
Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to GAN Models and Training
Similar to GAN Models and Training (20)
Recently uploaded
Recently uploaded (20)
GAN Models and Training
- 1. BENJAMIN PETRY bpetry@acm.org www.bpetry.de Generative Adversarial Networks SHAMANE SIRIWARDHANA
- 3. Why Generative Models are Important
- 5. Discriminative (Eg : CNN) Yunjey Choi
- 10. Designing stuff for you !
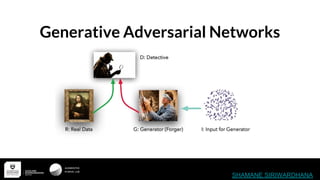
- 14. Generative Adversarial Networks(GAN) Basic Architecture
- 15. Somehow Generator needs to fool the Discriminator
- 16. Min-Max Game ● Generator trying to Fool the discriminator ● Discriminator somehow needs to identify fake from real very well ● Something similar to min-max in game theory Since it’s Adversary
- 18. Two way Optimization ❖ In supervised learning we train our network with a single objective function ❖ But here we have to train Generator and the Discriminator separately
- 19. After the two way Optimization ... Start End
- 20. How to train your GAN
- 21. Discriminator
- 22. Training the Discriminator Yunjey Choi
- 23. Training the Discriminator Yunjey Choi
- 24. Generator
- 25. Training the Generator D is Fixed ! Yunjey Choi
- 30. Main Problem - Discriminator Saturation ● Discriminator is too Good :( ● There won’t be any chance for the generator to learn something Yunjey Choi
- 31. Why GAN Works ? No Magic
- 32. ● GAN's Task is to make the Generated Distribution(Pmodel) same as the Real data Distribution(Preal)
- 33. ● There are ways to measure similarity of two distributions Eg: ○ KL divergence ○ Jensen–Shannon divergence We can easily prove that Optimization of GAN’s loss function is similar to reducing Jensen–Shannon divergence between the two distributions
- 35. When we have an optimal discriminator Optimization of the Loss = Minimizing the Jensen Shannon Divergence
- 36. Challenges in training ! ● Non-convergence: the parameters oscillate, constantly destabilize and unlikely to arrive to converge (Issues with Nash Equality). ● Mode collapse: generator collapses, leading to produce limited varieties of samples.
- 37. Yes! there are more stable methods right now ! ❖ Wasserstein GAN WGAN vs GAN - Similar in terms of Formality & Functionality Only thing change is the Loss Function !
- 38. Now Loss Function is more of a Critic ! ❖ Previously the Discriminator and the Generator are working against each other ❖ But now discriminator is is trying to give the generator an Idea of how different it’s generated data is deviate from the actual data distribution. ❖ No Log probabilities - No Diminish Gradients ❖ Uses EM(Earth Mover's Distance) distance to model the loss function !
- 39. Wasserstein Distance or EM Distance This is a measurement about how much work that generator has to do to match the distribution of the real images This is why we call it a Critic!
- 40. Reducing the distance between generated samples and real samples Generator distribution Real distribution Critic
- 41. WGAN vs GAN
- 42. Solving the Vanishing Gradient Issues .. More stable training ...
- 45. Resources GAN - https://arxiv.org/abs/1406.2661 WGAN - https://arxiv.org/abs/1701.07875 Improved WGAN - https://arxiv.org/abs/1704.00028 Principal Method Of Training GAN - https://openreview.net/pdf?id=Hk4_qw5xe Amazing series of Article By Jonathan Hui https://medium.com/@jonathan_hui/gan-whats-generative-adversarial-networks-and-its-application-f39ed278ef09