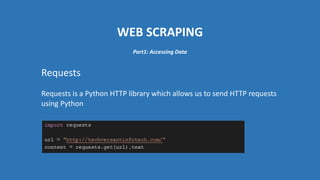
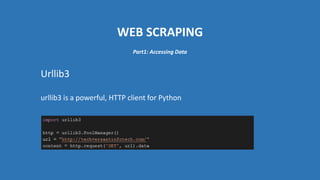
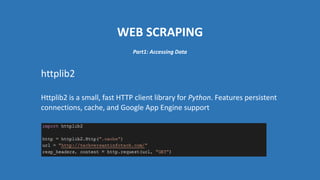
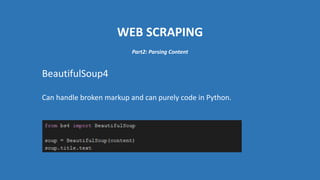
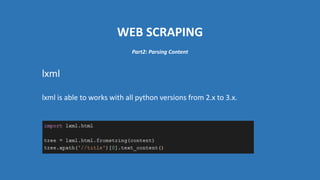
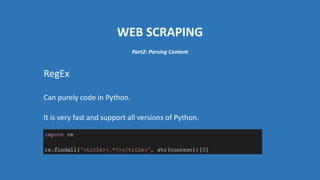
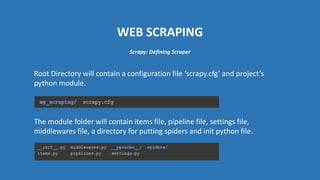
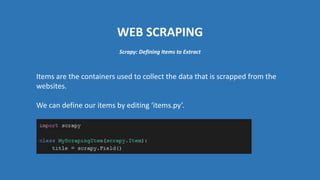
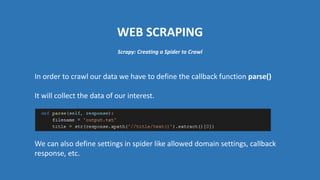
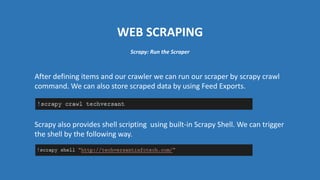
The document provides an introduction to web scraping using Python, explaining its purpose, methods, and tools like requests, BeautifulSoup, and Scrapy. It details how to access, parse, and save web data, and discusses the automation of scraping tasks with tools such as Selenium. The content is structured to guide readers through the concepts and practical applications of web scraping techniques.