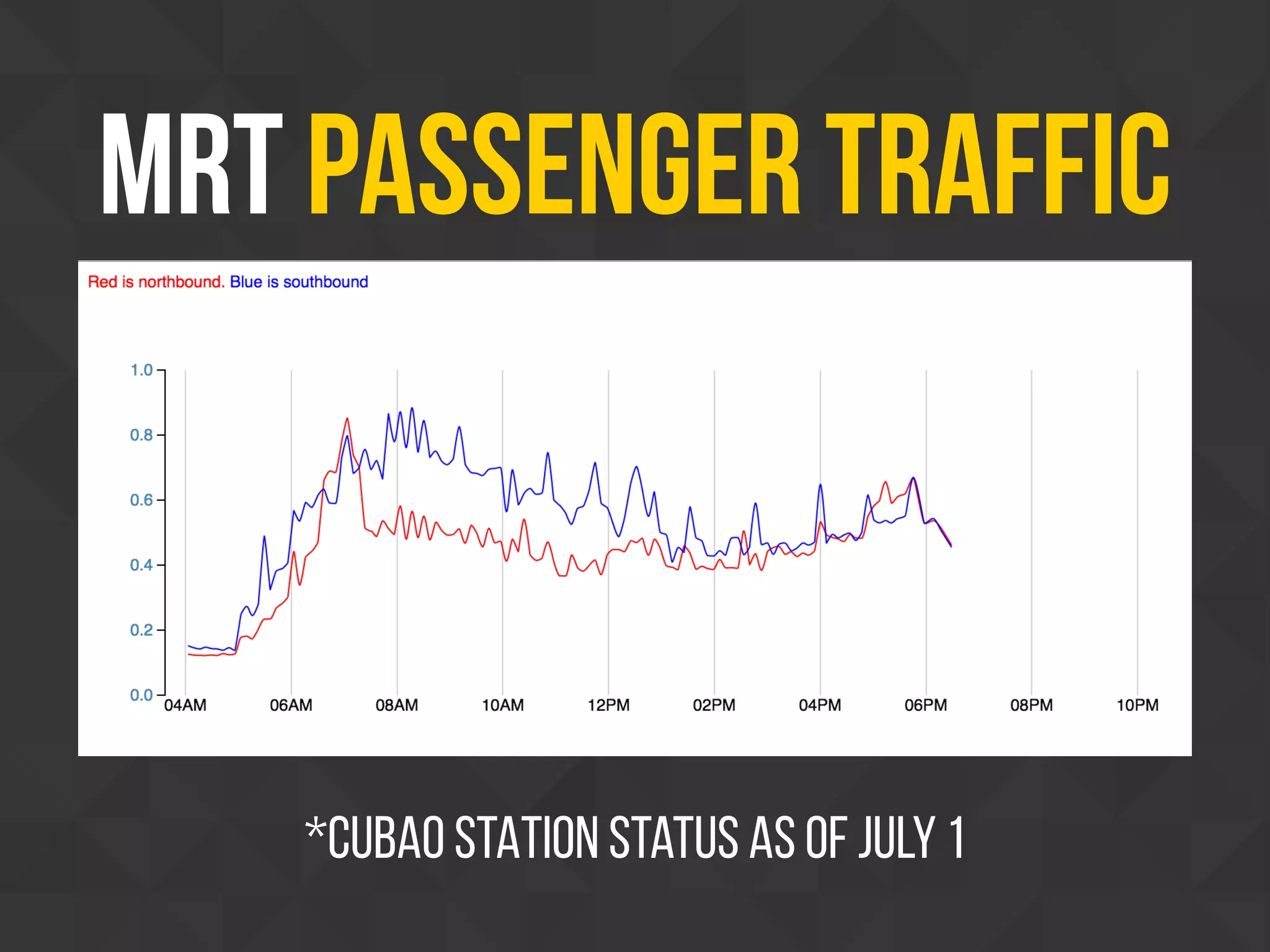
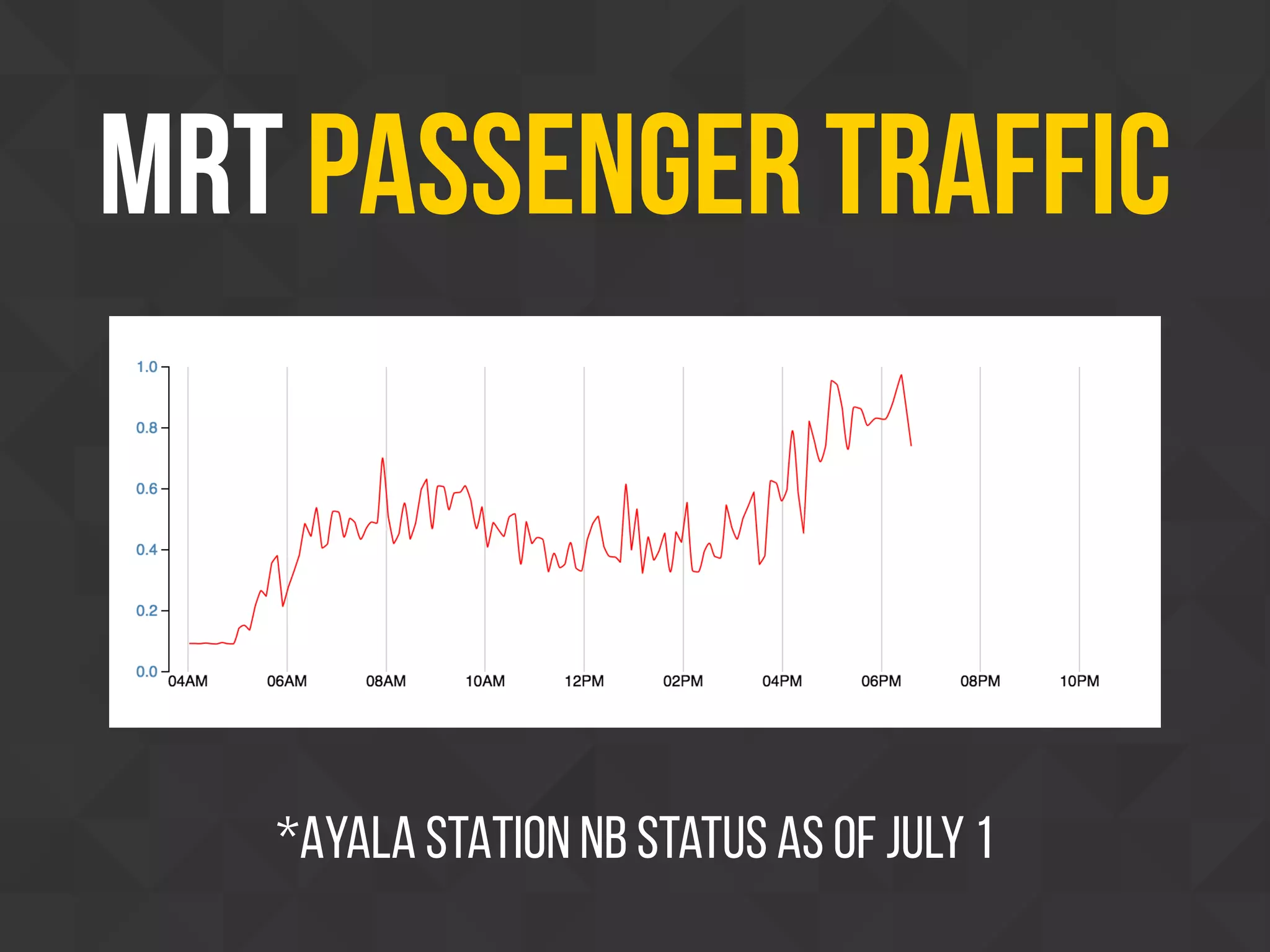
This document discusses using web scraping to extract structured data from unstructured sources on the internet. It introduces Scrapy, an open source and customizable Python framework for scraping websites. Scrapy processes requests asynchronously, handles errors and delays, and includes tools for parsing HTML and XML. Examples are given of how Scrapy is used for market analysis, academic research, government projects, and personal side projects involving scraping Philippine news, elections data, and transportation websites. Legal considerations around scraping public data are also briefly addressed.




































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






