Download as PDF, PPTX












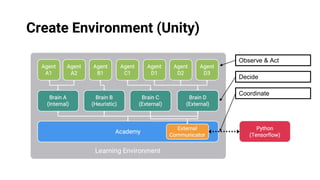

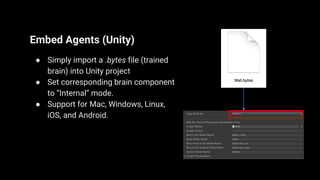






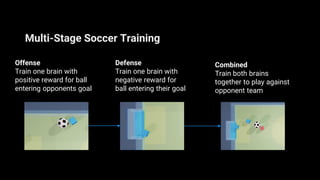






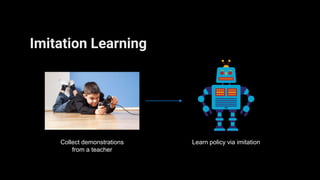





Unity ML-Agents enables developers to create intelligent agents capable of learning through various methods such as reinforcement and imitation learning within dynamic environments. The toolkit has evolved through several versions, adding components like curriculum learning, multi-agent training, and on-demand decision-making. It supports deployment across multiple platforms, allowing seamless integration into Unity projects.



































































