Download to read offline




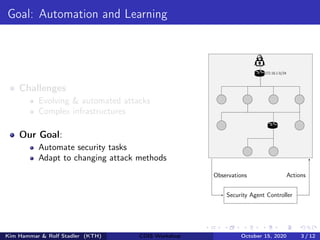


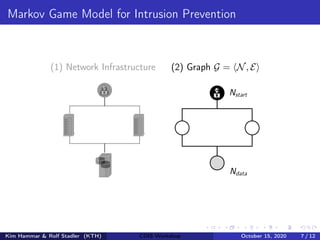
![Markov Game Model for Intrusion Prevention
(1) Network Infrastructure (2) Graph G = hN, Ei
Ndata
Nstart
(3) State space |S| = (w + 1)|N|·m·(m+1)
SA
3 = [0, 0, 0, 0]
SD
3 = [9, 1, 5, 8, 1]
SA
0 = [0, 0, 0, 0]
SD
0 = [0, 0, 0, 0, 0]
SA
1 = [0, 0, 0, 0]
SD
1 = [1, 9, 9, 8, 1]
SA
2 = [0, 0, 0, 0]
SD
2 = [9, 9, 9, 8, 1]
Kim Hammar & Rolf Stadler (KTH) CDIS Workshop October 15, 2020 7 / 12](https://image.slidesharecdn.com/cdishammarstadler15oct2020-210205113942/85/Cdis-hammar-stadler_15_oct_2020-11-320.jpg)
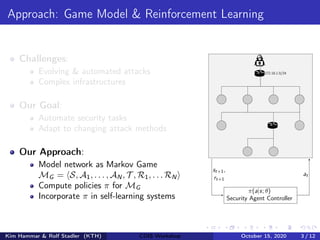
![Markov Game Model for Intrusion Prevention
(1) Network Infrastructure (2) Graph G = hN, Ei
Ndata
Nstart
(3) State space |S| = (w + 1)|N|·m·(m+1)
SA
3 = [0, 0, 0, 0]
SD
3 = [9, 1, 5, 8, 1]
SA
0 = [0, 0, 0, 0]
SD
0 = [0, 0, 0, 0, 0]
SA
1 = [0, 0, 0, 0]
SD
1 = [1, 9, 9, 8, 1]
SA
2 = [0, 0, 0, 0]
SD
2 = [9, 9, 9, 8, 1]
(4) Action space |A| = |N| · (m + 1)
?/0 ?/0 ?/0 ?/0
?/0
?/0
?/0 ?/0 ?/0
Kim Hammar & Rolf Stadler (KTH) CDIS Workshop October 15, 2020 7 / 12](https://image.slidesharecdn.com/cdishammarstadler15oct2020-210205113942/85/Cdis-hammar-stadler_15_oct_2020-12-320.jpg)
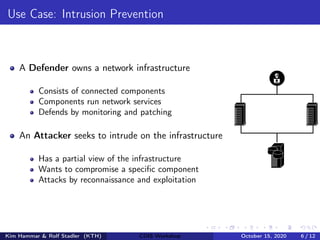
![Markov Game Model for Intrusion Prevention
(1) Network Infrastructure (2) Graph G = hN, Ei
Ndata
Nstart
(3) State space |S| = (w + 1)|N|·m·(m+1)
SA
3 = [0, 0, 0, 0]
SD
3 = [9, 1, 5, 8, 1]
SA
0 = [0, 0, 0, 0]
SD
0 = [0, 0, 0, 0, 0]
SA
1 = [0, 0, 0, 0]
SD
1 = [1, 9, 9, 8, 1]
SA
2 = [0, 0, 0, 0]
SD
2 = [9, 9, 9, 8, 1]
(4) Action space |A| = |N| · (m + 1)
?/0 ?/0 ?/0 ?/0
?/0
?/0
?/0 ?/0 ?/0
(5) Game Dynamics T , R1, R2, ρ0
4/0 0/1 8/0 ?/0
?/0
?/0
0/0 9/0 8/0
Kim Hammar & Rolf Stadler (KTH) CDIS Workshop October 15, 2020 7 / 12](https://image.slidesharecdn.com/cdishammarstadler15oct2020-210205113942/85/Cdis-hammar-stadler_15_oct_2020-13-320.jpg)
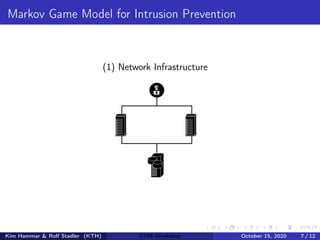
![Markov Game Model for Intrusion Prevention
(1) Network Infrastructure (2) Graph G = hN, Ei
Ndata
Nstart
(3) State space |S| = (w + 1)|N|·m·(m+1)
SA
3 = [0, 0, 0, 0]
SD
3 = [9, 1, 5, 8, 1]
SA
0 = [0, 0, 0, 0]
SD
0 = [0, 0, 0, 0, 0]
SA
1 = [0, 0, 0, 0]
SD
1 = [1, 9, 9, 8, 1]
SA
2 = [0, 0, 0, 0]
SD
2 = [9, 9, 9, 8, 1]
(4) Action space |A| = |N| · (m + 1)
?/0 ?/0 ?/0 ?/0
?/0
?/0
?/0 ?/0 ?/0
(5) Game Dynamics T , R1, R2, ρ0
4/0 0/1 8/0 ?/0
?/0
?/0
0/0 9/0 8/0
∴
- Markov game
- Zero-sum
- 2 players
- Partially observed
- Stochastic elements
- Round-based
MG = hS, A1, A2, T , R1, R2, γ, ρ0i
Kim Hammar & Rolf Stadler (KTH) CDIS Workshop October 15, 2020 7 / 12](https://image.slidesharecdn.com/cdishammarstadler15oct2020-210205113942/85/Cdis-hammar-stadler_15_oct_2020-14-320.jpg)
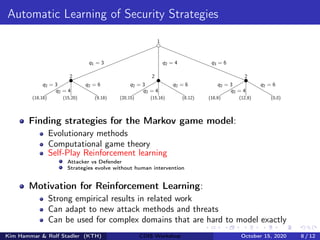
![The Reinforcement Learning Problem
Goal:
Approximate π∗
= arg maxπ E
hPT
t=0 γt
rt+1
i
Learning Algorithm:
Represent π by πθ
Define objective J(θ) = Eo∼ρπθ ,a∼πθ
[R]
Maximize J(θ) by stochastic gradient ascent with gradient
∇θJ(θ) = Eo∼ρπθ ,a∼πθ
[∇θ log πθ(a|o)Aπθ
(o, a)]
Domain-Specific Challenges:
Partial observability: captured in the model
Large state space |S| = (w + 1)|N|·m·(m+1)
Large action space |A| = |N| · (m + 1)
Non-stationary Environment due to presence of adversary
Agent
Environment
at
st+1
rt+1
Kim Hammar & Rolf Stadler (KTH) CDIS Workshop October 15, 2020 9 / 12](https://image.slidesharecdn.com/cdishammarstadler15oct2020-210205113942/85/Cdis-hammar-stadler_15_oct_2020-16-320.jpg)
![The Reinforcement Learning Problem
Goal:
Approximate π∗
= arg maxπ E
hPT
t=0 γt
rt+1
i
Learning Algorithm:
Represent π by πθ
Define objective J(θ) = Eo∼ρπθ ,a∼πθ
[R]
Maximize J(θ) by stochastic gradient ascent with gradient
∇θJ(θ) = Eo∼ρπθ ,a∼πθ
[∇θ log πθ(a|o)Aπθ
(o, a)]
Domain-Specific Challenges:
Partial observability: captured in the model
Large state space |S| = (w + 1)|N|·m·(m+1)
Large action space |A| = |N| · (m + 1)
Non-stationary Environment due to presence of adversary
Agent
Environment
at
st+1
rt+1
Kim Hammar & Rolf Stadler (KTH) CDIS Workshop October 15, 2020 9 / 12](https://image.slidesharecdn.com/cdishammarstadler15oct2020-210205113942/85/Cdis-hammar-stadler_15_oct_2020-17-320.jpg)
![The Reinforcement Learning Problem
Goal:
Approximate π∗
= arg maxπ E
hPT
t=0 γt
rt+1
i
Learning Algorithm:
Represent π by πθ
Define objective J(θ) = Eo∼ρπθ ,a∼πθ
[R]
Maximize J(θ) by stochastic gradient ascent with gradient
∇θJ(θ) = Eo∼ρπθ ,a∼πθ
[∇θ log πθ(a|o)Aπθ
(o, a)]
Domain-Specific Challenges:
Partial observability: captured in the model
Large state space |S| = (w + 1)|N|·m·(m+1)
Large action space |A| = |N| · (m + 1)
Non-stationary Environment due to presence of adversary
Agent
Environment
at
st+1
rt+1
Kim Hammar & Rolf Stadler (KTH) CDIS Workshop October 15, 2020 9 / 12](https://image.slidesharecdn.com/cdishammarstadler15oct2020-210205113942/85/Cdis-hammar-stadler_15_oct_2020-18-320.jpg)


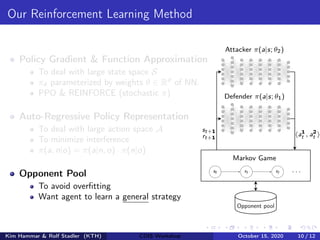
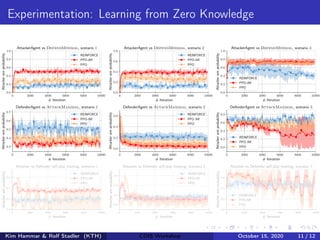
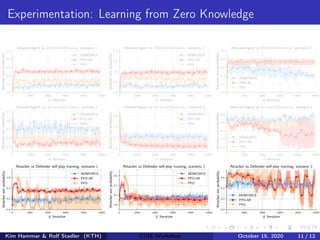



The document describes using reinforcement learning to model cyber security as a Markov game and learn security strategies. Specifically: - A network infrastructure is modeled as a graph, with states representing network configuration and actions like patching or attacking components. - This is formulated as a Markov game with two players (attacker and defender). Reinforcement learning is used to approximate optimal policies by representing policies with neural networks and optimizing a policy gradient objective. - Challenges include large state/action spaces and a non-stationary environment. The method addresses these through policy parameterization, auto-regressive policy representations, and training against an opponent pool.























































































