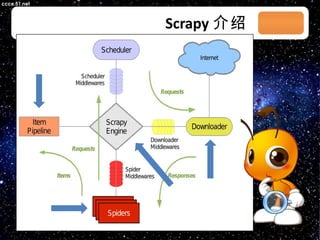
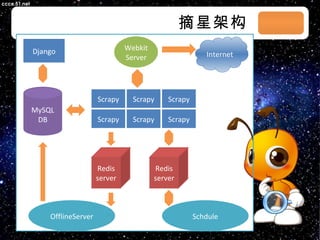
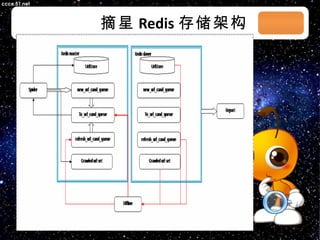
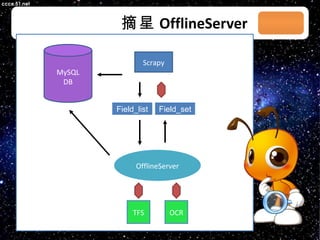
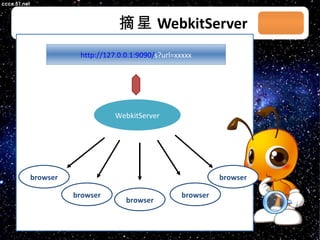
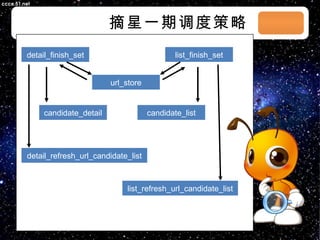
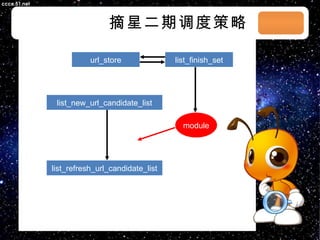
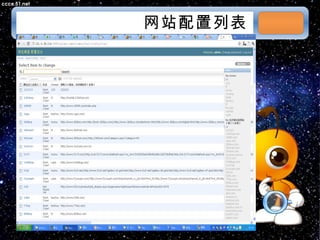
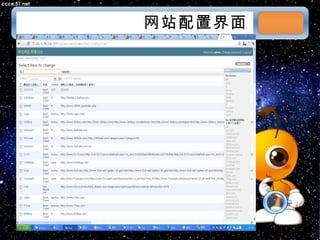
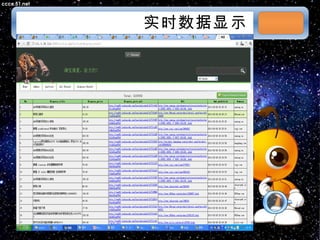
本文档讨论了摘星项目中的爬虫技术与算法,包括应对路径黑洞、JS/Ajax加载问题等。介绍了Scrapy框架的架构、调度策略和Redis存储系统的高性能特性。文档还列出了系统部署和调度策略的详细状态信息。










![Thank you for listening~ 小敏 Email : [email_address] 03/08/11](https://image.slidesharecdn.com/random-110308042706-phpapp02/85/slide-21-320.jpg)







































