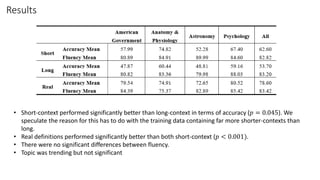
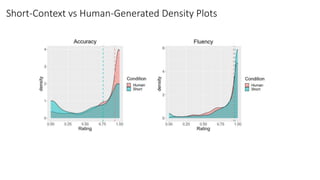
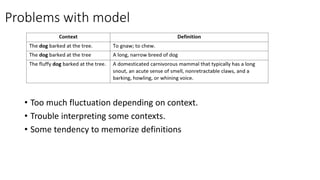
The document discusses a study that trained a GPT-2 model to generate contextual definitions for words based on the provided context. The model was trained on a new dataset containing definition and context pairs from various sources. It was evaluated through surveys where human raters assessed definitions generated by the model for short and long contexts, as well as real human-generated definitions. The results found that while the model performed significantly better at generating definitions for short contexts compared to long ones, human-generated definitions were still significantly more accurate. Areas for improvement included reducing fluctuations depending on context and better interpreting some contexts.








































![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=640&height=640&fit=bounds)


























































