多層ネットワークの学習の難しさ
誤り訂正教師信号 t は1階層であれば対応可能
中間層z1, z2 に対する教師信号はどう生成する?
43
u
yx1 y
x2
Σ
u
θ
w1
w2
u
yx1 y
x2
Σ
u
θ
w1
w2
u
yx1 y
x2
Σ
u
θ
w1
w2
x1
x2
z1
z2
y
tw11
(1)
w22
(1)
w12
(1)
w21
(1)
w1
(2)
w2
(2)
z1
θ
z2
θ
u
u OK!
NG!
43.
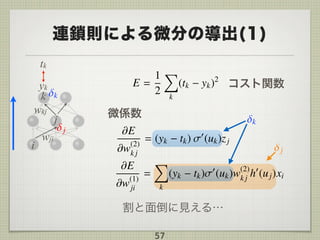
Error Back-propagation
単純 Perceptronの線形分離問題
→ 階層性による打破
多層Perceptron (MLP)の学習則
基本アイディアは勾配法
微分の連鎖則を活用
44
x0
x1
xD
z0
z1
zM
y1
yK
w
(1)
MD
w
(2)
KM
w
(2)
10
hidden units
inputs outputs
MLP の勾配学習
MLP の勾配学習に線形性ではなく微分可能性なのでは?
微分の連鎖則(chain-rule)を適用
多層に意味を持たせるためには
微分可能な非線形活性化関数であれば良い
54
u
yx1 y
x2
Σ
u
θ
w1
w2
u
yx1 y
x2
Σ
u
θ
w1
w2
u
yx1 y
x2
Σ
u
θ
w1
w2
x1
x2
z1
z2
y
tw11
(1)
w22
(1)
w12
(1)
w21
(1)
w1
(2)
w2
(2)
z1
u
z2
u
y
u
@E(w)
@w(1)
22
@E(w)
@w(2)
2
z1
u
z2
u
y
u
MLP 学習のコスト関数例
56
yk
tk
k
j
wkj
i
wji
入力層 x
隠れ層z
出力層 y
回帰問題と同様に考える
n 番目の入力に関するコスト
回帰問題→2乗誤差関数
2値分類→Logisitic-Sigmoid
多値分類→ Softmax
yn
k = yk(xn
; w) として
En
(w) =
1
2
X
k
⇣
tn
k yn
k
⌘2
En
(w) =
X
k
tn
k ln yn
k
+ (1 tn
k )(1 yn
k)
初期視覚野の性質
線分やエッジなどの成分に反応
Simple cell: 方位,位相に敏感
Complexcell: 位相には許容的
66
Simple Cell
Phase Sensitive
Orientation Selective
Receptive Field
Input Stimulus
Fire Not FireNot Fire
Phase InsensitiveComplex Cell
Receptive Field
Input Stimulus
Fire Not FireFire
V1
V2
V4
PITCIT
Ventral Pathway
AIT
TEO
TE
V1
V4
V2
IT
Small receptive field
Edge, Line segment
detector
Large receptive field
Face, Complex feature
detector
?
?
Simple Cell
Phase Sensitive
Orientation Selective
Receptive Field
Input Stimulus
Fire Not FireNot Fire
Phase InsensitiveComplex Cell
Receptive Field
Input Stimulus
Fire Not FireFire
66.
Hubel-Wiesel 階層仮説
Simple Cellの出力合成で,
Complex cell は説明可能
(Hubel & Wiesel 59)
67
Simple Cell
Phase Sensitive
Orientation Selective
Receptive Field
Input Stimulus
Fire Not FireNot Fire
Phase InsensitiveComplex Cell
Receptive Field
Input Stimulus
Fire Not FireFire
Boltzmann Machine:
アーキテクチャ
素子モデル
86
h
v
vi= { 1, +1}, hj = { 1, +1}
u =
v
h
!
とりあえず,系のエネルギーを定義しておく
E(u) =
X
i,i0
Wi0ivivi0
X
j, j0
Wj0 jhjhj0
X
i,j
Wijvihj
係数 W が互いの素子の好感度設定
Wukul において W > 0 ならukとul とは好きどうし
Restricted Boltzmann Machine(RBM):
アーキテクチャ
BMで恐ろしく時間がかかる理由
→結合数が多すぎること
隠れ層と可視層を階層構造と考え,
層内結合を撤廃
→ RBM
何ということでしょう.
素子が条件付き独立に!
92
h
v
H(h, v) =
X
i,j
hjWi jvi p(h | v) =
Y
j
p(hj | v) =
Y
j
exp(hj
P
i Wijvi)
2 cosh(
P
i Wijvi)
p(v | h) =
Y
i
p(vi | h) =
Y
i
exp(vi
P
j Wijhj)
2 cosh(
P
j Wijhj)
p(v | h1
)=
Y
i
p(vi | h1
)
Sigmoid
Belief net
Deep Belief Net(DBN):
アーキテクチャ
RBM は単層モデル (結構成功はしている)
隠れ層の表現をさらに RBM で
学習する機械を考えてみよう!
学習後の下層はパターン生成器として働く
(Sigmoid Belief net)
98
h1
v
h2
RBM
Sigmoid
Belief net
p(v, h1
, h2
) = p(v | h1
)p(h1
, h2
)
RBM
p(h1
, h2
) =
1
Z(W2)
exp(
X
j,k
h2
kW2
jkh1
j)
97.
Deep Belief Net(DBN):
学習モデル
DBNの学習は,階層ごとのRBM学習
(Greedy Layer-wise Learning)
第1層: 勾配法での対数尤度最大化
99
h1
v
RBM
@ ln p(v)
@W1
ij
=
D
vihj
E
cramp
D
vihj
E
free
ln p(v(p)
) =
X
i,j
h1
jW1
i jv(p)
i ln Z(W1
)
98.
Deep Belief Net(DBN):
学習モデル
DBNの学習は,階層ごとのRBM学習
(Greedy Layer-wise Learning)
第1層学習後,p(h1 | v) に基づき
サンプル {h1(p)} を収集
第2層: 勾配法による対数尤度最大化
100
h1
v
h2
RBM
Sigmoid
Belief net
@ ln p(h1
)
@W2
jk
=
D
h1
jh2
k
E
cramp
D
h1
jh2
k
E
free
ln p(h1(p)
) =
X
j,k
h2
kW2
jkh1
j
(p)
ln Z(W2
)
99.
Deep Belief Net(DBN):
サンプリング
DBNによるサンプリング
最上位層 ( p(h
1
, h
2
) )の Gibbs サンプリング,h
1
のサンプルを生成
得られた表現 h
1
を 下層の Sigmoid Belief Net へ投入,p(v | h
1
)
により v のサンプルを生成
101
h1
v
h2
RBM
Sigmoid
Belief net
h2 h2 h2
h1 h1 h1
v
100.
Deep Belief Net(DBN):
MNISTを使った場合
MNIST を用いたDBNの
学習
高位層では,より大まかな
特徴抽出器として振る舞う
102
h1
v
h2
RBM
Sigmoid
Belief net
Learned Features
(Salakhudinov13, 14 より)
101.
Convolution Net +Deep Belief Net(CDBN):
自然画像への適用
Convolution net + DBN の自然画像への応用(Lee+09)
103
Learning Part based Representation
Convolutional DBN
Faces
Trained on face images.
Object Parts
Groups of parts.
Lee et.al., ICML 2009
102.
Convolution Net +Deep Belief Net(CDBN):
自然画像への適用
Convolution net + DBN の自然画像への応用(Lee+09)
104
Learning Part based Representation
Faces Cars Elephants Chairs
Lee et.al., ICML 2009
Deep Neural Net(DNN):
アーキテクチャ
DBNの構造 MLP の構造
識別モデルとして使ったら?
107
h1
v
h2
p(h1
j | v) =
exp(h1
j
P
i W1
ijvi)
2 cosh(
P
i W1
ijvi)
y
p(h2
k | h1
) =
exp(h2
k
P
j W2
jkh1
j)
2 cosh(
P
j W2
jkh1
j)
p(yl = 1 | h2
) =
exp(
P
k W3
klh2
k)
P
m exp(
P
k W3
kmh2
k)
SoftMax
106.
Deep Neural Net(DNN):
学習
BackProp の問題点: 局所解の存在
DBN を初期状態として使う
(Pre-Training)
ネットワークの結合 (Unroll)
結合したネットワークを MLP として
BP 学習(Fine Tuning)
108
h1
v
h2
y
h2
h1
RBM
RBM
SoftMax
107.
Deep Neural Net(DNN):
MNISTへの応用
誤識別率→ DNN: 1.2 %, SVM 1.4 %, MLP: 1.6 %
109
DBNs$for$Classifica:on$
W +W
W
W
W +
W +
W +
W
W
W
W
1 11
500 500
500
2000
500
500
2000
500
2
500
RBM
500
2000
3
Pretraining Unrolling Fine tuning
4 4
2 2
3 3
1
2
3
4
RBM
10
Softmax Output
10
RBM
T
T
T
T
T
T
T
T






































![MLP にできること
適切な設定(隠れ層の素子数,結合重み)を選べば
任意の関数を任意精度で表現できる.[Funahashi 1989]
41
{xn}
{zn}
x1
x0
z0
z1
z2
1 1
z3
y
x1
y
x1
y
x1
y
x1
y](https://image.slidesharecdn.com/20150803-150807012455-lva1-app6892/85/20150803-40-320.jpg)

















![誤差逆伝搬法の適用
コスト関数 En(w) はパターン事に定義可能
1サンプルごとの勾配で動かす (Online learning)
→ 局所解の問題
全サンプルの平均勾配で動かす(Batch learning)
→ 学習が遅い
確率的降下法(Stochastic GD)[Amari 67]
mini Batch: 数個∼100個程度の平均勾配
準ニュートン法や,共益勾配法 (Le+11)
60](https://image.slidesharecdn.com/20150803-150807012455-lva1-app6892/85/20150803-59-320.jpg)




























































![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)





















































