

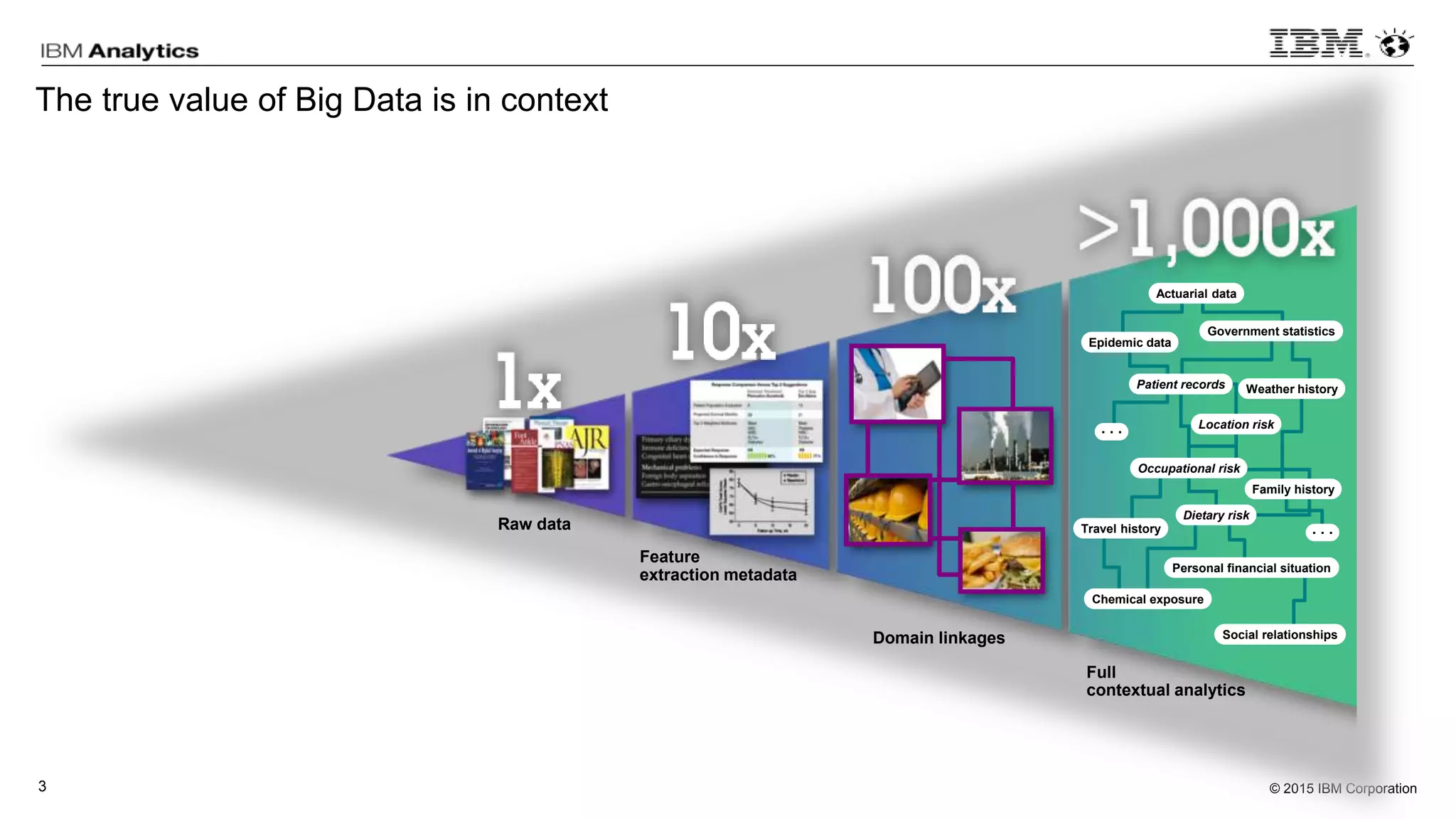
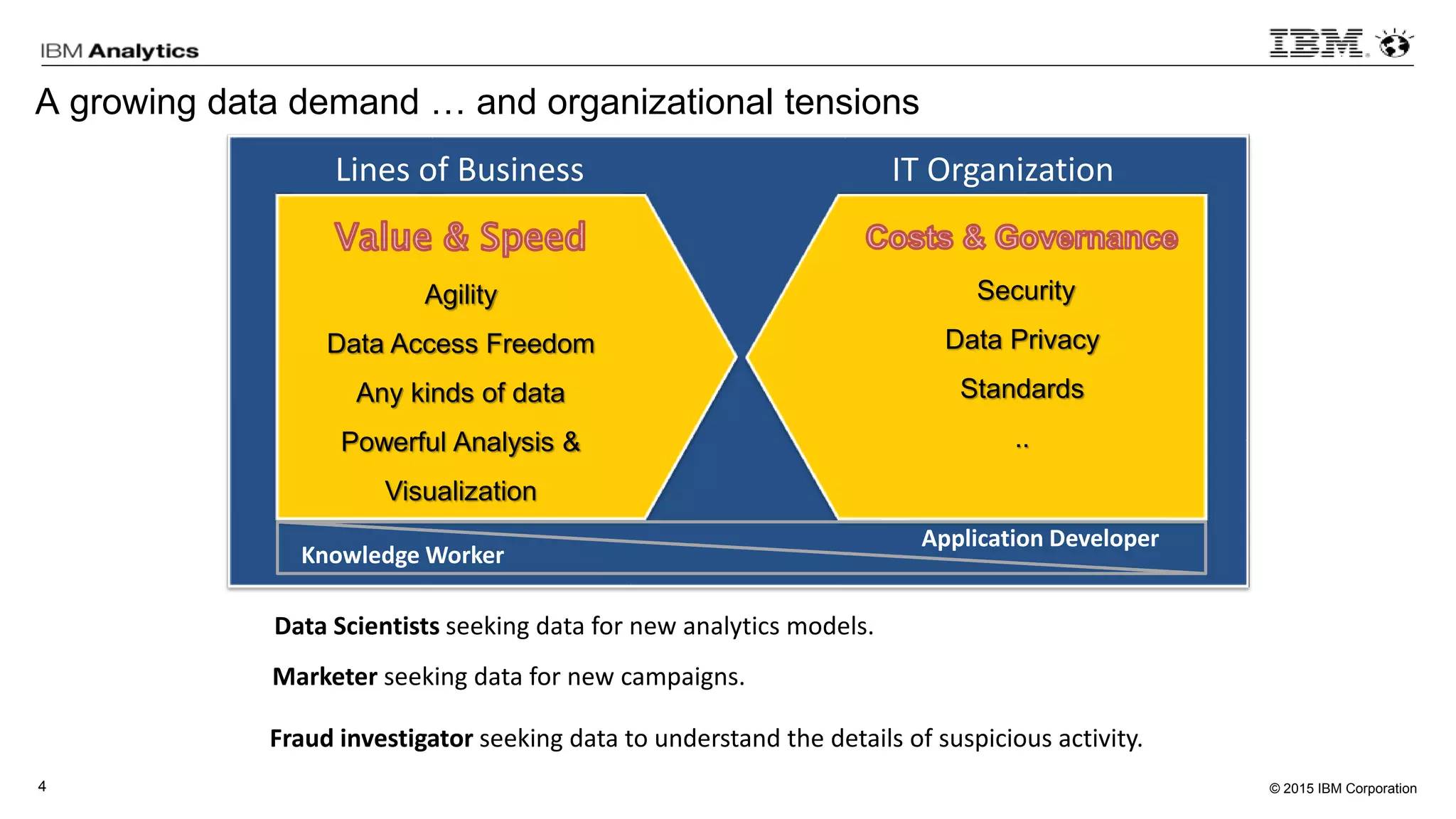

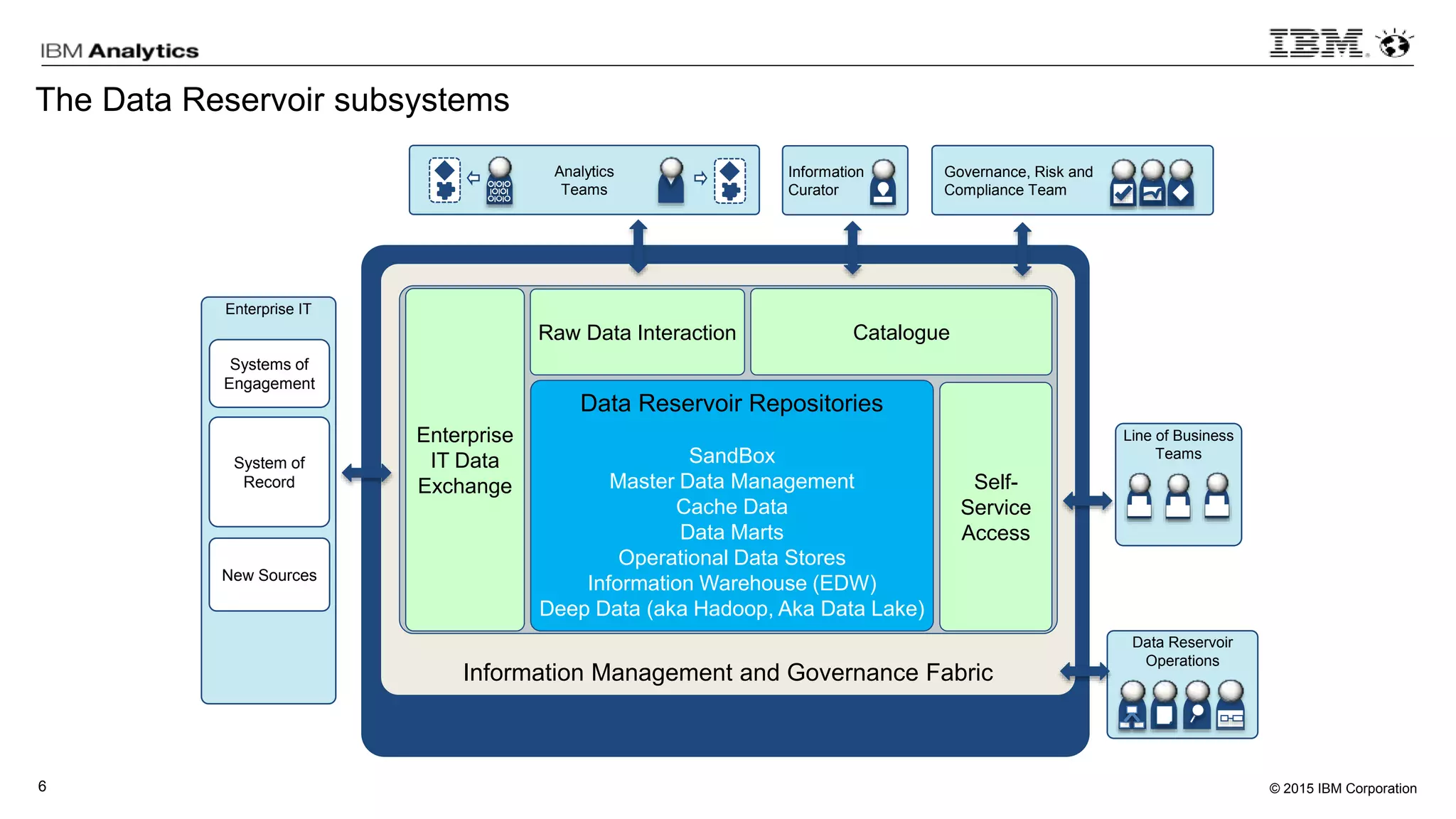
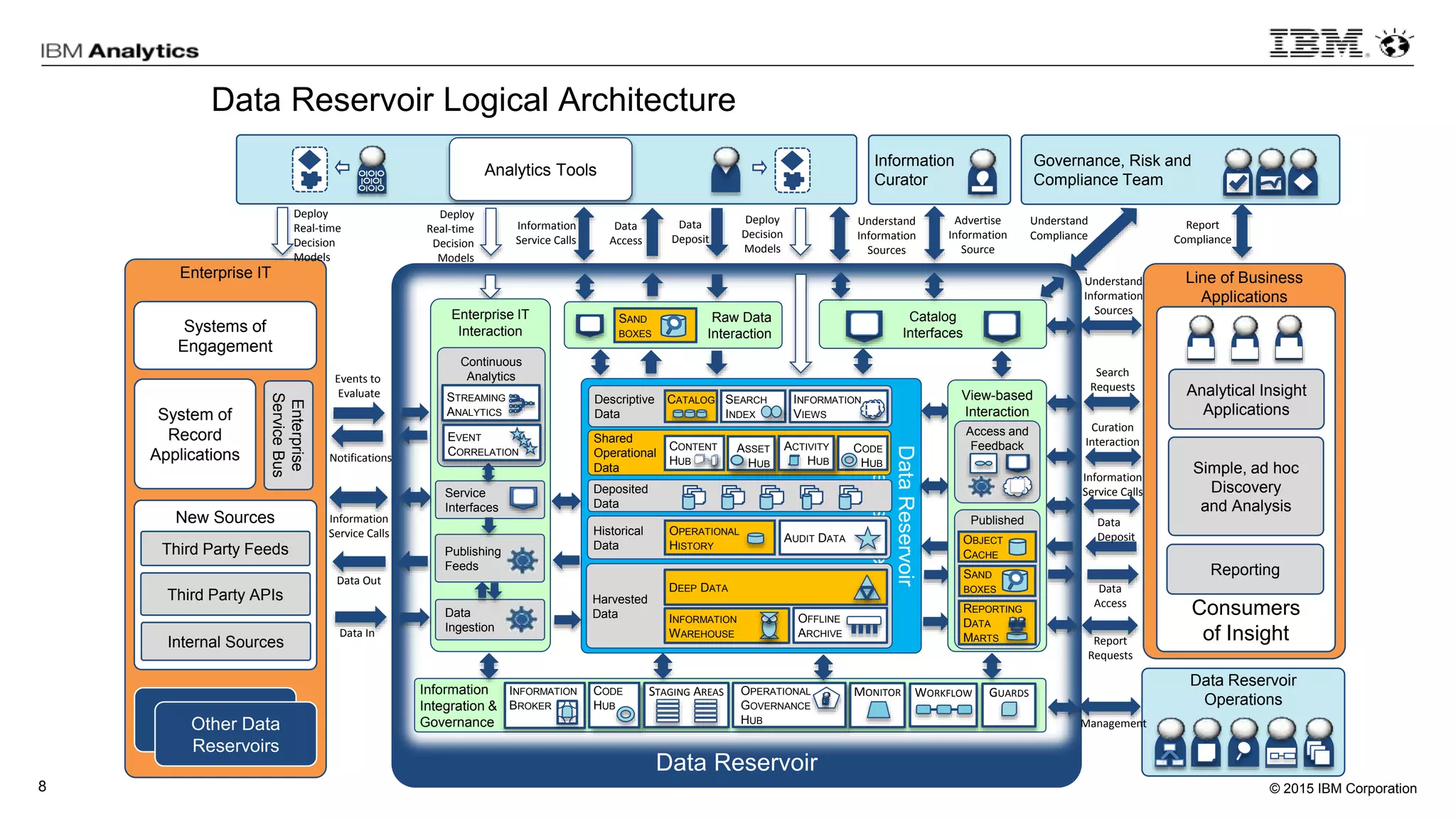

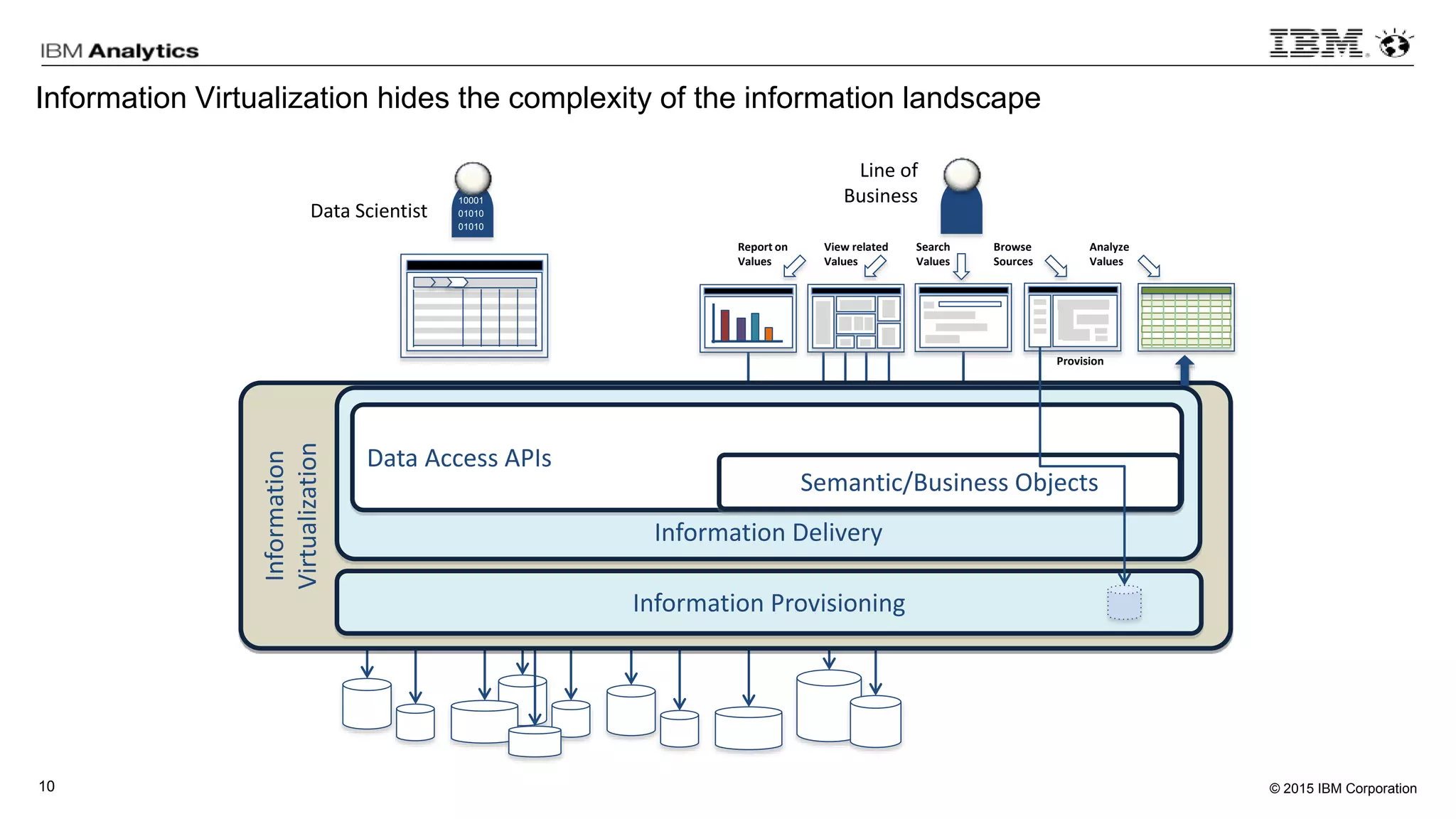
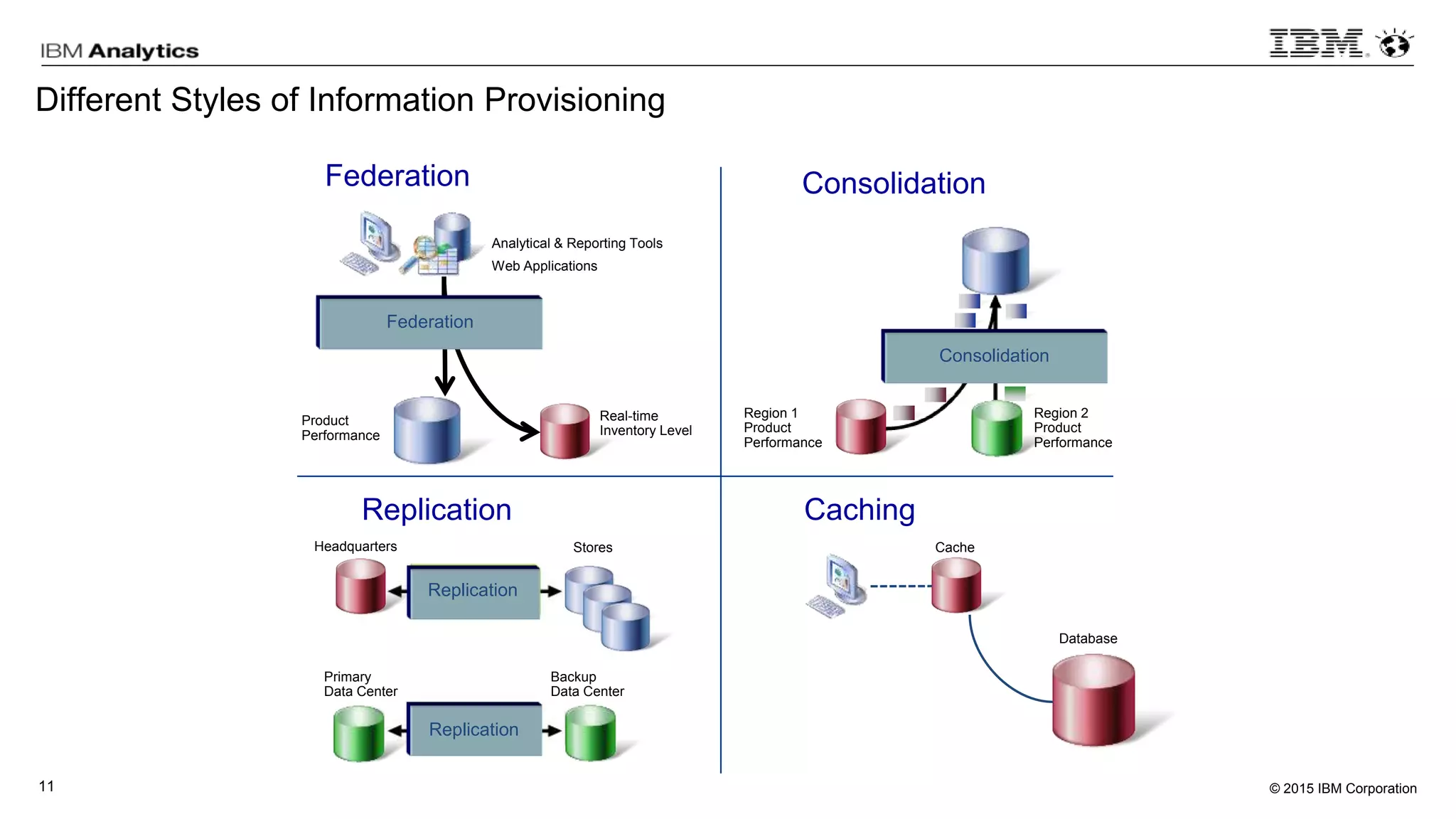
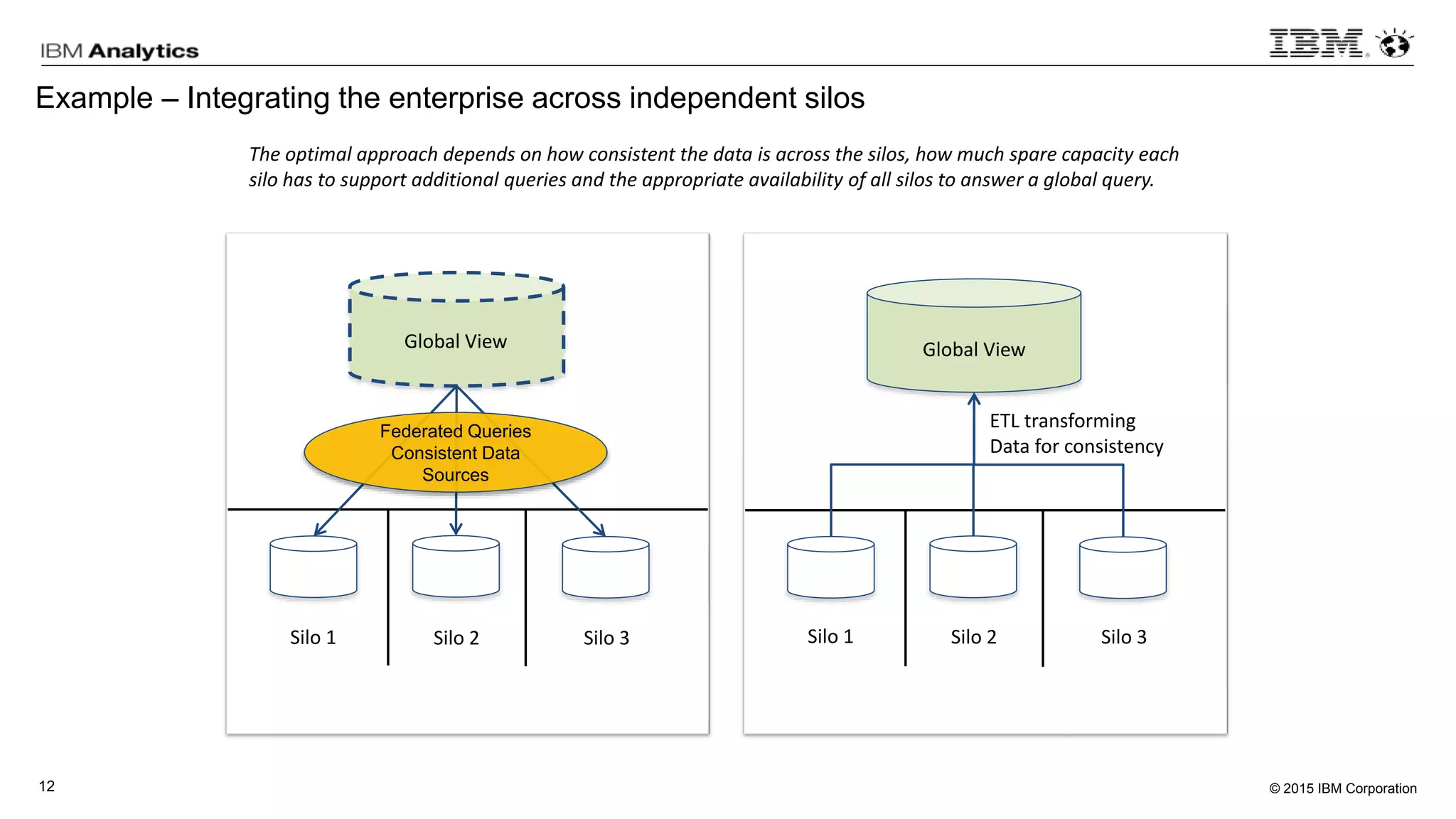
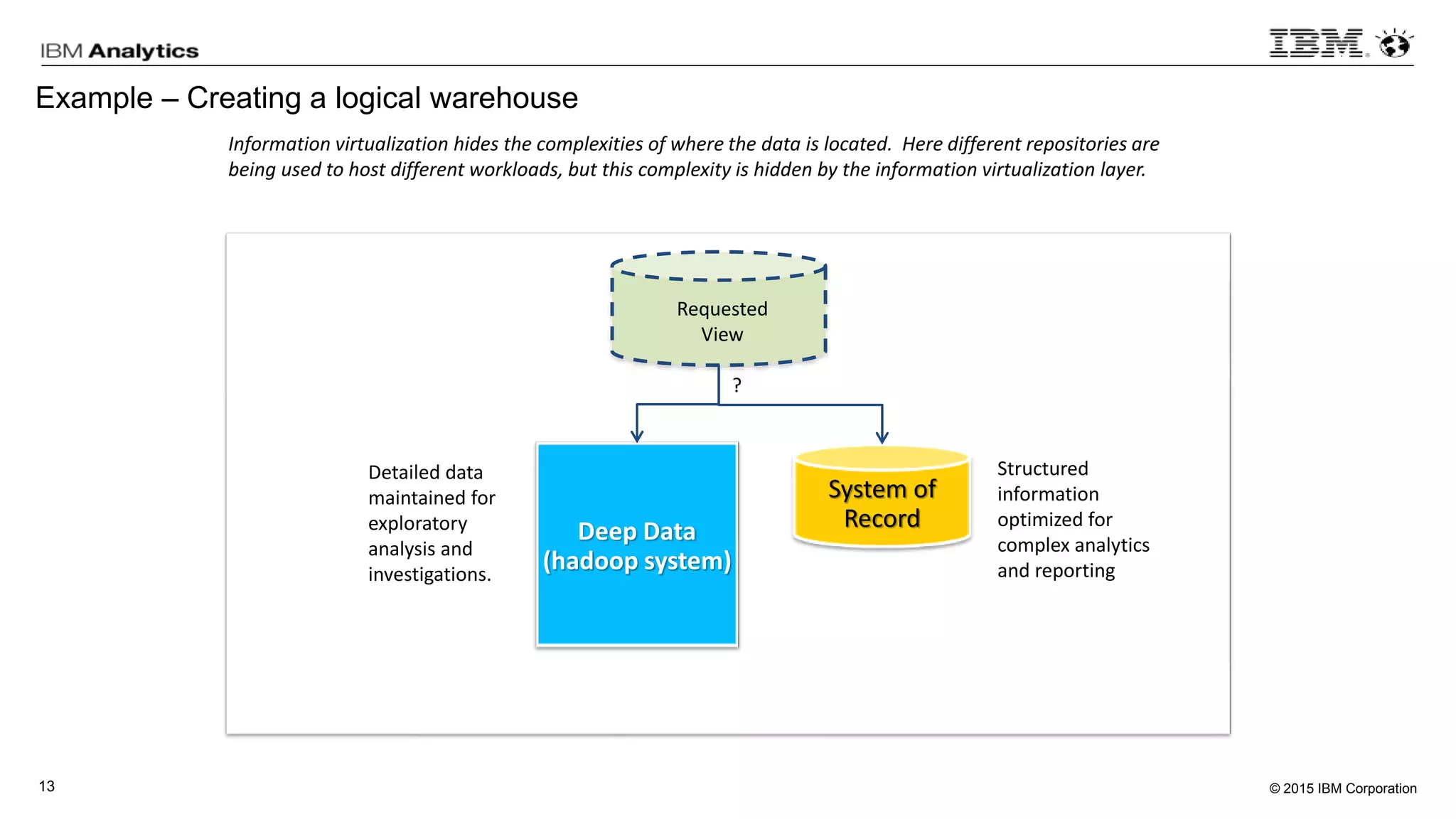
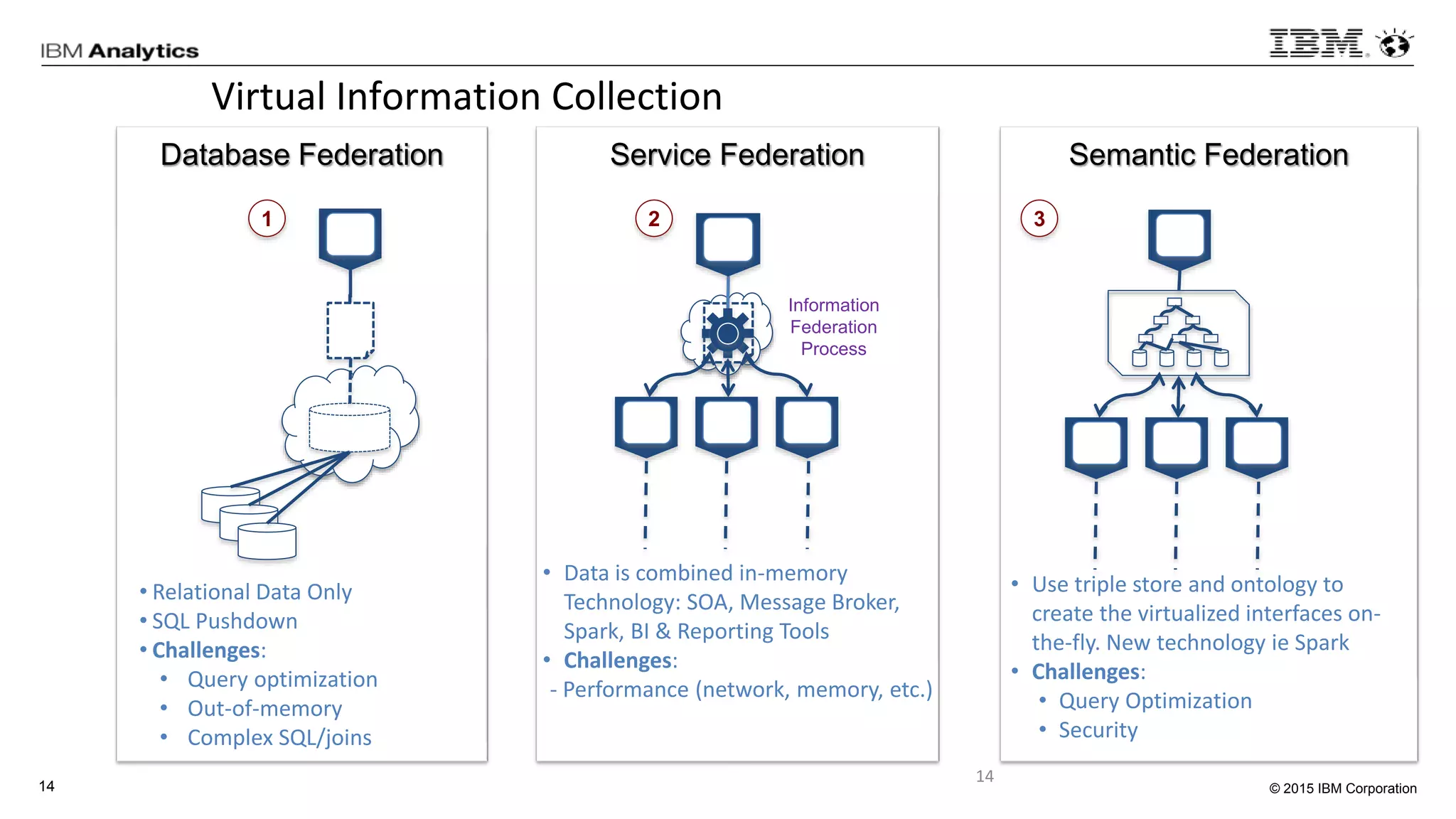

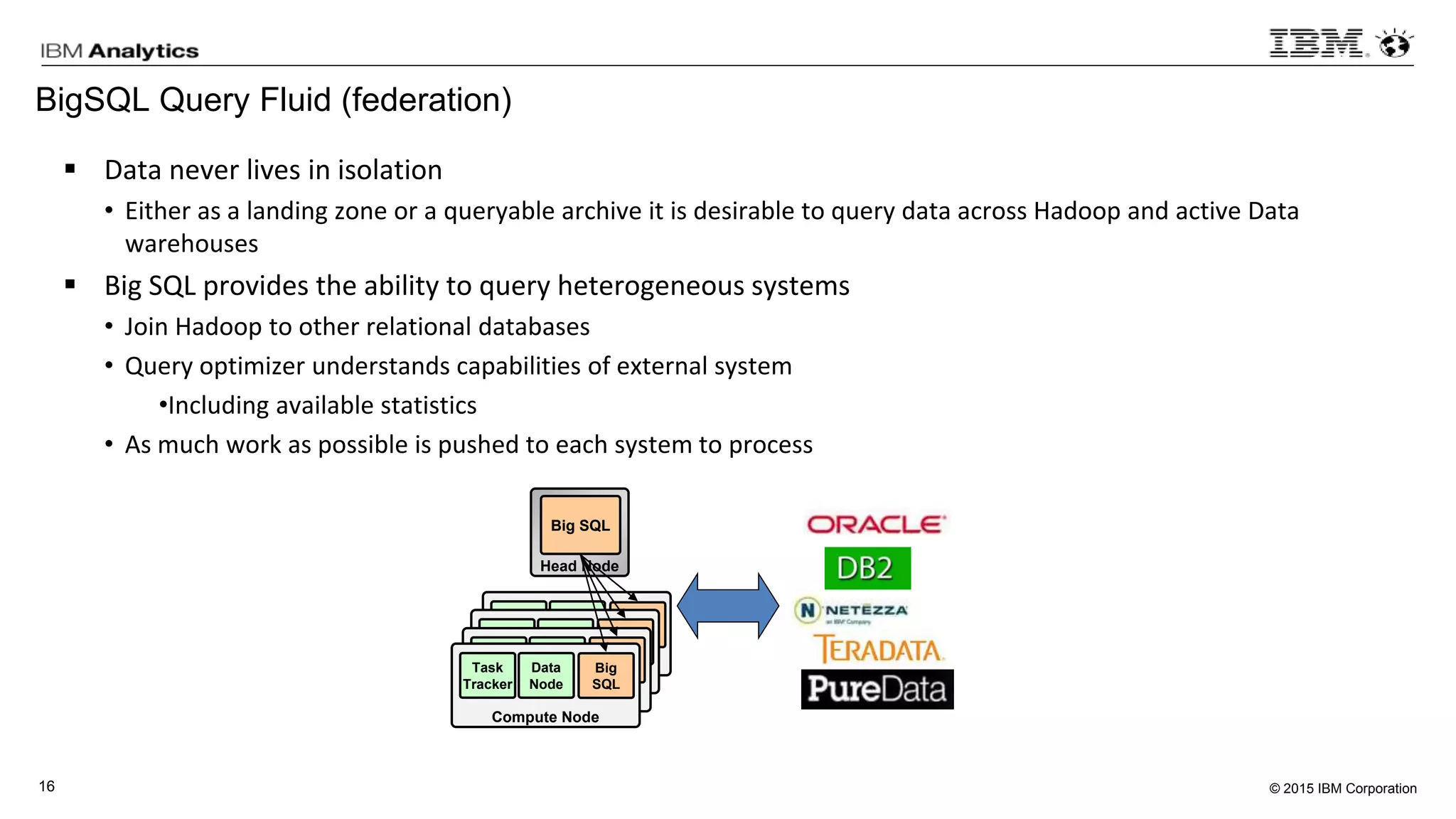
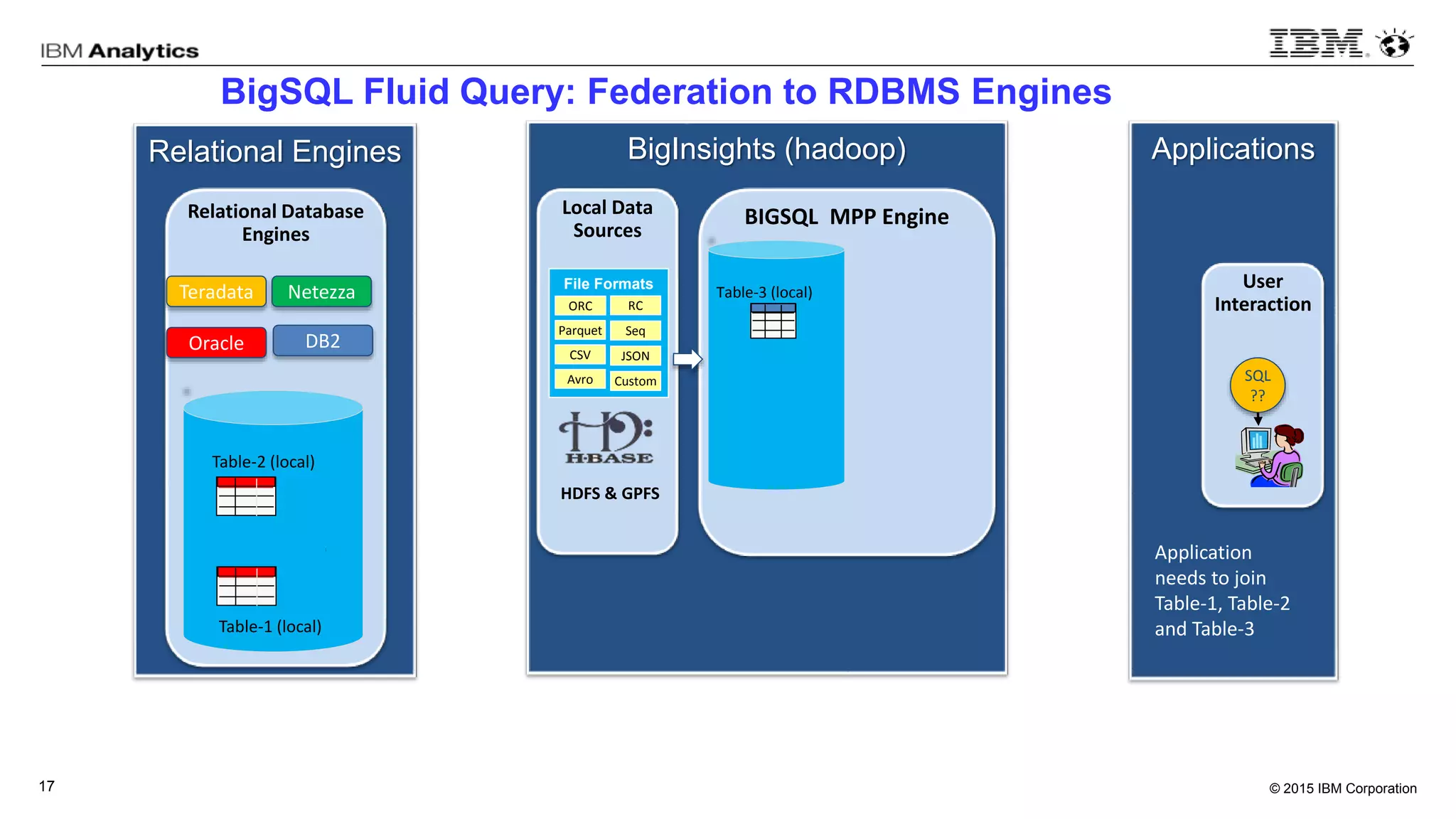
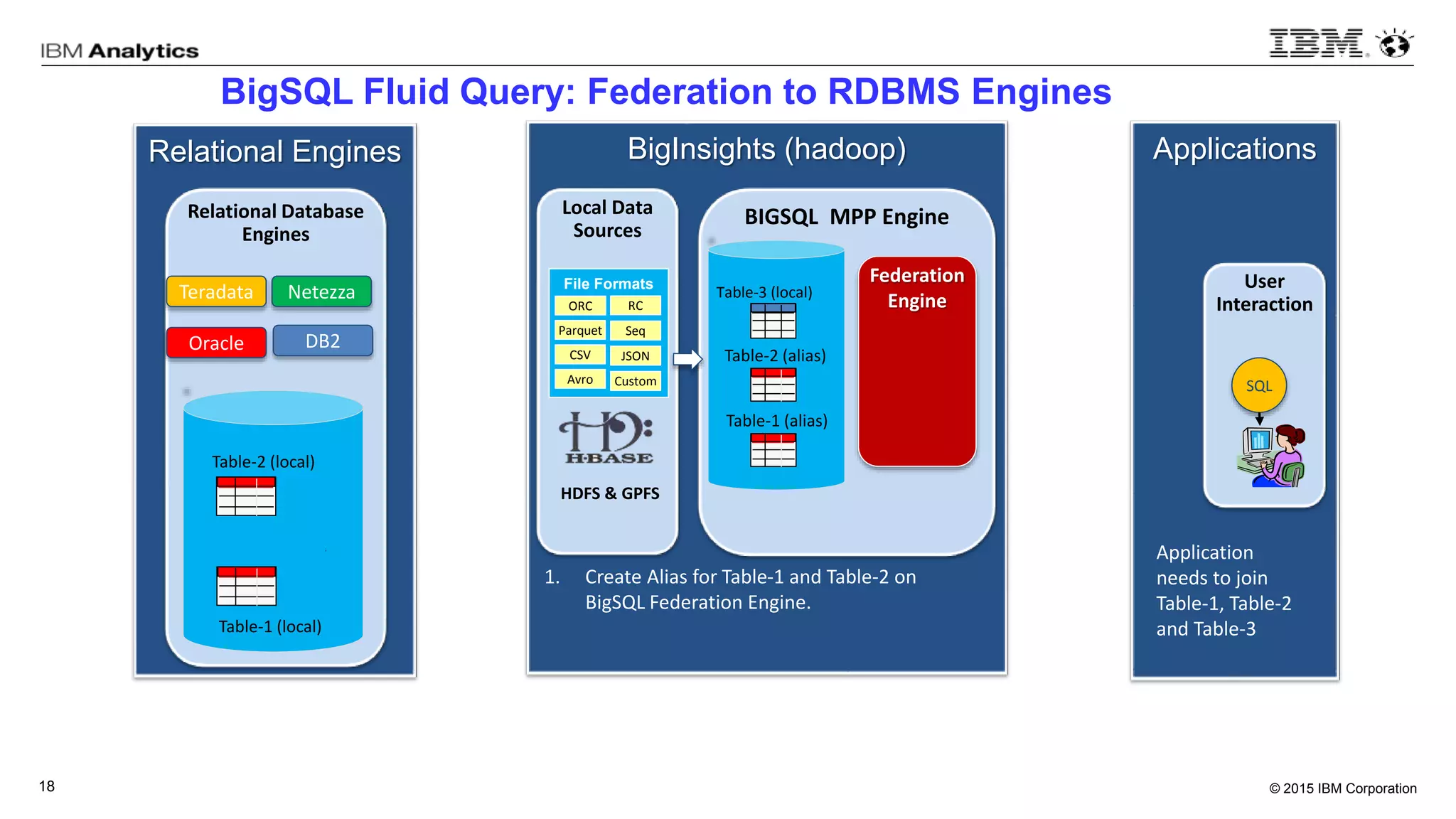
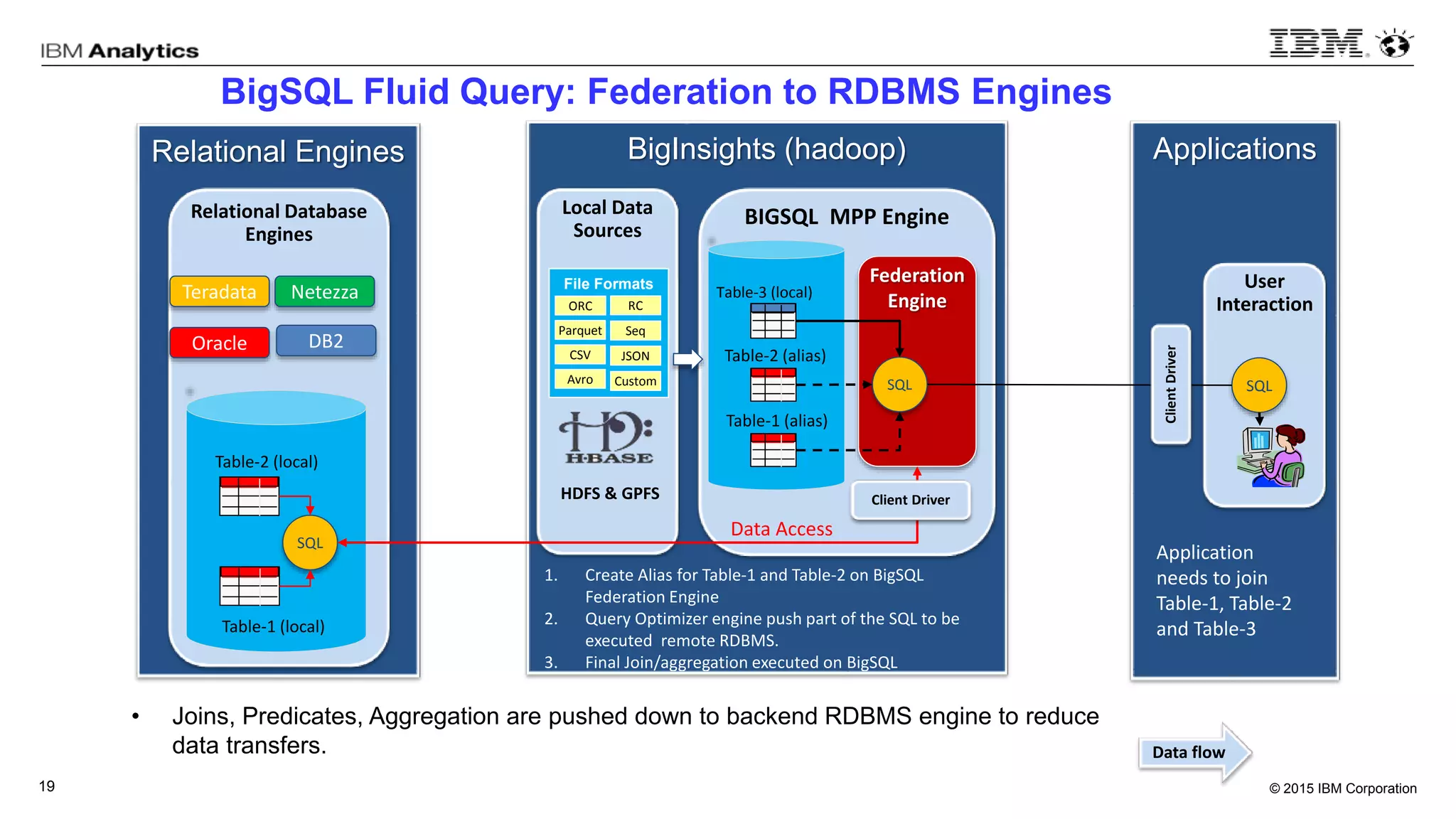

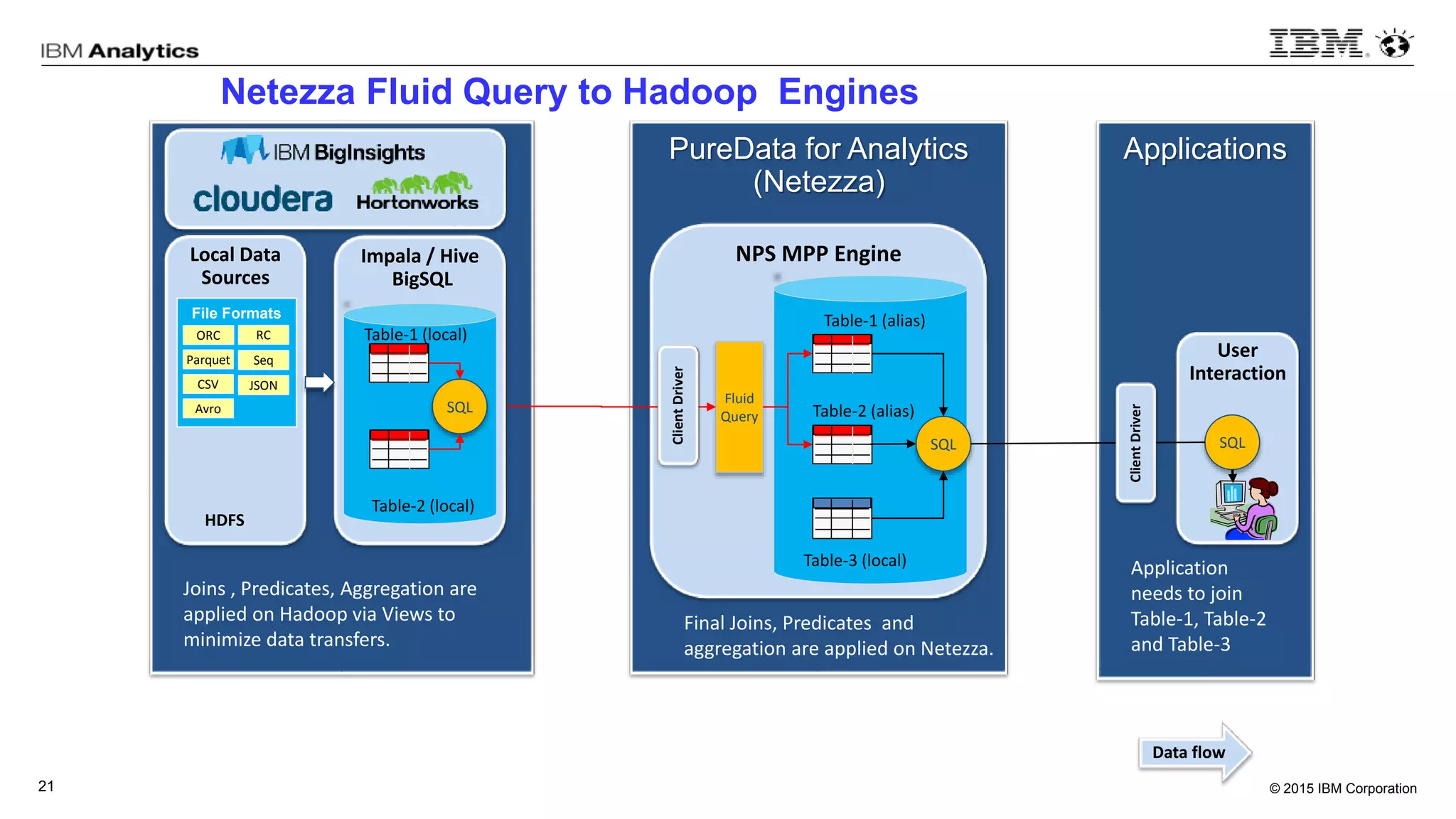




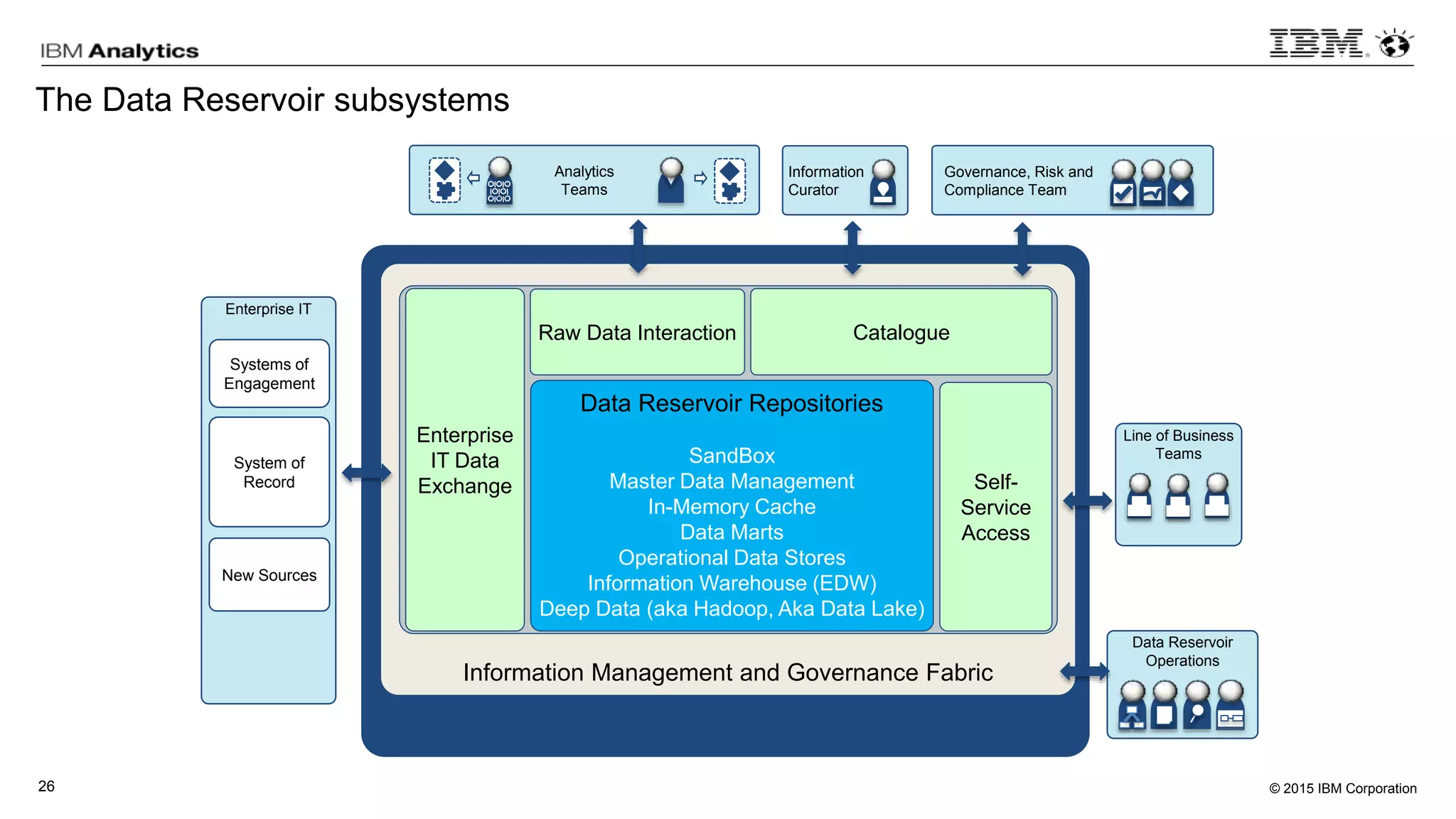

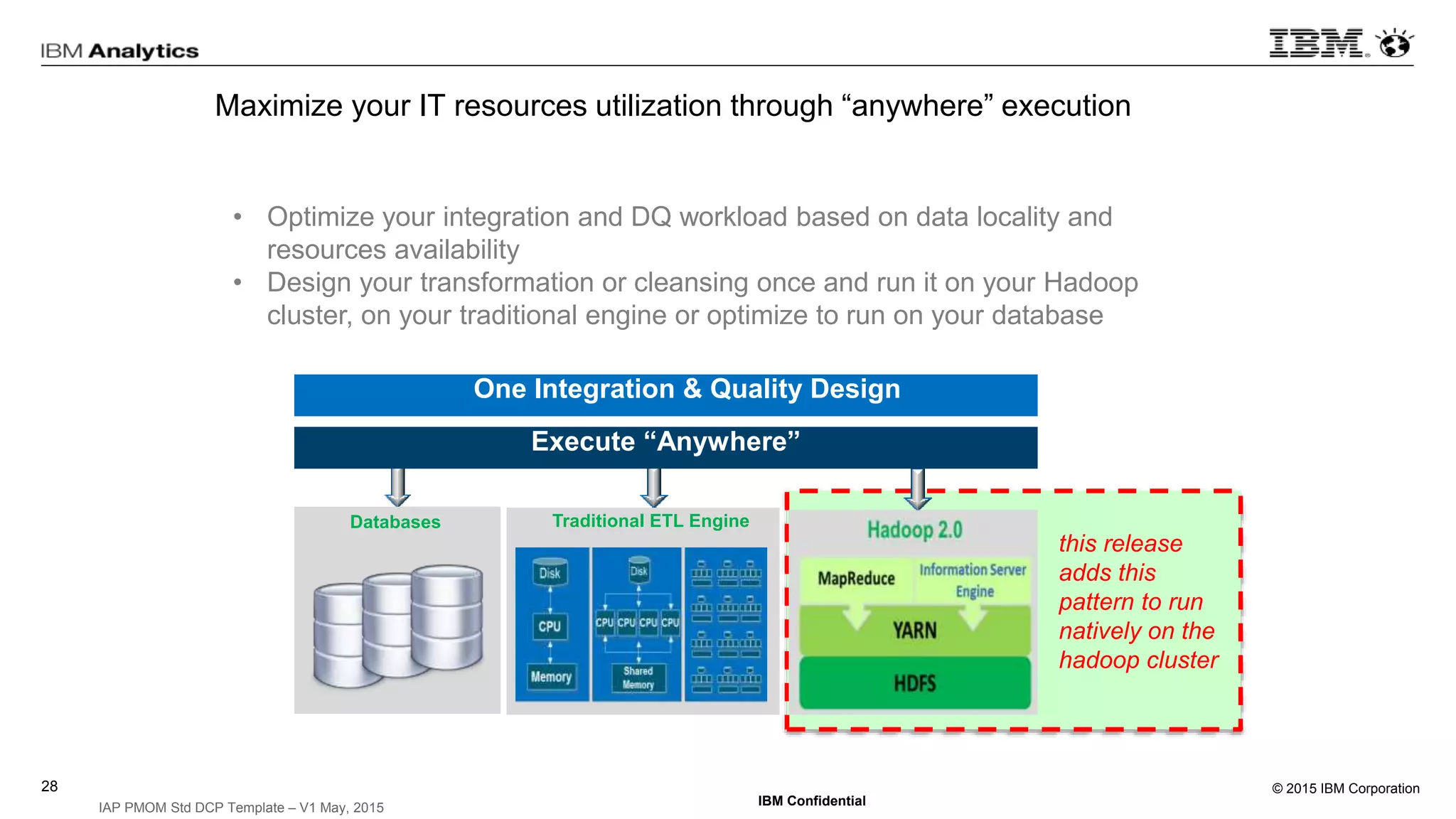



This document discusses information virtualization and query federation on data lakes. It provides examples of how information virtualization hides the complexity of integrating data from different sources and allows queries to span multiple data repositories. It also discusses best practices for query federation, including avoiding complex joins across many systems and keeping statistics up to date on all tables in a federated system.






















































































