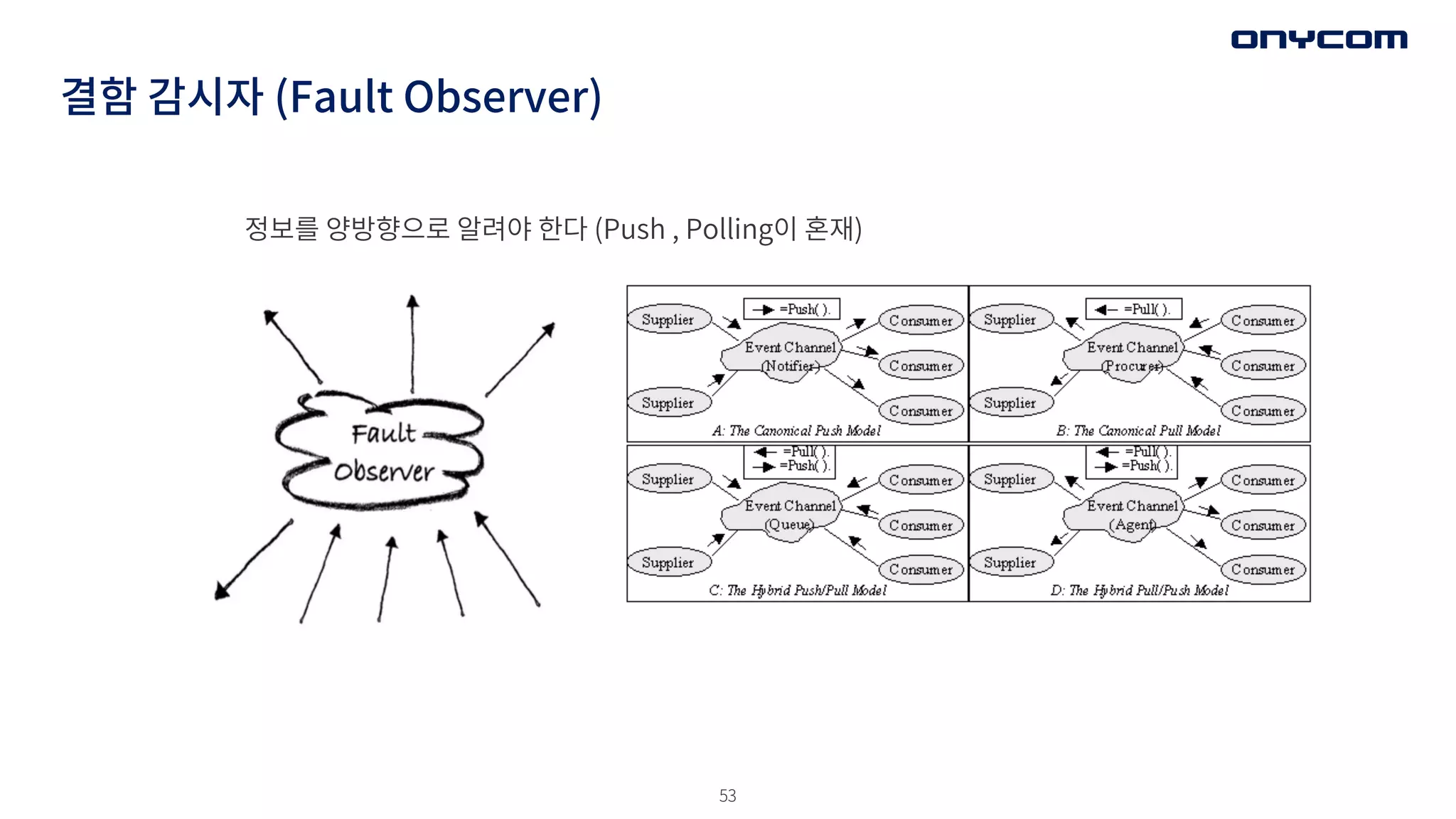
결함 감시자 (FaultObserver)
• 시스템의 오류를 단순한게 처리할수 없다면
• 결함에 영향을 받는 여러 컴포넌트/서비스들에게 결함 정보를 효과적으로 알려야 한다면..
• 사례: 산림청은 화재를 감지하기 위해 소방탑을 운영하고 있다.
- 마을 인근 산에서 불이 나면 대응 책은?
- 삼각 측량을 고민해 불이 번질 위치에 대한 도움은? (바람의 세기, 방향은 누구에게)
- 초기 화재를 빠르게 진압하기 위해 누구에게?
- 주위 마을이 있다면, 마을 주민에게는 어떻게 알려야 하는지?
52.
52
결함 감시자 (FaultObserver)
• 결함에 관심을 가진 수진자/관계자에게 잘 알리기
• Pub-Sub 또는 Event Channel 패턴 으로 체계 구축하기
54
소프트웨어 업데이트 (SoftwareUpdate)
• 소프트웨어의 새로운 기능이나 오류를 처리하기 위한 방법
• 주의할 점
- 소프트웨어 업데이트시 시스템이 멈춰서는 안된다.
- 가용성을 최대한 유지 / 다운타임을 최소화
• 중복을 이용한 배포 (RED-GREEN / RED BLACK 배포)
- 새 버전의 더 많은 문제가 생기면 이전 버전으로 회귀(Recovery Block)
- 이전 버전과 새 버전을 일부 배포해서 같이 운영후 판단 (Canary)
- 가능한 모듈로 나눠져 있어서 부분 패치만 (Small Patch)
55.
55
소프트웨어 업데이트 (SoftwareUpdate)
• 업데이트 전략 (가용성 이슈)
- 모든 컴포넌트에게 일순간 새 버전을 받게 할건지 ?
- 스케줄러로 순차적으로 돌아가면 할건지?
• 업데이트 스케줄링 전략은 어떻게?
- 설치 시간을 Seed 값으로
- 순차적으로 티켓을 받아가며 서서히 업데이트 할지
- 우선순위 높은 장비만 먼저 업데이트 할려면?
• Reference Counted 패턴, Half-Push/Half-Polling 패턴
57
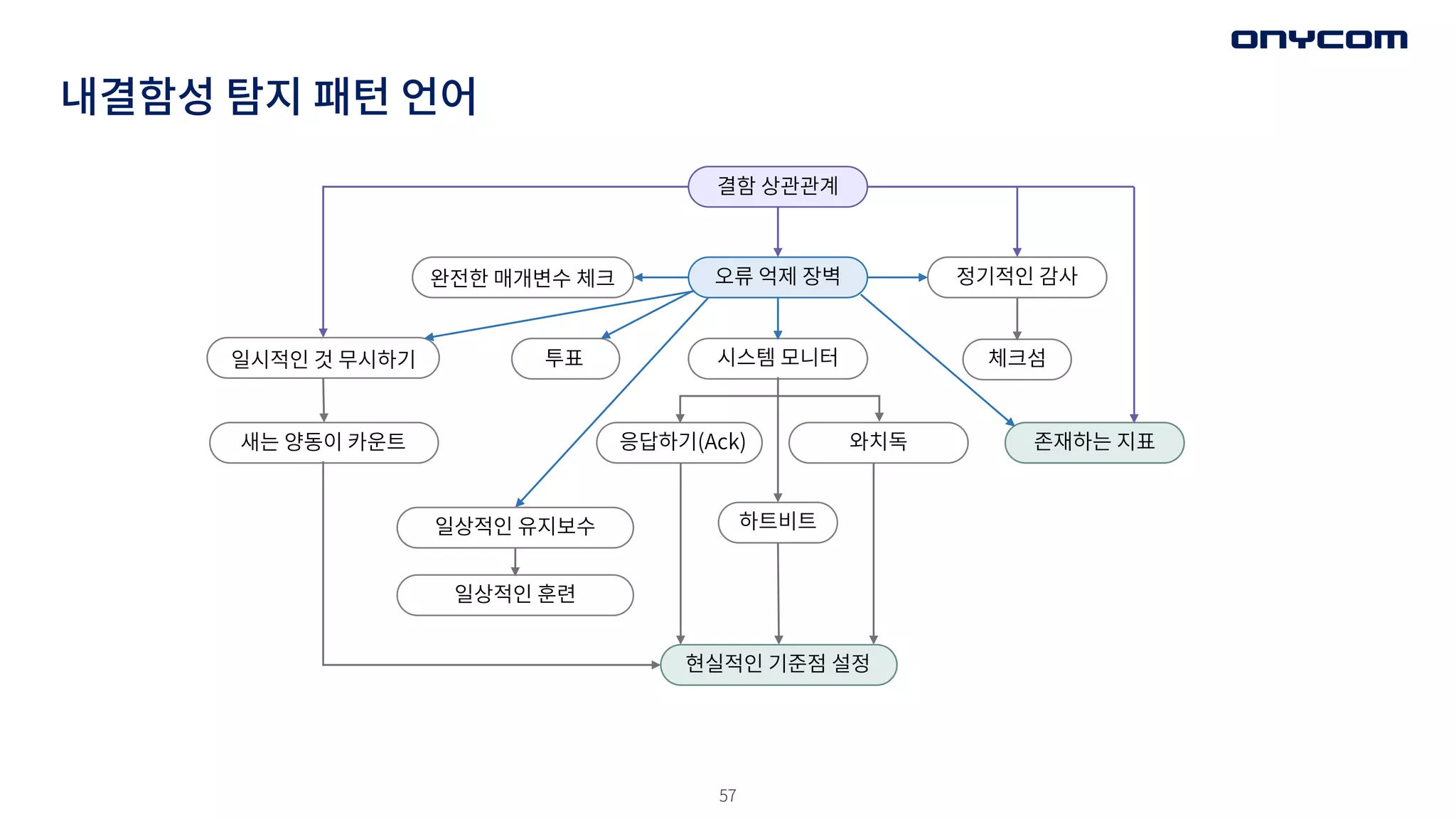
내결함성 탐지 패턴언어
일시적인 것 무시하기
결함 상관관계
오류 억제 장벽 정기적인 감사
완전한 매개변수 체크
체크섬
존재하는 지표
시스템 모니터
와치독
응답하기(Ack)
하트비트
현실적인 기준점 설정
투표
새는 양동이 카운트
일상적인 유지보수
일상적인 훈련
58.
58
탐지 패턴
• 결함상관 관계 (Fault Correlation)
• 오류 억제 장벽 (Error Containment
Barrier)
• 완전한 매개변수 확인
(Complete Parameter Checking)
• 시스템 모니터(SYSTEM MONITOR)
• 하트 비트 (HEARTBEAT )
• 받았다고 알리기
(ACKNOWLEDGEMENT)
• 감시견 (WatchDog)
• 현실적인 임계값 (Realistic Threshold)
• 기존 지표 (Existing Metric)
• 투표 (Voting)
• 일상적인 유지보수
(Routine Maintenance)
• 일상적인 훈련 (Routine Exercise)
• 정기 감사 (Routine Audits)
• 체크섬 (CHECKSUM)
• 일시적인 것들은 무시하기
(RIDING OVER TRANSIENTS )
• 새는 양동이 카운트
(Leaky Bucket Counter)
59.
59
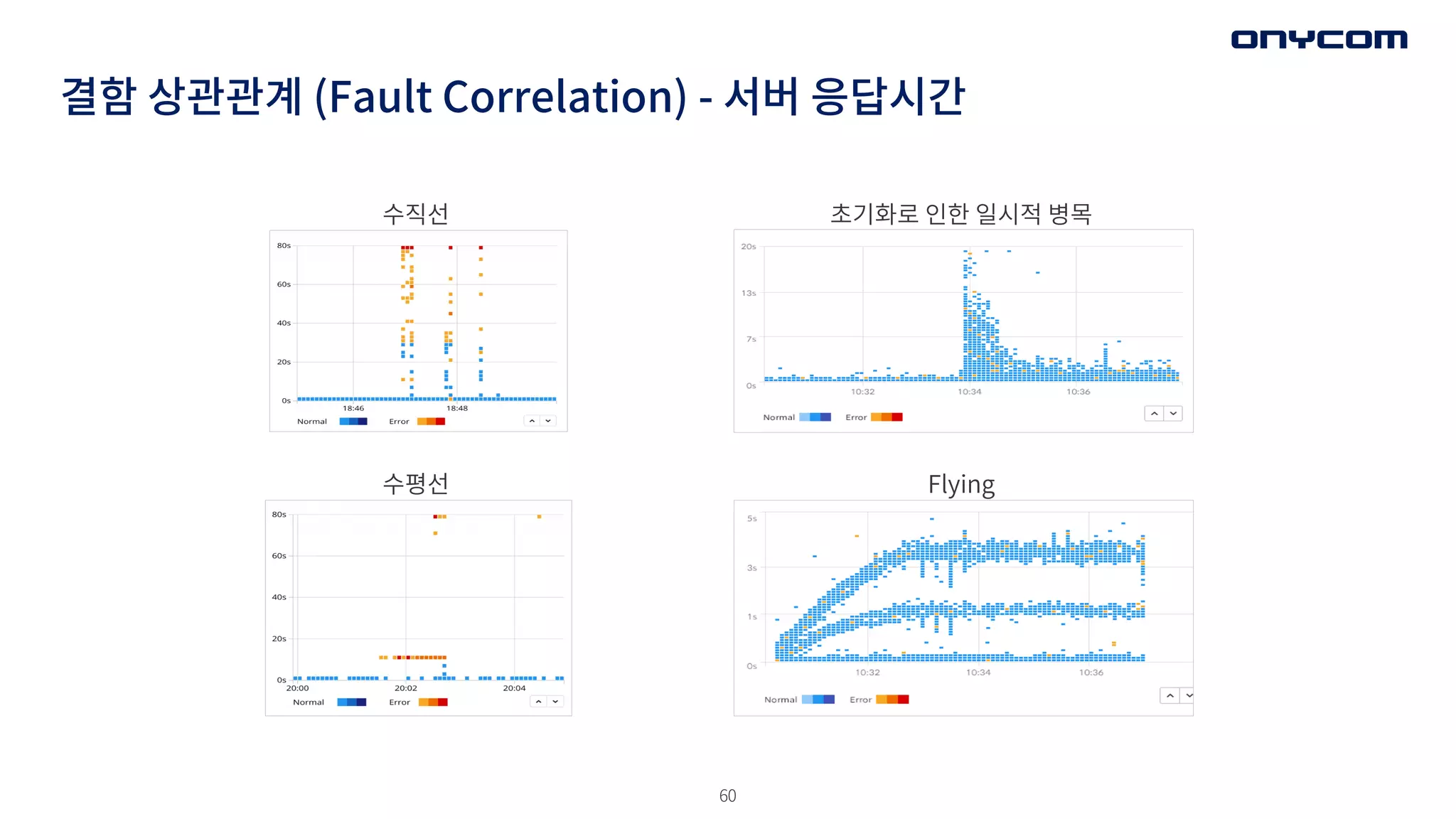
결함 상관관계 (FaultCorrelation)
• 여러개의 오류( Error) 메세지를 분석하여, 실제 활성화된 결함(Fault)을 식별한다.
• 전제조건 : 흔한 에러 유형은 조기에 제거를 한 이후
• 결함을 분류하기 위해, 에러의 독특한 시그니처를 살펴 보아라
- 실례: 테스트 도중 범위(off-by-one)와 관련된 많은 에러를 발견함
- 데이터 오류 발생: 관련 데이터를 사전에 확인(점검)해라
• 여러 오류가 가까운 시간에 발생한다 : 결함 위치를 삼각 측량하기 (범위 좁히기)
• 결함 - 오류 ‒ 오류 체인: 오류 체인을 시작한 초기 오류를 먼저 처리해라
60.
60
결함 상관관계 (FaultCorrelation) - 서버 응답시간
수직선
수평선
초기화로 인한 일시적 병목
Flying
62
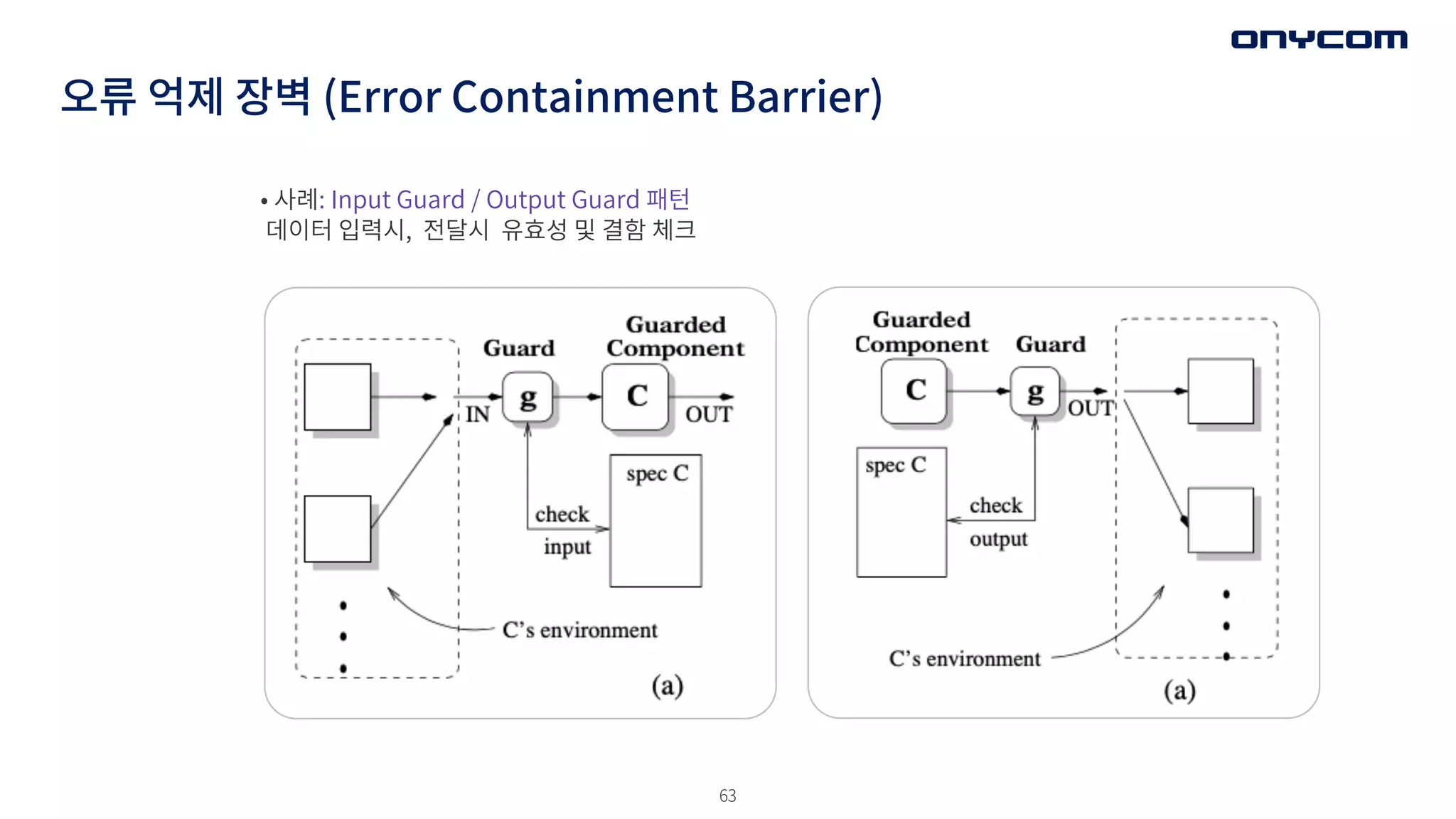
오류 억제 장벽(Error Containment Barrier)
• 오류에 감염된 시스템이 오류를 계속 전파하는 것을 막는 방법은?
• 오류는 메세지, 메모리, 후속 조치의 사이드 이펙트등으로 확산될수 있다.
• 오류 억제 장벽을 구현해라 (완화 단위의 한 수단)
- 별도의 구성 요소로 취급하기
- 에러 상태를 캡슐화 (감싸거나) 하거나, 복구/완화를 수행함
- 결함과 가까운 곳에서 감지를 수해해라 (위치적/시간적)
• 하드웨어
- 상태 비트로 결함있는 구성요소를 격리 시키기
64
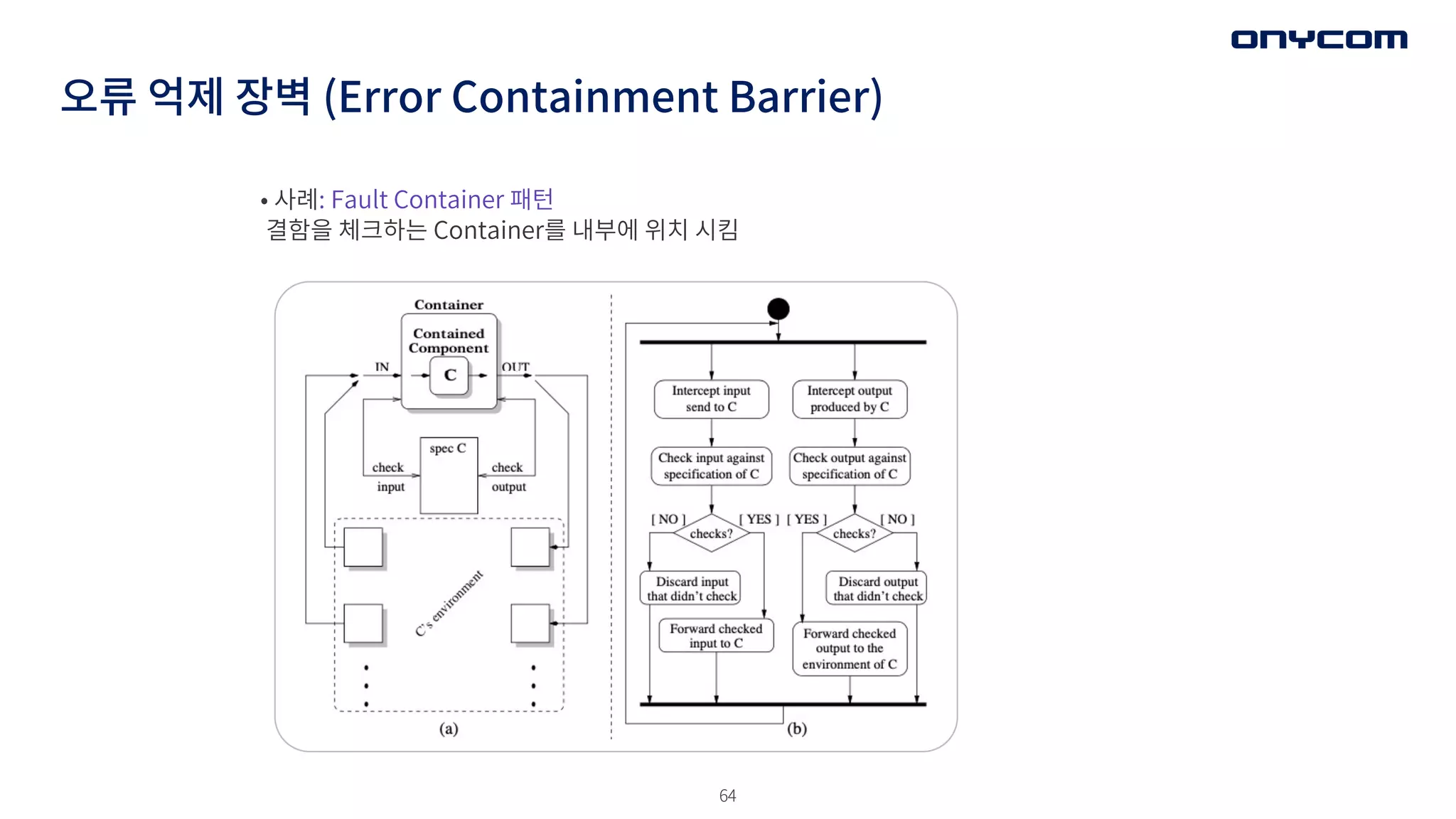
오류 억제 장벽(Error Containment Barrier)
• 사례: Fault Container 패턴
결함을 체크하는 Container를 내부에 위치 시킴
65.
65
오류 억제 장벽(Error Containment Barrier)
• 또 다른 사례
1. 에러를 완화시킨다.
- Marked Data 패턴
에러를 유발하는 데이터를 마킹함
에러 있는 데이터를 처리하는 룰을 정의함
- Correcting Audit - 패턴 오류가 있는 요소를 수정함
2. 오류 없는 상태를 만들기 위해 복구하기
- Check Point 패턴
- Rollback 패턴
- Roll-Forward 패턴
- Fault Observer 패턴 ‒ 적절한 오류처리기에 전달 (알림, 로깅 등)
69
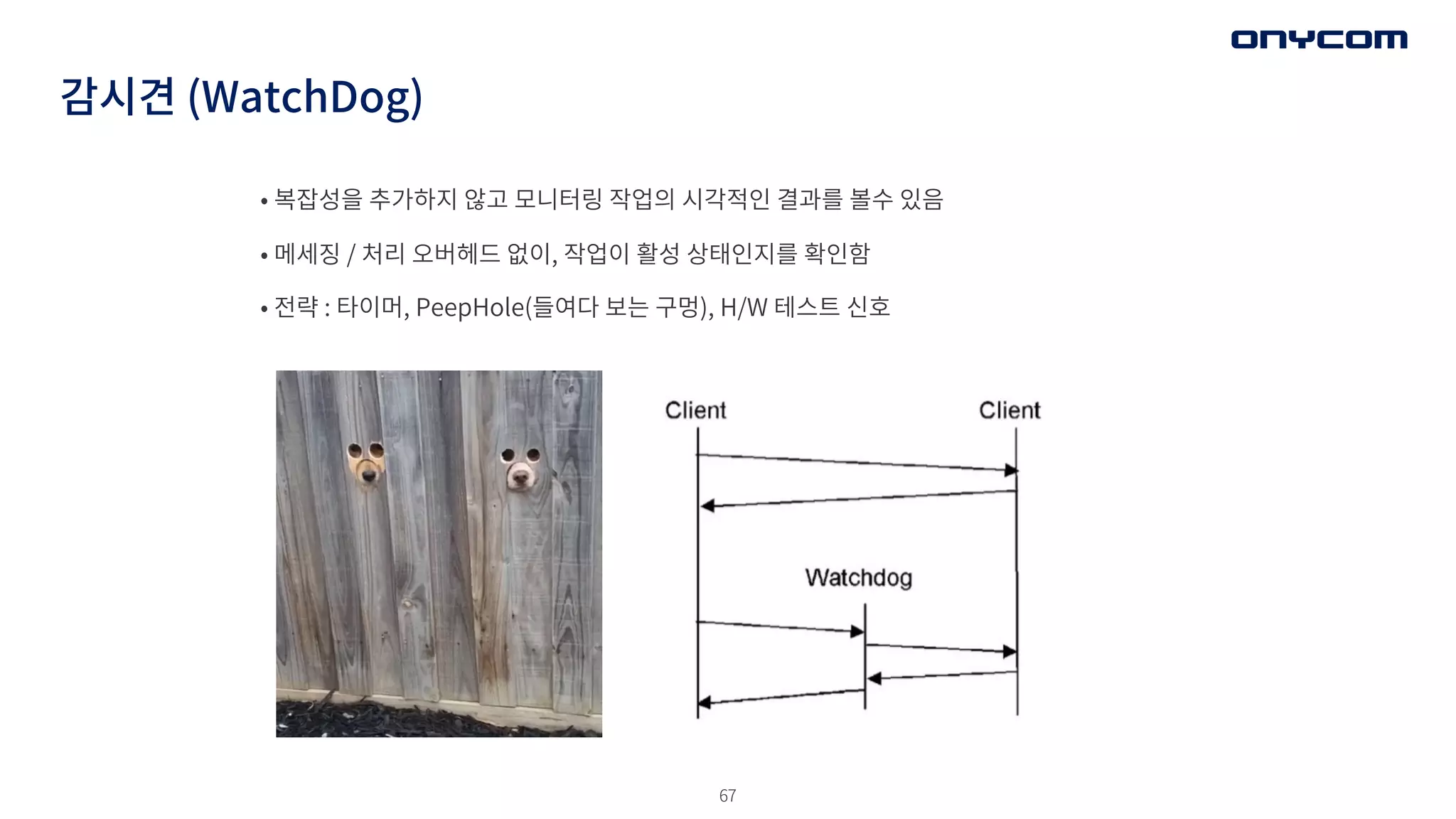
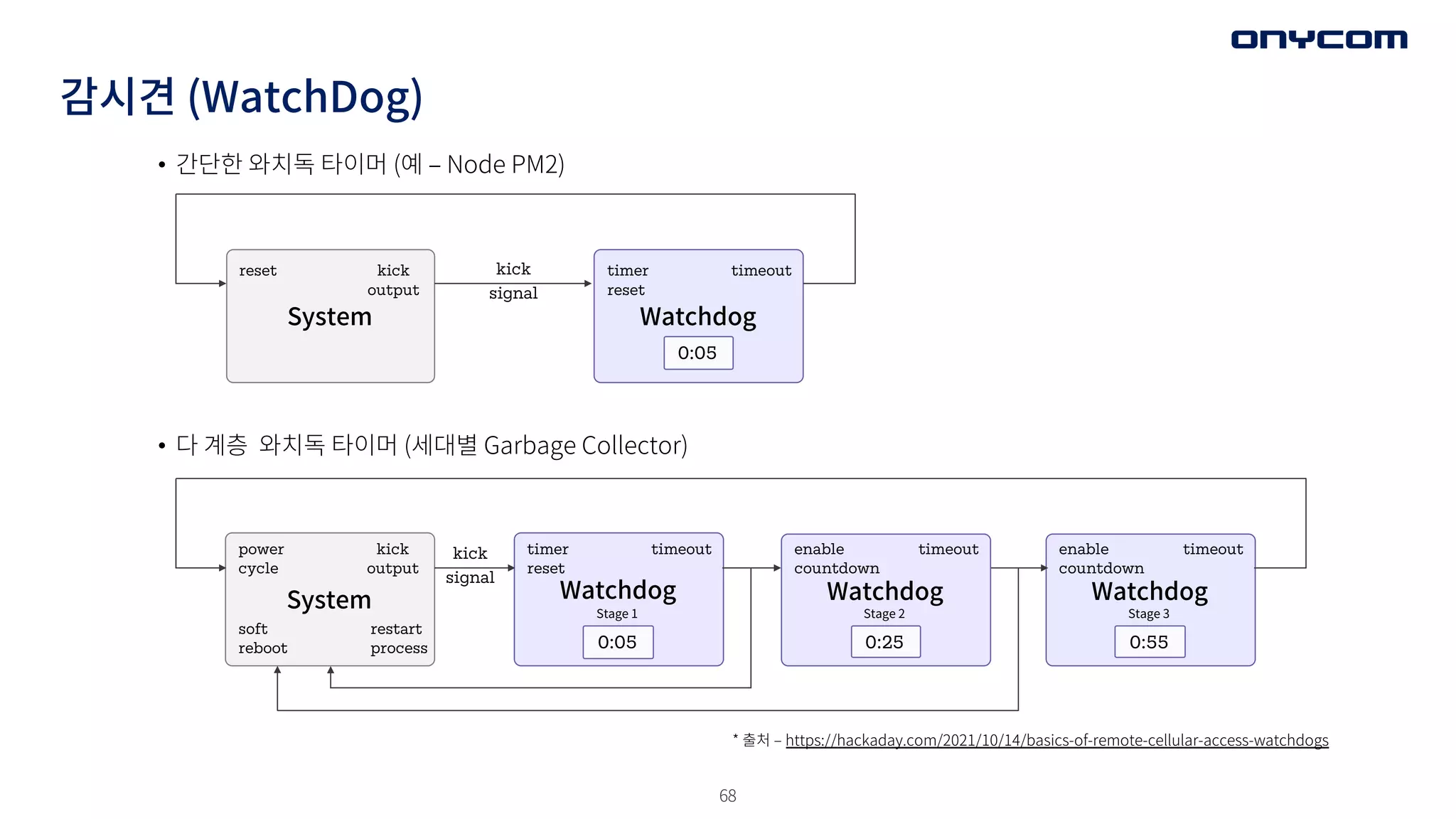
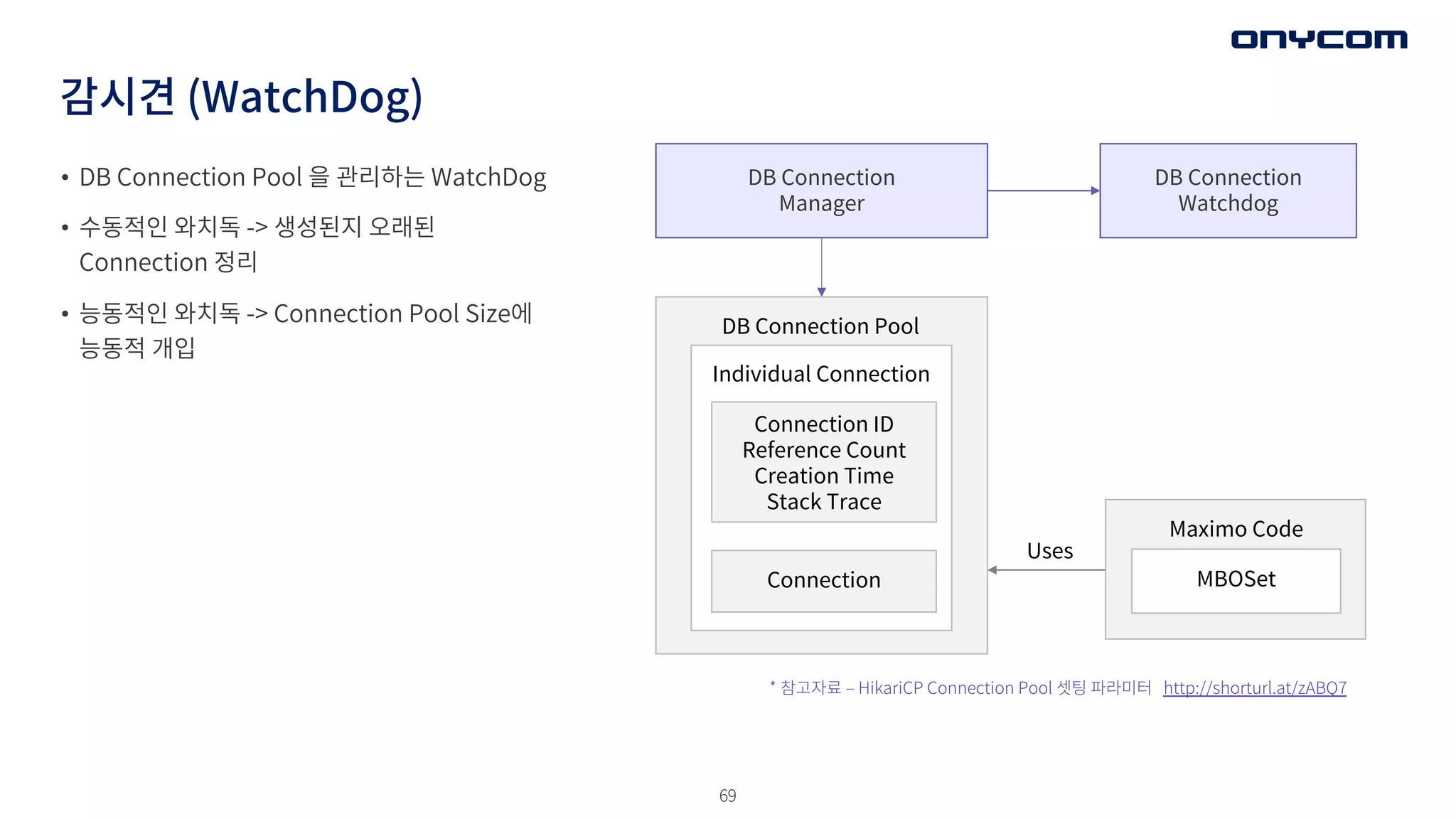
감시견 (WatchDog)
DB Connection
Manager
DBConnection
Watchdog
DB Connection Pool
Individual Connection
Connection ID
Reference Count
Creation Time
Stack Trace
Connection
Maximo Code
MBOSet
Uses
* 참고자료 ‒ HikariCP Connection Pool 셋팅 파라미터 http://shorturl.at/zABQ7
• DB Connection Pool 을 관리하는 WatchDog
• 수동적인 와치독 -> 생성된지 오래된
Connection 정리
• 능동적인 와치독 -> Connection Pool Size에
능동적 개입
70.
70
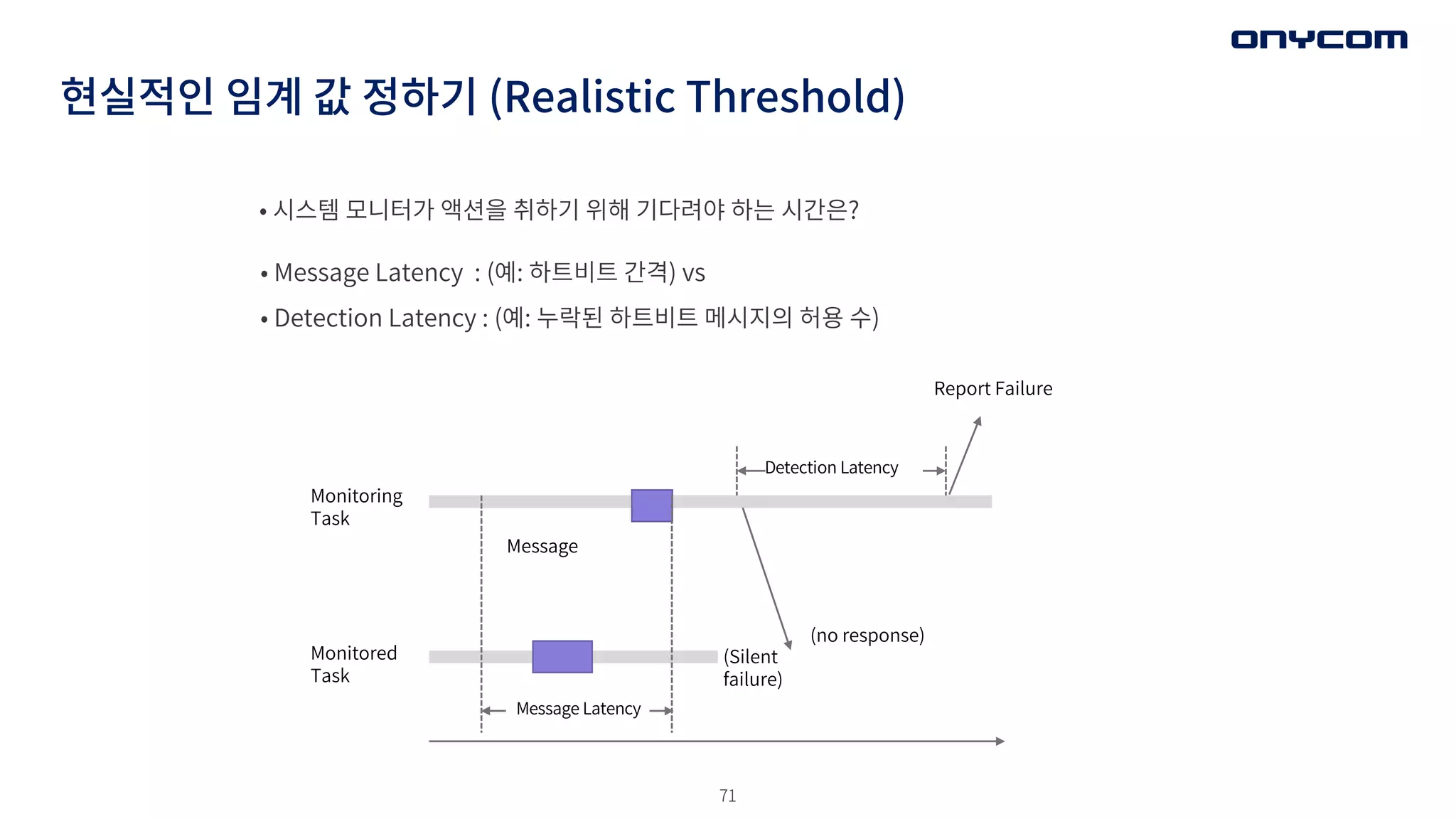
현실적인 임계 값정하기 (Realistic Threshold)
• 시스템 모니터가 액션을 취하기 위해 기다려야 하는 시간은?
• Message Latency : (예: 하트비트 간격) vs
• Detection Latency : (예: 누락된 하트비트 메시지의 허용 수)
• Heartbeat 메시지를 정할 때 고려해야 하는 시간들
- 모니터링 작업을 시작하기 전에 준비시간 - 20ms
- 모니터링 시작 + 모니터링 대상으로부터 응답 시간 - 15ms
- 응답을 처리하는 시간 ‒ 15ms
- 메시지 RoundTrip 시간 : 50ms ~ 100ms
71.
71
현실적인 임계 값정하기 (Realistic Threshold)
• 시스템 모니터가 액션을 취하기 위해 기다려야 하는 시간은?
• Message Latency : (예: 하트비트 간격) vs
• Detection Latency : (예: 누락된 하트비트 메시지의 허용 수)
Monitoring
Task
Monitored
Task
Message Latency
(Silent
failure)
Message
(no response)
Report Failure
Detection Latency
72.
72
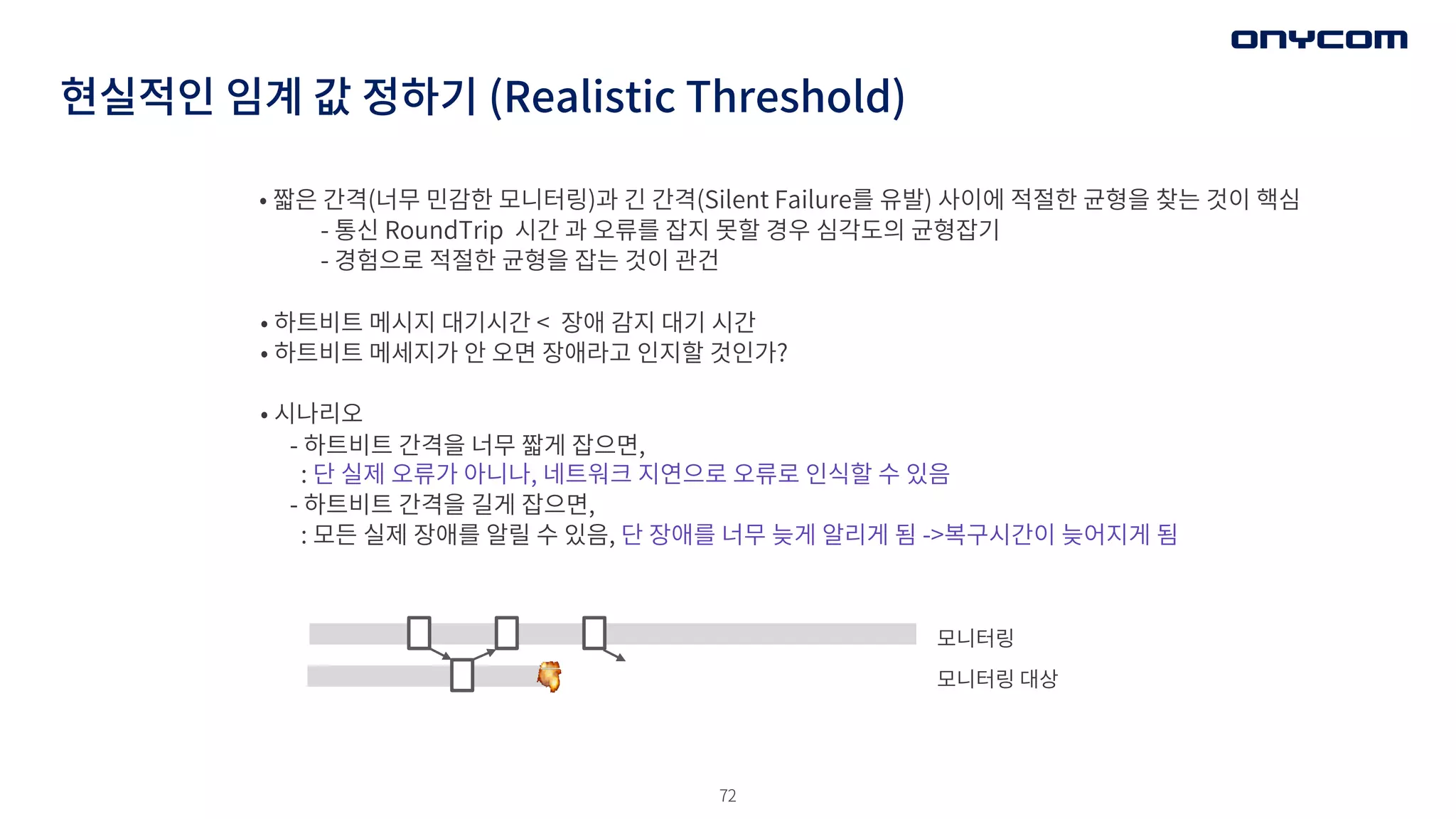
현실적인 임계 값정하기 (Realistic Threshold)
• 짧은 간격(너무 민감한 모니터링)과 긴 간격(Silent Failure를 유발) 사이에 적절한 균형을 찾는 것이 핵심
- 통신 RoundTrip 시간 과 오류를 잡지 못할 경우 심각도의 균형잡기
- 경험으로 적절한 균형을 잡는 것이 관건
• 하트비트 메시지 대기시간 < 장애 감지 대기 시간
• 하트비트 메세지가 안 오면 장애라고 인지할 것인가?
• 시나리오
- 하트비트 간격을 너무 짧게 잡으면,
: 단 실제 오류가 아니나, 네트워크 지연으로 오류로 인식할 수 있음
- 하트비트 간격을 길게 잡으면,
: 모든 실제 장애를 알릴 수 있음, 단 장애를 너무 늦게 알리게 됨 ->복구시간이 늦어지게 됨
모니터링
모니터링 대상
73.
73
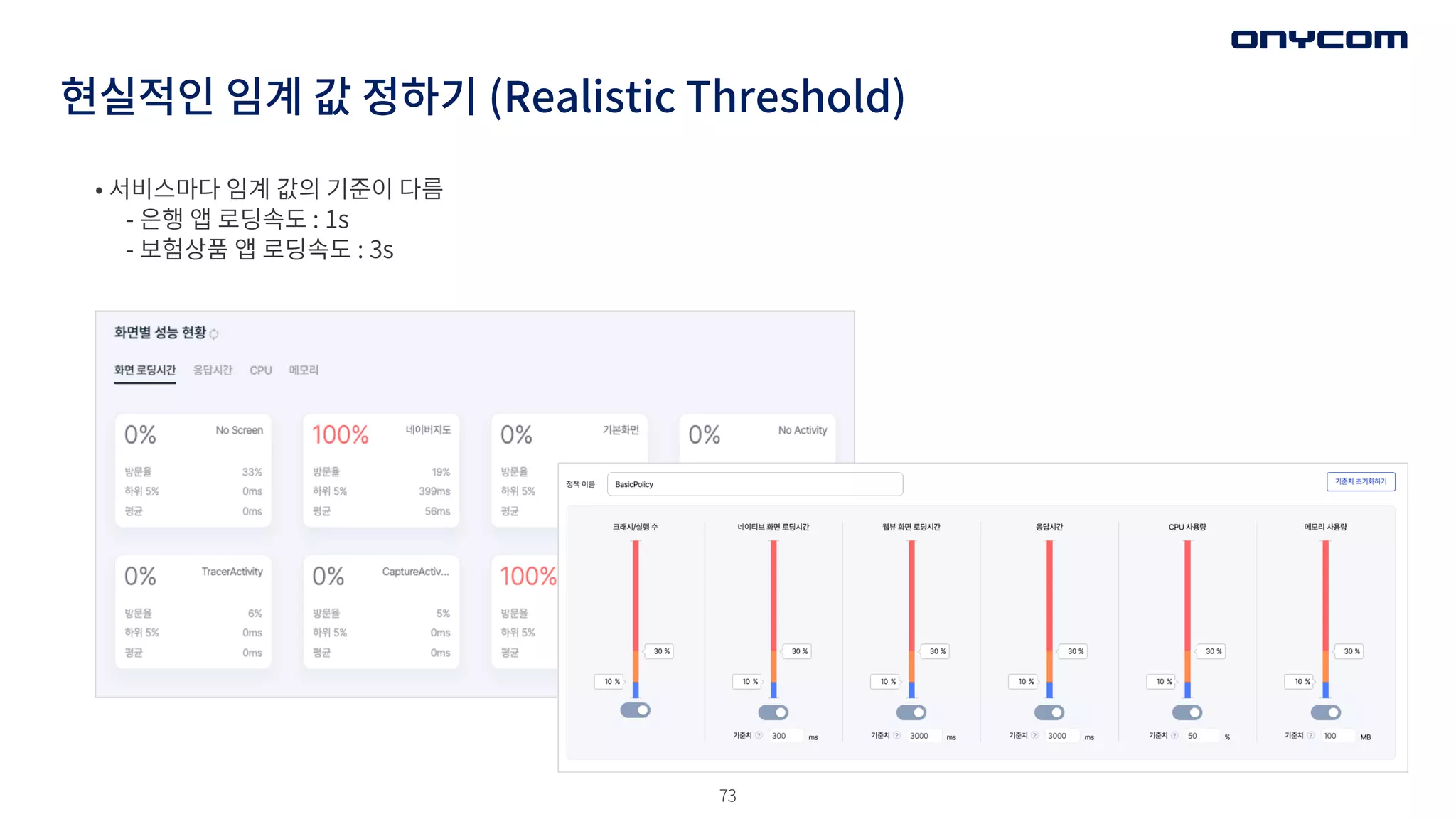
현실적인 임계 값정하기 (Realistic Threshold)
• 서비스마다 임계 값의 기준이 다름
- 은행 앱 로딩속도 : 1s
- 보험상품 앱 로딩속도 : 3s
74.
74
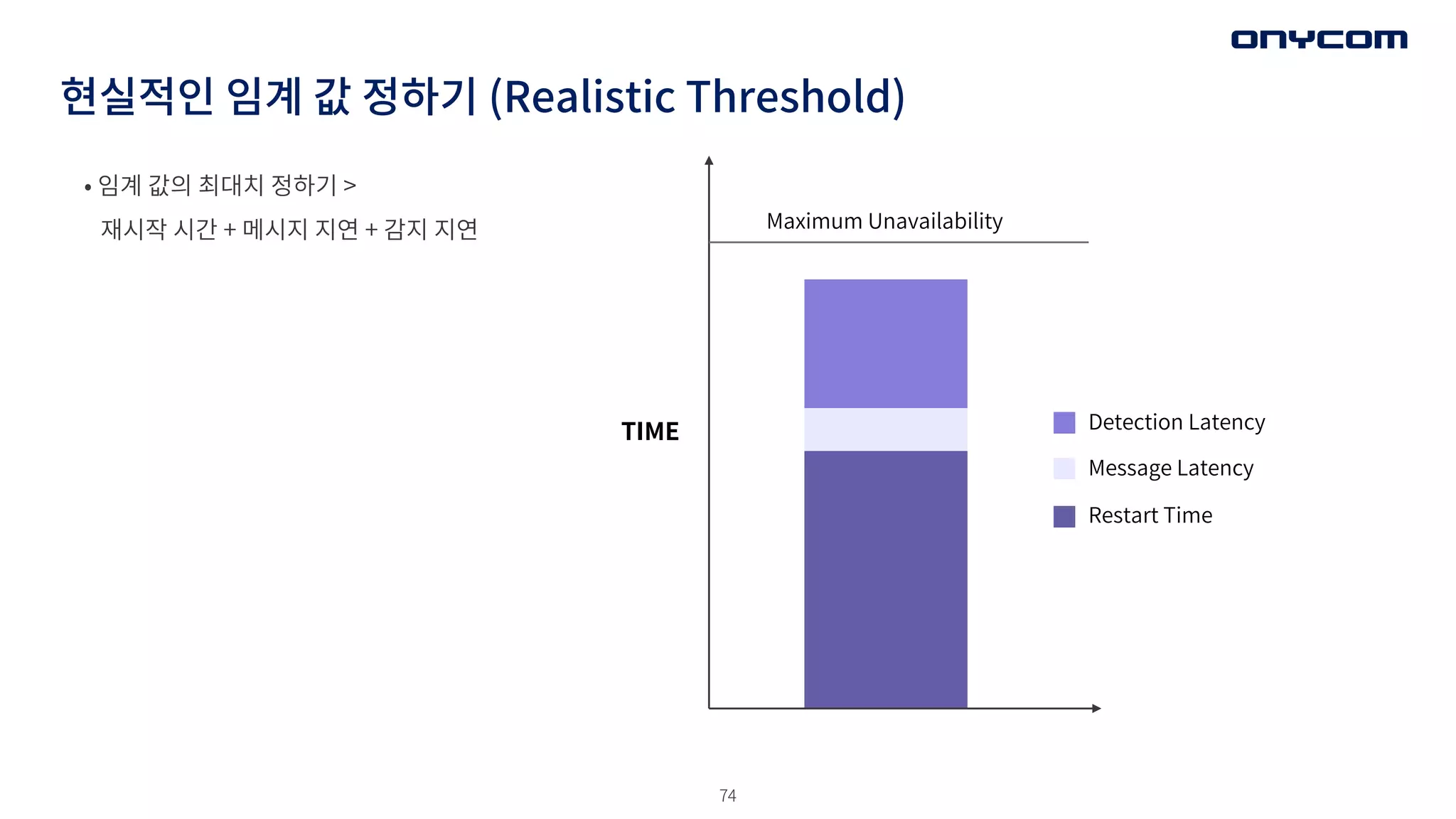
현실적인 임계 값정하기 (Realistic Threshold)
• 임계 값의 최대치 정하기 >
재시작 시간 + 메시지 지연 + 감지 지연 Maximum Unavailability
TIME Detection Latency
Message Latency
Restart Time
75.
75
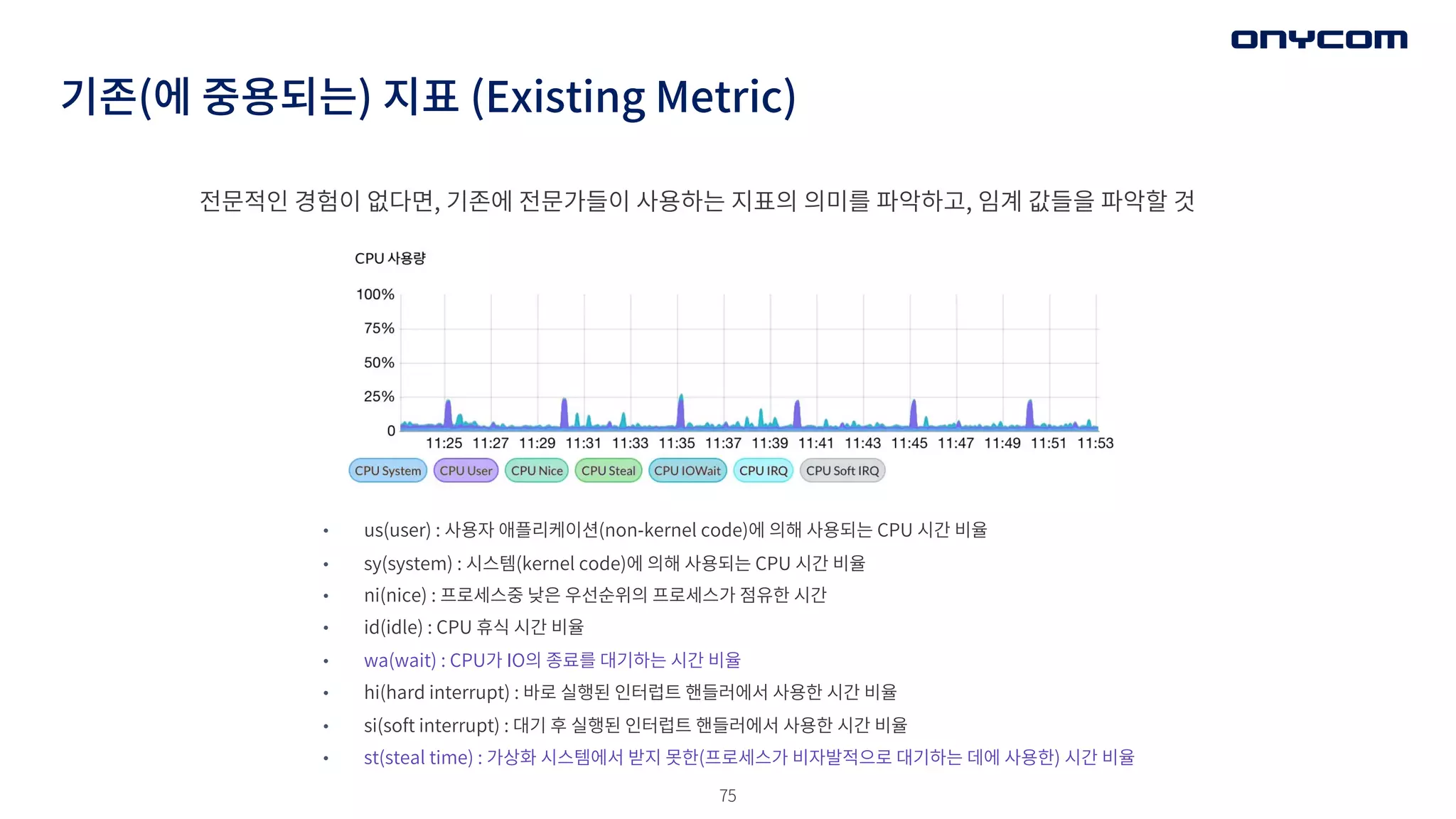
기존(에 중용되는) 지표(Existing Metric)
전문적인 경험이 없다면, 기존에 전문가들이 사용하는 지표의 의미를 파악하고, 임계 값들을 파악할 것
• us(user) : 사용자 애플리케이션(non-kernel code)에 의해 사용되는 CPU 시간 비율
• sy(system) : 시스템(kernel code)에 의해 사용되는 CPU 시간 비율
• ni(nice) : 프로세스중 낮은 우선순위의 프로세스가 점유한 시간
• id(idle) : CPU 휴식 시간 비율
• wa(wait) : CPU가 IO의 종료를 대기하는 시간 비율
• hi(hard interrupt) : 바로 실행된 인터럽트 핸들러에서 사용한 시간 비율
• si(soft interrupt) : 대기 후 실행된 인터럽트 핸들러에서 사용한 시간 비율
• st(steal time) : 가상화 시스템에서 받지 못한(프로세스가 비자발적으로 대기하는 데에 사용한) 시간 비율
76.
76
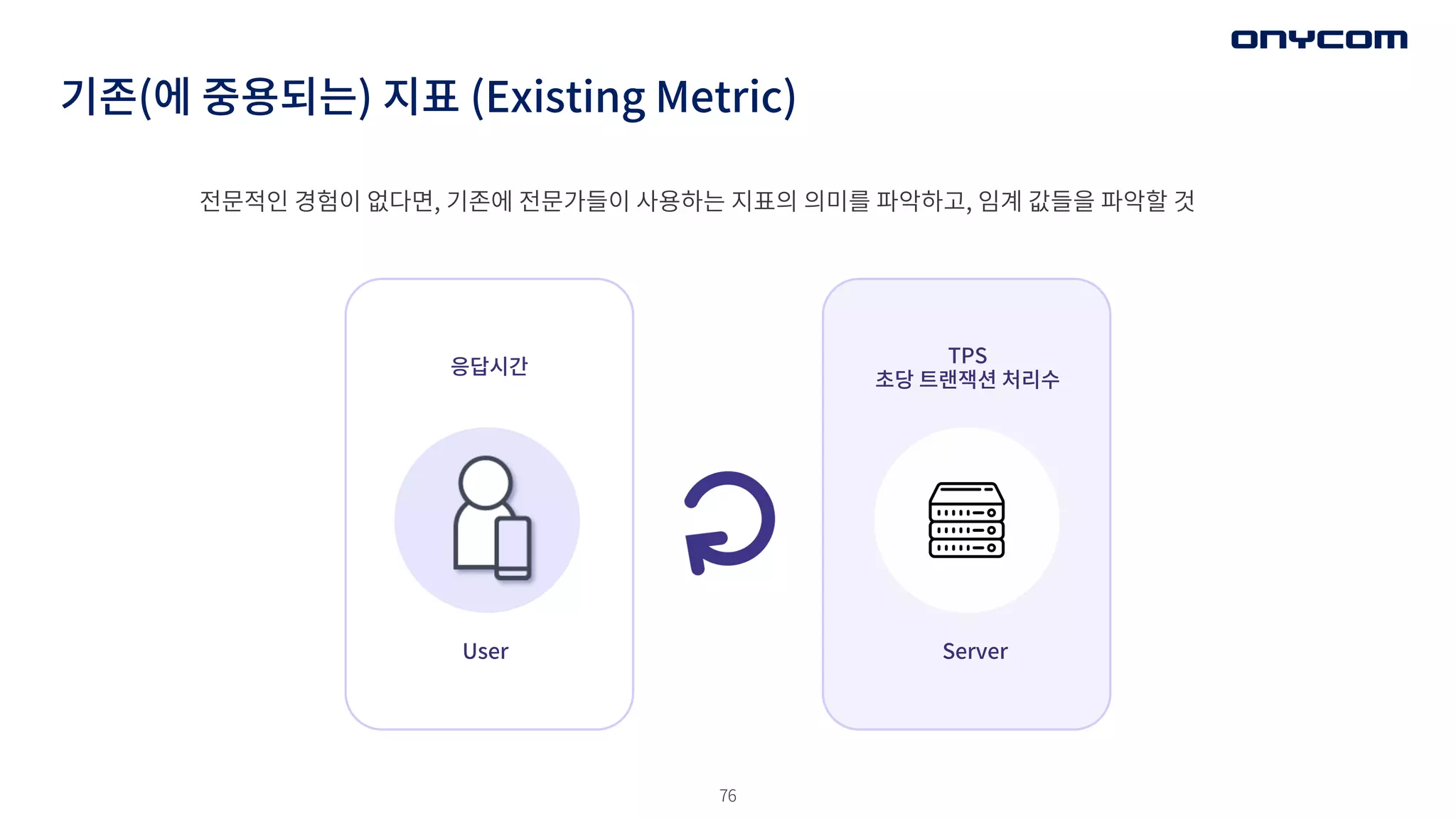
기존(에 중용되는) 지표(Existing Metric)
전문적인 경험이 없다면, 기존에 전문가들이 사용하는 지표의 의미를 파악하고, 임계 값들을 파악할 것
User
응답시간
TPS
초당 트랜잭션 처리수
Server
77.
77
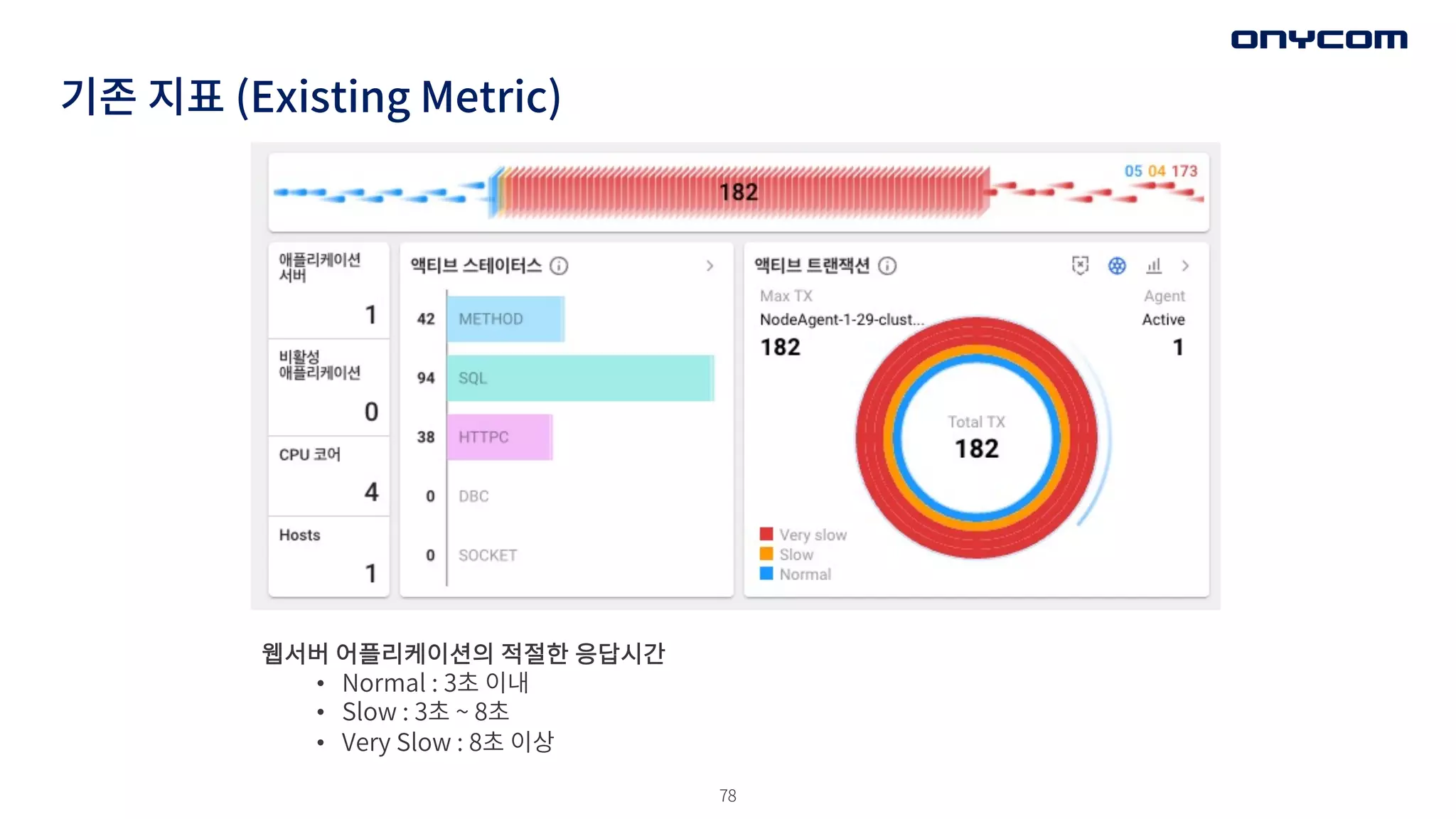
기존 지표 (ExistingMetric)
FP(First Paint)
흰 화면에서 화면에 무언가가
처음으로 그려지기 시작하는 순간
FCP(First Contentful Paint)
텍스트나 이미지가 출력되기 시작하는 순간
FMP(First Meaningful Paint)
- 사용자에게 의미 있는 콘텐츠가 그려지기 시작하는 첫 순간
- 콘텐츠를 노출하는데 필요한 CSS, 자바스크립트 로드가
시작되고 스타일이 적용되어 주요 콘텐츠를 읽을 수 있다.
TTI(Time to Interactive)
자바스크립트의 초기 실행이 완료되어서 사용자가 직접
행동을 취할 수 있는 순간
First Paint First Contentful
Paint (FCP)
First Meaningfu
Paint (FMP)
Time to
Interactive (TTI)
78.
78
기존 지표 (ExistingMetric)
웹서버 어플리케이션의 적절한 응답시간
• Normal : 3초 이내
• Slow : 3초 ~ 8초
• Very Slow : 8초 이상
79.
79
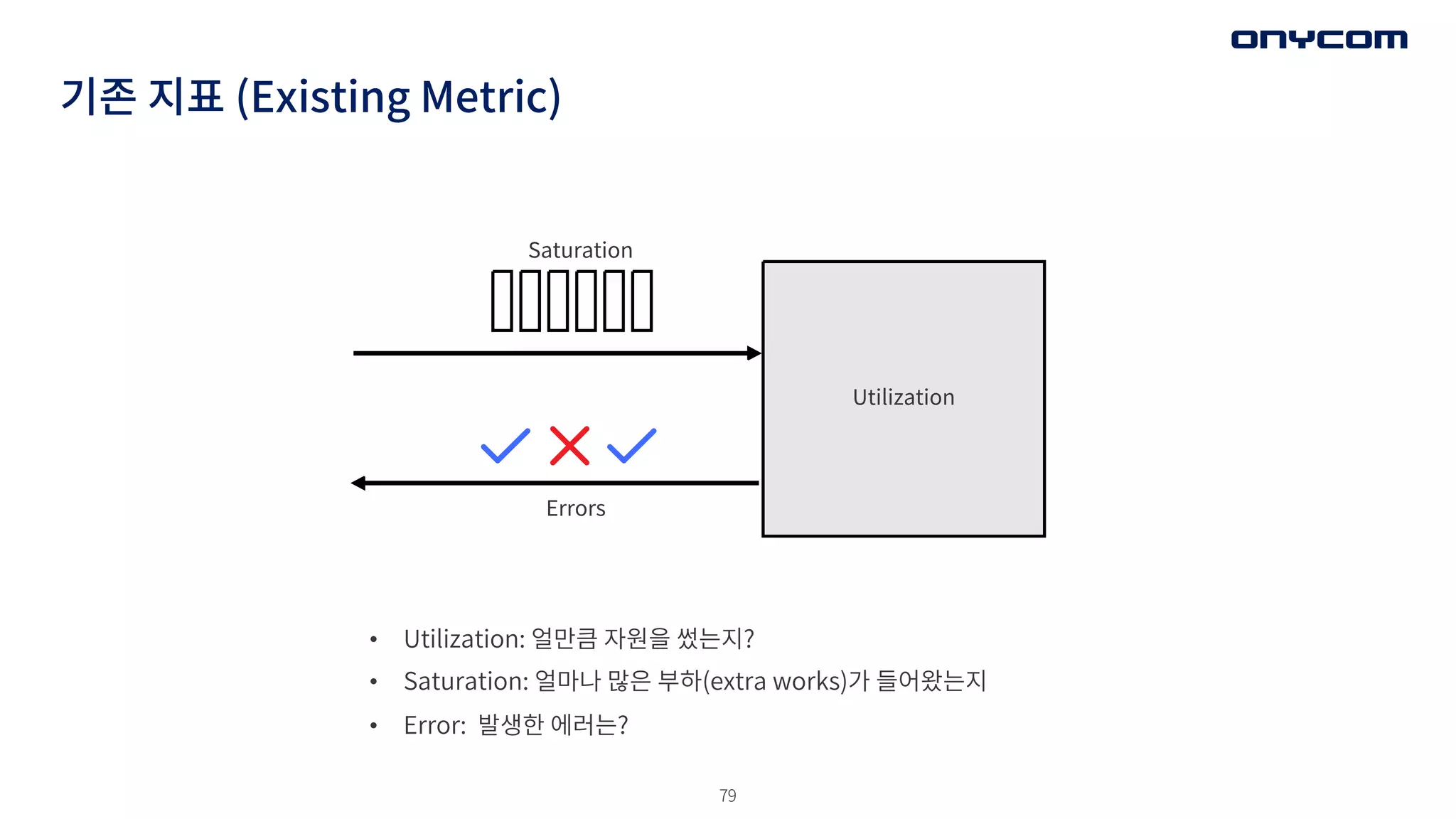
기존 지표 (ExistingMetric)
• Utilization: 얼만큼 자원을 썼는지?
• Saturation: 얼마나 많은 부하(extra works)가 들어왔는지
• Error: 발생한 에러는?
Utilization
Saturation
Errors
81
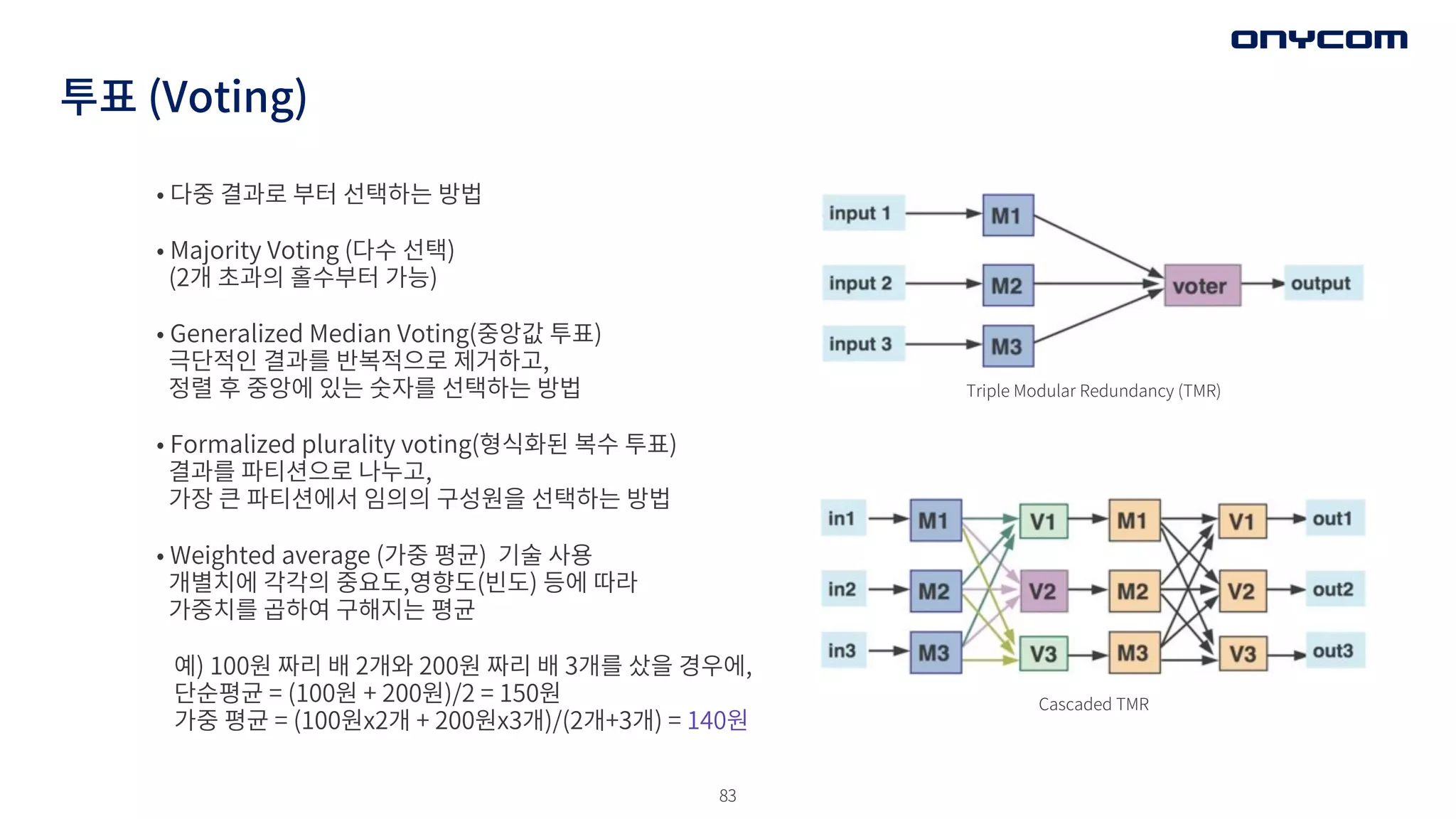
투표 (Voting)
• 중복을이용한 다양한 투표 전략을 고민해라.
- Cassandra / Consist Hashing 전략
- plurality voting (다수 투표 전략)
• 정확한 투표 (Exact Voting)
- 모든 값이 같아 결과를 반환하거나, 불확실한 상태라고 반환함
82.
82
투표 (Voting)
• 부정확한투표 (Inexact Voting) : 비교하여, 다수의 올바른 결과를 이끌어 낼 수 있다.
- 선택적 투표(Adaptive Voting) : 과거의 경험을 기반으로 랭킹을 도출함
예: 다른 결과들에 가중치를 도입하여 도출
R=W1*R1 + W2*R2 + W3*R3 with W1+W2+W3=1 (머신러닝??)
- 비선택적 투표(Non Adaptive Voting) : 허용 가능한 결과의 범위를 설정
(GPS 3개로 위치 보정하기)
Discrepancy (허용할 수 있는 오차 범위)를 기반으로 선택하는 방법
허용 오차 범위는 D = 0.9
세 개의 머신/모듈 에서 R1 = 117.0, R2 = 116.5, R3 = 115.8로 결과 반환
R12, R23, R31의 값의 절대값 차이 (0.5, 0.7, 1.2)
- 전략 1 : min (R12,R23,R31) < D -> min (0.5, 0.7, 1.2) < 0.9 -> 0.5 < 0.9 (만족함)
- 전략 2 : max(R12,R23,R31) < D -> max (0.5.0.7, 1.2) < 0.9 -> 1.2 < 0.9 (불만족 -> 다시 계산)
만족하면 세계의 값 중 평균, 중앙값, 최빈값 (mean, median, mode) 으로 할지는 알아서…
83.
83
투표 (Voting)
• 다중결과로 부터 선택하는 방법
• Majority Voting (다수 선택)
(2개 초과의 홀수부터 가능)
• Generalized Median Voting(중앙값 투표)
극단적인 결과를 반복적으로 제거하고,
정렬 후 중앙에 있는 숫자를 선택하는 방법
• Formalized plurality voting(형식화된 복수 투표)
결과를 파티션으로 나누고,
가장 큰 파티션에서 임의의 구성원을 선택하는 방법
• Weighted average (가중 평균) 기술 사용
개별치에 각각의 중요도,영향도(빈도) 등에 따라
가중치를 곱하여 구해지는 평균
예) 100원 짜리 배 2개와 200원 짜리 배 3개를 샀을 경우에,
단순평균 = (100원 + 200원)/2 = 150원
가중 평균 = (100원x2개 + 200원x3개)/(2개+3개) = 140원
Triple Modular Redundancy (TMR)
Cascaded TMR
84.
84
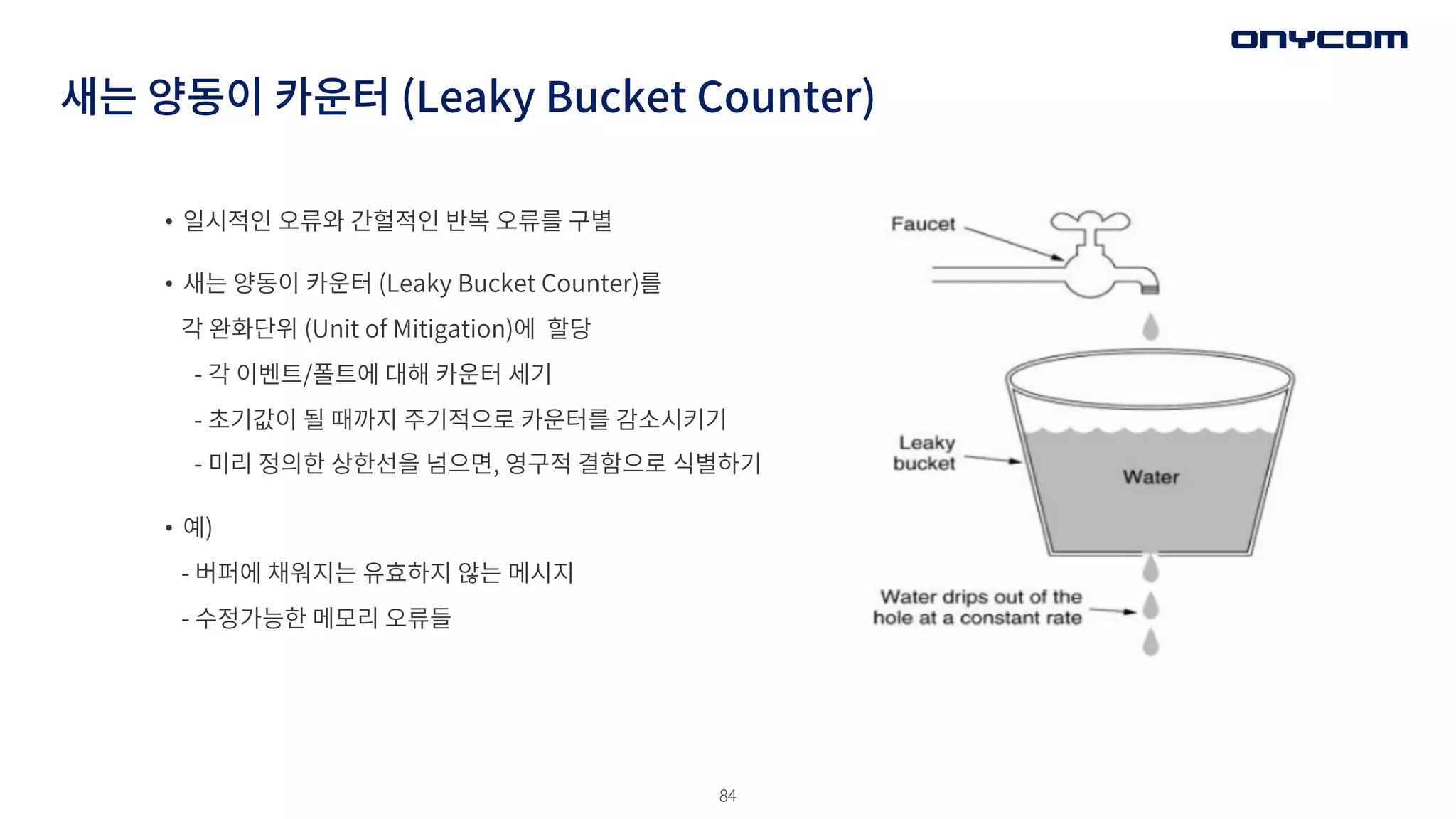
새는 양동이 카운터(Leaky Bucket Counter)
• 일시적인 오류와 간헐적인 반복 오류를 구별
• 새는 양동이 카운터 (Leaky Bucket Counter)를
각 완화단위 (Unit of Mitigation)에 할당
- 각 이벤트/폴트에 대해 카운터 세기
- 초기값이 될 때까지 주기적으로 카운터를 감소시키기
- 미리 정의한 상한선을 넘으면, 영구적 결함으로 식별하기
• 예)
- 버퍼에 채워지는 유효하지 않는 메시지
- 수정가능한 메모리 오류들
88
집중 회복 (ConcentratedRecovery)
• 비가용성(Unavailability)를 최소화하기 위해, 모든 자원을 복구에만 집중해서 쓸것
• 빠른 복구 활동을 하기 위해, 격리 시킨 후 복구에만 높은 자원을 할당
• 도착하는 작업을 연기 시키거나, 버퍼링을 할 것
Fresh Work before Stale/ Queue for Resource 패턴과 연관되어 있음
• 복구를 하는 동안, Fault Observer(장애 감시자)에게는 죽은 것으로 보임
- Fault Observer에게 복구 행위 등을 알리고, 개별 완화 유닛은 활동
• 높은 생존성을 요구하는 시스템 (통신사)에서 잘 확립되어 있음
- 이동형 기지국 차량 보내기
- 휴대폰 사이즈의 휴대용 기지국 (저전력 무선통신 기술)
- 중복된 여러 개의 망 쓰기
89.
89
되돌아가기 (RollBack)
• 에러복구 / 에러 핸들링을 한 이후에. 어떻게 이어서 Task를 처리할까?
• 전략 1: 되돌아가기 (RollBack)
- 마지막 요청 중 체크포인트의 시점을 보고, 롤백 포인트를 결정함
- 트랜잭션이 중요한다면, 입출금 같은 강한 동기화라면, 무조건 롤백을 사용해야 함
- 반복되는 작업을 할 경우 발생하는 사이드 이펙트를 고려
- 오류가 다시 발생할 수 있으므로, 재시도 횟수를 제한(Limit Retries)해라.
90.
90
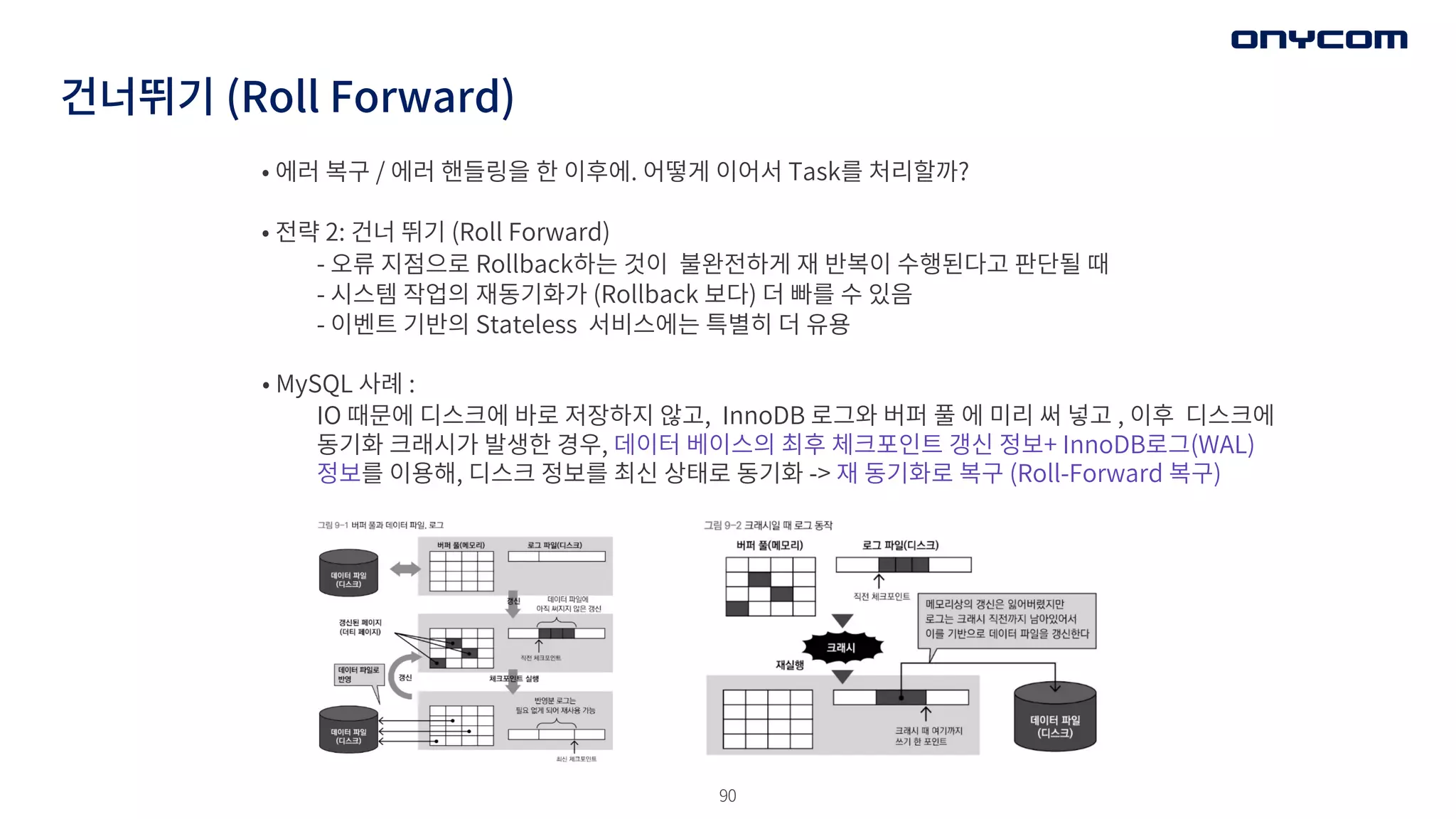
건너뛰기 (Roll Forward)
•에러 복구 / 에러 핸들링을 한 이후에. 어떻게 이어서 Task를 처리할까?
• 전략 2: 건너 뛰기 (Roll Forward)
- 오류 지점으로 Rollback하는 것이 불완전하게 재 반복이 수행된다고 판단될 때
- 시스템 작업의 재동기화가 (Rollback 보다) 더 빠를 수 있음
- 이벤트 기반의 Stateless 서비스에는 특별히 더 유용
• MySQL 사례 :
IO 때문에 디스크에 바로 저장하지 않고, InnoDB 로그와 버퍼 풀 에 미리 써 넣고 , 이후 디스크에
동기화 크래시가 발생한 경우, 데이터 베이스의 최후 체크포인트 갱신 정보+ InnoDB로그(WAL)
정보를 이용해, 디스크 정보를 최신 상태로 동기화 -> 재 동기화로 복구 (Roll-Forward 복구)
91.
91
재시작 (Restart)
• 복구/ 에스컬레이션 (단계별 올리기)가 불가능 할때, 실행을 재개하는 방법
• 재시작은 중복된 유닛에, 장애조치(FailOver) 기법으로 자주 사용됨
• 체크포인트(CheckPoint)를 기반으로 함
• 특히, 일시적인 오류에 자주 사용됨
• Cold/Warm 재시작
- Cold Restart (Hardware Restart)
: 모든 것을 다 초기화 함
: 파일시스템이 적절한지 체크하는 것처럼, 초기 추가 검사 필요
- Warm Restart (Software Restart )
: 시스템을 초기값으로 복원 가능
: 특정 긴 단계를 건너뛸 수 있음 (ex. 파일 시스템 검사를 건너뜀)
93
재시도 제한 (LimitRetries)
• 많은 결함은 결정적(deterministic)이다.
• 잠재적 결함 -> 동일한 자극 -> 오류가 재 반복 (재 활성화)
오류가 활성화되는 원인이 남아 있는 경우, Rollback은 해결책이 안됨
• 예) 잘못된 체크 포인트, 강제로 종료 시키는 킬러 메세지가 남아있을 경우
• 문제 : 내부적으로 오류를 재 전파 시, 재시도를 제한해서 중지시켜야 함
• 해결책 :
- 건너뛰기 (Roll Forward) 패턴,
- 세이프가드(Safeguard) ‒ 별도의 보호받는 자원 (별도의 전원, 백업시스템)
: 저궤도 위성의 세이프가드 메모리 운영 전략
https://koreascience.kr/article/CFKO201221868476227.page
94.
94
• 시스템은 오류로부터 복구하기 원하나, 어디서부터 다시 시작해야할지 모를때.
• 복구 하고 싶으나 적절한 CheckPoint가 없을 때
• 재시작(Restart) 하고 싶으나 너무나 많은 시간이 걸릴 때
• 체크 포인트 (CheckPoint)는 저장 정보가 중간 중간 알아서 저장됨 -> 동적임
• 참조 포인트 (Reference Point)는 정적임 -> 지정된 장소 / 설계 시 미리 고려
- 게임에서 스테이지 1을 넘기면, 그 다음은 무조건 스테이지 2임
- 게임에서 특정 유닛에 달려가야만 저장이 됨
• 극단적인 케이스
- 체크 포인트: 보스와 싸우다가 죽었는데, 롤백하니 에너지가 충전안된 상황에서 다시 보스 앞이라면..
- 참조 포인트는 보스가 싸우다가 죽으면, 안전한 저장 장소(사원 등)에서 다시 시작
재정비의 시간을 가질 수 있음 -> 무기 교환 / 에너지 채우기 등
기준점으로 돌아가기 (Return to Reference Point)
95.
95
• 전역 ,상태 정보를 저장하여 복구 중 결과의 손실 방지
- 아카이빙(저장)하기 어려운, 장기간 데이터에 집중
- 체크포인트 데이터 일관성 과 간격이 밀접한 연관성을 가짐
- 서비스의 실패율에 따라 저장 간격을 결정해라.
: 자주 실패하면, 촘촘하게 저장을, 복구가 빨라 짐 (단 저장 부하가 큼)
: 실패율이 낮다면, 자주 저장하는 것이 오히려 부하임
- 저장의 부하를 줄이는 방법 -> 초기 상태 + 변화량만 계속 누적하기
• "스냅샷" 문제 ‒ 분산(전역)된 환경에서 일관성을 달성하는 방법은 무엇입니까?
- 트랜잭션으로 엄격하게 일관성을 유지할 것인가? CA (배틀 그라운드, 포트나이트)
- 일관성은 유지하되, 조금 느슨하게 동기화해도 될 건가? CP (포켓몬 레이더배틀)
체크포인트 (Check Point)
97
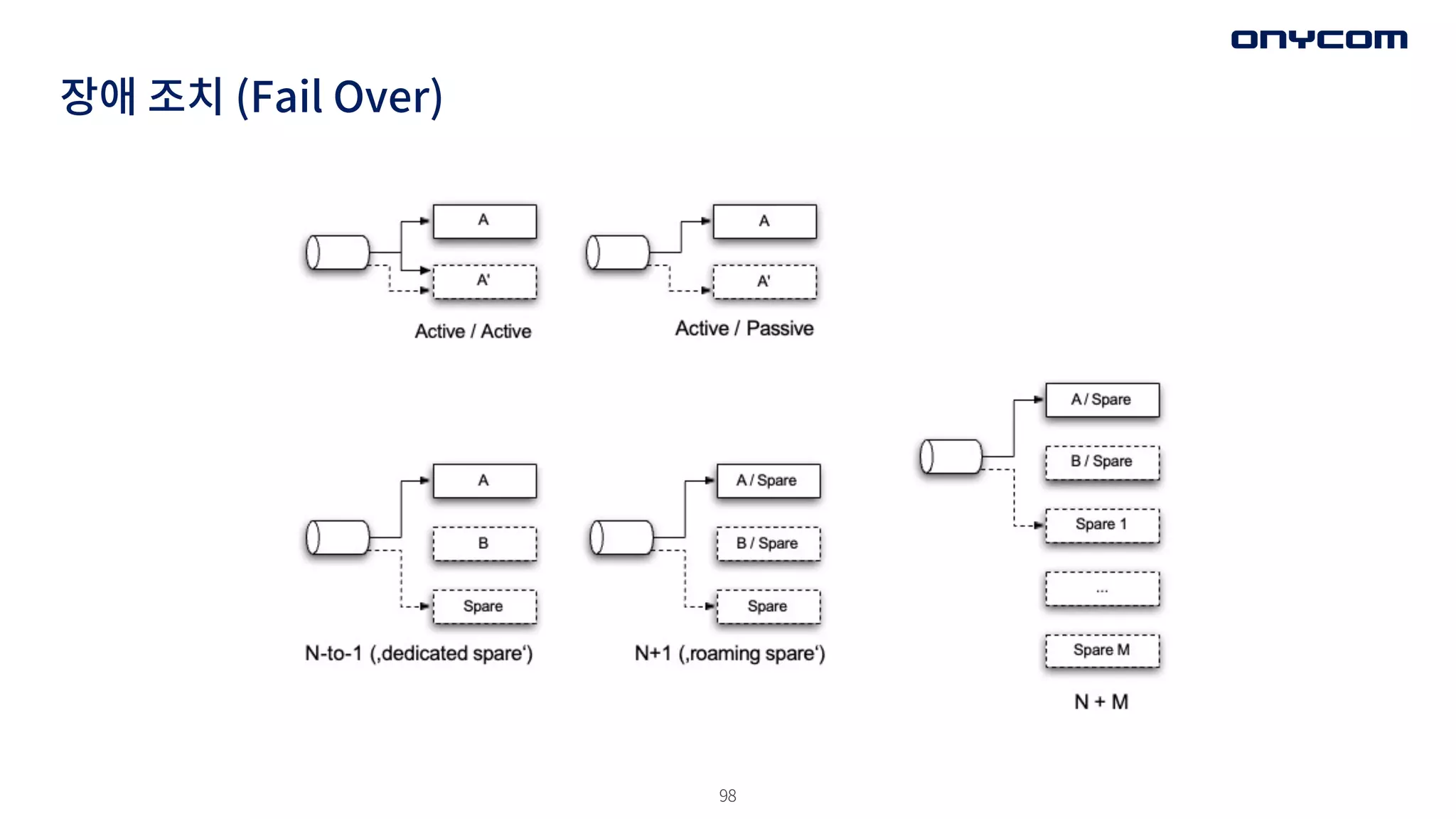
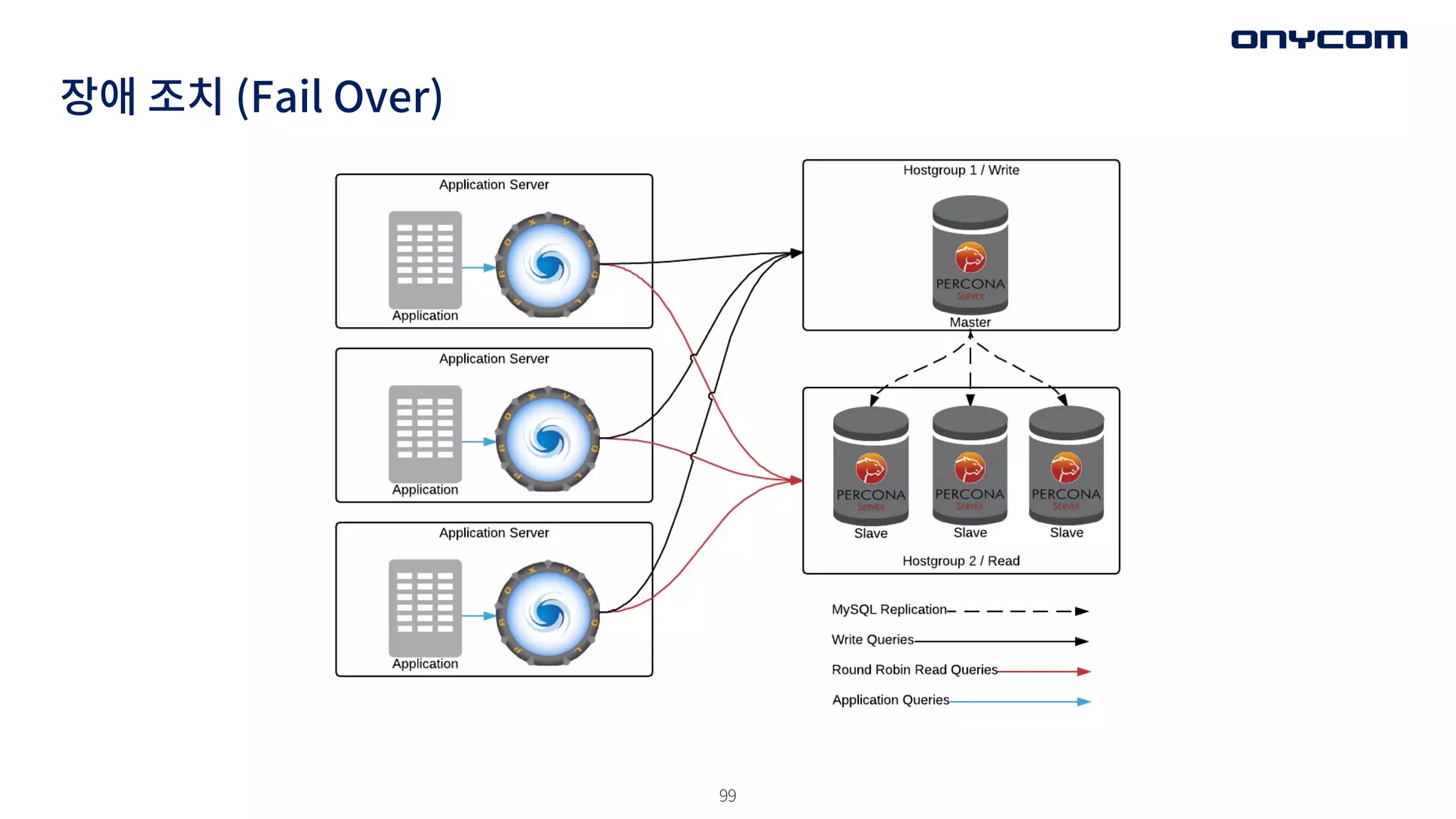
장애 조치 (FailOver)
• 중복된 요소들로 구성된 유닛 중, Active (활성) 요소가 결함을 가지고 있다.
• 어떻게 오류에 자유롭게, 실행을 계속할 것인가?
• 전략)
• 복제를 기반으로 한, 중복된 자원으로 교체함
• 중요한 요소 - 장애 조치 시간 최소/ 빠른 데이터 접근임 (빠른 교체, 데이터 복사)
• 결함이 있는 시스템에 적절한 검역 (격리하여 검사)이 필요함
• 생각거리들
• 두 개의 중복 요소들을 Active-Active로 돌렸을 때 하나가 죽으면?
• 데이터 베이스 같은 경우의 장애 조치 전략은?
100
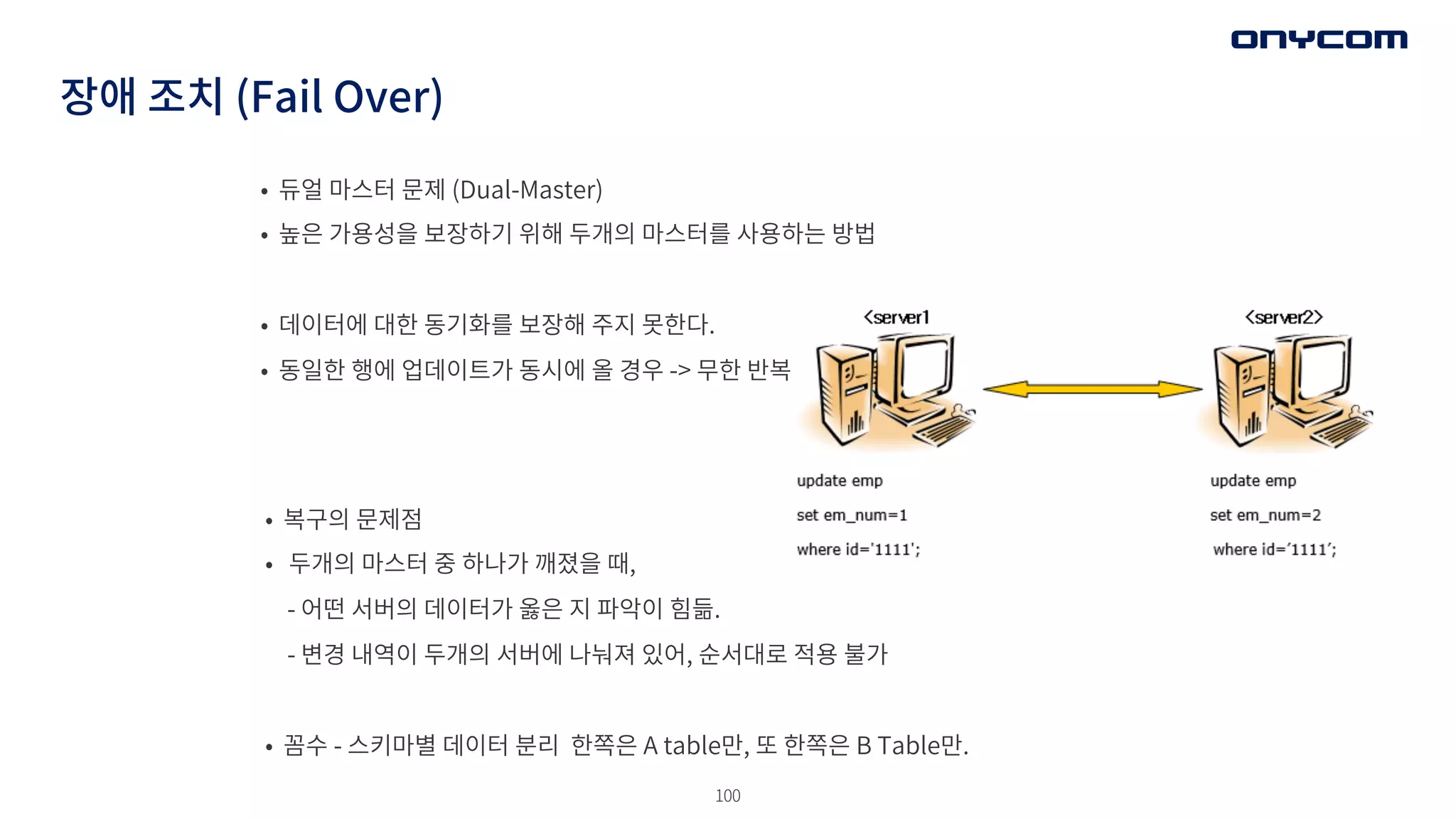
장애 조치 (FailOver)
• 복구의 문제점
• 두개의 마스터 중 하나가 깨졌을 때,
- 어떤 서버의 데이터가 옳은 지 파악이 힘듦.
- 변경 내역이 두개의 서버에 나눠져 있어, 순서대로 적용 불가
• 꼼수 - 스키마별 데이터 분리 한쪽은 A table만, 또 한쪽은 B Table만.
• 듀얼 마스터 문제 (Dual-Master)
• 높은 가용성을 보장하기 위해 두개의 마스터를 사용하는 방법
• 데이터에 대한 동기화를 보장해 주지 못한다.
• 동일한 행에 업데이트가 동시에 올 경우 -> 무한 반복
101.
101
장애 조치 ‒정족수 (Quorum)
• 중앙 중재(Central arbitration)
수동 정족수, 중앙 집중식 서버/관리자 설정 마스터
몽고 DB -> 아비터 (arbiter)
• 단순 다수(Simple majority)
그룹을 형성한 노드의 절반 이상의 의견을 따르는 방법
Cassandra의 데이터 읽기 (정합성 체크일때)
• Tie-breaker (동률 깨뜨리기)
Ping이 빠른 녀석으로 선택하기 등.. 다양한 옵션 있음
Voting 패턴에서 언급한 내용을 참고하세요.
104
오류(부하) 완화 패턴
•과부하 도구상자 (Overload Toolbox)
• 지연가능한 작업 (Deferrable Work)
• 과부화 결정 평가
(Reassess Overload Decision)
• 공정한 자원 할당
(Equitable Resource Allocation)
• 자원 대기열
(Queue for Resource)
• 확장 기반의 자동 제어
(Expansive Automatic Controls)
• 보호 자동 컨트롤
(Protective Automatic Controls)
• 부하 억제 (Sherd Load)
• 최종 처리 (Final Handling)
• 부하 공유하기 (Share the Load)
• 주변에서 일하기
(Shed Work at Periphery)
• 천천히 하기 (Slow It Down)
• 진행 중인 작업 완료
(Finish Work in Progress)
• 오래되지 않는 신선한 작업
(Fresh Work Before Stale)
• 데이터 표시하기 (Mark Data)
• 오류 수정 코드
(Error Correcting Codes)
105.
105
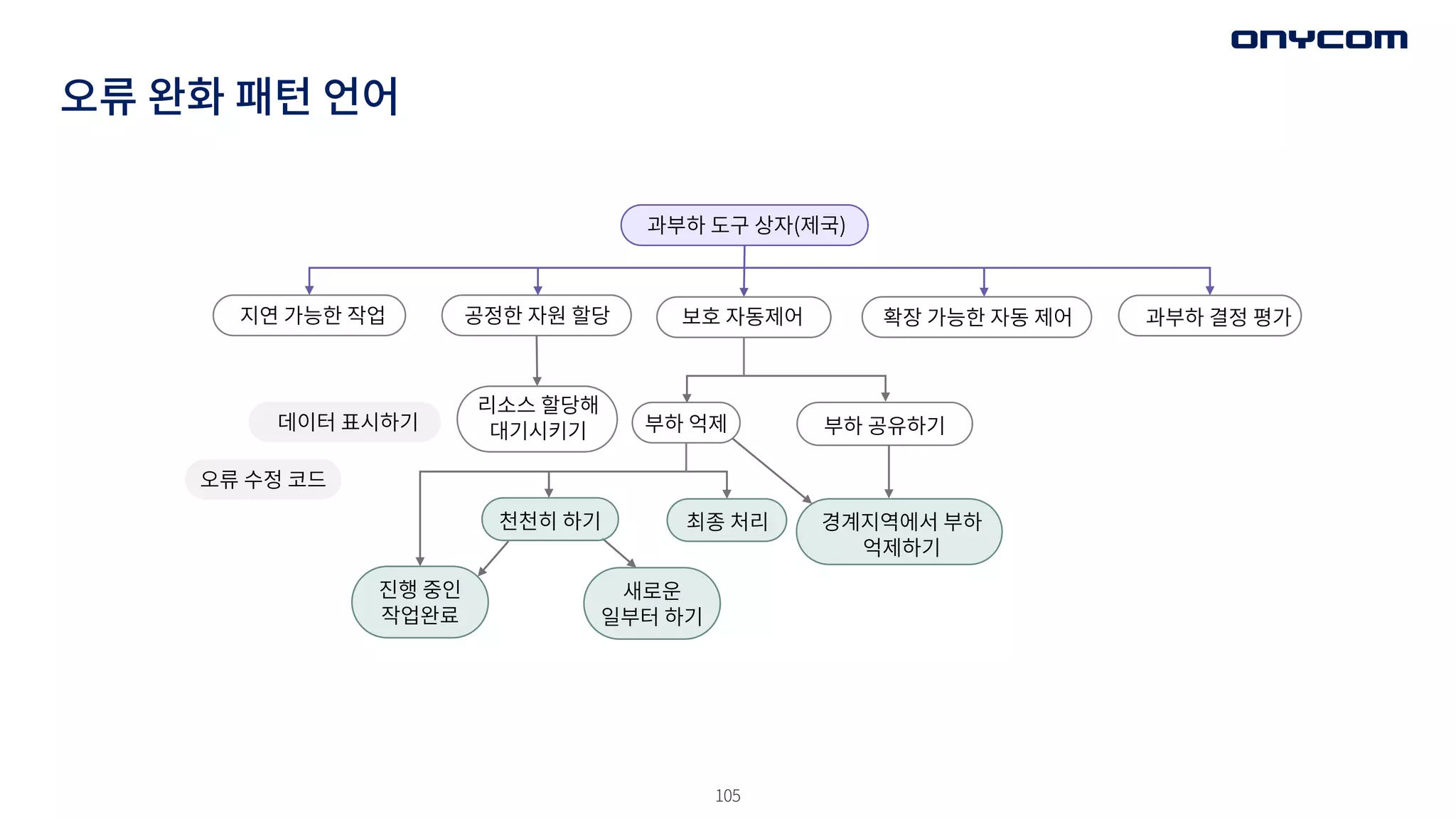
오류 완화 패턴언어
과부하 도구 상자(제국)
보호 자동제어 확장 가능한 자동 제어
리소스 할당해
대기시키기
공정한 자원 할당
지연 가능한 작업 과부하 결정 평가
부하 억제 부하 공유하기
경계지역에서 부하
억제하기
최종 처리
천천히 하기
새로운
일부터 하기
진행 중인
작업완료
데이터 표시하기
오류 수정 코드
106.
106
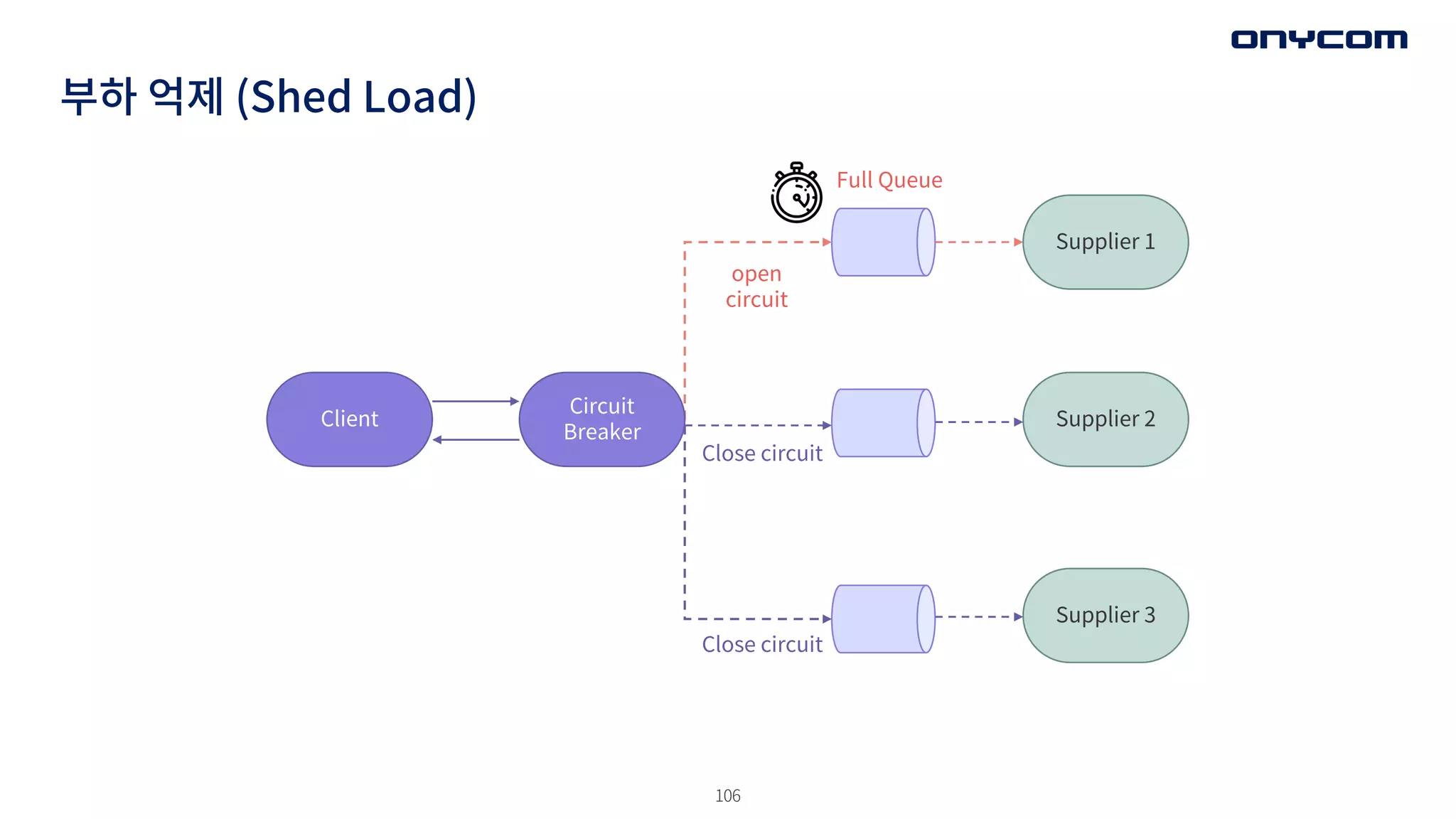
부하 억제 (ShedLoad)
Client Supplier 2
Supplier 1
Supplier 3
Circuit
Breaker
Full Queue
open
circuit
Close circuit
Close circuit
107.
107
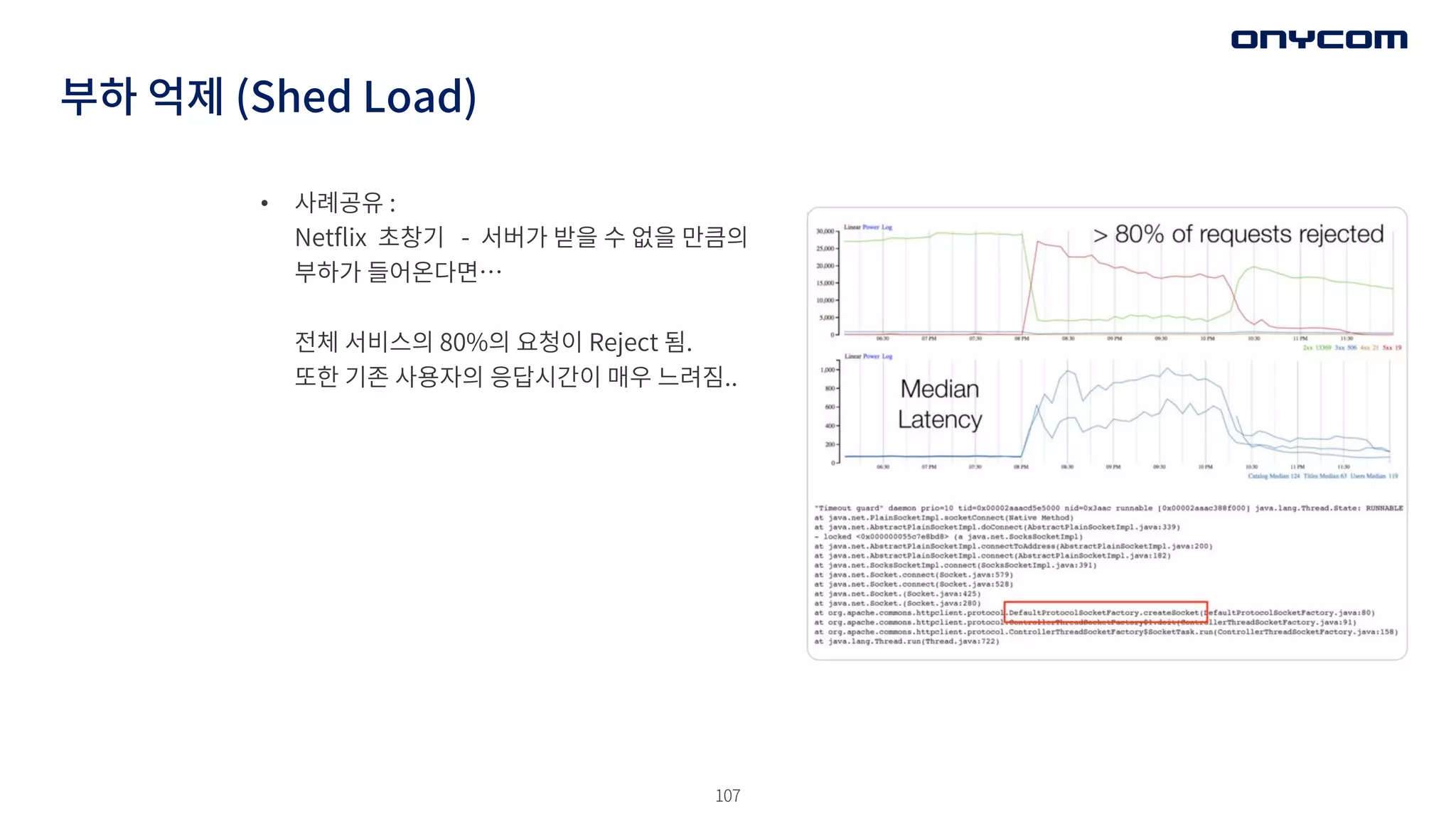
• 사례공유 :
Netflix초창기 - 서버가 받을 수 없을 만큼의
부하가 들어온다면…
전체 서비스의 80%의 요청이 Reject 됨.
또한 기존 사용자의 응답시간이 매우 느려짐..
부하 억제 (Shed Load)
108.
108
부하 억제 (ShedLoad)
• 다수에게 서비스를 제공하기 위해, 소수를 버려라.
• 임계점에서 자원 사용량을 줄이는 방법
• 패턴 (해결책) : 거부해라. (AcK를 보내지 말거나, 40X 보내기)
• 그래서 MSA 패턴중 ‒ Circuit Breaker 도입
Closed Open
Half Open
success
Fail [threshold reached]
Fail
Call/ raise circuit open
Reset timeout
success
Fail [under threshold]
109.
109
부하 억제 (ShedLoad)
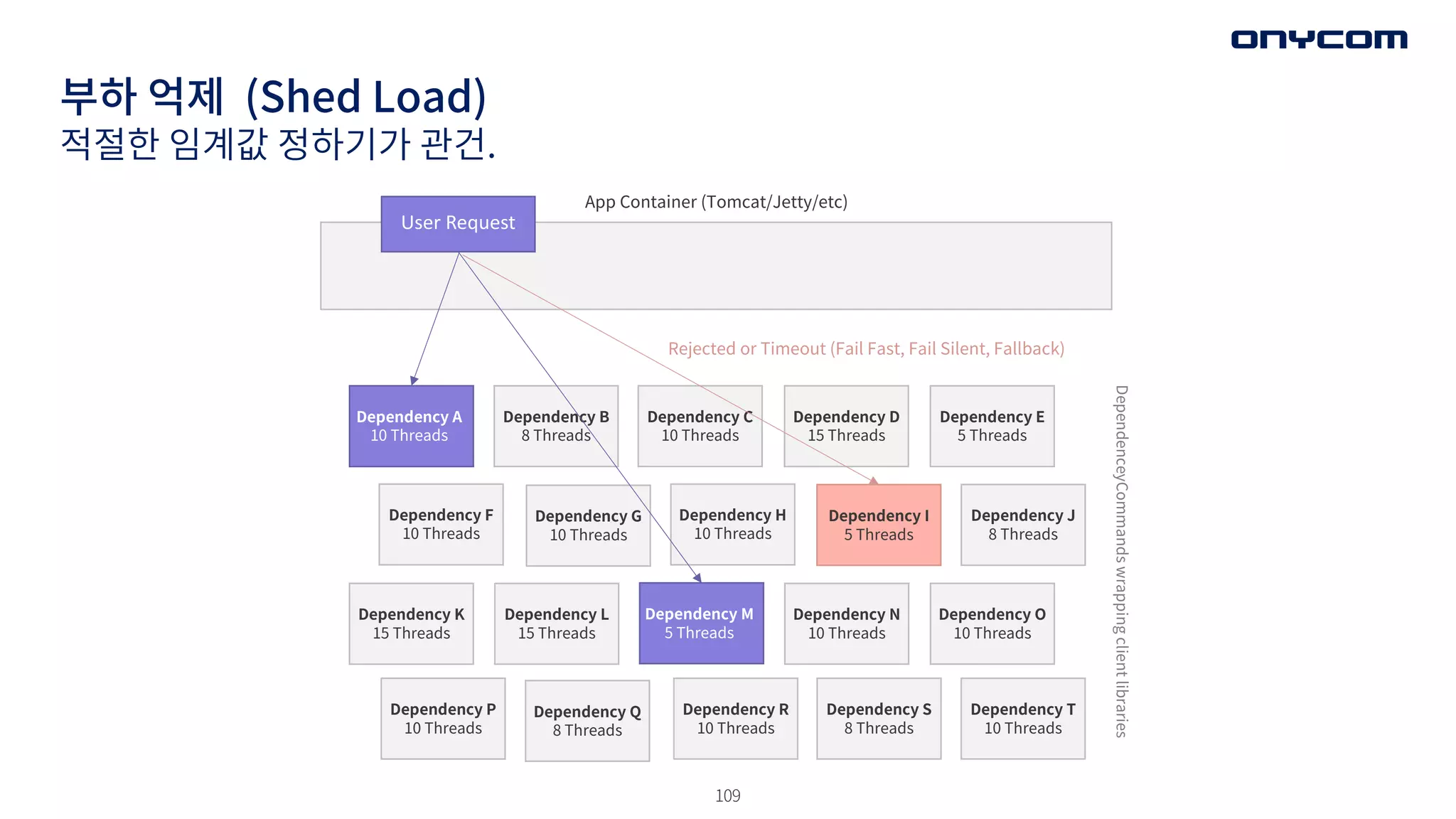
적절한 임계값 정하기가 관건.
User Request
Dependency A
10 Threads
Dependency B
8 Threads
Dependency C
10 Threads
Dependency D
15 Threads
Dependency E
5 Threads
Dependency J
8 Threads
Dependency F
10 Threads
Dependency G
10 Threads
Dependency I
5 Threads
Dependency H
10 Threads
Dependency K
15 Threads
Dependency N
10 Threads
Dependency O
10 Threads
Dependency P
10 Threads
Dependency R
10 Threads
Dependency T
10 Threads
Dependency S
8 Threads
Dependency L
15 Threads
Dependency M
5 Threads
Dependency Q
8 Threads
Rejected or Timeout (Fail Fast, Fail Silent, Fallback)
App Container (Tomcat/Jetty/etc)
DependenceyCommands
wrapping
client
libraries
112
부하 억제 (ShedLoad)
• 적절한 임계점을 찾아라
• 서버가 견딜 수 있을 만큼의 트랜잭션 ?
• 아니면 사용자의 99%가 만족하는 응답시간을 기준으로..
• 순간 Peak를 견디는 임계점 찾기 보다는…
• Aging 테스트처럼, 오랫동안 부하가 가더라도 죽지 않는 것이 진짜 임계점
• 튕겨 나간 사용자가 많아지면, 새로운 서버를 Scale Out하기
• Shed work at periphery (주변으로 부하 나누기..)
• 더 상세한 것은? 별도의 대용량 부하테스트 실습 시간에.. (1일 코스)
113.
113
진행 중인 작업완료 (Finish Work in Progress)
• 무엇을 처리하고 무엇을 거부 해야할까?
- 가장 좋은 경우는 요청에 레이블을 지정하는 것입니다:
예) "New"(새로움) 대 ”Continuation” (지속)
- 지속적으로 자원을 사용하는 프로세스를 구분할 것
- 리소스를 낭비하는 프로세스를 적극적으로 찾아서 제거하기
(Broker 패턴 ‒ Android)
• 부하억제 (Shed Load)의 연장선상에서는..
- 새 요청을 제한하고, 기존의 요청을 처리하는데 집중할 것
- 부작용 발생
: 하지만 계속 이렇게 하다 보면, Slow it Down (천천히 하기) 상황이 발생함
: 아니면 모든 요청을 다 처리하고(cleanup), 새로운 요청을 받게 됨 (자원 낭비 발생)
- 해결책: 새로운 요청은 소량 받으면서, 기존 작업을 완료하는데 집중하기
114.
114
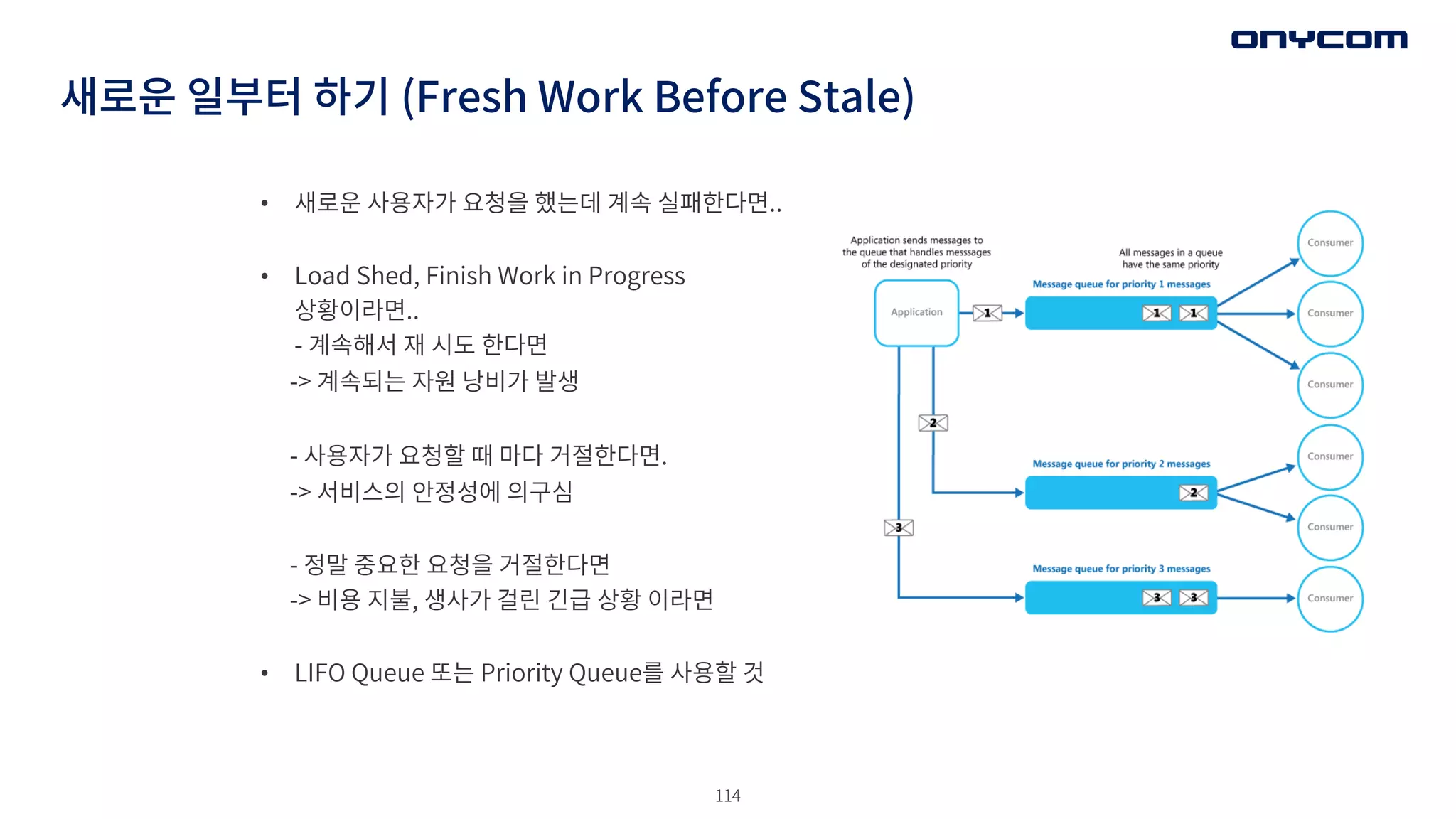
• 새로운 사용자가요청을 했는데 계속 실패한다면..
• Load Shed, Finish Work in Progress
상황이라면..
- 계속해서 재 시도 한다면
-> 계속되는 자원 낭비가 발생
- 사용자가 요청할 때 마다 거절한다면.
-> 서비스의 안정성에 의구심
- 정말 중요한 요청을 거절한다면
-> 비용 지불, 생사가 걸린 긴급 상황 이라면
• LIFO Queue 또는 Priority Queue를 사용할 것
새로운 일부터 하기 (Fresh Work Before Stale)
116
• 처리할 수없는 많은 요청이 들어오면, 어떻게 핸들링 해야 할까요?
• 시스템의 목적은 유용한 작업을 수행하는 것.
너무나 많은 부하에 압도되어 느려지면 안됨.
부하를 비효율적으로 처리해서도 안됨
• 많은 부하를 처리하는 방법
- 무시하고 다 받기 -> 결국 시스템은 작동하지 않게 된다.
- 받는 부하의 양을 점진적으로 감소시킨다.
- 요청이 많아지면 단계(레벨)별로
부하를 낮추는 Escalation 전략을 사용해라.
천천히 하기 (Slow It Down)
117.
117
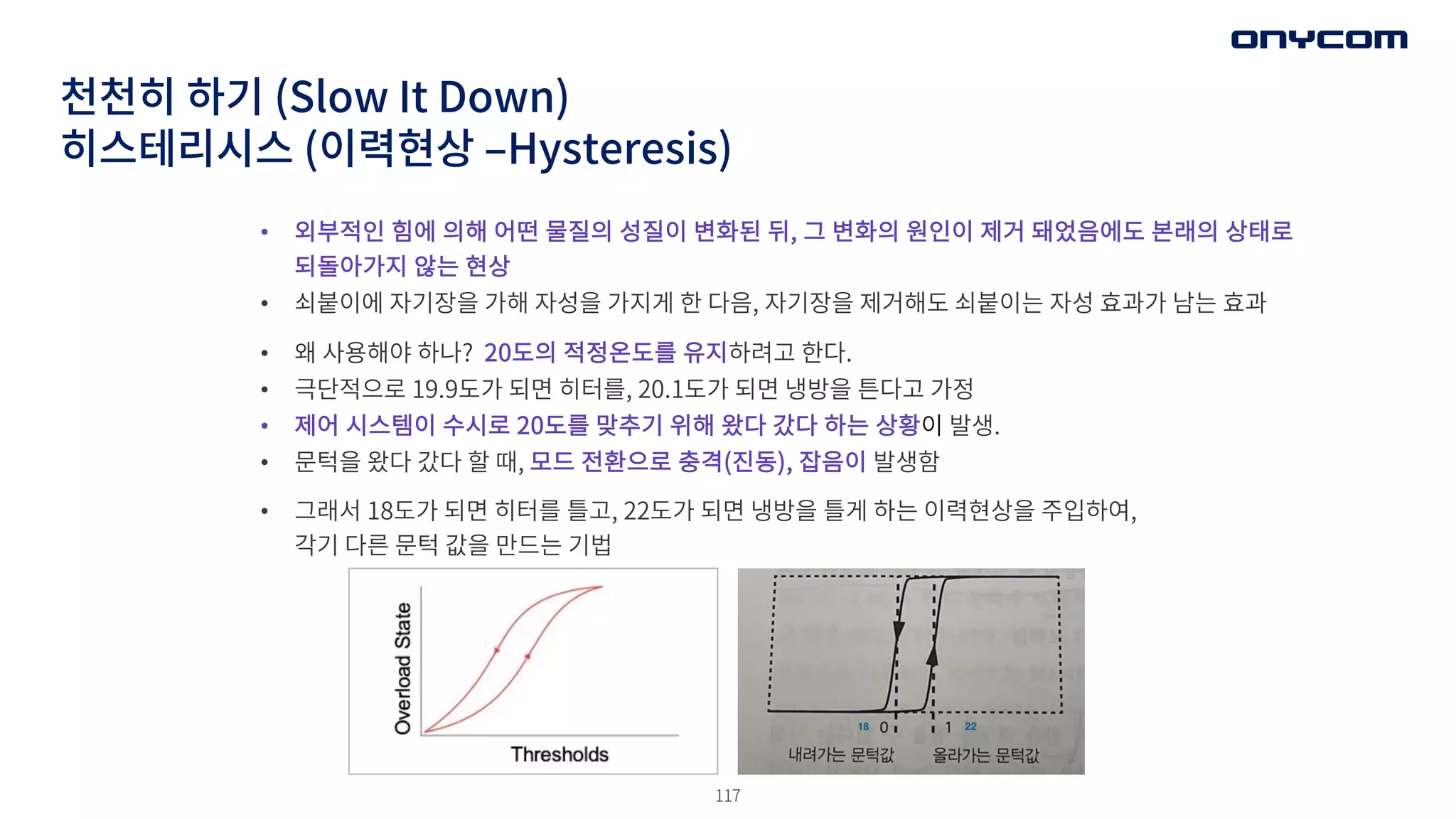
천천히 하기 (SlowIt Down)
히스테리시스 (이력현상 ‒Hysteresis)
• 외부적인 힘에 의해 어떤 물질의 성질이 변화된 뒤, 그 변화의 원인이 제거 돼었음에도 본래의 상태로
되돌아가지 않는 현상
• 쇠붙이에 자기장을 가해 자성을 가지게 한 다음, 자기장을 제거해도 쇠붙이는 자성 효과가 남는 효과
• 왜 사용해야 하나? 20도의 적정온도를 유지하려고 한다.
• 극단적으로 19.9도가 되면 히터를, 20.1도가 되면 냉방을 튼다고 가정
• 제어 시스템이 수시로 20도를 맞추기 위해 왔다 갔다 하는 상황이 발생.
• 문턱을 왔다 갔다 할 때, 모드 전환으로 충격(진동), 잡음이 발생함
• 그래서 18도가 되면 히터를 틀고, 22도가 되면 냉방을 틀게 하는 이력현상을 주입하여,
각기 다른 문턱 값을 만드는 기법
118.
118
• Escalation 전략으로단계별로 특정 임계 값을 설정함.
• 그리고 임계 값에 맞추어, 다른 대응 전략을 하도록 소프트웨어를 구성함.
• 예) 1000명의 사용자 일 때는 1대, 1001명의 사용자 부터는 2대로 서버 확장
• 확장 시 전략 - 서버 한대 추가 , Load Balancer 에 서버 추가 , + ….
• 축소 시 전략 ‒ 필요 데이터 백업, Load Balancer에 제거, 서버 제거 + ….
• 그런데 동시 접속 사용자가 1000명에서 1001명을 짧은 시간에 수시로 왔다 갔다 한다면..
• 위 전략을 실행했다, 취소했다 하는 부하가 매우 커짐.
• 그래서 히스테리시스 현상을 대입하여, 임계 값의 문턱을 만듬
예) 확장시 1100명이 기준, 축소시 900명으로 기준을 바꾸어 변화 충격 완화
예) 모바일 무선 네트워크에서 기지국(셀)의 임계점을 왔다 갔다 하는 사람이 많을 때,
핑퐁 핸드오버의 부하를 줄이기 위해 사용함
천천히 하기 (Slow It Down)
히스테리시스 (이력현상 ‒Hysteresis)
119.
119
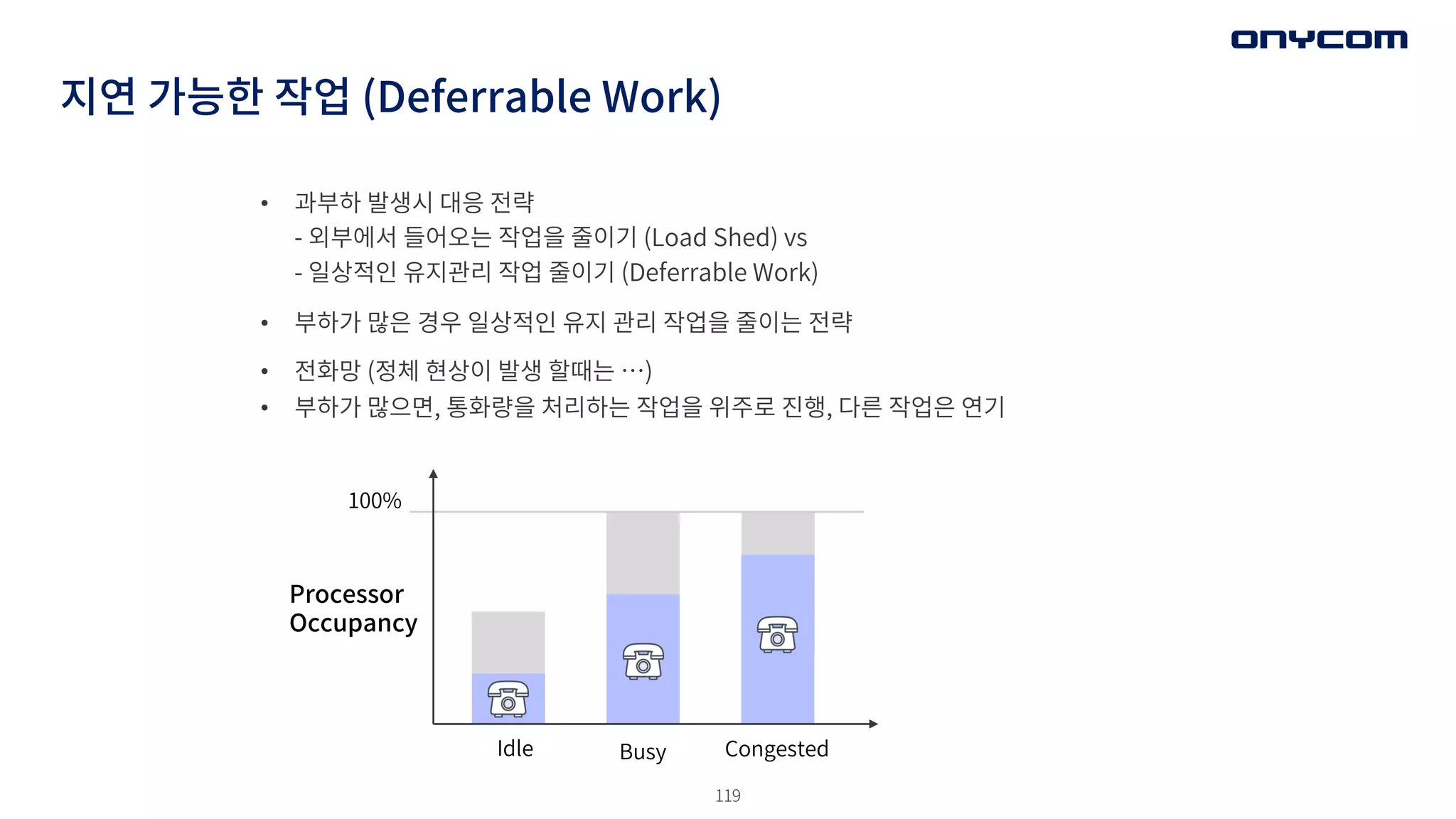
• 과부하 발생시대응 전략
- 외부에서 들어오는 작업을 줄이기 (Load Shed) vs
- 일상적인 유지관리 작업 줄이기 (Deferrable Work)
• 부하가 많은 경우 일상적인 유지 관리 작업을 줄이는 전략
• 전화망 (정체 현상이 발생 할때는 …)
• 부하가 많으면, 통화량을 처리하는 작업을 위주로 진행, 다른 작업은 연기
지연 가능한 작업 (Deferrable Work)
100%
Processor
Occupancy
Idle Busy Congested
120.
120
• 자원이 제한된환경에서 다양한 유형/우선순위를 가진 요청이 올 때 ,
• 새로운 일부터 하기(패턴) 정책이라면, 새로운 일을 먼저 처리하느라,
기존 작업은 늦게 처리되는 문제가 발생함.
• 예) 데이터베이스에 많은 요청이 오는데, 영업 사원이 물건을 사겠다는 주문이
온다면 그걸 최 우선 순위로 처리해야 한다. > 사용자마다 다른 우선순위를
주어야 함. 이상적임 > 이렇게 만들어도 됨 (우선순위 큐 쓰기)
단점 > 낮은 우선순위를 가진 애는 처리 시간을 보장 못함 (부익부 빈익빈)
> 특정 시간이 지나면 오랫동안 처리되지 못한 작업의 우선순위를 상향 시킴
공정한 자원 할당 (Equitable Resource Allocation)
121.
121
• 또 하나의전략 )
• 새로운 요청, 기존에 작업도, 공평하게 자원을 할당하는 방법
• 단 많은 요청을 처리하기 위해 유형 별로 Pool을 만들 수도 있다.
- 결제 DB에 요청하는 Pool
- 회원 가입하는 Pool
- 외부 서비스와 연동되는 Pool
• 요청 및 리소스 수요를 관리하는 데, 별도의 추가 정보를 기술해야 함
• 트랜잭션별 유형 분류 등 작업필요 (MSA별로 서비스 나누기와 유사)
• 단점) 우선순위 역전 시나리오가 발생될 수 있음.
공정한 자원 할당 (Equitable Resource Allocation)
122.
122
• 부하가 많이들어올 때 하는 제어 방식
- 내부 작업의 부하를 줄인다 (Shed Internal Work)
- 들어오는 부하를 줄인다 (Shed Incoming Load)
- 아무것도 하지 않는다
• 시스템이 작동하는 동안 허용되는 작업량을 제한
• 경합으로 인해 처리량이 떨어질 수 있다.
• 단 처리량이 0으로 떨어져서는 안된다.
보호 자동 제어 (Protective Automatic Controls)
123.
123
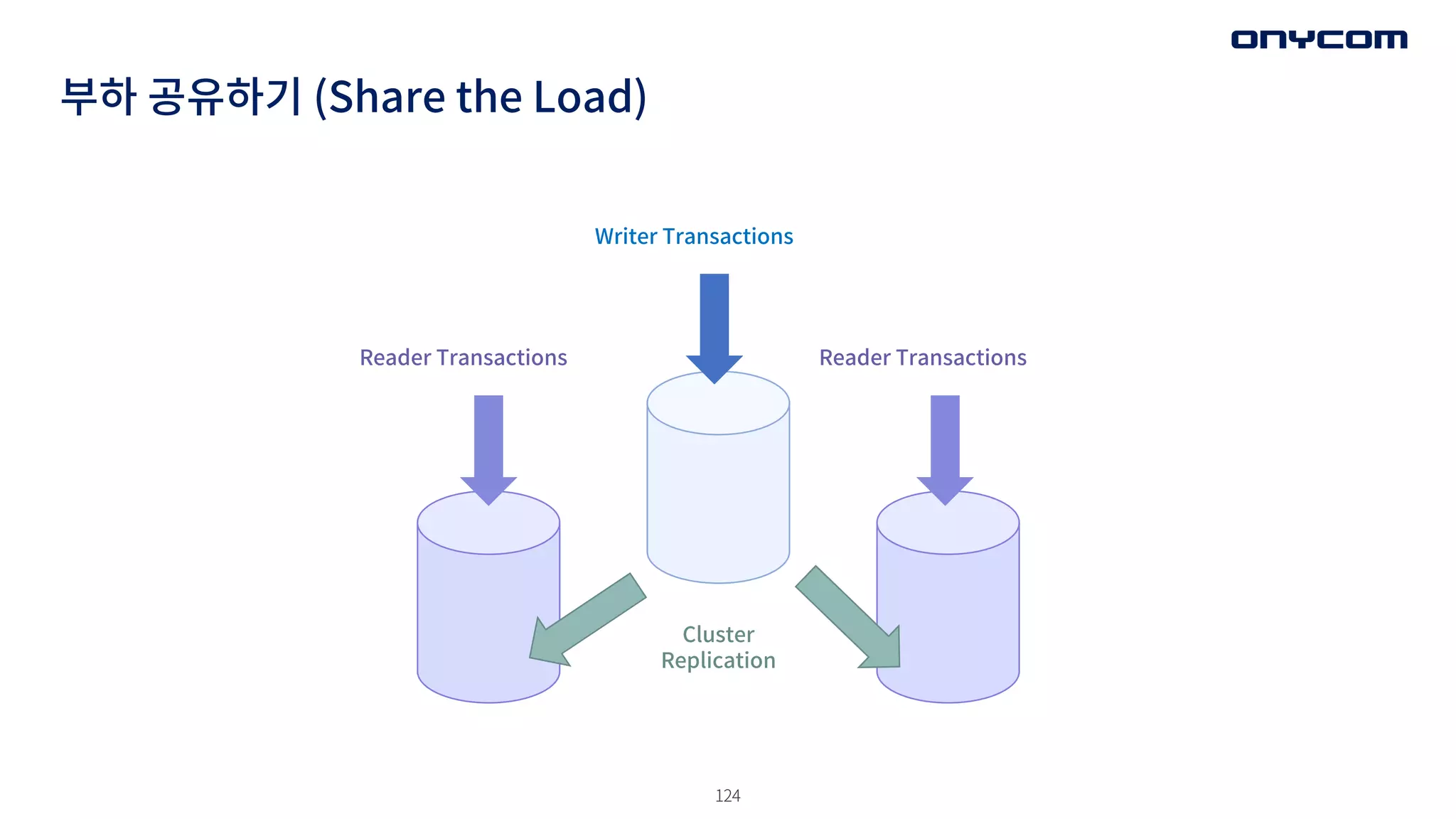
• 확장 가능한자동 제어의 연장선상
• 과부하 기간 동안 추가 처리 리소스를 사용하자
• 데이터 동기화, 프로세스 동기화를 고려하여, 부하를 분산해라.
부하 공유하기 (Share the Load)
125
• 즉각 처리하지않아도 되는 요청이라면.
• 자원이 제한 되어서 대기할 수 밖에 없는 요청이라면.
• 대기열을 만들어서, 손실없이 이후에 결과를 반환해라.
• 즉각 처리하지 않아도 되는 요청
- 빅데이터 분석, 대용량 로그 분석 등
• 제한된 자원
- KTX 추석/설날 예약시를 고려해 많은 서버를 항상 운영할수 없다.
순차적으로 입장하도록 대기열 쓰기
- 프린터 하기 -> 프린터 하나에 여러 명이 동시에 출력하고자 하면,
먼저 프린트를 한 사람 부터
리소스 할당해 대기시키기 (Queue for Resource)
126.
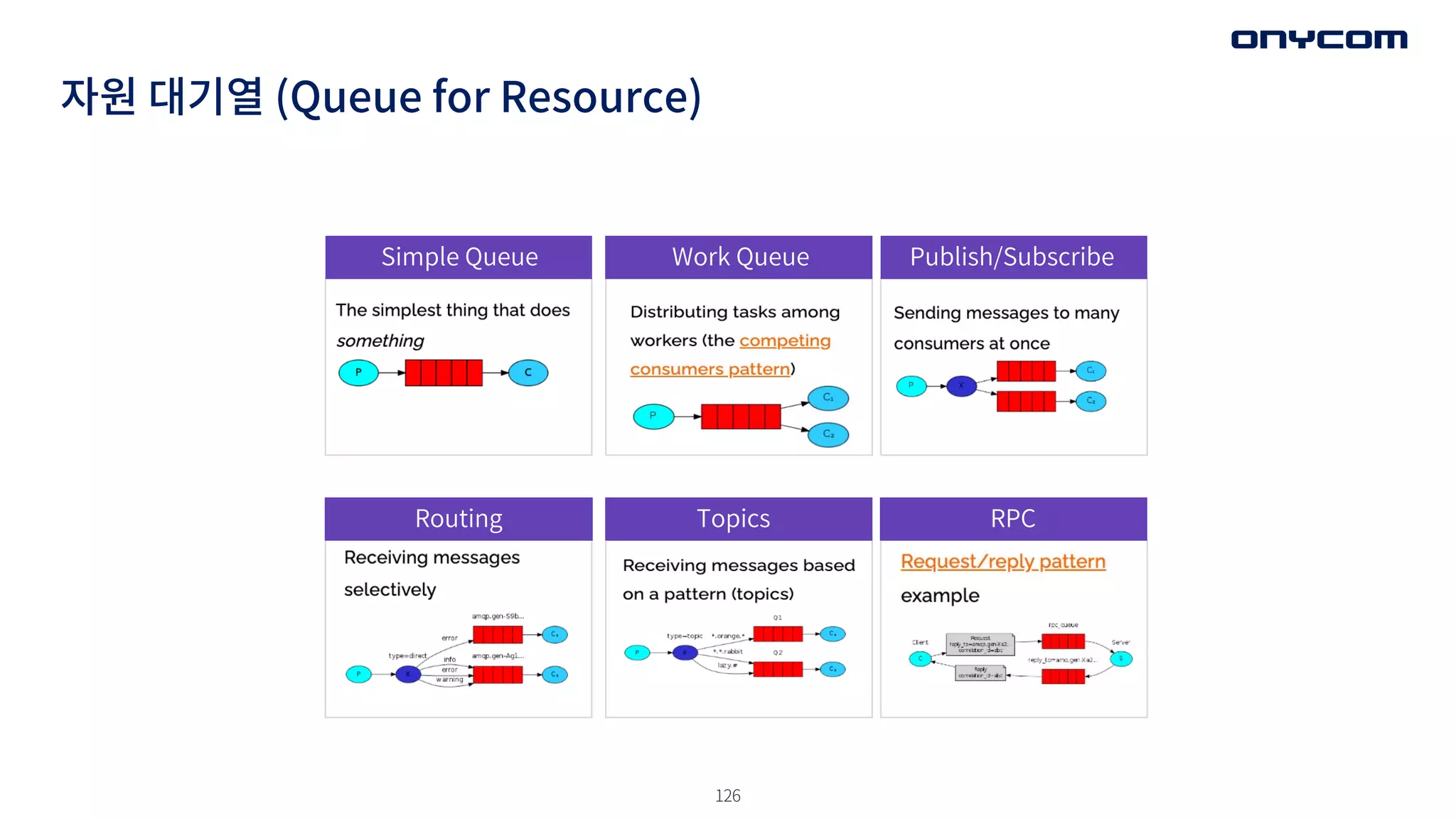
자원 대기열 (Queuefor Resource)
126
Simple Queue Work Queue Publish/Subscribe
Routing Topics RPC
127.
127
• 시스템 데이터경로와 스토리지를 가능한 오류 없이 만드는 방법은?
• 각 CHECKSUM 은 잘못된 데이터 값이 감지 될때, 시스템이 자동으로
수정할수 있도록 충분한 정보를 제공할 수 있다.
오류 수정 코드 (Error Correcting Codes)
2개의 추가 비트들은 4개의 데이터 비트들을 보호할 수 있다.
128.
128
최종 처리 (FinalHandling)
• 자원을 제대로 해제하지 못한,
비정상적으로 종료된 요청들을 관리하는, 매커니즘을 지원해라.
• 1)개발시 별도의 정상/ 비정상 리소스 해제 매커니즘을 준비할 것
• 2)정상 비정상 사례가 동일한 리소스 해제 매커니즘을 공유
2번 방식)
정상/비정상 동일 리소스 해제 매커니즘이 관리
비용이 적게 발생
-> 코드 관리도 간단
Garbage Collector??





























































![108
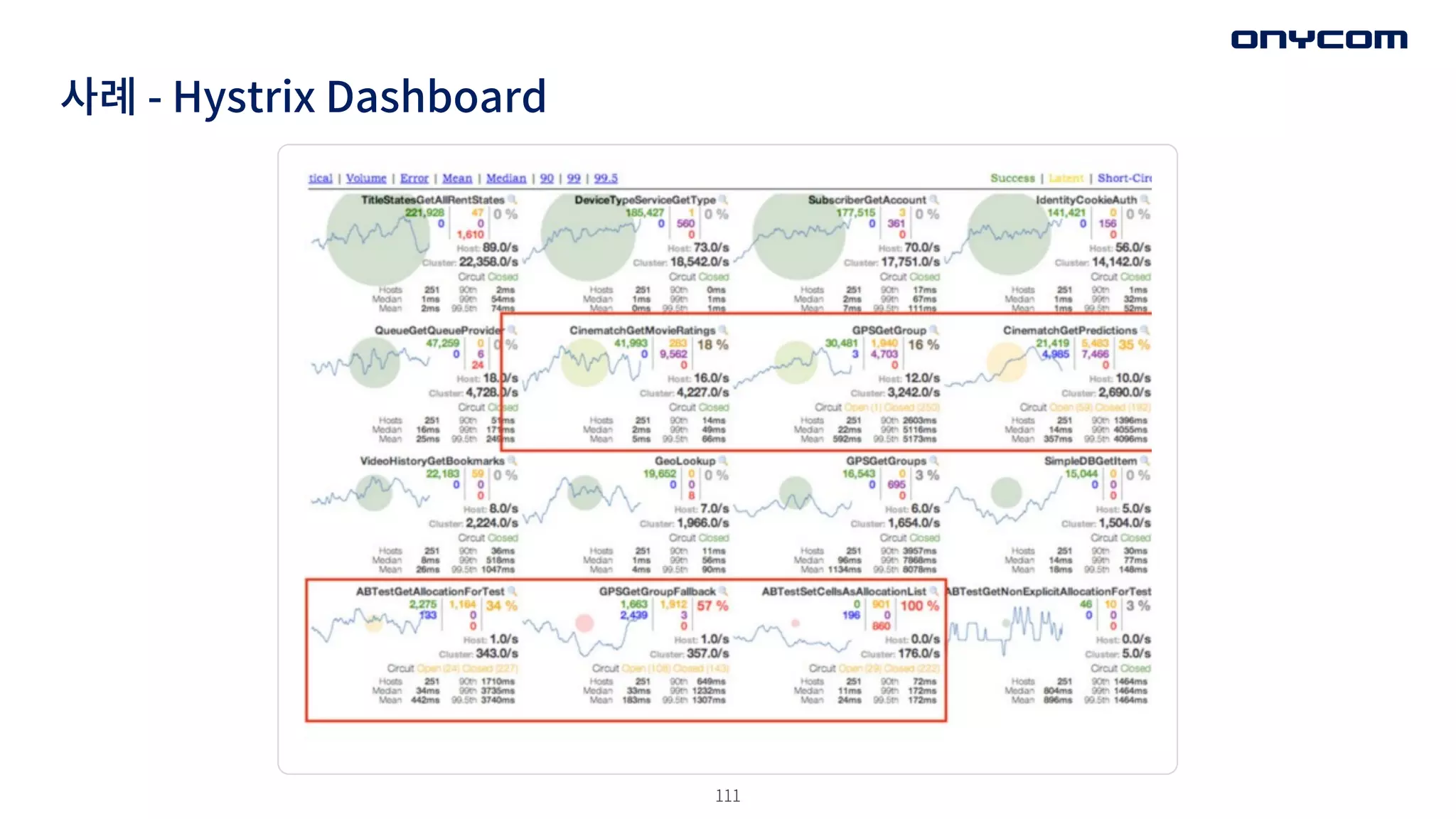
부하 억제 (Shed Load)
• 다수에게 서비스를 제공하기 위해, 소수를 버려라.
• 임계점에서 자원 사용량을 줄이는 방법
• 패턴 (해결책) : 거부해라. (AcK를 보내지 말거나, 40X 보내기)
• 그래서 MSA 패턴중 ‒ Circuit Breaker 도입
Closed Open
Half Open
success
Fail [threshold reached]
Fail
Call/ raise circuit open
Reset timeout
success
Fail [under threshold]](https://image.slidesharecdn.com/2022faulttolerancepattern-221214060443-5144e1c3/75/Fault-Tolerance-108-2048.jpg)


























![[D2]pinpoint 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/d2pinpoint-150522091711-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





![[IMQA] performance consulting](https://cdn.slidesharecdn.com/ss_thumbnails/imqaperformanceconsulting-210528063922-thumbnail.jpg?width=640&height=640&fit=bounds)




![[네이버오픈소스세미나] Pinpoint를 이용해서 서버리스 플랫폼 Apache Openwhisk 트레이싱하기 - 오승현](https://cdn.slidesharecdn.com/ss_thumbnails/apacheopenwhisktracingwithpinpoint-190716072443-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[일본자료] 시스템엔지니어링입문(게이오 기주쿠 대학 시스템디자인관리(SDM)) 강의자료](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontoseinkorean-181215102014-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Main Session] 보안을 고려한 애플리케이션 개발 공정 및 실무적 수행 방법 소개](https://cdn.slidesharecdn.com/ss_thumbnails/s-sdlcsecurecoding2018-04-21-180423031934-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IMQA] 빠른 웹페이지 만들기 - 당신의 웹페이지는 몇 점인가요?](https://cdn.slidesharecdn.com/ss_thumbnails/imqa-230410032255-964948bc-thumbnail.jpg?width=640&height=640&fit=bounds)







