Downloaded 69 times





























![Choose Your Own [CAP] Adventure
Consistency
Availability
Partition
Tolerance
Apache
HBase
Berkeley DB
Apache
Cassandra
Scylla DB
Google Cloud
Bigtable](https://image.slidesharecdn.com/p-170621194825/75/Large-Scale-Graph-Analytics-with-JanusGraph-43-2048.jpg)






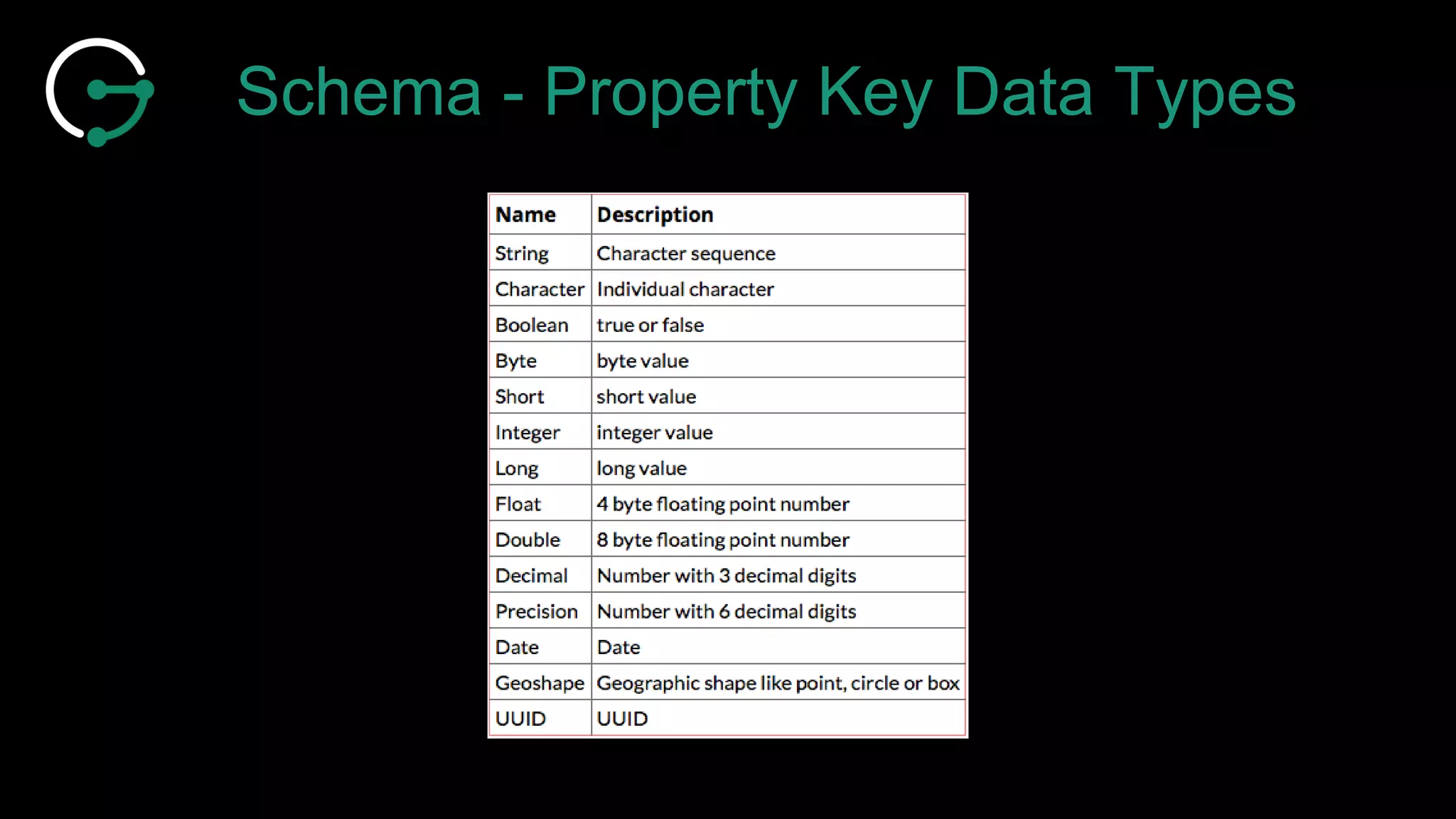



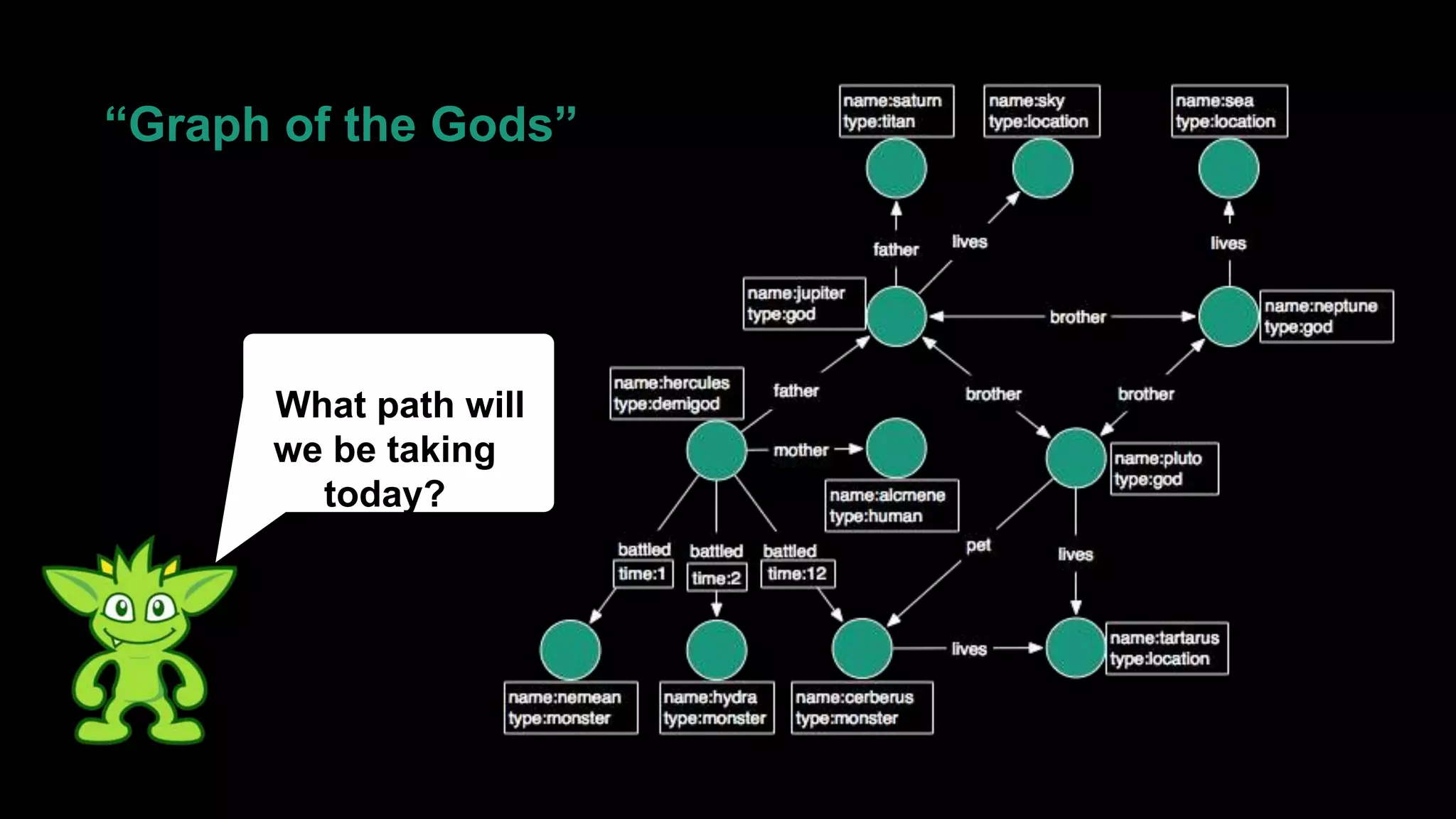
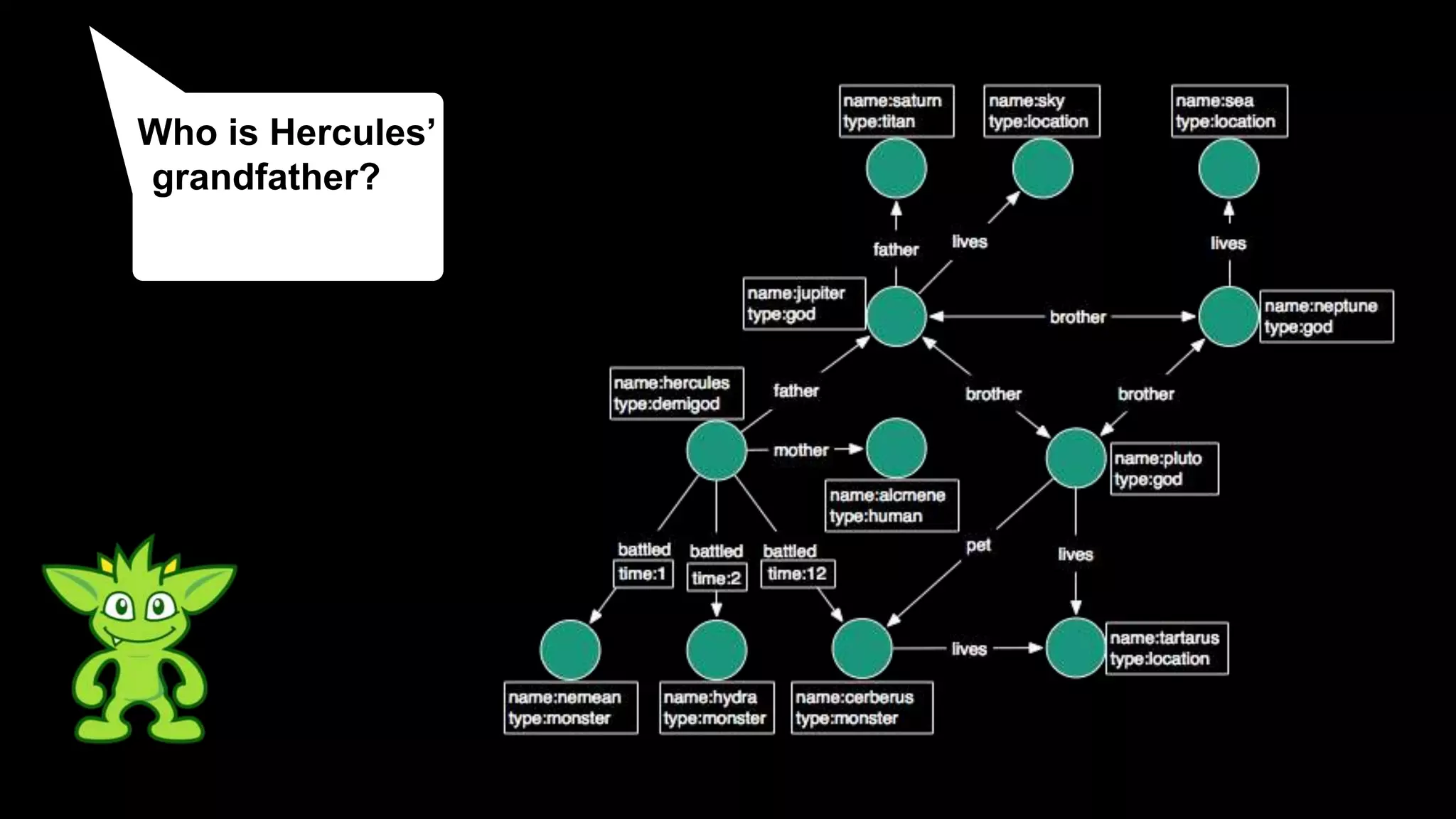
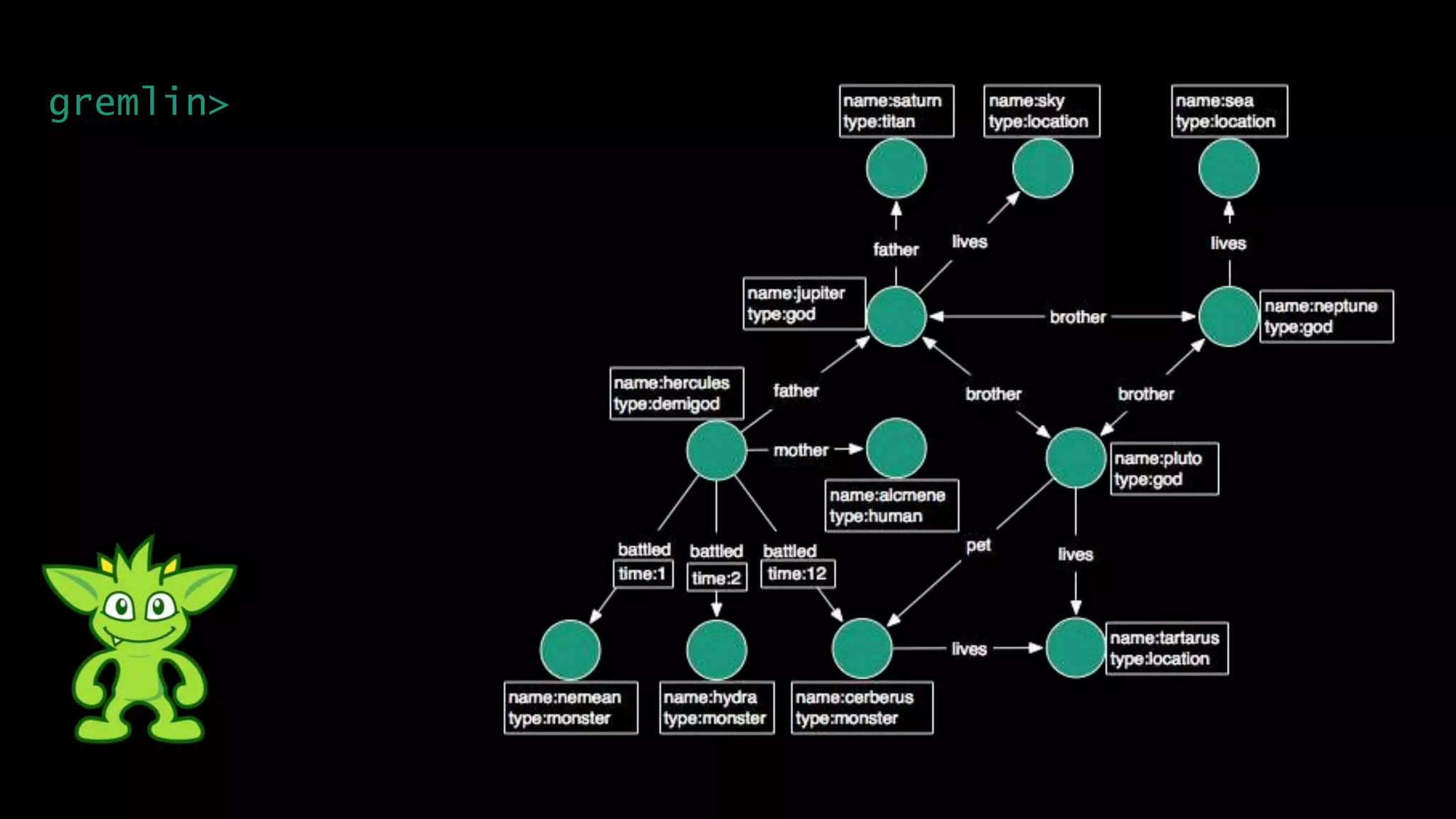
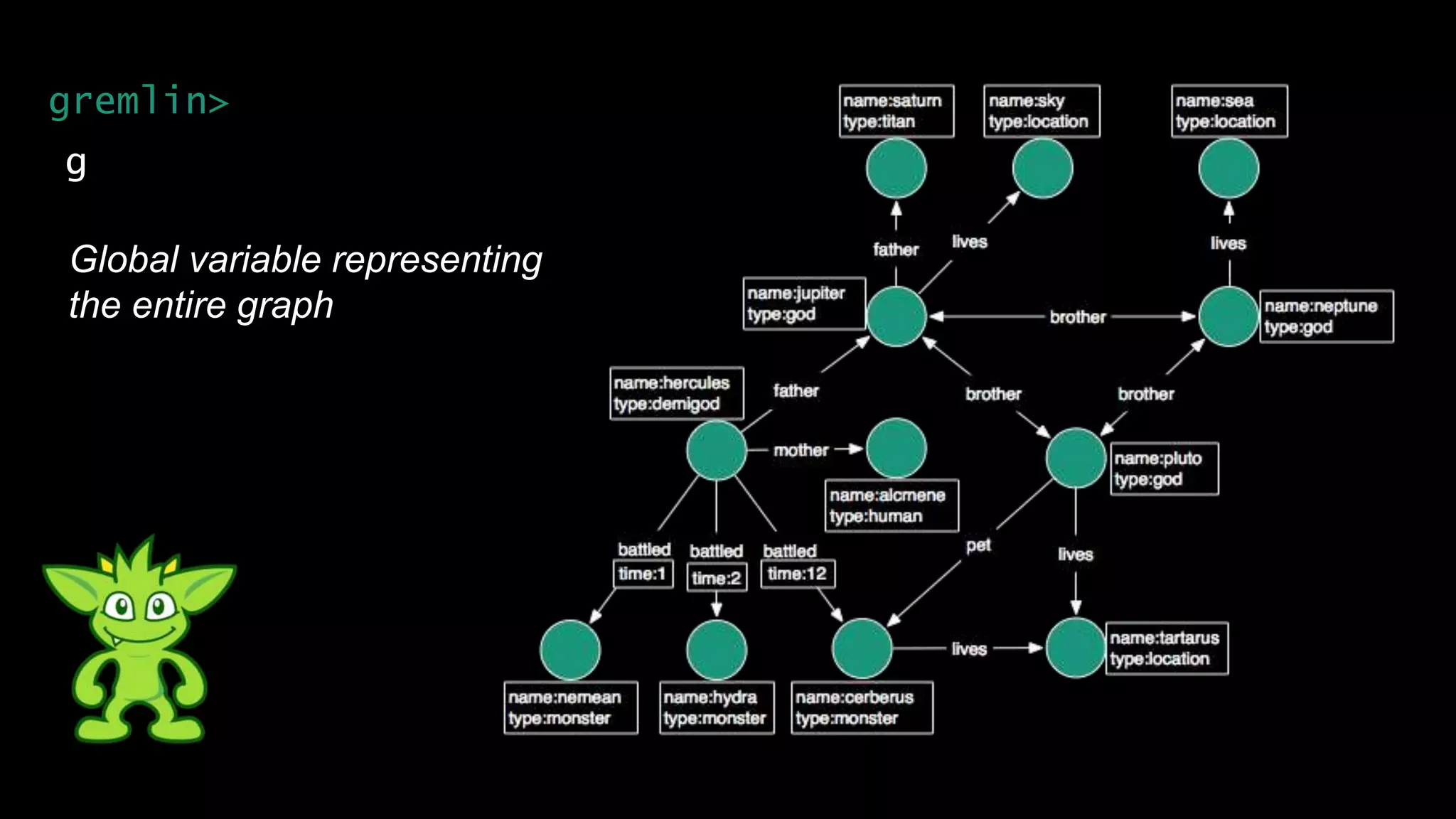
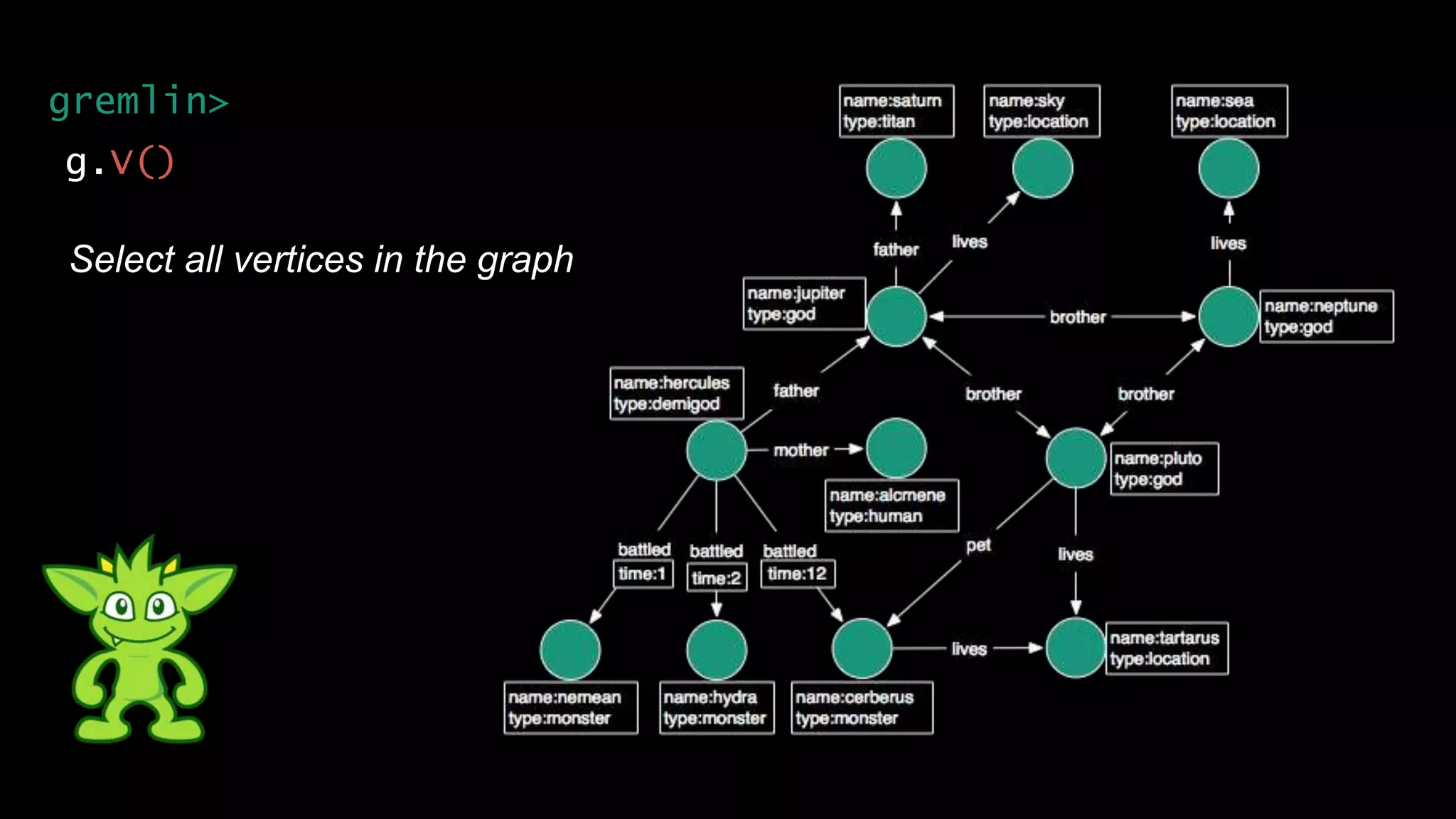
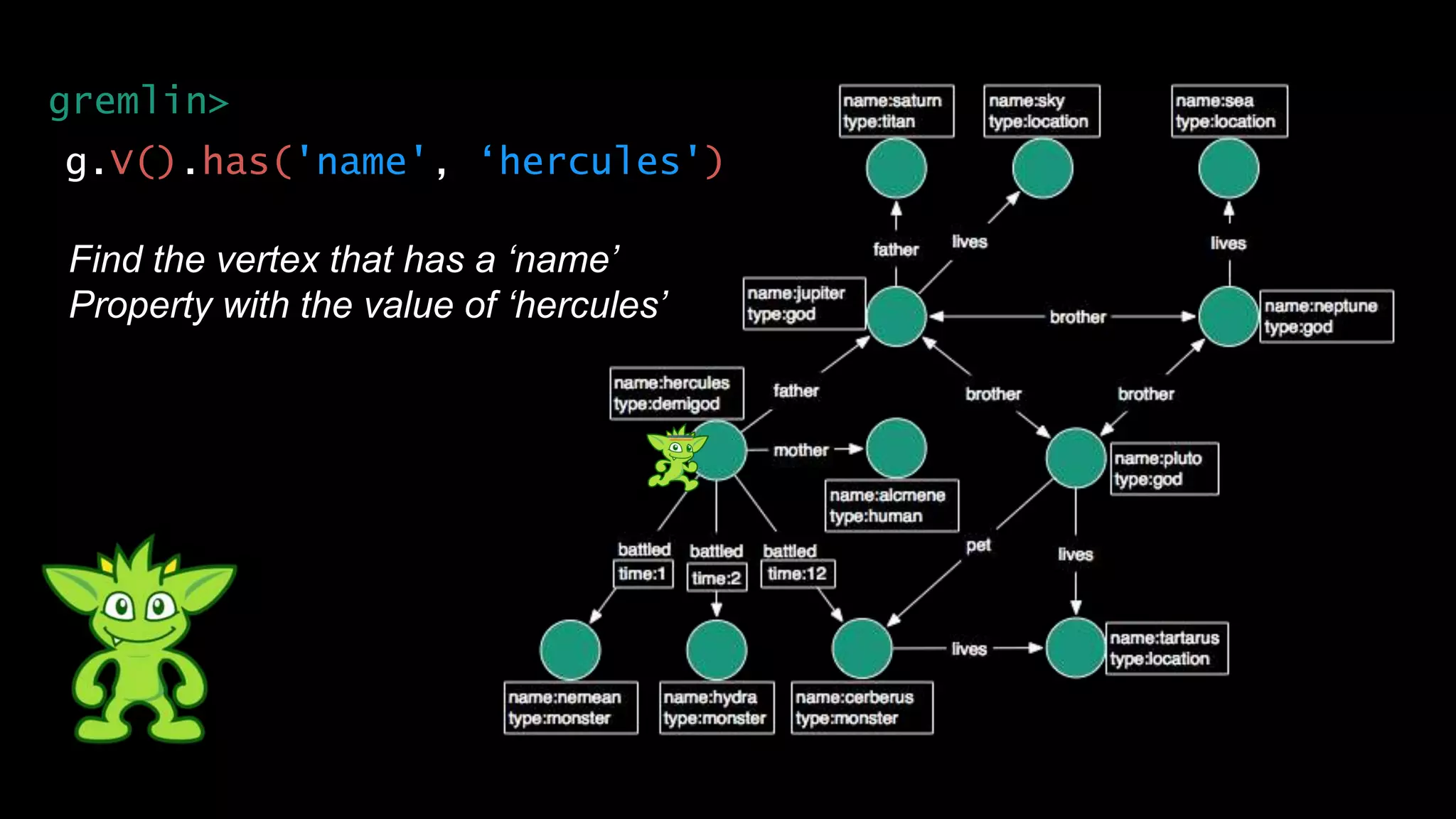
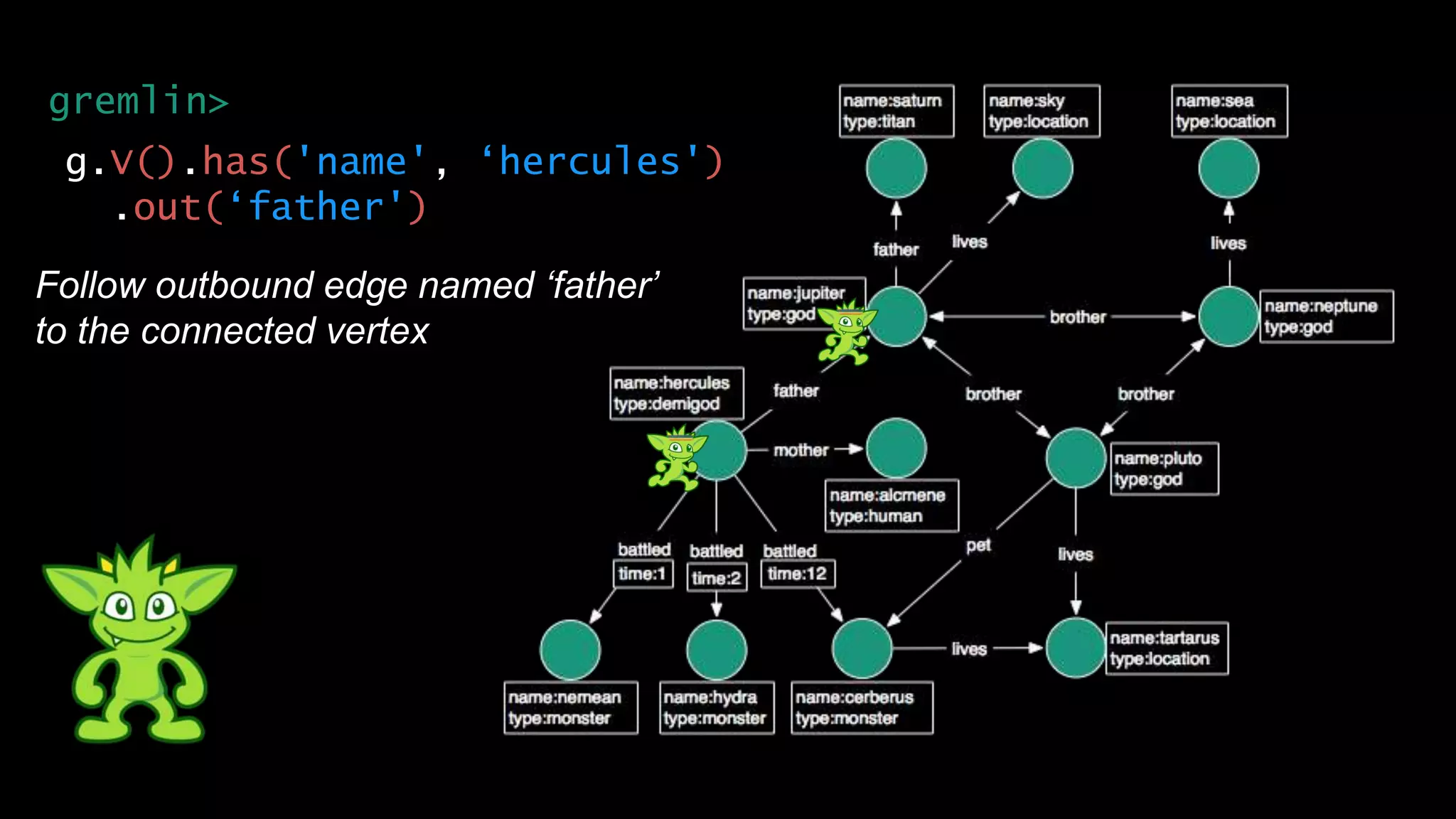
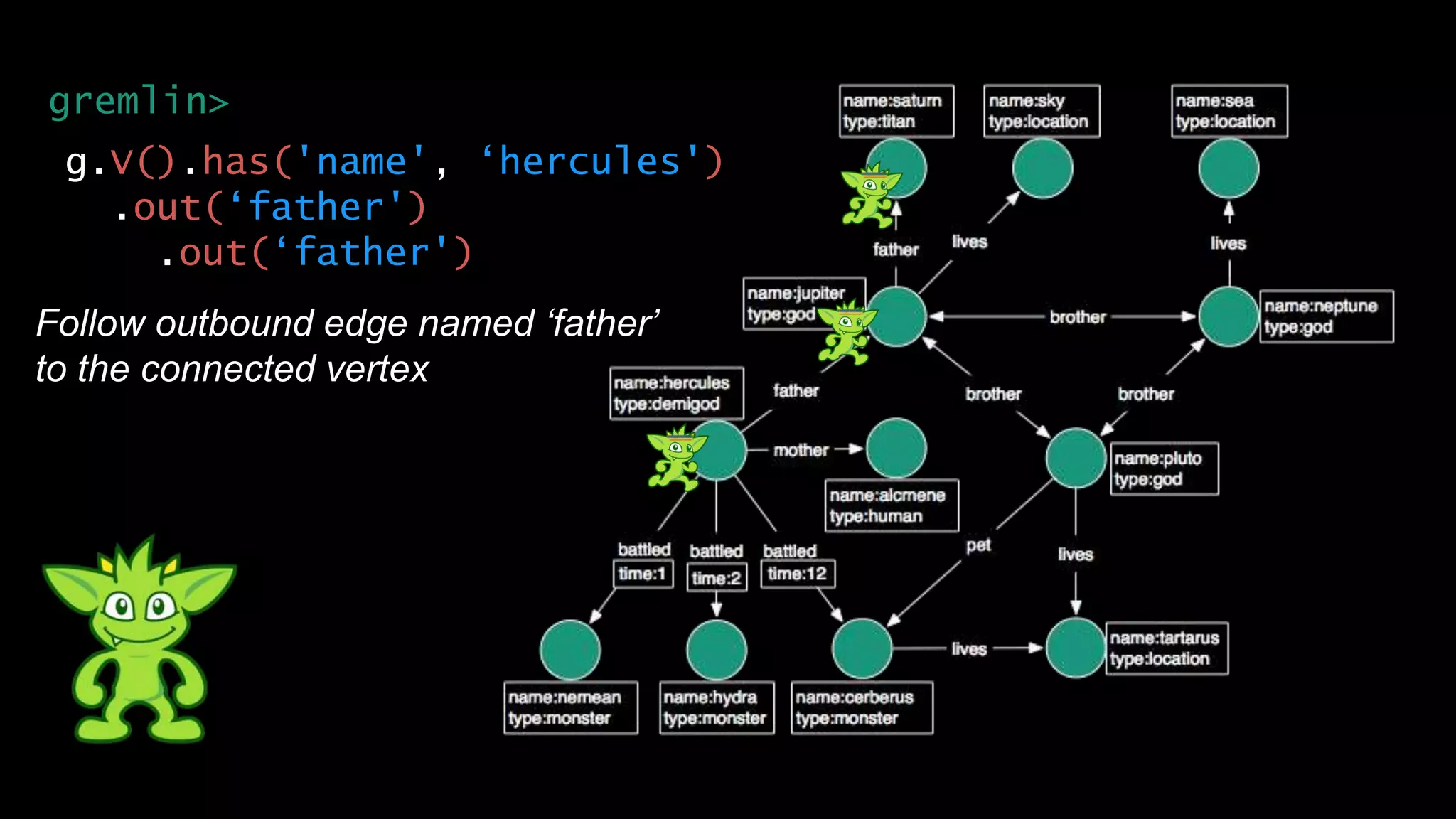
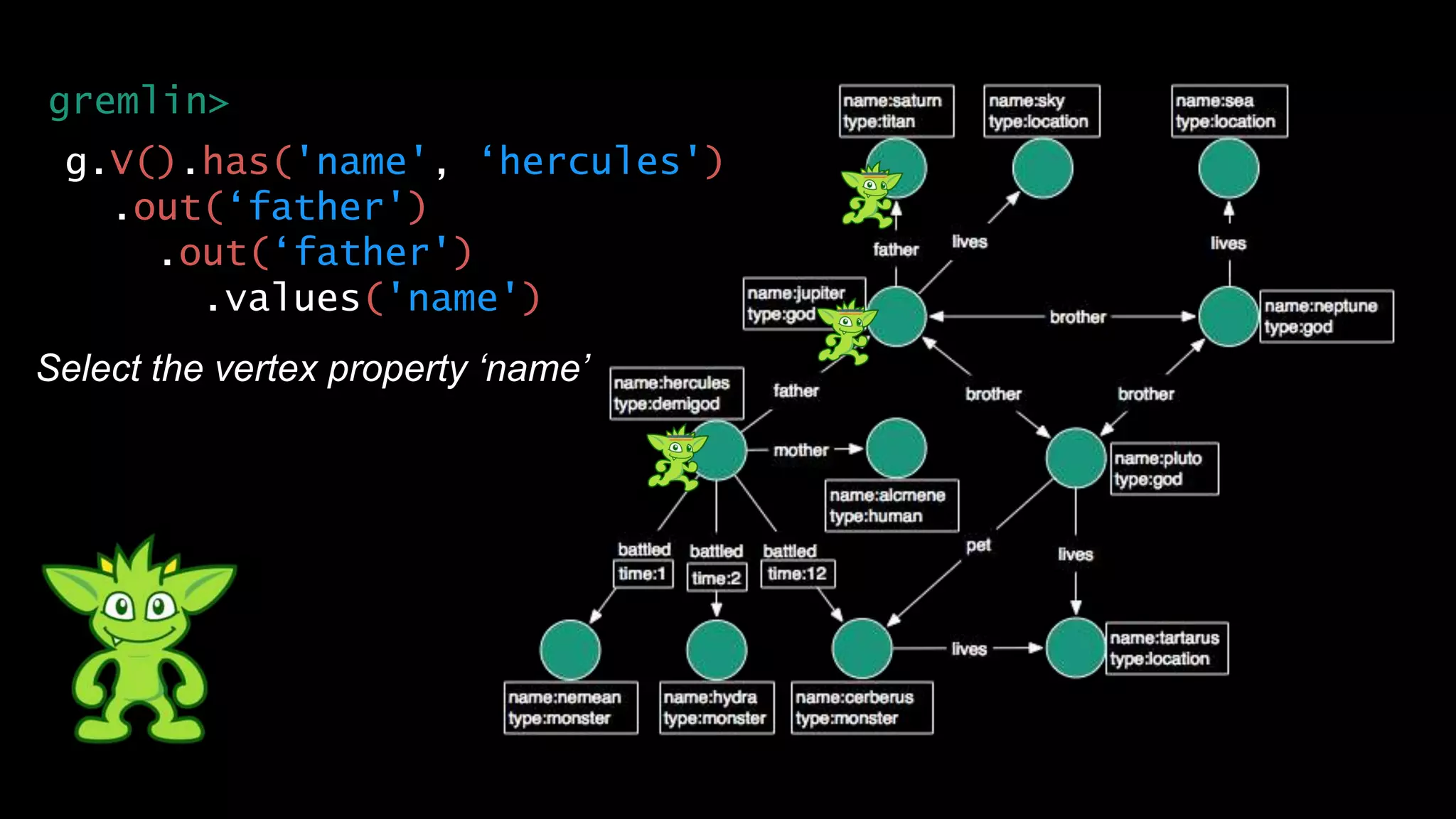

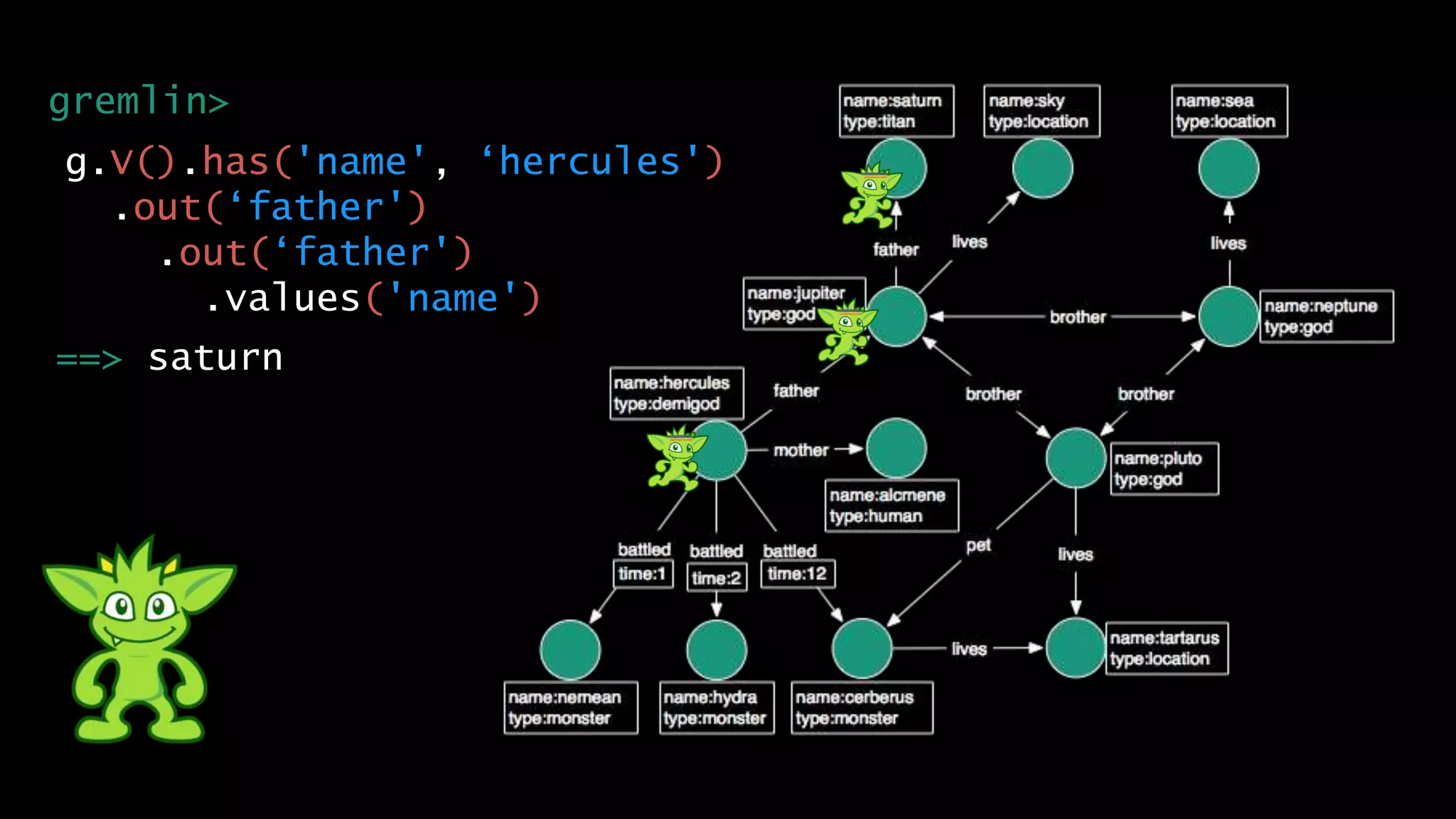




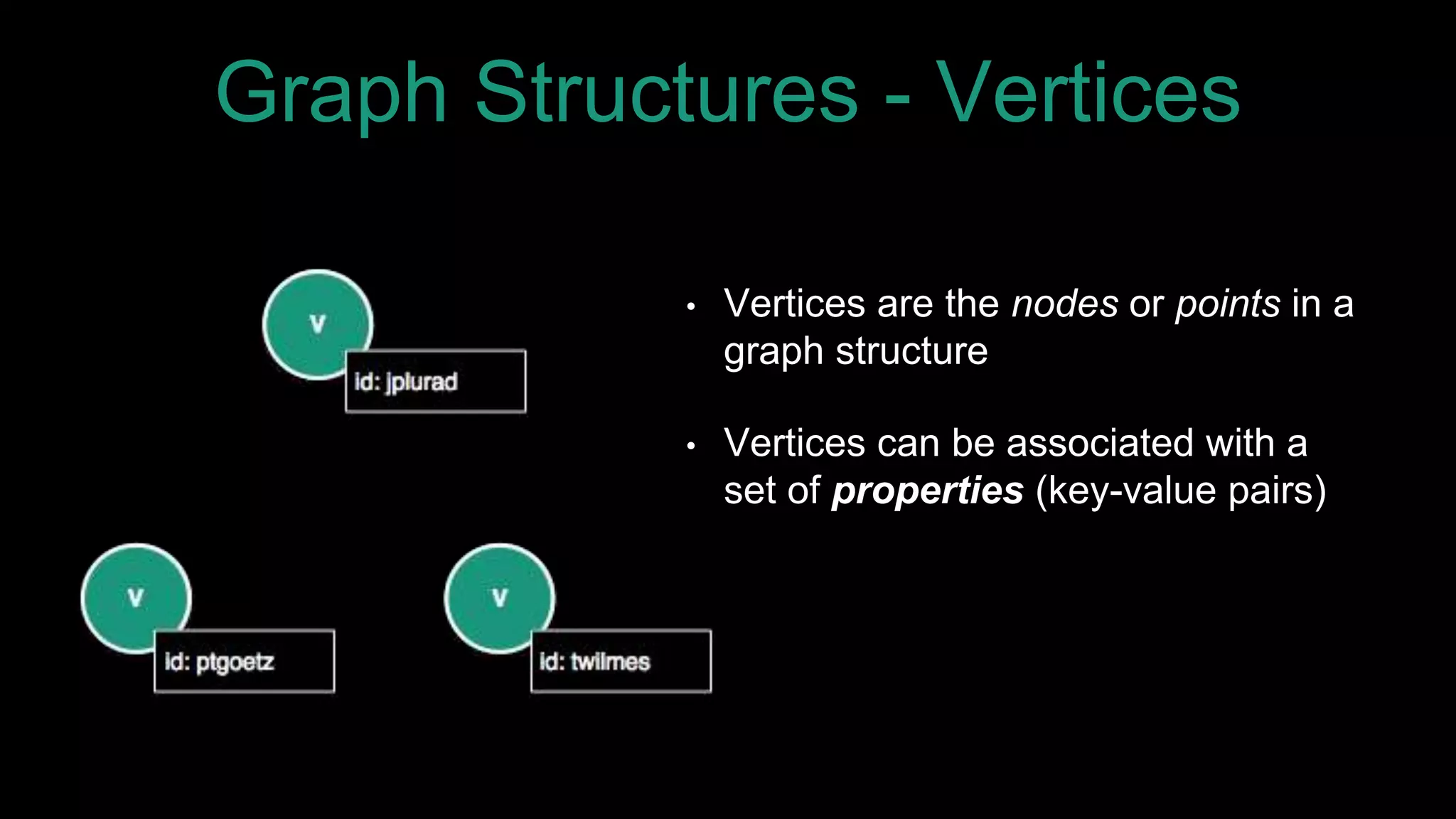
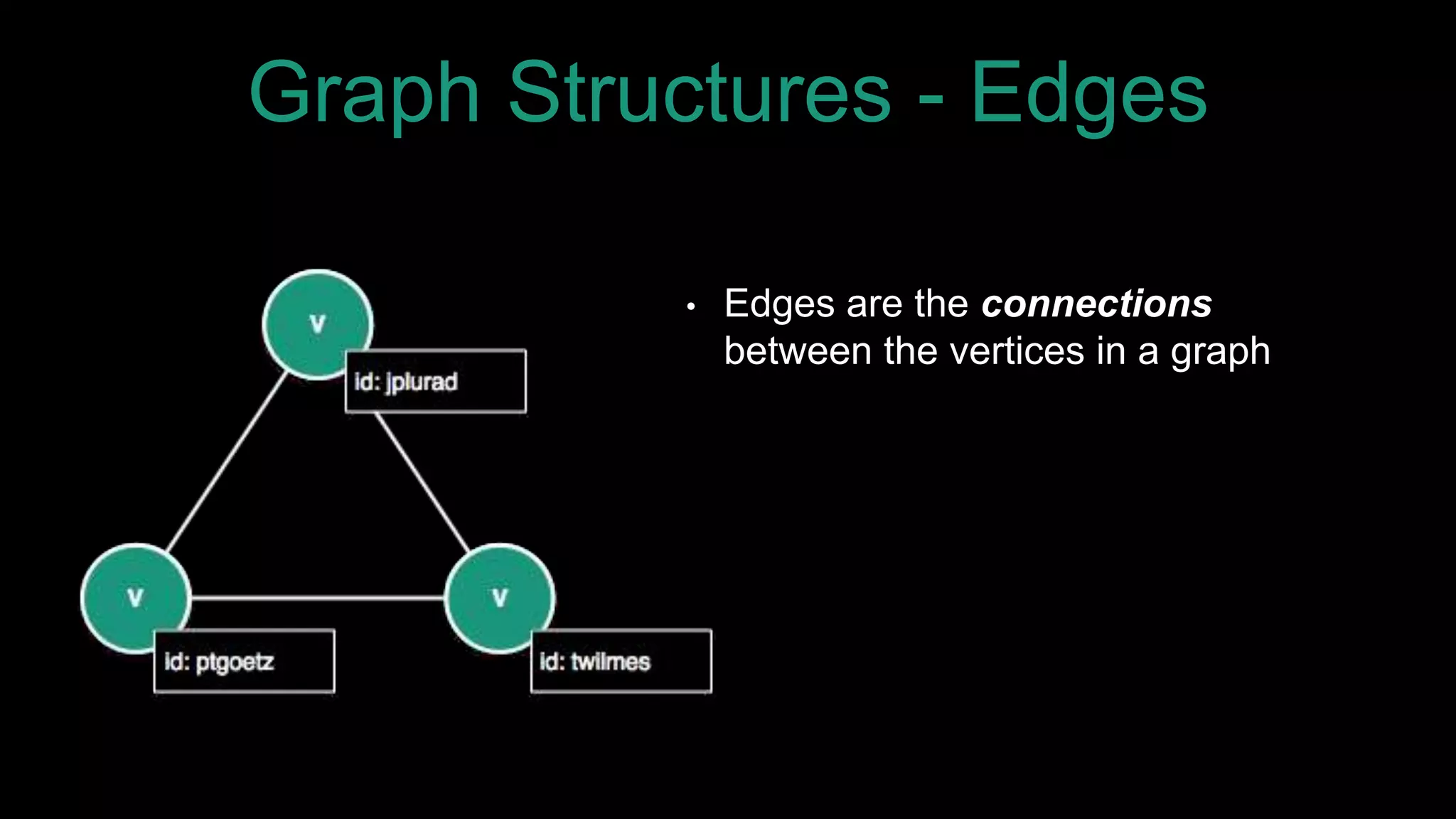
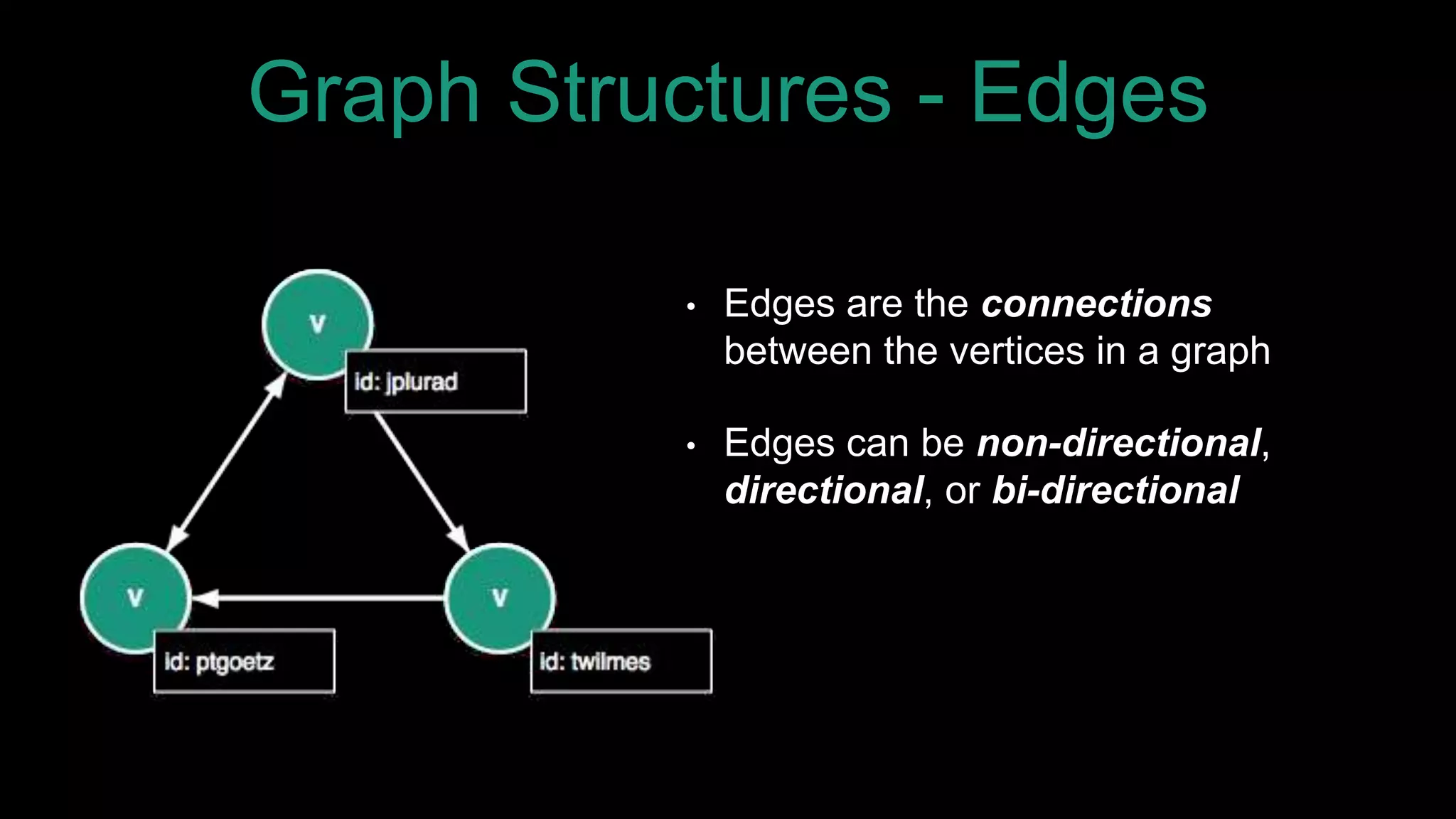
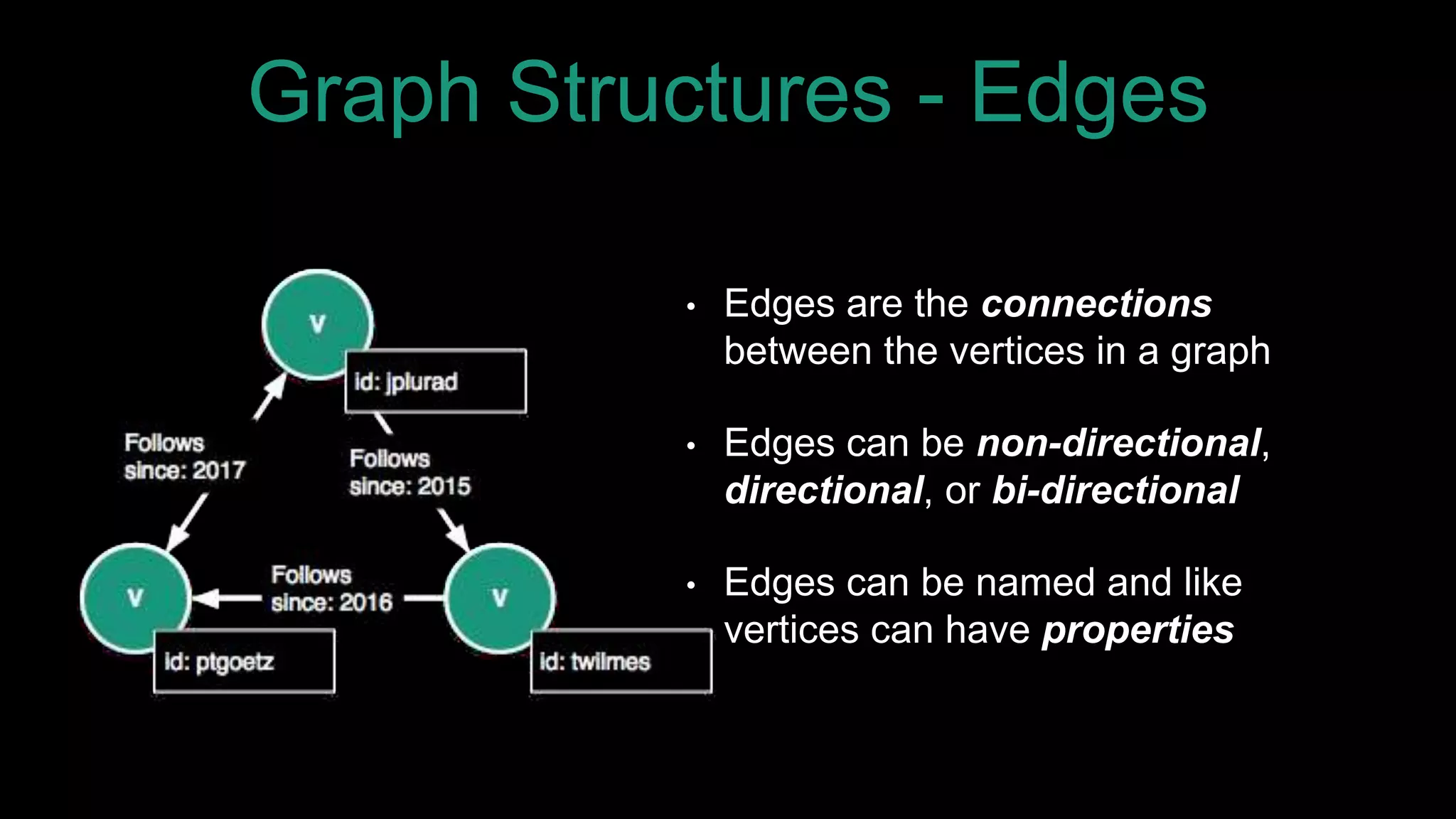
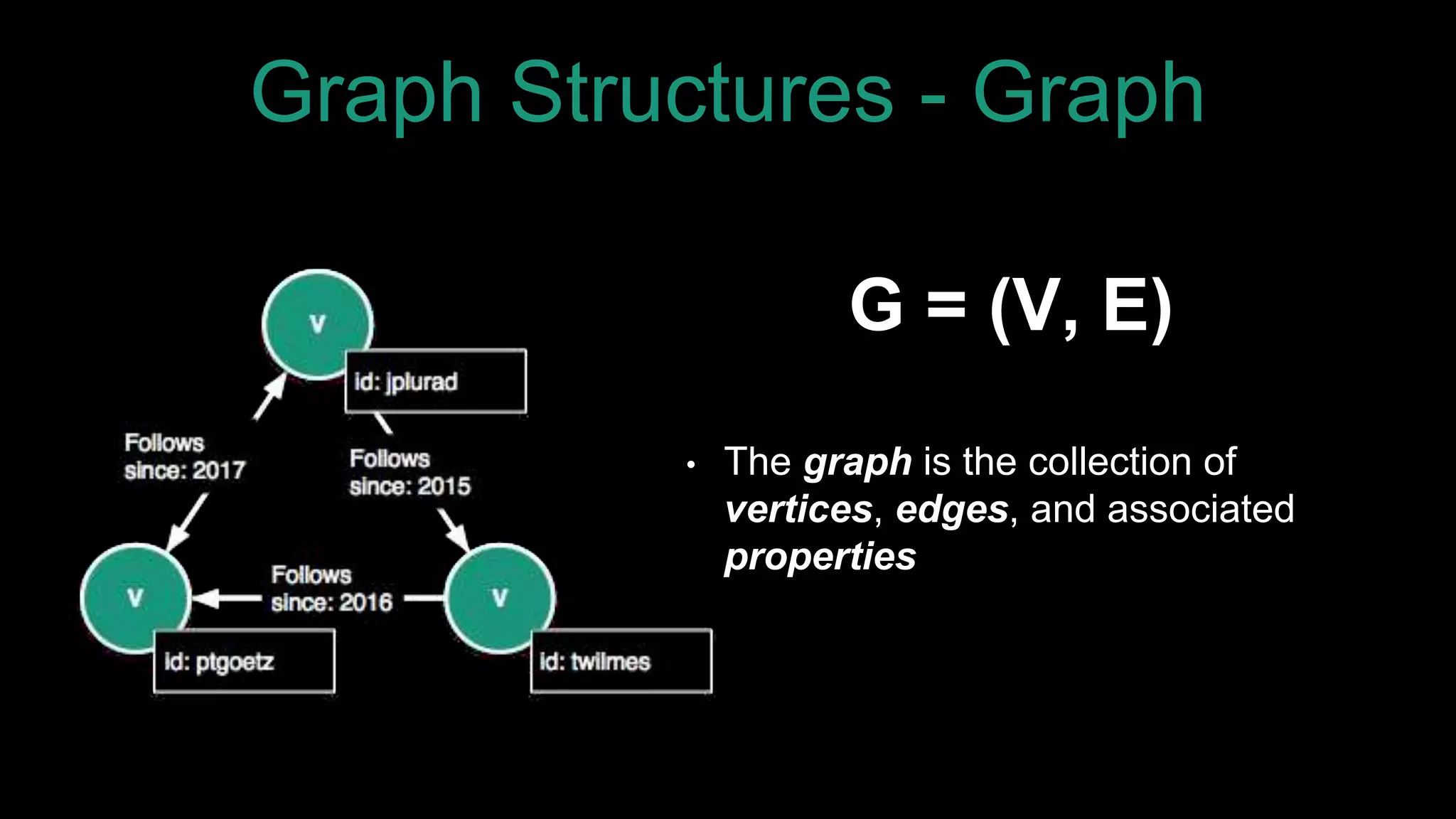
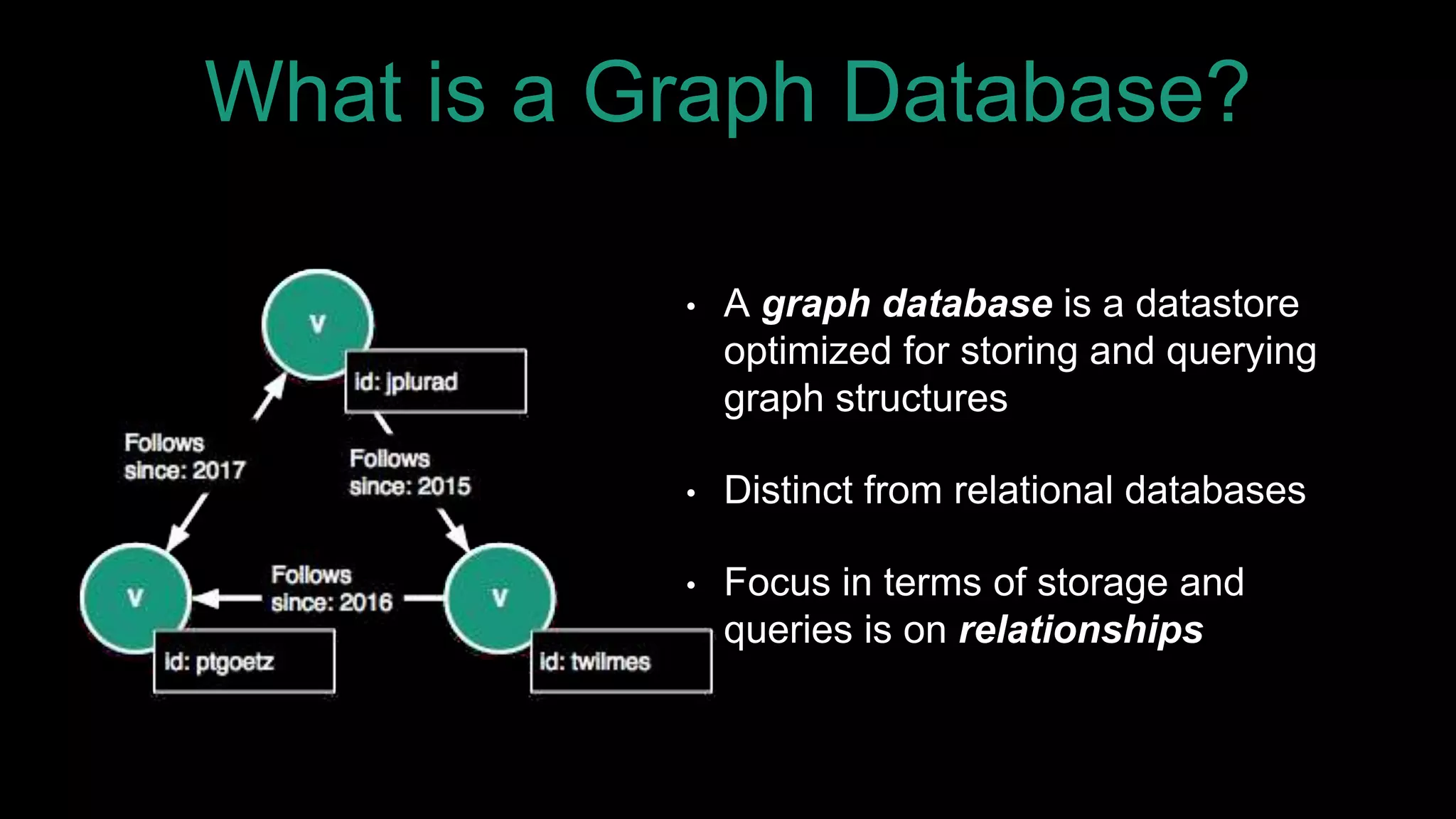
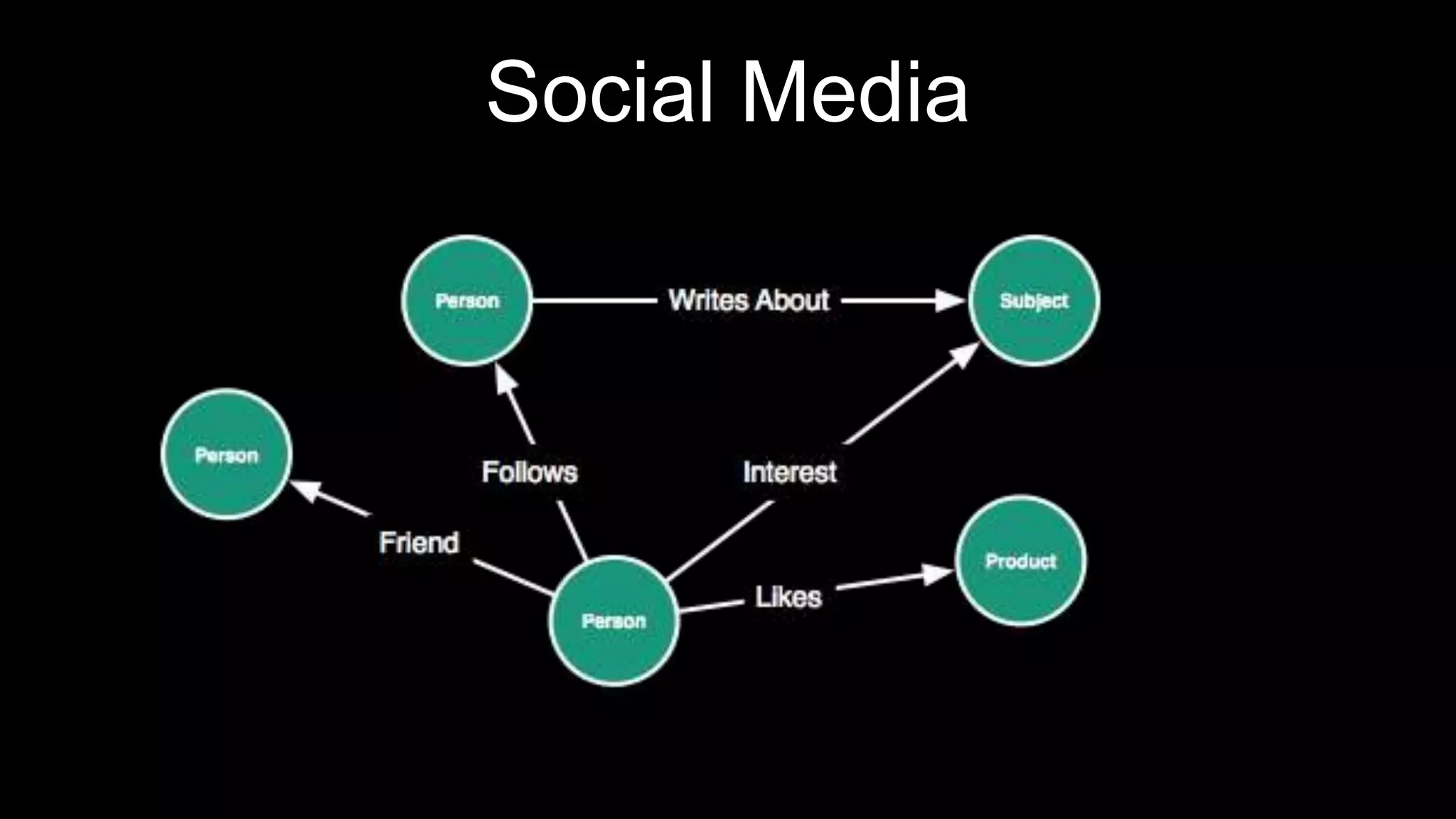
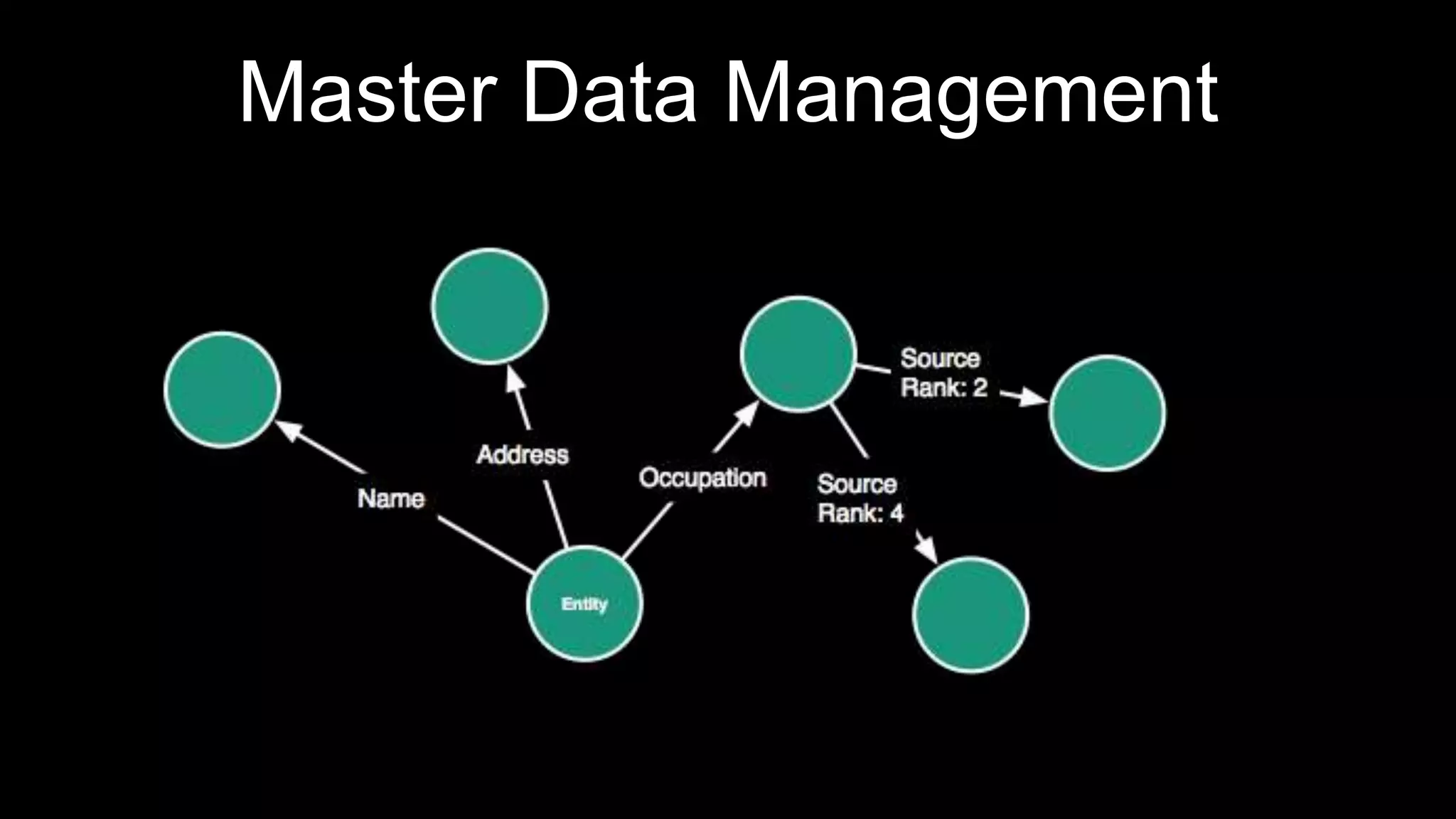
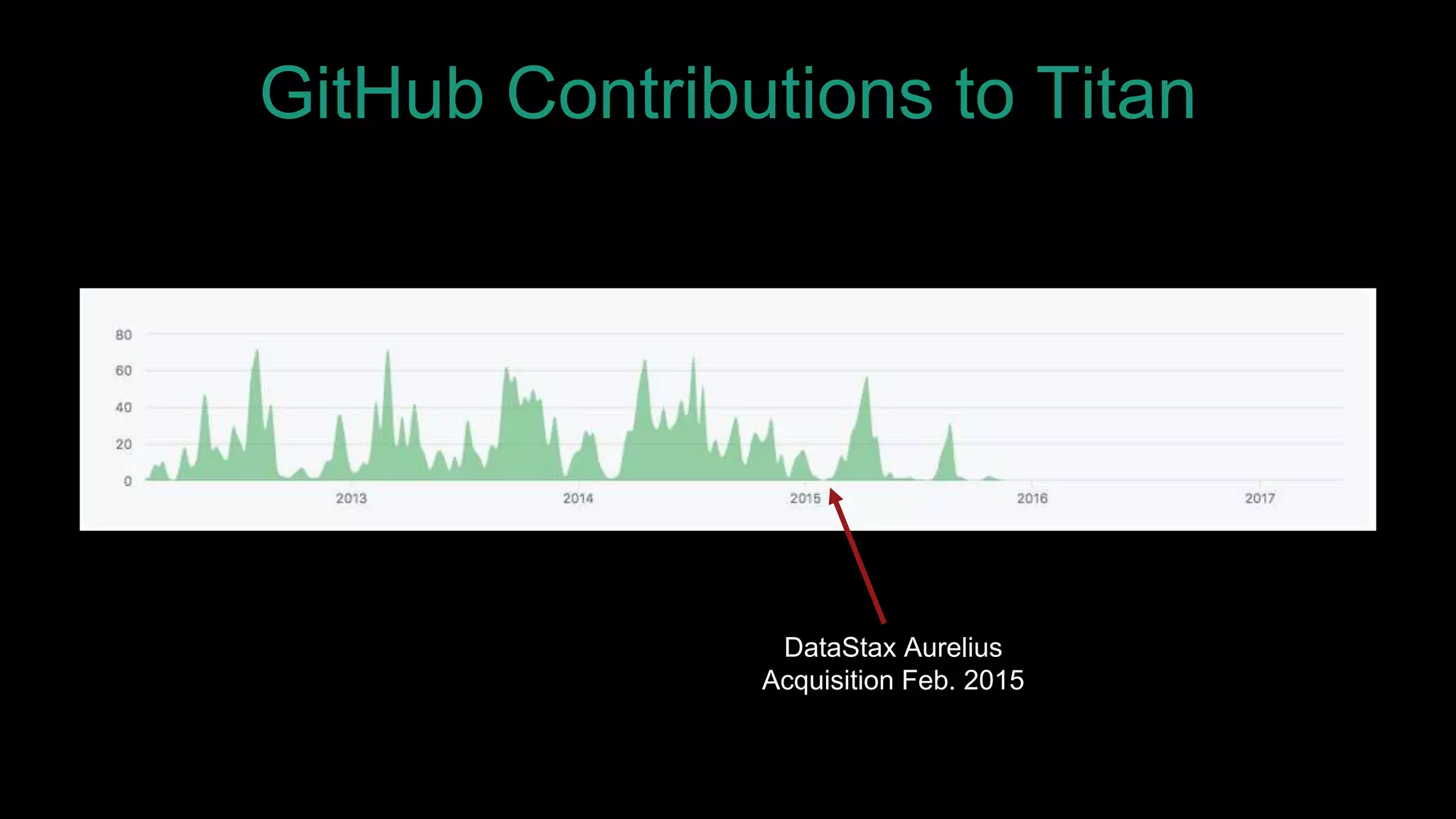
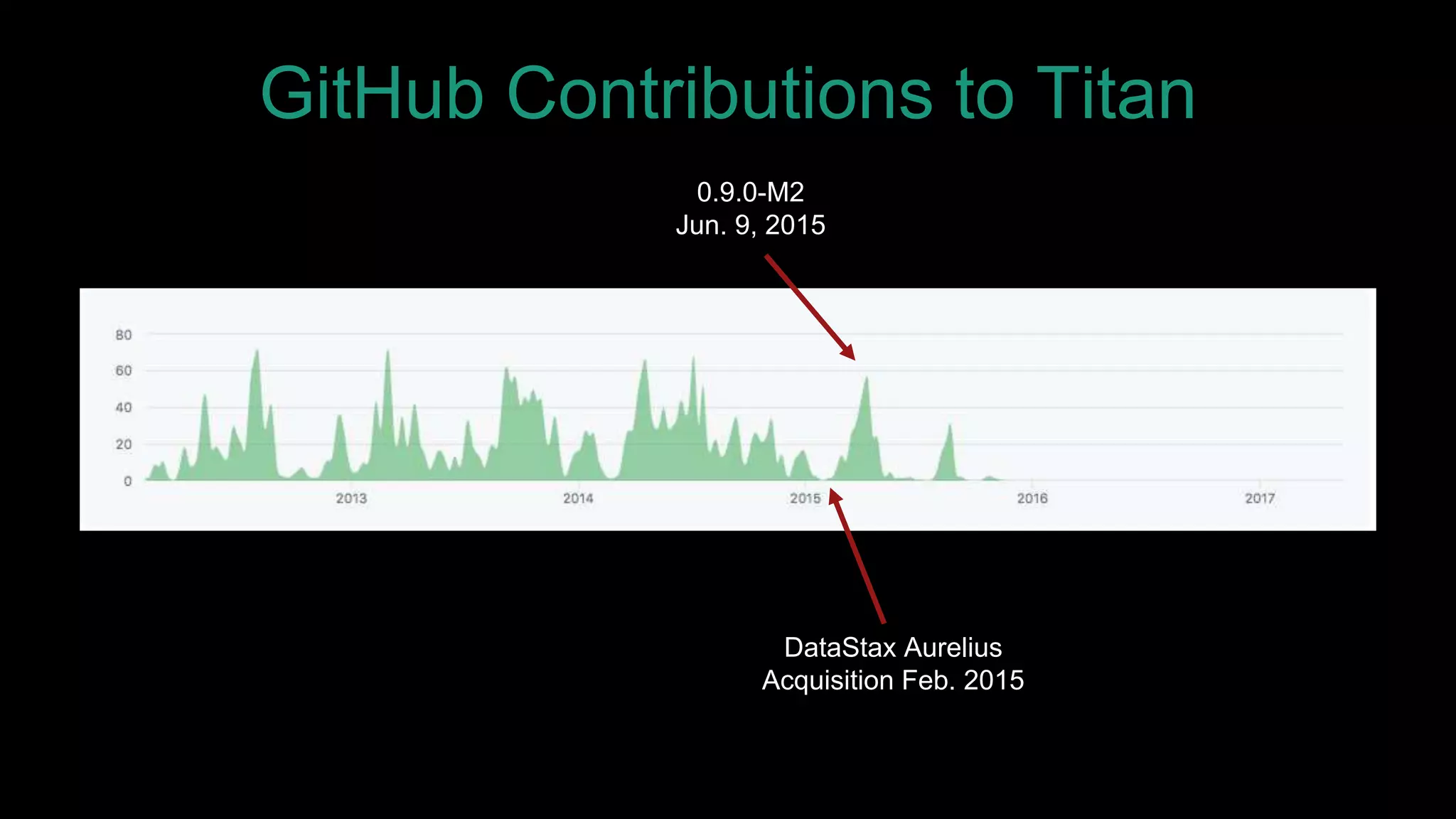
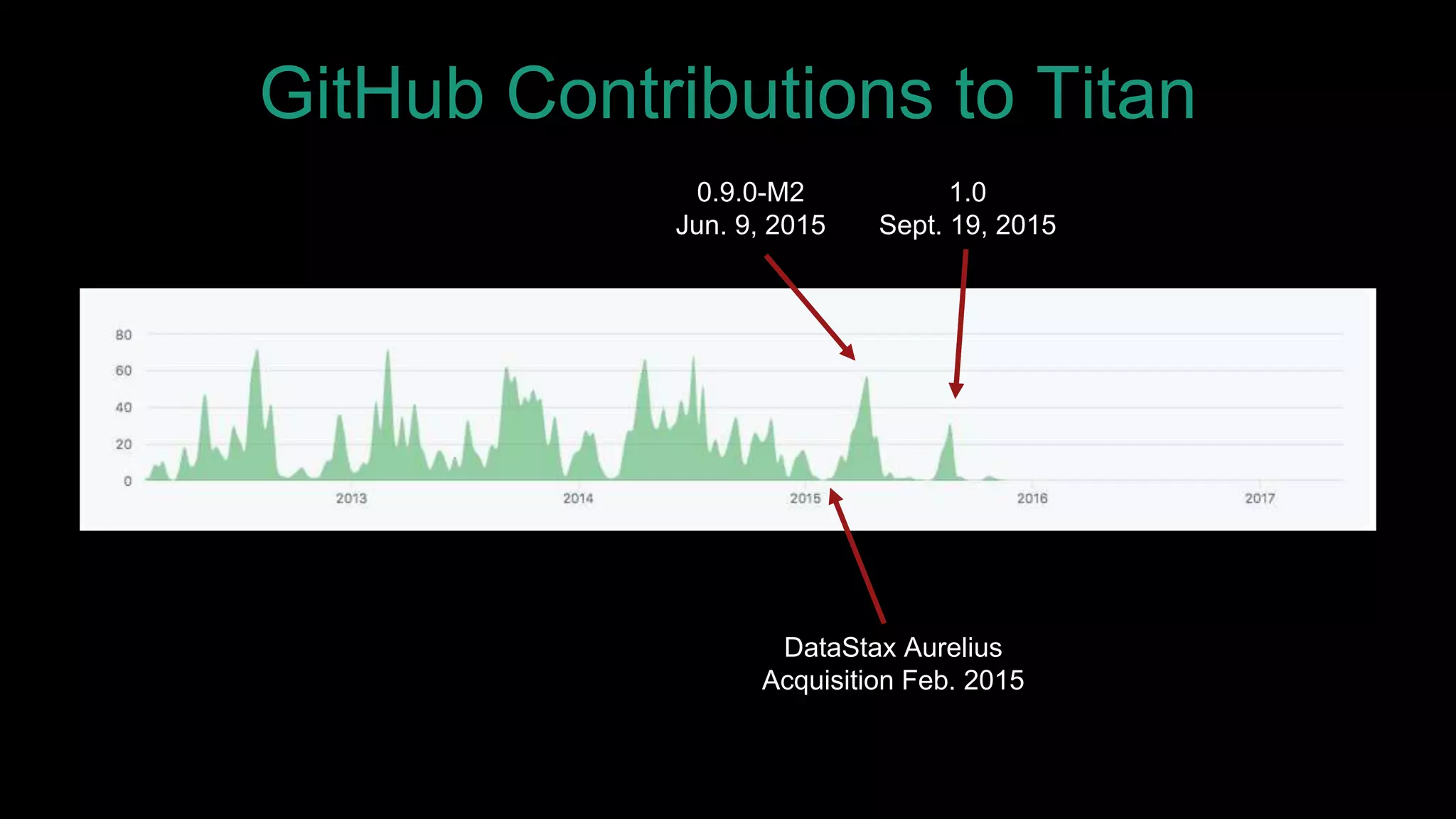
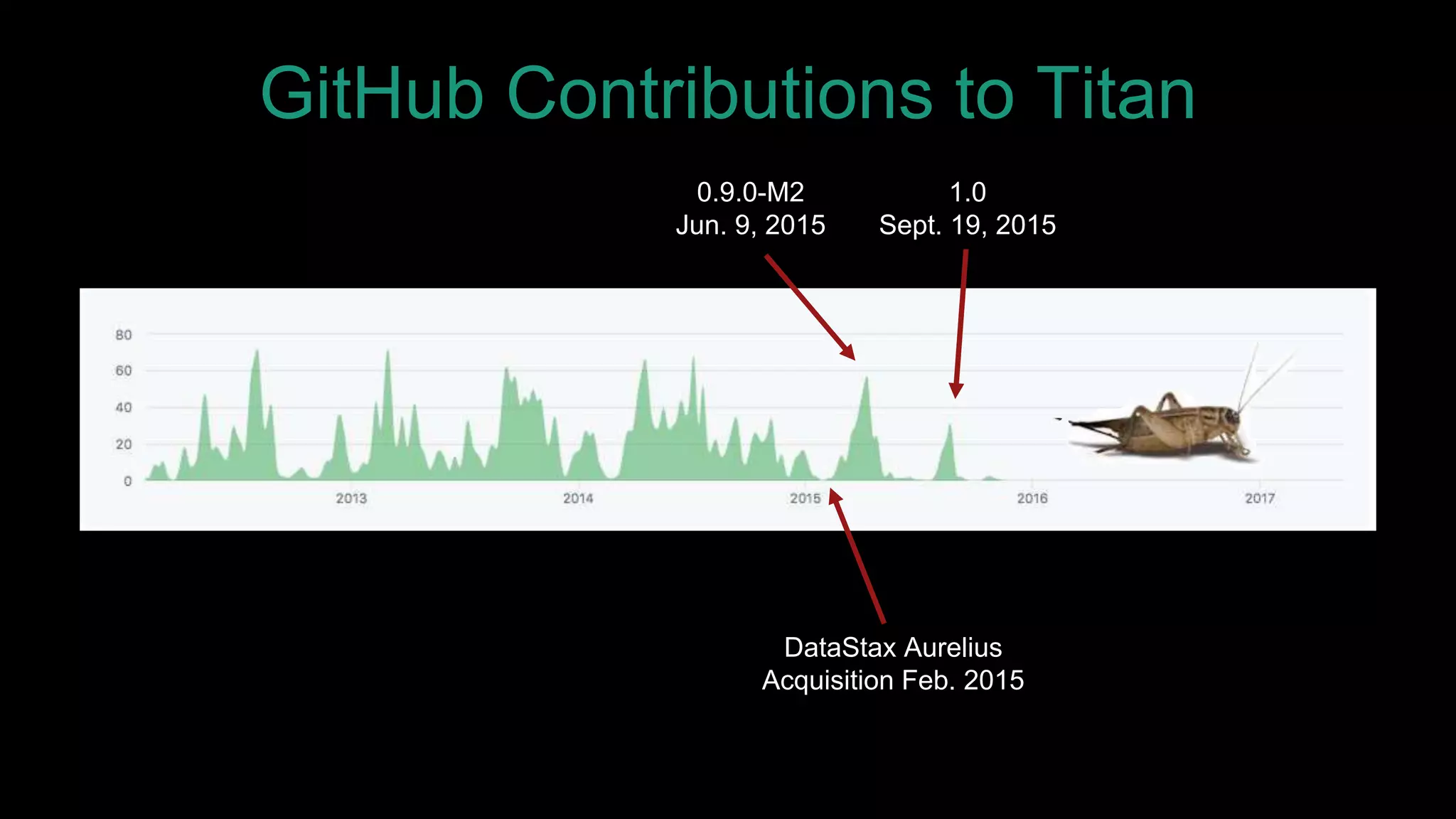
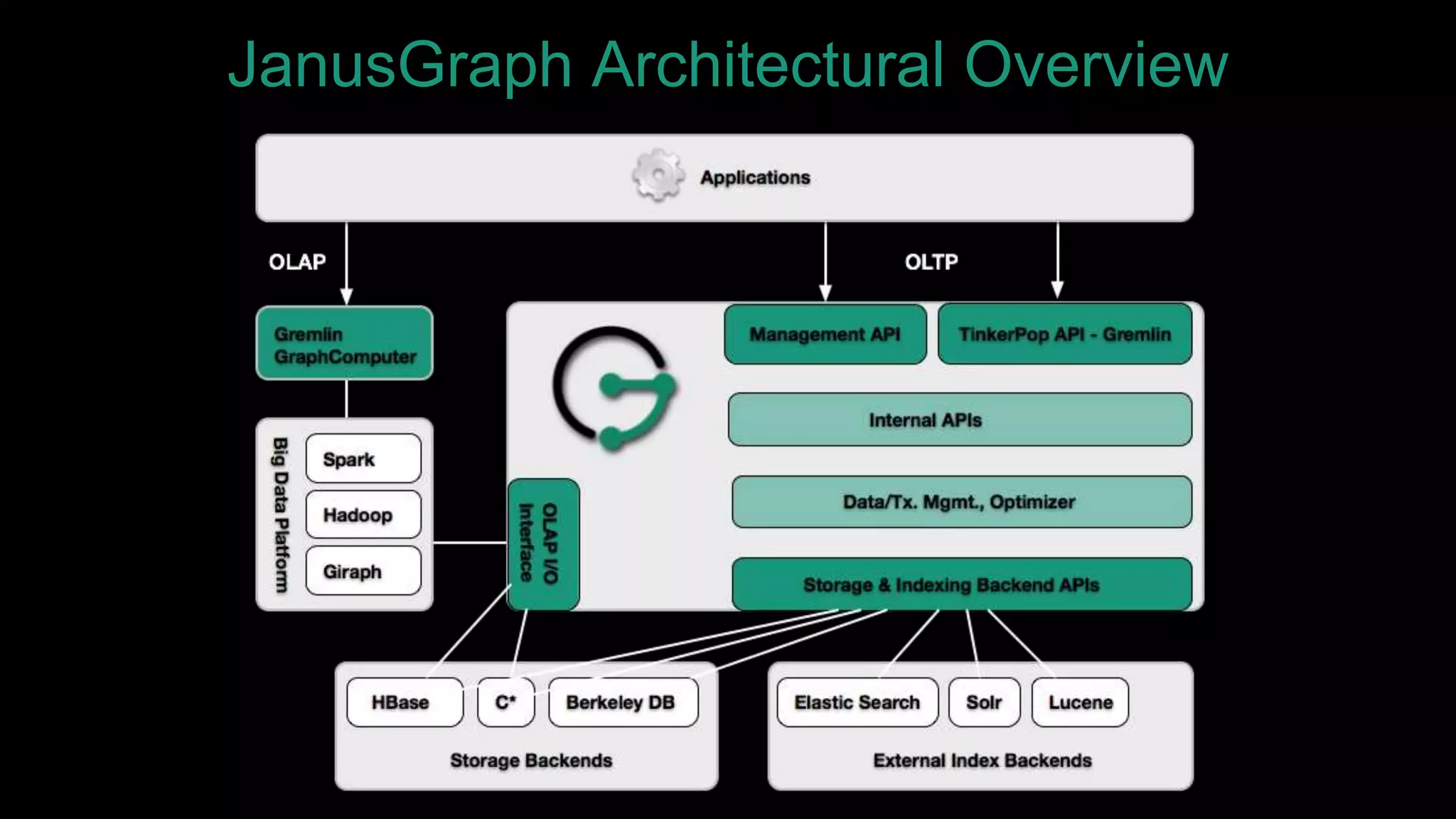
The document discusses large-scale graph analytics and provides an overview of graph databases, particularly focusing on JanusGraph and its architecture. It explains key components such as vertices, edges, and uses in various applications like social networks and fraud detection. Furthermore, it outlines the technical aspects of JanusGraph, including storage backends, schema evolution, and the Gremlin query language for graph traversal.



![[오픈소스컨설팅] EFK Stack 소개와 설치 방법](https://cdn.slidesharecdn.com/ss_thumbnails/elasticstack-210712042246-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[오픈테크넷서밋2022] 국내 PaaS(Kubernetes) Best Practice 및 DevOps 환경 구축 사례.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/2022paaskubernetesbestpracticedevops-220927105318-84776c9a-thumbnail.jpg?width=640&height=640&fit=bounds)




























































