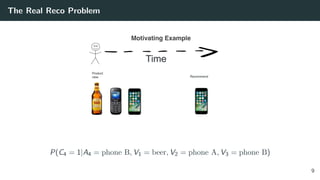
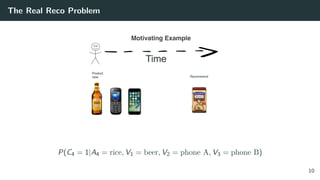
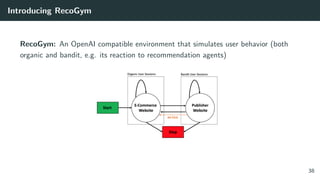
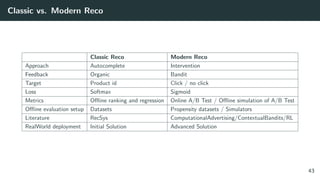
The document discusses the differences between classic and modern recommendation approaches. Classic recommendation frames the problem as next item prediction based on past user behavior, while modern recommendation frames it as predicting the success of intervention policies. Modern approaches aim to directly optimize business metrics and allow for better offline evaluation methods like inverse propensity scoring that can predict A/B test results. The document also outlines the experimentation lifecycle of real-world recommendation systems, which involves supervised learning from past user data, offline evaluation, A/B testing, and continuous improvement.








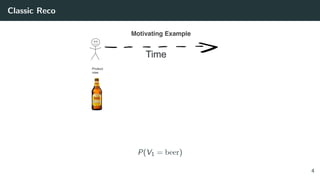
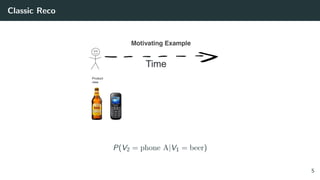
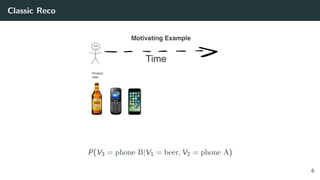



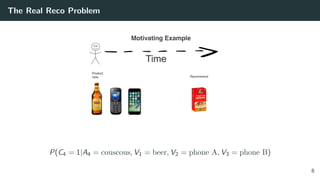











![Solving the Wrong Problem: are the Classic Datasets Logs of RecSys?
• MovieLens: no, explicit feedback of movie ratings [1]
• Netflix Prize: no, explicit feedback of movie ratings [2]
• Yoochoose (RecSys competition ’15): no, implicit session-based behavior [3]
• 30 Music: no, implicit session-based behavior [4]
• Yahoo News Feed Dataset: yes! [5]
• Criteo Dataset for counterfactual evaluation of RecSys algorithms: yes! [6]
19](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-28-320.jpg)
![Solving the Wrong Problem: are the Classic Datasets Logs of RecSys?
• MovieLens: no, explicit feedback of movie ratings [1]
• Netflix Prize: no, explicit feedback of movie ratings [2]
• Yoochoose (RecSys competition ’15): no, implicit session-based behavior [3]
• 30 Music: no, implicit session-based behavior [4]
• Yahoo News Feed Dataset: yes! [5]
• Criteo Dataset for counterfactual evaluation of RecSys algorithms: yes! [6]
The Criteo Dataset shows a log of recommendations and if they were successful in
getting users to click.
19](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-29-320.jpg)
![Solving the Wrong Problem: do the Classical Offline Metrics Evaluate the Qual-
ity of Recommendation?
Classical offline metrics:
• Recall@K, Precision@K, HR@K: How often is an item in the top k - no, evaluates
next item prediction
• DCG: Are we assigning a high score to an item - no, evaluates next item prediction
Online metrics and their offline simulations:
• A/B Test: i.e. run a randomized control trial live — yes, but expensive + the
academic literature has no access to this
• Inverse Propensity Score estimate of click-through rate: - to be explained later.
— yes! (although it is often noisy) [7]
20](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-30-320.jpg)






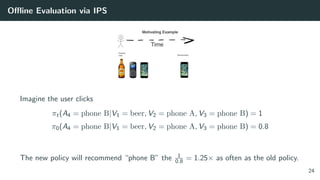




![Offline Evaluation via IPS
This estimator is unbiased
CTR estimate = Eπ0
c · πt(a|X)
π0(a|X)
= Eπt [c]
27](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-42-320.jpg)

![Offline Evaluation via IPS
Overall, IPS actually attempts to answer a counterfactual question (what would have
happened if instead of π0 we would have used πt ?), but it often has less than
spectacular results because of its variance issues.
A lot of the shortcomings of the naive IPS estimator are handled in [8].
29](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-44-320.jpg)

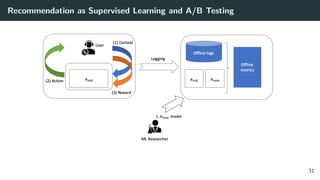
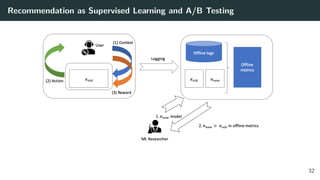
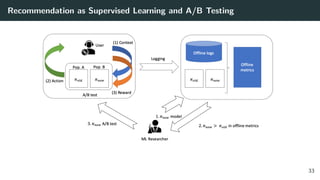
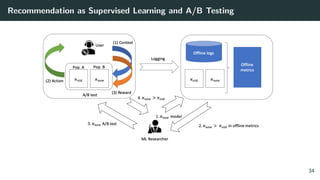














![Reward(Click) Modeling via Logistic Regression
cn ∼ Bernoulli σ Φ([Xn an])T
β
where
• X represent context or user features
• a represent action or product features
• β are the parameters;
• σ (·) is the logistic sigmoid;
• Φ (·) is a function that maps X, a to a higher dimensional space and includes
some interaction terms between Xn and an.
45](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-68-320.jpg)
![Reward(Click) Modeling via Logistic Regression
cn ∼ Bernoulli σ Φ([Xn an])T
β
where
• X represent context or user features
• a represent action or product features
• β are the parameters;
• σ (·) is the logistic sigmoid;
• Φ (·) is a function that maps X, a to a higher dimensional space and includes
some interaction terms between Xn and an. Why?
45](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-69-320.jpg)
![Modeling interaction between user/context and product/action
• Φ ([Xn an]) = Xn ⊗ an Kronecker product, this is somewhat what we will be
doing in the example notebook, these will model pairwise interactions between
user and product features.
• Φ ([Xn an]) = ν(Xn) · µ(an) Another more ”modern” approach, is to build an
embedded representation of the user and product features and consider the dot
product between both (in this case the parameters of the model are carried in the
embedding functions ν and µ and we have no parameter vector β)
46](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-70-320.jpg)
![Reward(Click) Modeling via Logistic Regression
Then it’s just a classification problem, right? We want to maximize the log-likelihood:
ˆβlh = argmaxβ
n
cn log σ Φ ([Xn an]))T
β
+ (1 − cn) log 1 − σ Φ ([Xn an])T
β
47](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-71-320.jpg)
![Other Possible Tasks
Imagine we recommend a group of items (a banner with products, for instance), and
one of them gets clicked, an appropriate task would be to rank the clicked items higher
than non clicked items.
Example: Pairwise Ranking Loss
n
log σ Φ ([Xn an])T
β − Φ Xn a n
T
β
Where an represent a clicked item from group n and a n a non clicked item.
Multitude of possible other tasks (list-wise ranking, top-1, ...) e.g. BPR [9]
48](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-72-320.jpg)






![Sidepoint: Scaling argmax in the Case of Large Action Spaces
• Several method families
• Hashing based: Locality Sensitive Hashing [10]
• Tree based: Random Projection Trees [11]
• Graph based: Navigable Small World Graphs [12]
• Bottom line: use and abuse them!
52](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-79-320.jpg)







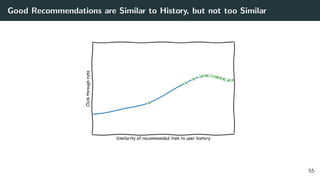
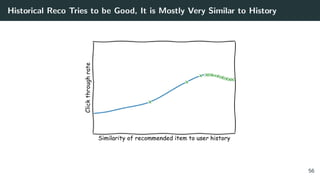
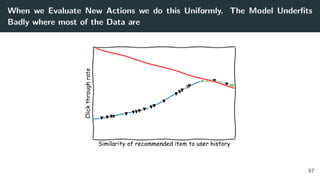
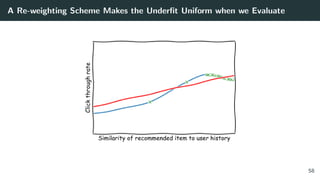






![Issue #2: The Optimizer’s Curse. A Story
Figure 1: The distribution of rewards of argmax of 3 actions with ∆ separation. From: The
Optimizer’s Curse: Skepticism and Postdecision Surprise in Decision Analysis [13]
64](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-97-320.jpg)









![References i
References
[1] F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and
context. Acm transactions on interactive intelligent systems (tiis), 5(4):19, 2016.
[2] James Bennett, Stan Lanning, et al. The netflix prize. In Proceedings of KDD
cup and workshop, volume 2007, page 35. New York, NY, USA., 2007.
[3] David Ben-Shimon, Alexander Tsikinovsky, Michael Friedmann, Bracha Shapira,
Lior Rokach, and Johannes Hoerle. Recsys challenge 2015 and the yoochoose
dataset. In Proceedings of the 9th ACM Conference on Recommender Systems,
pages 357–358. ACM, 2015.
70](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-107-320.jpg)
![References ii
[4] Roberto Turrin, Massimo Quadrana, Andrea Condorelli, Roberto Pagano, and
Paolo Cremonesi. 30music listening and playlists dataset. In RecSys 2015 Poster
Proceedings, 2015. Dataset: http://recsys.deib.polimi.it/datasets/.
[5] Yahoo. Yahoo news feed dataset, 2016.
[6] Damien Lefortier, Adith Swaminathan, Xiaotao Gu, Thorsten Joachims, and
Maarten de Rijke. Large-scale validation of counterfactual learning methods: A
test-bed. arXiv preprint arXiv:1612.00367, 2016.
[7] Daniel G Horvitz and Donovan J Thompson. A generalization of sampling
without replacement from a finite universe. Journal of the American statistical
Association, 47(260):663–685, 1952.
71](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-108-320.jpg)
![References iii
[8] Alexandre Gilotte, Cl´ement Calauz`enes, Thomas Nedelec, Alexandre Abraham,
and Simon Doll´e. Offline a/b testing for recommender systems. In Proceedings of
the Eleventh ACM International Conference on Web Search and Data Mining,
pages 198–206. ACM, 2018.
[9] Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars
Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. In
Proceedings of the twenty-fifth conference on uncertainty in artificial intelligence,
pages 452–461. AUAI Press, 2009.
[10] Aristides Gionis, Piotr Indyk, Rajeev Motwani, et al. Similarity search in high
dimensions via hashing. In Vldb, volume 99, pages 518–529, 1999.
72](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-109-320.jpg)
![References iv
[11] erikbern. Approximate nearest neighbors in c++/python optimized for memory
usage and loading/saving to disk, 2019.
[12] Yury A Malkov and Dmitry A Yashunin. Efficient and robust approximate nearest
neighbor search using hierarchical navigable small world graphs. IEEE transactions
on pattern analysis and machine intelligence, 2018.
[13] James E Smith and Robert L Winkler. The optimizer’s curse: Skepticism and
postdecision surprise in decision analysis. Management Science, 52(3):311–322,
2006.
73](https://image.slidesharecdn.com/banditrecocoursepart1-191206151633/85/Modern-Recommendation-for-Advanced-Practitioners-110-320.jpg)













![[UMAP2013]Tutorial on Context-Aware User Modeling for Recommendation by Bamsh...](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialcontext-aware-recommendationumap2013-130704190441-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DSC Europe 24] Dmitrii Matveev - RecSys.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/dsceurope24dmitriimatveev-recsys-241209181706-598e49df-thumbnail.jpg?width=640&height=640&fit=bounds)






























