Downloaded 97 times







![[Overview of Apache Kafka — By Ch.ko123 — Own work, CC BY 4.0,
https://commons.wikimedia.org/w/index.php?curid=59871096]](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-7-320.jpg)
![[Druid Architecture, http://druid.io/technology]](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-8-320.jpg)
![[Druid Architecture, http://druid.io/docs/latest/design/ ]](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-9-320.jpg)
![[Druid Architecture, http://druid.io/technology]](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-10-320.jpg)
![[Druid Architecture, http://druid.io/technology]](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-11-320.jpg)
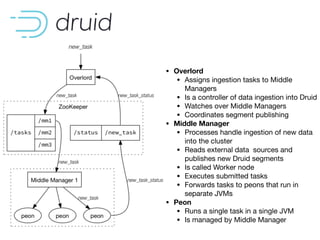



![The Autoscaling mechanisms currently in place are tightly coupled with our deployment
infrastructure but the framework should be in place for other implementations. We are highly
open to new implementations or extensions of the existing mechanisms. In our own
deployments, middle manager nodes are Amazon AWS EC2 nodes and they are
provisioned to register themselves in a galaxy environment.
If autoscaling is enabled, new middle managers may be added when a task has been in
pending state for too long. Middle managers may be terminated if they have not run any
tasks for a period of time.
“
”
[Autoscaling, http://druid.io/docs/latest/design/overlord.html ]
Description of Auto Scaling in Druid](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-19-320.jpg)
![[EC2AutoScalar.java, https://github.com/apache/incubator-druid/blob/master/indexing-service/src/main/java/org/apache/druid/
indexing/overlord/autoscaling/ec2/EC2AutoScaler.java ]
public class EC2AutoScaler implements AutoScaler<EC2EnvironmentConfig>
{
...
@Override
public AutoScalingData provision() { ... }
...
@Override
public AutoScalingData terminate(List<String> ips) { ... }
...
}
Implementation of Auto Scaling in Druid](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-20-320.jpg)











![$ make certs
Generating TLS certs
Generating a 2048 bit RSA private key
......................................+++
.......................+++
writing new private key to 'metrics-ca.key'
-----
2018/09/19 20:05:54 [INFO] generate received request
2018/09/19 20:05:54 [INFO] received CSR
2018/09/19 20:05:54 [INFO] generating key: rsa-2048
2018/09/19 20:05:55 [INFO] encoded CSR
2018/09/19 20:05:55 [INFO] signed certificate with serial number
369504685819654624616304590957348031615297503101
Generating custom-metrics-api/cm-adapter-serving-certs.yaml
$
Exploring Middle Manager Auto Scaling based on Custom Metrics](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-36-320.jpg)



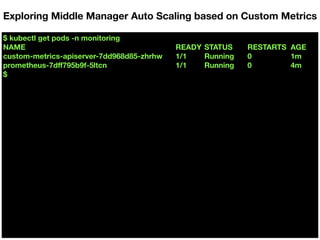
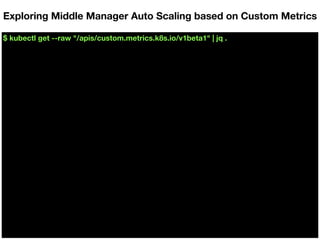
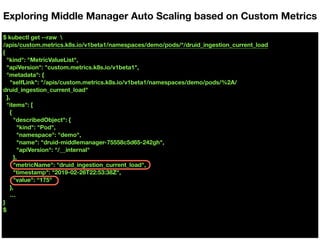
![$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "persistentvolumeclaims/kubelet_volume_stats_inodes_free",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "namespaces/kube_statefulset_status_observed_generation",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
…
Exploring Middle Manager Auto Scaling based on Custom Metrics](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-42-320.jpg)









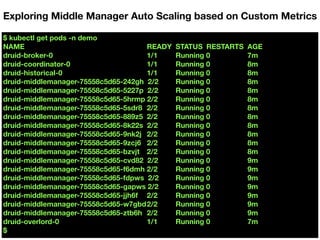

![[replica_set.go, https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/replicaset/replica_set.go#L459 ]
Precedences Rules & Workaround
1. Unassigned < Assigned
2. Pending < Unknown < Running
3. Not ready < Ready
4. Ready for empty time < Less time < More time
5. Higher restart counts < Lower restart counts
6. Empty creation time pods < Newer pods < Older pods](https://image.slidesharecdn.com/thurs1100amroom118-119apachedruidautoscale-outinforstreamingdataingestiononkubernetesjinchulkim-190321230105/85/Apache-Druid-Auto-Scale-out-in-for-Streaming-Data-Ingestion-on-Kubernetes-57-320.jpg)


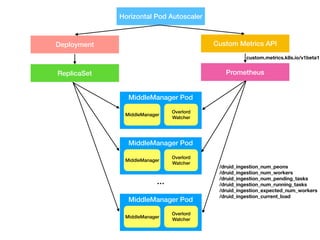
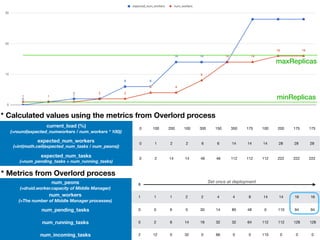
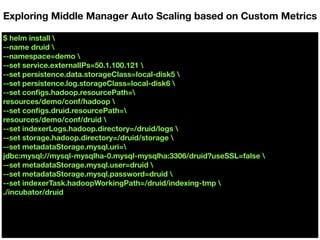
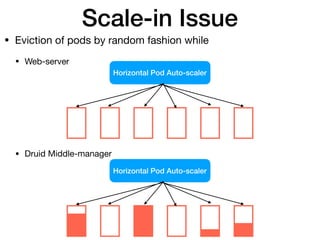
Apache Druid supports auto-scaling of Middle Manager nodes to handle changes in data ingestion load. On Kubernetes, this can be implemented using Horizontal Pod Autoscaling based on custom metrics exposed from the Druid Overlord process, such as the number of pending/running tasks and expected number of workers. The autoscaler scales the number of Middle Manager pods between minimum and maximum thresholds to maintain a target average load percentage.









































![[k8s] Kubernetes terminology (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/k8skubernetesterminology1-230513211357-e2d31a79-thumbnail.jpg?width=640&height=640&fit=bounds)












































