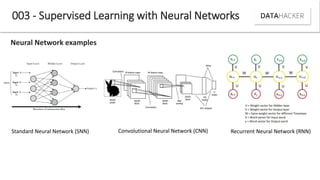
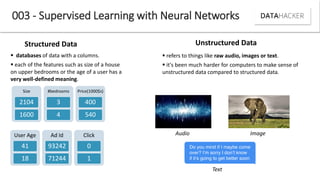
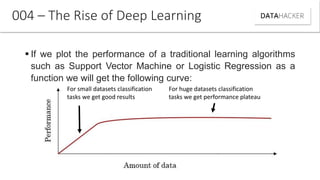
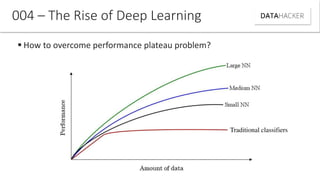
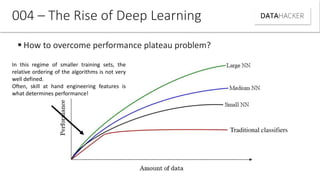
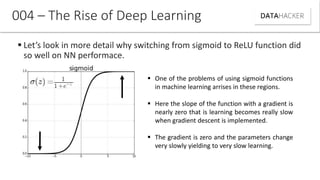
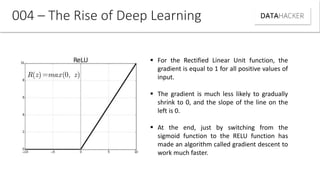
Deep learning uses neural networks to process data and create patterns in a way that imitates the human brain. It has transformed industries like web search and advertising by enabling tasks like image recognition. This document discusses neural networks, deep learning, and their various applications. It also explains how recent advances in algorithms and increased data availability have driven the rise of deep learning by allowing neural networks to train on larger datasets and overcome performance plateaus.













































































































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)



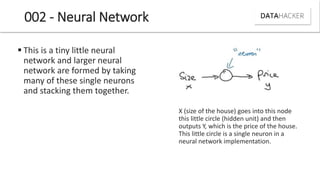
![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)












