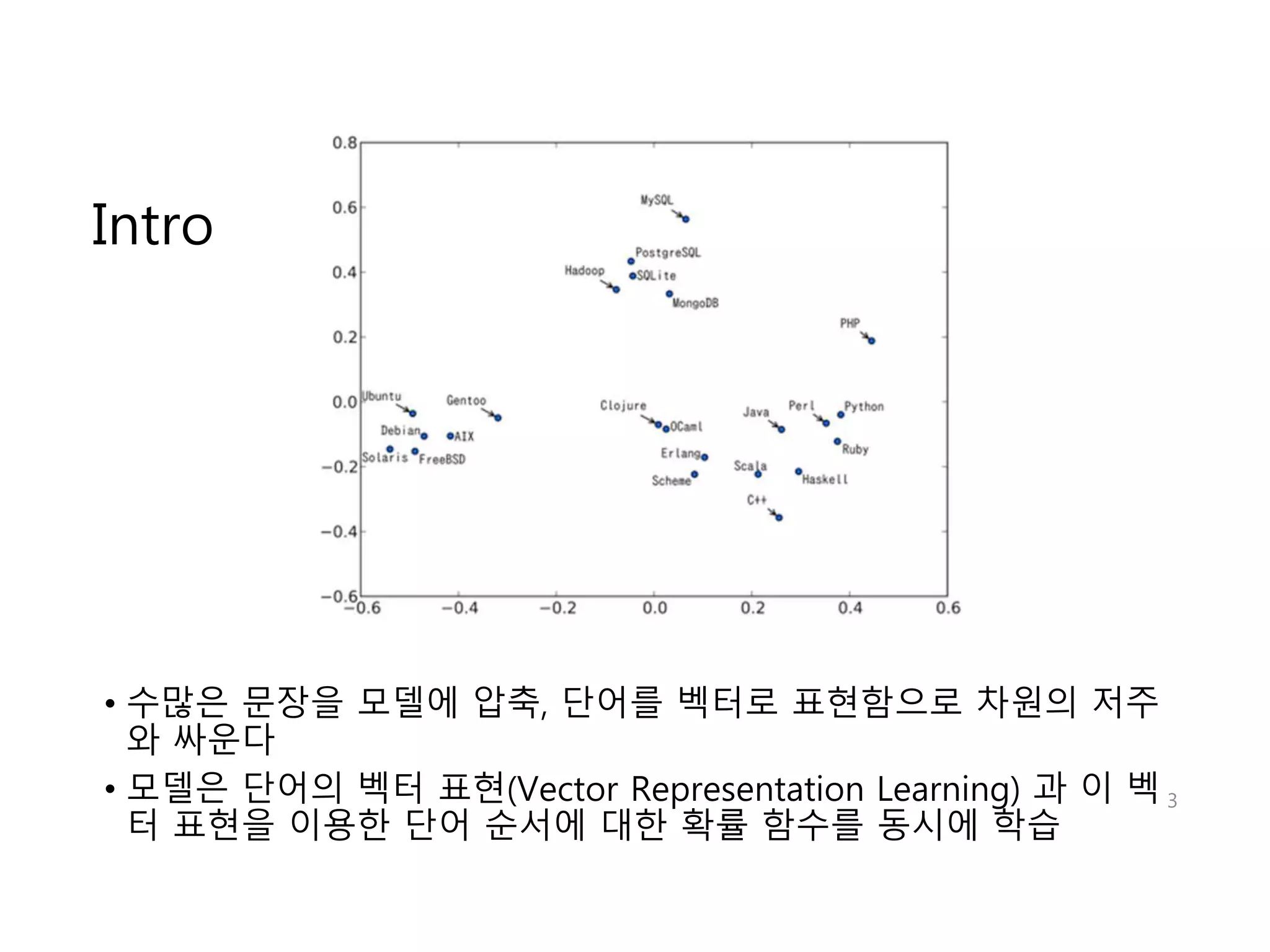
Intro
• 고전언어 모델 N-gram
• 다 세는 거 어렵다
• p(wt | wt-1) => 추정할 parameter 수 |V|^2
• p(wt | wt-1,wt-2) => 추정할 parameter 수 |V|^3
• p(wt | wt-1,wt-2, wt-3) => 추정할 parameter 수 |V|^4
• …
• 차원의 저주
3.
Intro
• 수많은문장을 모델에 압축, 단어를 벡터로 표현함으로 차원의 저주
와 싸운다
• 모델은 단어의 벡터 표현(Vector Representation Learning) 과 이 벡
터 표현을 이용한 단어 순서에 대한 확률 함수를 동시에 학습
3
4.
LSI와 다른 점
• LSI 는 같은 문서 안의 단어의 co-occurring을 단
어의 특성 벡터로 학습
• NPLM 은 단어 시퀀스의 확률 분포를 컴팩트하게
표현하는 것이 목표
• 다음 문장의 시밀러리티를 인지할 수 있음
• cat 다음에 dog가 비슷한 특성 벡터로 학습됨
• LSI 는 못함
4
1.1 Fighting theCurse of Dimensionality
with Distributed Representations
• 단어를 피쳐 벡터(실수)로 표현
• 단어 시퀀스의 결합 확률 함수를 피쳐 벡터로 표
현
• 학습 시 단어 피쳐 벡터와 확률 함수의 파라메터
를 동시에 학습
• 이 함수는 훈련셋의 log-likelihood +regularized criterion 을 최대화 하는 방
향으로 파라메터를 반복적으로 수정해 간다(ridge regression과 비슷)
• 학습 후, “비슷한” 단어는 비슷한 피쳐 벡터를 갖
게 된다
7.
2. A NeuralModel
• 학습 데이터는 단어 시퀀스 w1 · · · wT of words wt ∈ V
• The objective is to learn a good model, f(wt,··· ,wt−n+1) = Pˆ(wt|wt−1) in the sense
that it gives high out-of-sample likelihood
• 학습의 목적은 학습 데이터의 likelihood가 제일 큰 모델 P를 피팅하는 것
• The only constraint on the model is that for any choice of wt−1,
• f(i,wt,··· ,wt−n+1): 이전 단어들이 주어졌을 때, 현재 단어가 i일 확률
• By the product of these conditional probabilities, one obtains a model of the joint
probability of sequences of words.
• 이 조건부 확률의 곱으로, 단어 시퀀스의 결합확률을 구할 수 있다
8.
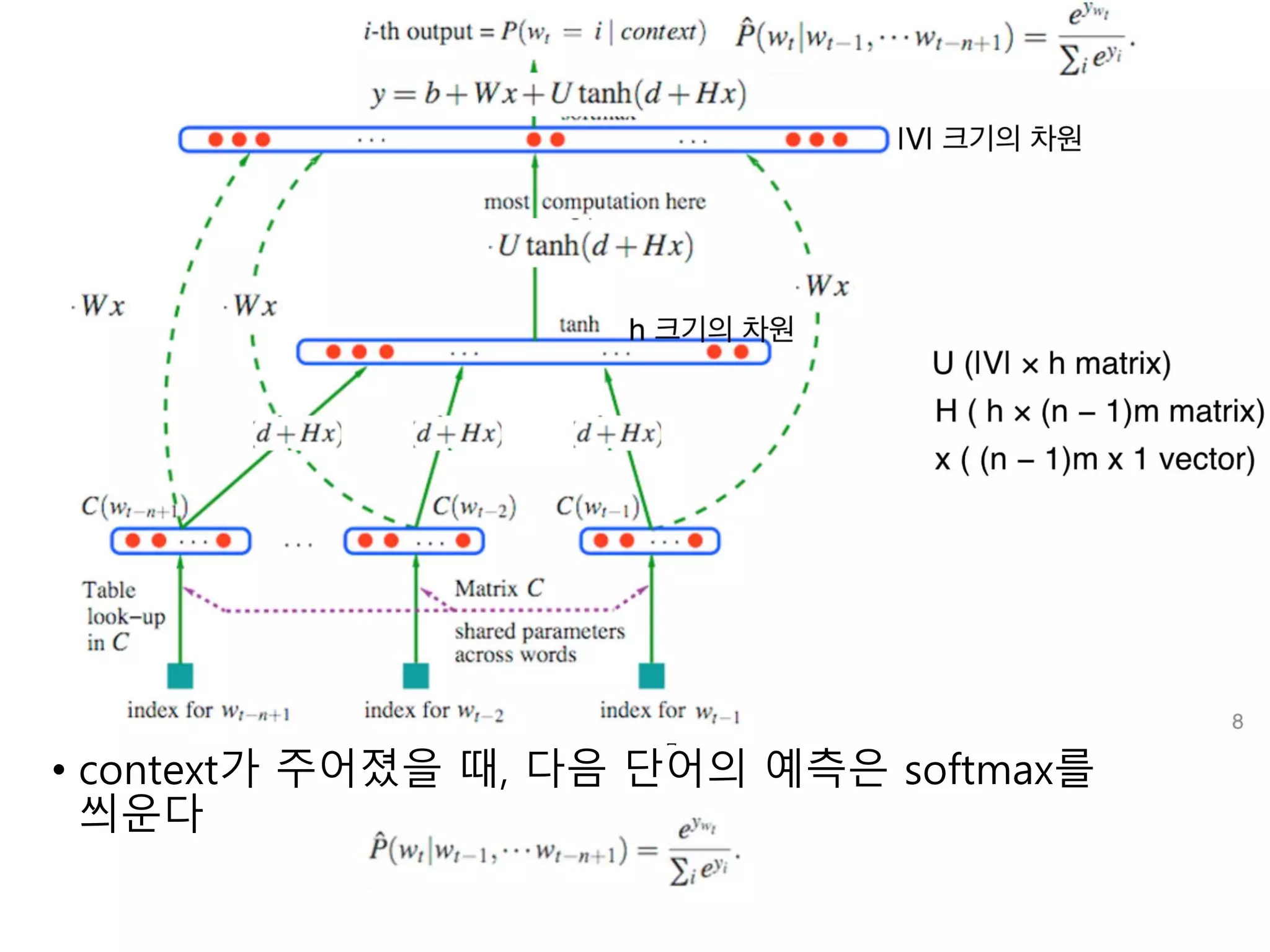
2. A NeuralModel
g의 아웃풋 벡터의 i 번째 원소 = 다음 단어 가 단어집의 i 번째 단어일
• f를 두 부분으로 나눌 수 있다
• 각 단어의 특성 벡터 와 그 벡터의 모든 단어의 모임 행렬 C
• 인풋 단어 시퀀스가 주어졌을 때, 다음 단어에 뭐가 나올지에 대한
확률 분포 g
8
9.
2. A NeuralModel
뉴럴넷으로 구현
• 함수 f 는 두 매핑 C 와 g의 합성이고, C 는 context안의 모든 단어가 공
유한다
• C 와 g 는 각각 파라메터를 갖는다
• C의 파라메터는 피쳐 벡터 자신, 즉 단어 i의 피쳐벡터는 |V | × m matrix
C에서 i번째 row를 추출. C(i)
• 함수 g는 뉴럴넷으로 구성, 그러므로 뉴럴넷의 파라메터ω 가 g의 파라
메터
• 전체 파라메터는 θ = (C, ω).
• Training is achieved by looking for θ that maximizes the training
corpus penalized log-likelihood:
9
• 단어 시퀀스에서 각 단어를 한칸씩 순회하면서, 훈련셋에서 나온 단어의
p(wt | context)가 최대가 되도록 파라메터 θ를 피팅
10.
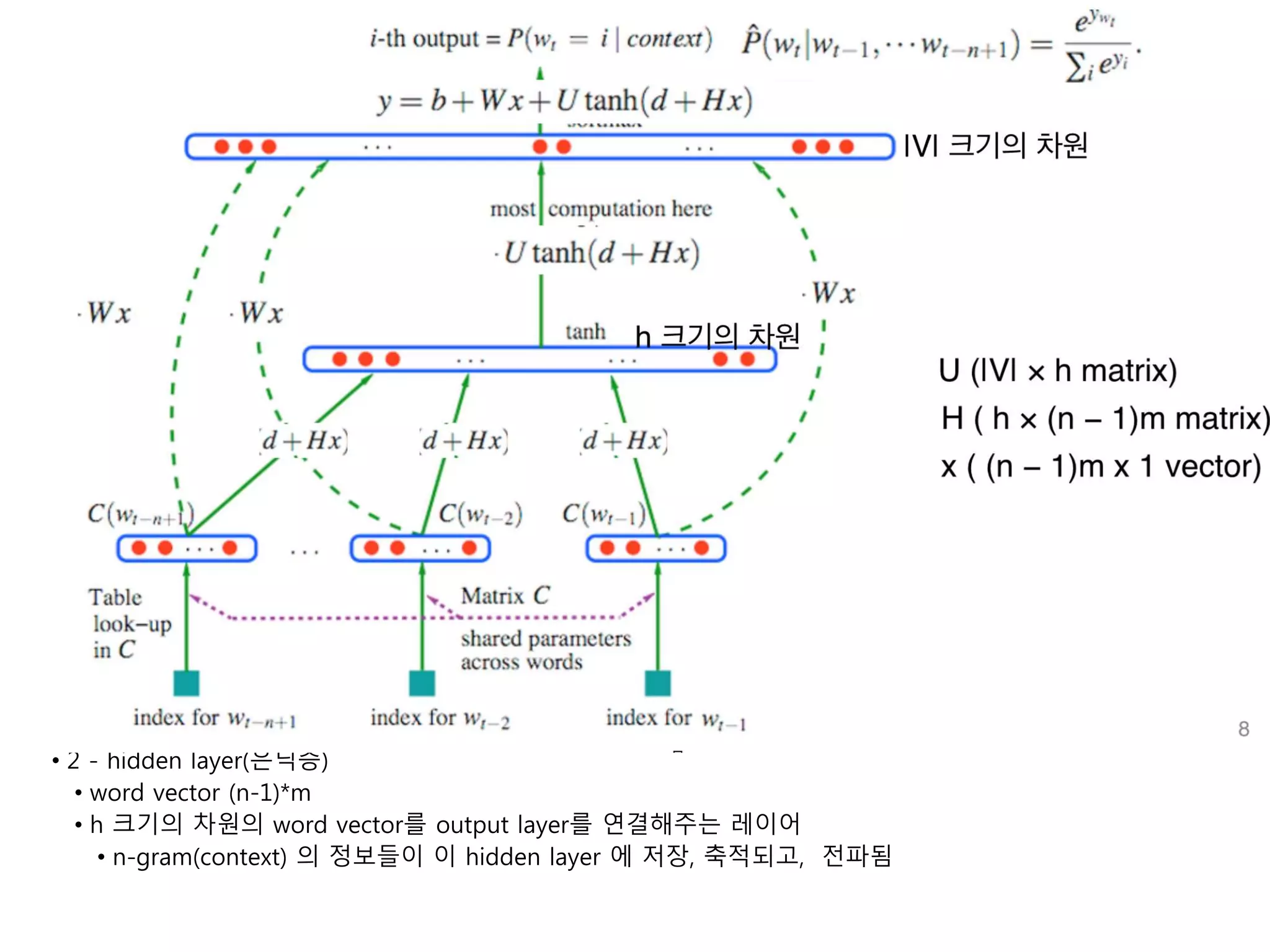
• 2 -hidden layer(은닉층)
• word vector (n-1)*m
• h 크기의 차원의 word vector를 output layer를 연결해주는 레이어
• n-gram(context) 의 정보들이 이 hidden layer 에 저장, 축적되고, 전파됨
11.
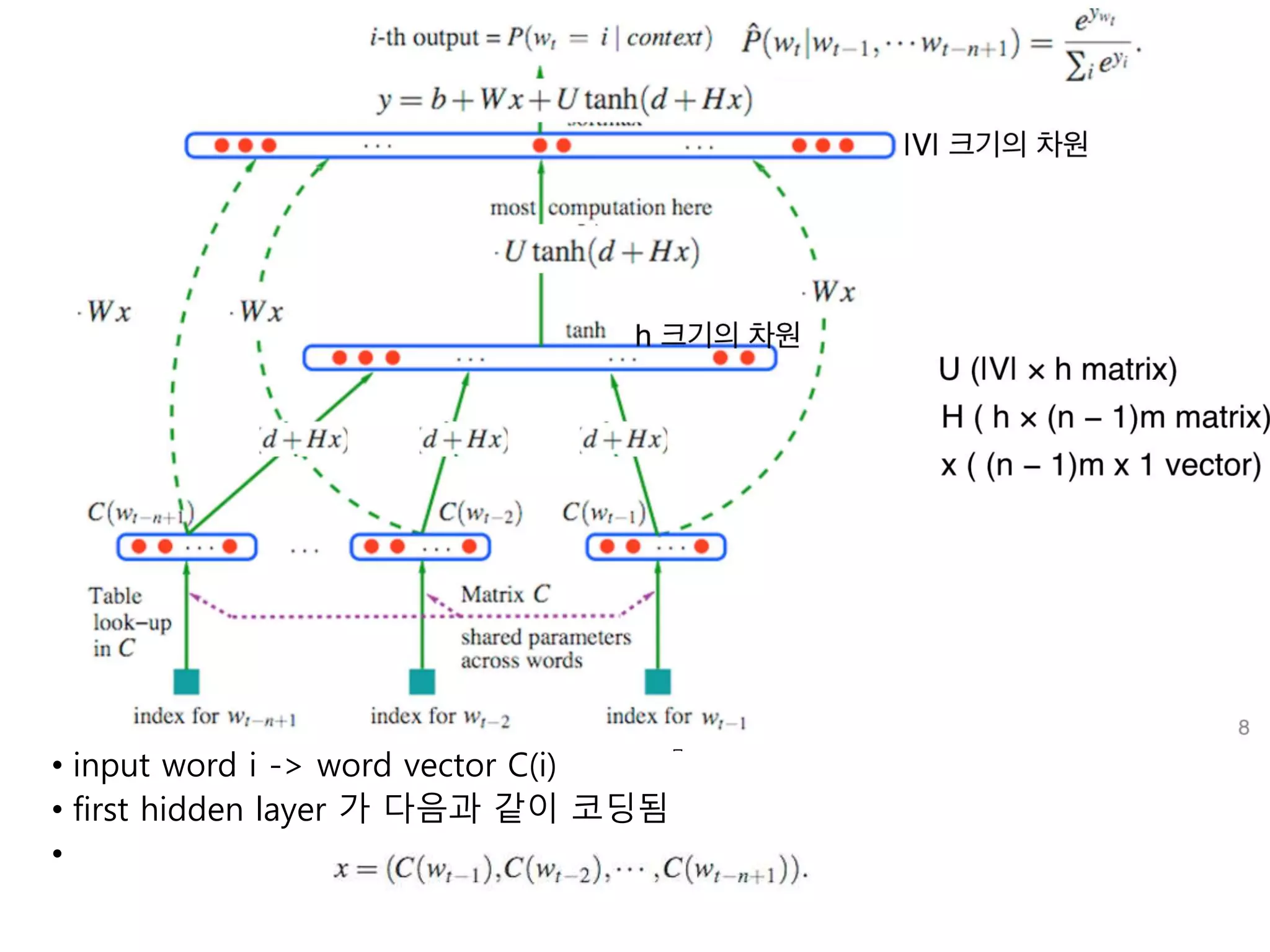
• input wordi -> word vector C(i)
• first hidden layer 가 다음과 같이 코딩됨
•
12.
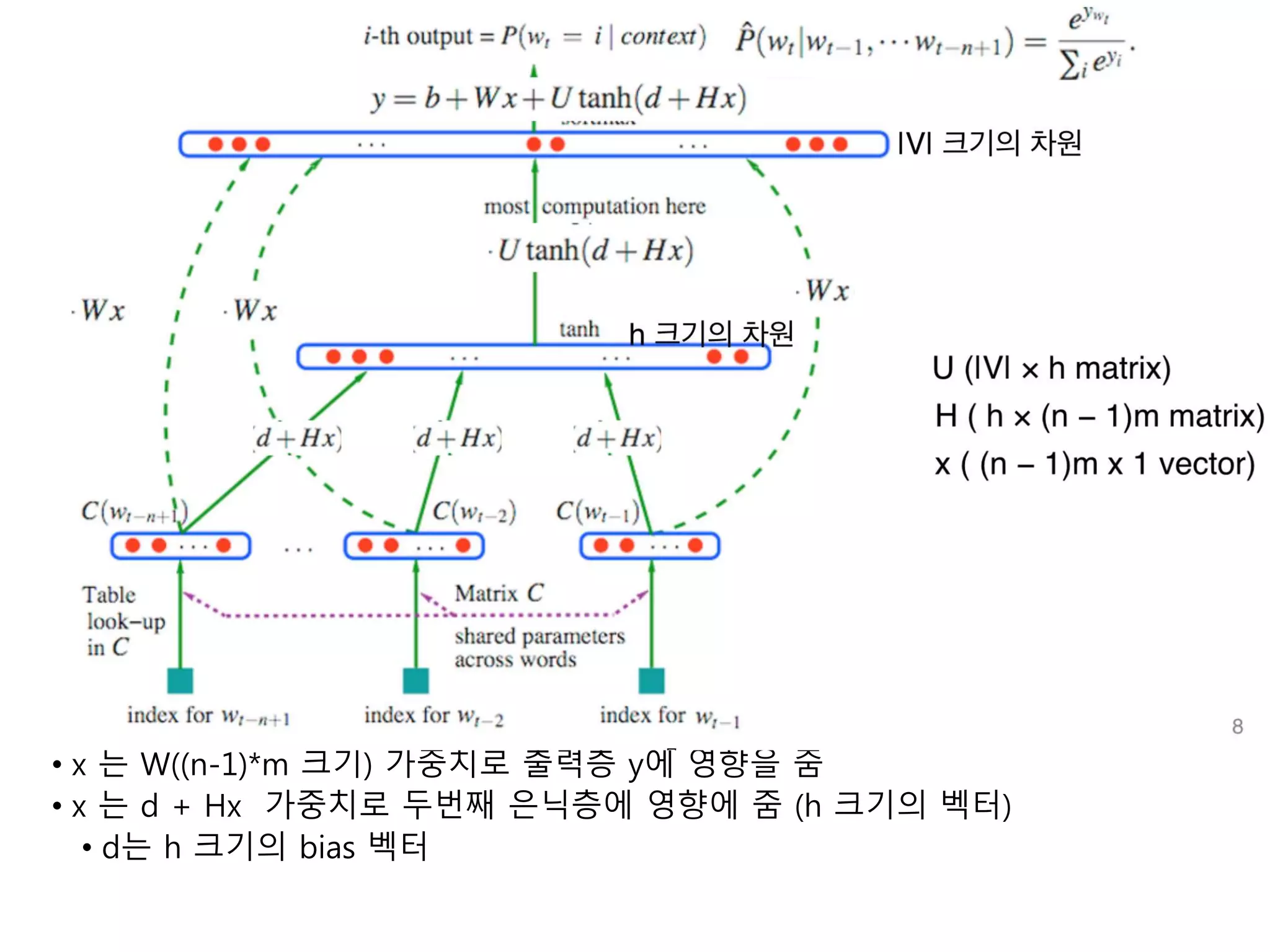
• x 는W((n-1)*m 크기) 가중치로 출력층 y에 영향을 줌
• x 는 d + Hx 가중치로 두번째 은닉층에 영향에 줌 (h 크기의 벡터)
• d는 h 크기의 bias 벡터
13.
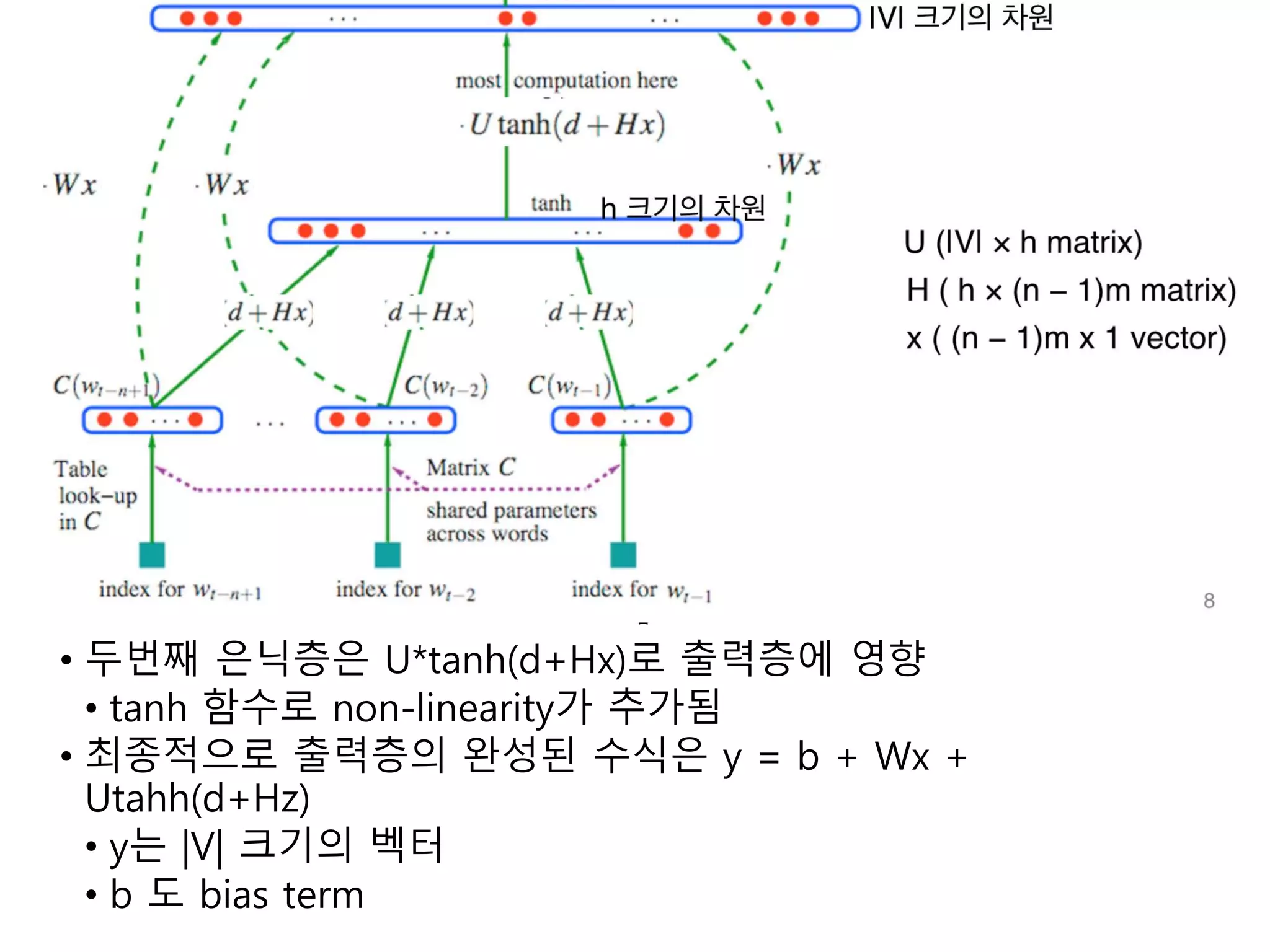
• 두번째 은닉층은U*tanh(d+Hx)로 출력층에 영향
• tanh 함수로 non-linearity가 추가됨
• 최종적으로 출력층의 완성된 수식은 y = b + Wx +
Utahh(d+Hz)
• y는 |V| 크기의 벡터
• b 도 bias term
learning
• 최종적으로학습해야 할 파라메터는 θ = (b,d,W,U,H,C)
• 학습해야할 파라메터 수는 |V|에 비례
• |V |(nm + h) <- 모델 복잡도
• 학습은 훈련셋의 각 t 번째 단어에 대해서 다음과 같이
stochastic gradient descent 를 반복적으로 수행
• 학습느림
• softmax 예측할때마다 모든 단어 스캔 15
16.
word2vec
• bengio모델(2003) 이후, 많은 변형 연구
• 최근(2013), bengio 모델의 학습은 매우 느리므로, Mikolov(@google)가 변형 모델을 제
안
• skip-gram model
• cbow model
• dense한 행렬 곱셉 연산을 포함하지 않아서 학습이 굉장히 효율적
• 1000억 단어(|V|가 아니라)로 이루어진 시퀀스 학습 시 싱글 컴퓨터에서 하루도 안걸
림
• 추가적으로 학습을 빠르게 하는 여러가지 추가 기법이 들어감
• Negative Sampling : 정답이 아닌 비정답셋을 샘플링해서 훈련셋과 같이 보여준다.
• Hierarchical Softmax: 예측 수식 y의 Softmax의 분모를 구하는 것이 어려움을 해소
• 모든 단어 |V| 에 대해서 구하지 않고, 출력층을 단어 계층의 이진 트리로 표현해서
랜덤워크하면서 log(|V|)만으로 softmax를 근사함
• Subsampling of Frequent Words: 많이 나오는 단어는 다운 샘플링해서 모델에게 보
여준다
• https://code.google.com/p/word2vec/
16
17.
CBOW(Continuous Bag Of
Words)
• 문서를 순차적으로 학습하지만, 현재 단어 예측시
사용되는 Context는 bag of words
• bengio 모델과는 달리 단어의 앞도 사용
17
word2vec 메뉴얼
•architecture: skip-gram (slower, better for infrequent words) vs
CBOW (fast)
• the training algorithm: hierarchical softmax (better for
infrequent words) vs negative sampling (better for frequent
words, better with low dimensional vectors)
• sub-sampling of frequent words: can improve both accuracy
and speed for large data sets (useful values are in range 1e-3
to 1e-5)
• dimensionality of the word vectors: usually more is better, but
not always
• context (window) size: for skip-gram usually around 10, for
CBOW around 5 22




















![[F2]자연어처리를 위한 기계학습 소개](https://cdn.slidesharecdn.com/ss_thumbnails/f2-120919022113-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)








![[study] character aware neural language models](https://cdn.slidesharecdn.com/ss_thumbnails/181114characterawareneurallanguagemodels-190321063423-thumbnail.jpg?width=640&height=640&fit=bounds)




![[네이버AI해커톤]어떻게 걱정을 멈추고 베이스라인을 사랑하는 법을 배우게 되었는가](https://cdn.slidesharecdn.com/ss_thumbnails/hcc-180801101722-180803135108-thumbnail.jpg?width=640&height=640&fit=bounds)







