Downloaded 143 times










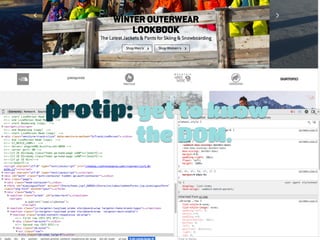



![class BackcountrySpider(CrawlSpider):!
name = 'backcountry'!
def __init__(self, *args, **kwargs):!
super(BackcountrySpider, self).__init__(*args, **kwargs)!
self.base_url = 'http://www.backcountry.com'!
self.start_urls = ['http://www.backcountry.com/Store/catalog/shopAllBrands.jsp']!
!
def parse_start_url(self, response):!
brands = response.xpath("//a[@class='qa-brand-link']/@href").extract()!
!
for brand in brands:!
brand_url = str(self.base_url + brand)!
self.log("Queued up: %s" % brand_url)!
!
yield scrapy.Request(url = brand_url, !
callback = self.parse_brand_landing_pages)!
Part I: Crawl Setup](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-15-320.jpg)
![e.g. brand_url = http://www.backcountry.com/burton
!
def parse_start_url(self, response):!
brands = response.xpath("//a[@class='qa-brand-link']/@href").extract()!
!
for brand in brands:!
brand_url = str(self.base_url + brand)!
self.log("Queued up: %s" % brand_url)!
!
yield scrapy.Request(url = brand_url, !
callback = self.parse_brand_landing_pages)!](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-16-320.jpg)
![!
def parse_brand_landing_pages(self, response):!
shop_all_pattern = "//a[@class='subcategory-link brand-plp-link qa-brand-plp-link']/@href"!
shop_all_link = response.xpath(shop_all_pattern).extract()!
!
if shop_all_link:!
all_product_url = str(self.base_url + shop_all_link[0]) !
!
yield scrapy.Request(url = all_product_url,!
callback = self.parse_product_pages)!
else: !
yield scrapy.Request(url = response.url,!
callback = self.parse_product_pages)](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-17-320.jpg)
![def parse_product_pages(self, response):!
product_page_pattern = "//a[contains(@class, 'qa-product-link')]/@href"!
pagination_pattern = "//li[@class='page-link page-number']/a/@href"!
!
product_pages = response.xpath(product_page_pattern).extract()!
more_pages = response.xpath(pagination_pattern).extract()!
!
# Paginate!!
for page in more_pages:!
next_page = str(self.base_url + page)!
yield scrapy.Request(url = next_page,!
callback = self.parse_product_pages)!
!
for product in product_pages:!
product_url = str(self.base_url + product)!
!
yield scrapy.Request(url = product_url,!
callback = self.parse_item)](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-18-320.jpg)
![def parse_product_pages(self, response):!
product_page_pattern = "//a[contains(@class, 'qa-product-link')]/@href"!
pagination_pattern = "//li[@class='page-link page-number']/a/@href"!
!
product_pages = response.xpath(product_page_pattern).extract()!
more_pages = response.xpath(pagination_pattern).extract()!
!
# Paginate!!
for page in more_pages:!
next_page = str(self.base_url + page)!
yield scrapy.Request(url = next_page,!
callback = self.parse_product_pages)!
!
for product in product_pages:!
product_url = str(self.base_url + product)!
!
yield scrapy.Request(url = product_url,!
callback = self.parse_item)](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-19-320.jpg)

![def parse_item(self, response):!
!
item = Product()!
dirty_data = {}!
!
dirty_data['product_title'] = response.xpath(“//*[@id=‘product-buy-box’]/div/div[1]/h1/text()“).extract()!
dirty_data['description'] = response.xpath("//div[@class='product-description']/text()").extract()!
dirty_data['price'] = response.xpath("//span[@itemprop='price']/text()").extract()!
!
for variable in dirty_data.keys():!
if dirty_data[variable]: !
if variable == 'price':!
item[variable] = float(''.join(dirty_data[variable]).strip().replace('$', '').replace(',', ''))!
else: !
item[variable] = ''.join(dirty_data[variable]).strip()!
!
yield item!
Part II: Parsing](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-21-320.jpg)
![for variable in dirty_data.keys():!
if dirty_data[variable]: !
if variable == 'price':!
item[variable] = float(''.join(dirty_data[variable]).strip().replace('$', '').replace(',', ''))!
else: !
item[variable] = ''.join(dirty_data[variable]).strip()
Part II: Clean it now!](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-22-320.jpg)

![2015-01-02 12:32:52-0800 [backcountry] INFO: Closing spider (finished)
2015-01-02 12:32:52-0800 [backcountry] INFO: Stored json feed (38881 items) in: bc.json
2015-01-02 12:32:52-0800 [backcountry] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 33068379,
'downloader/request_count': 41848,
'downloader/request_method_count/GET': 41848,
'downloader/response_bytes': 1715232531,
'downloader/response_count': 41848,
'downloader/response_status_count/200': 41835,
'downloader/response_status_count/301': 9,
'downloader/response_status_count/404': 4,
'dupefilter/filtered': 12481,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2015, 1, 2, 20, 32, 52, 524929),
'item_scraped_count': 38881,
'log_count/DEBUG': 81784,
'log_count/ERROR': 23,
'log_count/INFO': 26,
'request_depth_max': 7,
'response_received_count': 41839,
'scheduler/dequeued': 41848,
'scheduler/dequeued/memory': 41848,
'scheduler/enqueued': 41848,
'scheduler/enqueued/memory': 41848,
'spider_exceptions/IndexError': 23,
'start_time': datetime.datetime(2015, 1, 2, 20, 14, 16, 892071)}
2015-01-02 12:32:52-0800 [backcountry] INFO: Spider closed (finished)](https://image.slidesharecdn.com/pupy-meetup-shellman-09-150115125402-conversion-gate02/85/Downloading-the-internet-with-Python-Scrapy-24-320.jpg)







The document describes using the Python library Scrapy to build web scrapers and extract structured data from websites. It discusses monitoring competitor prices as a motivation for scraping. It provides an overview of Scrapy projects and components. It then walks through setting up a Scrapy spider to scrape product data from the backcountry.com website, including defining items to scrape, crawling and parsing instructions, requesting additional pages, and cleaning extracted data. The goal is to build a scraper that extracts product and pricing information from backcountry.com to monitor competitor prices.