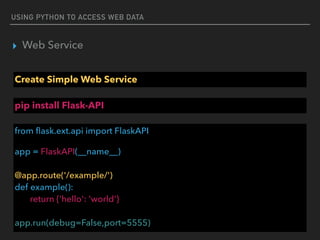
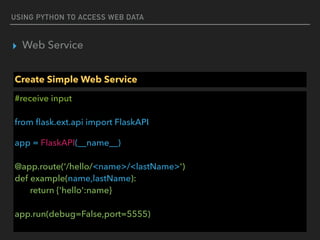
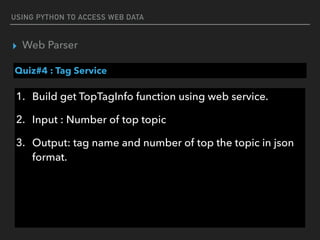
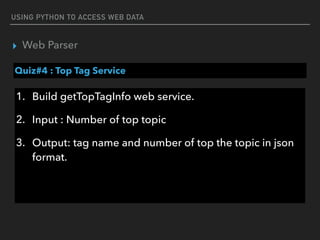
This document discusses using Python to access and process web data. It covers using the Requests library to make HTTP requests and get web content, parsing web content with Beautiful Soup and JSON, and accessing web services using REST. Example code is provided for making GET and POST requests, extracting data from HTML and JSON responses, and creating a simple Flask web service.



![USING PYTHON TO ACCESS WEB DATA
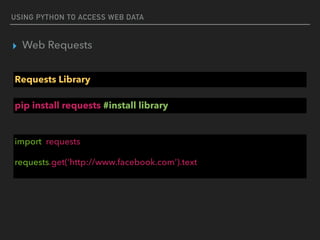
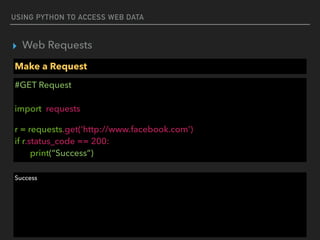
▸ Web Requests
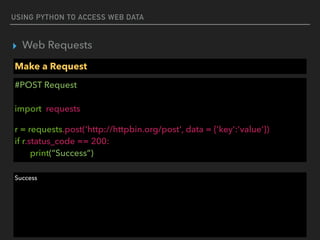
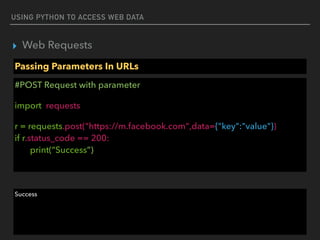
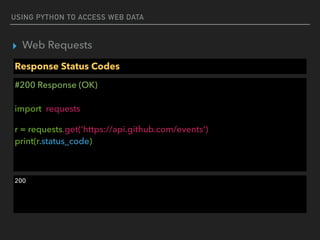
Response Status Codes
#200 Response (OK)
import requests
r = requests.get('https://api.github.com/events')
if r.status_code == requests.codes.ok:
print(data[0]['actor'])
{'url': 'https://api.github.com/users/ShaolinSarg', 'display_login': 'ShaolinSarg', 'avatar_url': 'https://
avatars.githubusercontent.com/u/6948796?', 'id': 6948796, 'login': 'ShaolinSarg', 'gravatar_id': ''}](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-15-320.jpg)
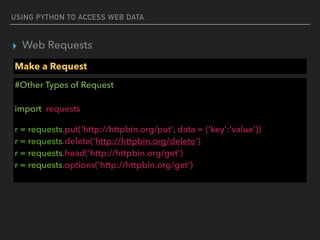
![USING PYTHON TO ACCESS WEB DATA
▸ Web Requests
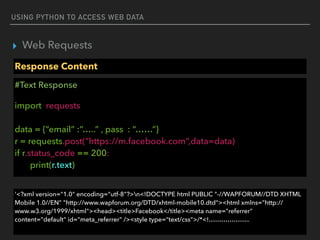
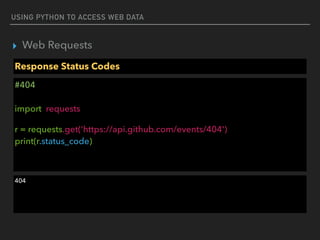
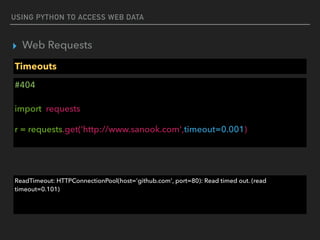
Response Headers
#404
import requests
r = requests.get('http://www.sanook.com')
print(r.headers)
print(r.headers[‘Date’])
{'Content-Type': 'text/html; charset=UTF-8', 'Date': 'Tue, 08 Nov 2016 14:38:41 GMT', 'Cache-
Control': 'private, max-age=0', 'Age': '16', 'Content-Encoding': 'gzip', 'Content-Length': '38089',
'Connection': 'keep-alive', 'Vary': 'Accept-Encoding', 'Accept-Ranges': 'bytes'}
Tue, 08 Nov 2016 14:38:41 GMT](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-18-320.jpg)
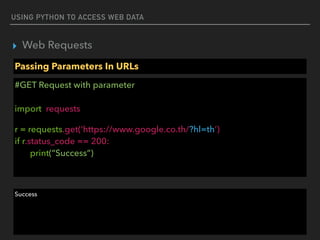
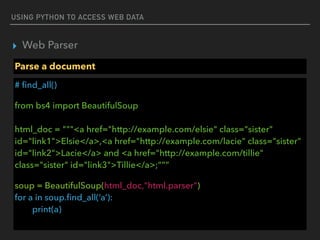
![USING PYTHON TO ACCESS WEB DATA
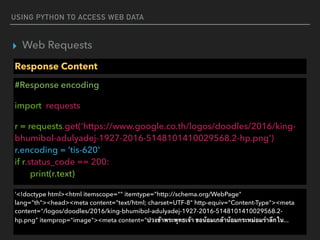
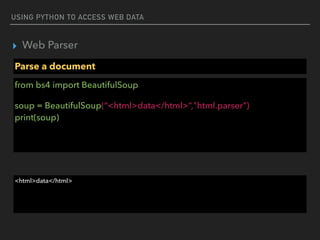
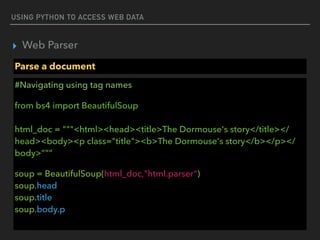
▸ Web Parser
Parse a document
#Access attribute
from bs4 import BeautifulSoup
html_doc = “<a href="http://example.com/elsie" >Elsie</a>”
soup = BeautifulSoup(html_doc,"html.parser")
print(soup.a[‘href’])
http://example.com/elsie](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-28-320.jpg)
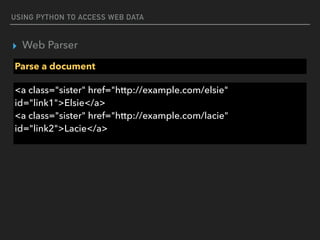
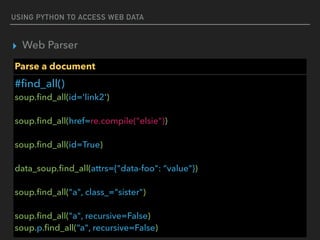
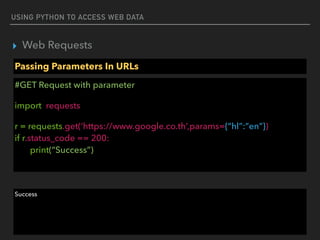
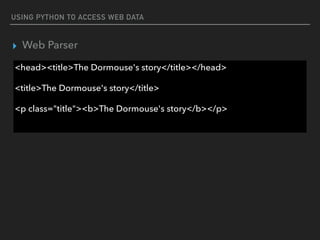
![USING PYTHON TO ACCESS WEB DATA
▸ Web Parser
Parse a document
re.compile(…..)
<a href=“http://192.x.x.x” class=“c1”>hello</a>
<a href=“https://192.x.x.x” class=“c1”>hello</a>
<a href=“https://www.com” class=“c1”>hello</a>
find_all(href=re.compile(‘(https|http)://[0-9.]’))
https://docs.python.org/2/howto/regex.html](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-33-320.jpg)
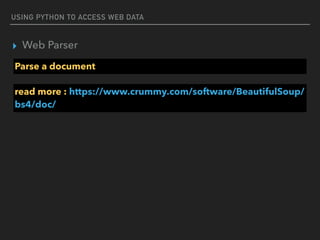
![USING PYTHON TO ACCESS WEB DATA
▸ Web Parser
JSON Parser : json
#JSON string
json_doc = “””{“employees":[
{"firstName":"John", "lastName":"Doe"},
{"firstName":"Anna", "lastName":"Smith"},
{"firstName":"Peter", "lastName":"Jones"}
]} “””](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-37-320.jpg)
![USING PYTHON TO ACCESS WEB DATA
▸ Web Parser
JSON Parser : json
#Parse string to object
import json
json_obj = json.loads(json_doc)
print(json_obj)
{'employees': [{'firstName': 'John', 'lastName': 'Doe'}, {'firstName': 'Anna', 'lastName': 'Smith'},
{'firstName': 'Peter', 'lastName': 'Jones'}]}](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-38-320.jpg)
![USING PYTHON TO ACCESS WEB DATA
▸ Web Parser
JSON Parser : json
#Access json object
import json
json_obj = json.loads(json_doc)
print(json_obj[‘employees’][0][‘firstName’])
print(json_obj[‘employees’][0][‘lastName’])
John
Doe](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-39-320.jpg)
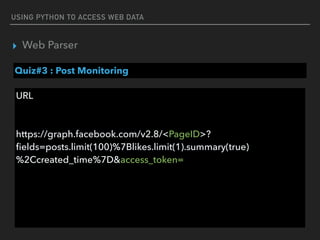

![USING PYTHON TO ACCESS WEB DATA
▸ Web Parser
JSON
{"employees":[
{"firstName":"John", "lastName":"Doe"},
{"firstName":"Anna", "lastName":"Smith"},
{"firstName":"Peter", "lastName":"Jones"}
]}
list
dict
key
value
read more : http://www.json.org/](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-51-320.jpg)


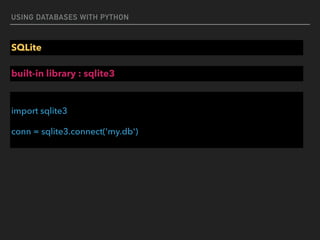
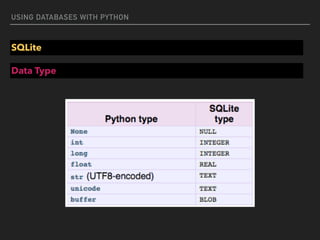
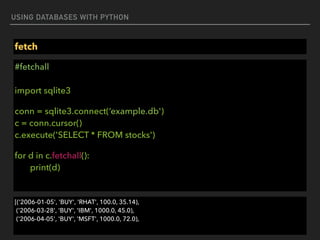
![USING DATABASES WITH PYTHON
Execute
#executemany
import sqlite3
conn = sqlite3.connect(‘example.db')
c = conn.cursor()
purchases = [('2006-03-28', 'BUY', 'IBM', 1000, 45.00),
('2006-04-05', 'BUY', 'MSFT', 1000, 72.00),
('2006-04-06', 'SELL', 'IBM', 500, 53.00),]
c.executemany('INSERT INTO stocks VALUES (?,?,?,?,?)', purchases)](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-65-320.jpg)
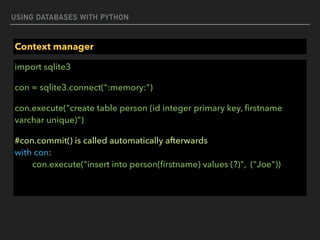

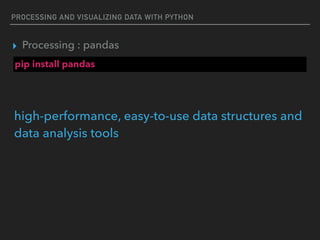
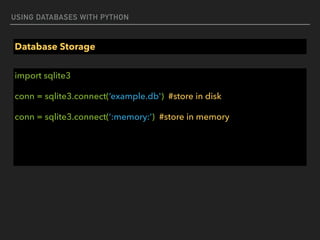
![USING DATABASES WITH PYTHON
Pandas : Series
#create series with Array-like
import pandas as pd
from numpy.random import rand
s = pd.Series(rand(5), index=['a', 'b', 'c', 'd', 'e'])
print(s)
a 0.690232
b 0.738294
c 0.153817
d 0.619822
e 0.4347](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-73-320.jpg)
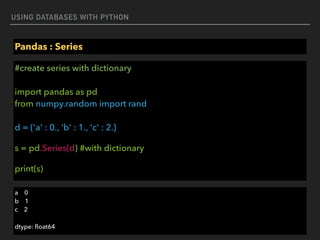
![USING DATABASES WITH PYTHON
Pandas : Series
#create series with Scalar
import pandas as pd
from numpy.random import rand
s = pd.Series(5., index=['a', 'b', 'a', 'd', ‘a']) #index can duplicate
print(s[‘a’])
a 5
a 5
a 5
dtype: float64](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-75-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : Series
#access series data
import pandas as pd
from numpy.random import rand
s = pd.Series(5., index=['a', 'b', 'a', 'd', ‘a']) #index can duplicate
print(s[0])
print(s[:3])
5.0
a 5
b 5
a 5
dtype: float64](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-76-320.jpg)
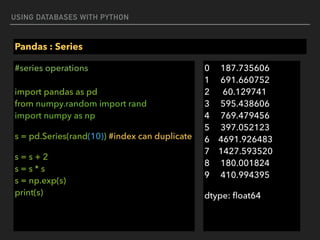
![USING DATABASES WITH PYTHON
Pandas : Series
#series filtering
import pandas as pd
from numpy.random import rand
import numpy as np
s = pd.Series(rand(10)) #index can duplicate
s = s[s > 0.1]
print(s)
1 0.708700
2 0.910090
3 0.380613
6 0.692324
7 0.508440
8 0.763977
9 0.470675
dtype: float64](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-78-320.jpg)
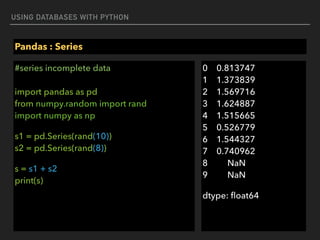
![USING DATABASES WITH PYTHON
Pandas : Series
#create series with Array-like
import pandas as pd
from numpy.random import rand
s = pd.Series(rand(5), index=['a', 'b', 'c', 'd', 'e'])
print(s)
a 0.690232
b 0.738294
c 0.153817
d 0.619822
e 0.4347](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-80-320.jpg)
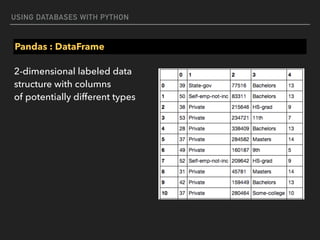
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#create dataframe with dict
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df)
one two
a 1 1
b 2 2
c 3 3
d NaN 4](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-82-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#create dataframe with dict list
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df)
one two
0 1 4
1 2 3
2 3 2
3 4 1](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-83-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#access dataframe column
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df[‘one’])
0 1
1 2
2 3
3 4
Name: one, dtype: float64](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-84-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#access dataframe row
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df.iloc[:3])
one two
0 1 4
1 2 3
2 3 2](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-85-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#add new column
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
df['three'] = [1,2,3,2]
print(df)
one two three
0 1 4 1
1 2 3 2
2 3 2 3
3 4 1 2](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-86-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#show data : head() and tail()
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
df['three'] = [1,2,3,2]
print(df.head())
print(df.tail())
one two three
0 1 4 1
1 2 3 2
2 3 2 3
3 4 1 2](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-87-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe summary
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df.describe())](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-88-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe function
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df.mean())
one 2.5
two 2.5
dtype: float64](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-89-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe function
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df.corr()) #calculate correlation
one two
one 1 -1
two -1 1](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-90-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe filtering
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df[(df[‘one’] > 1) & (df[‘one’] < 3)] )
one two
1 2 3](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-91-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe filtering with isin
d = {'one' : [1., 2., 3., 4.], 'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
print(df[df[‘one’].isin([2,4])] )
one two
1 2 3
3 4 1](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-92-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe with row data
d = [ [1., 2., 3., 4.], [4., 3., 2., 1.]]
df = pd.DataFrame(d)
df.columns = ["one","two","three","four"]
print(df)
one two three four
0 1 2 3 4
1 4 3 2 1](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-93-320.jpg)
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe sort values
d = [ [2., 1., 3., 4.], [1., 3., 2., 4.]]
df = pd.DataFrame(d)
df.columns = ["one","two","three","four"]
df = df.sort_values([“one”,”two”],ascending=[1,0])
print(df)
one two three four
0 2 1 3 4
1 1 3 2 4](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-94-320.jpg)
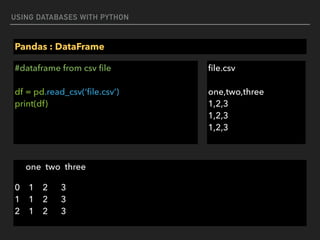
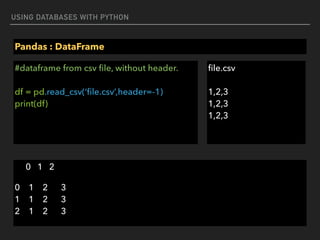
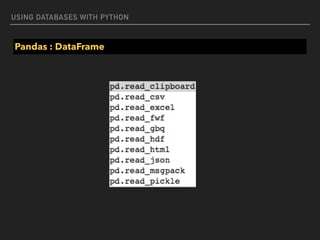
![USING DATABASES WITH PYTHON
Pandas : DataFrame
#dataframe from html, need to install lxml first (pip install lxml)
df = pd.read_html(‘https://simple.wikipedia.org/wiki/
List_of_U.S._states’)
print(df[0])
Abbreviation State Name Capital Became a State
1 AL Alabama Montgomery December 14, 1819
2 AK Alaska Juneau January 3, 1959
3 AZ Arizona Phoenix February 14, 1912](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-98-320.jpg)
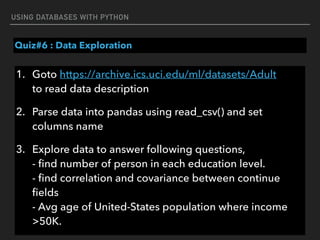
![USING DATABASES WITH PYTHON
Quiz#6 : Data Exploration
df[3].value_counts()](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-100-320.jpg)

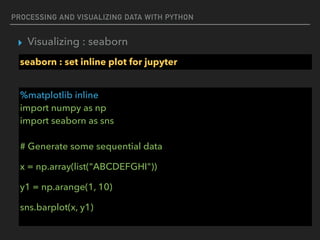
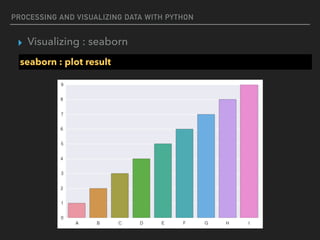
![PROCESSING AND VISUALIZING DATA WITH PYTHON
▸ Visualizing : seaborn
seaborn : set layout
%matplotlib inline
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
f,ax = plt.subplots(1,1,figsize=(10, 10))
sns.barplot(x=[1,2,3,4,5],y=[3,2,3,4,2])](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-104-320.jpg)
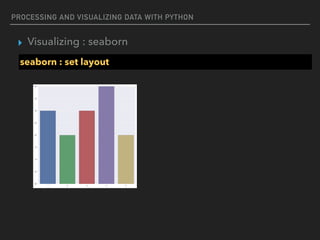
![PROCESSING AND VISUALIZING DATA WITH PYTHON
▸ Visualizing : seaborn
seaborn : set layout
%matplotlib inline
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
f,ax = plt.subplots(2,2,figsize=(10, 10))
sns.barplot(x=[1,2,3,4,5],y=[3,2,3,4,2],ax=ax[0,0])
sns.distplot([3,2,3,4,2],ax=ax[0,1])](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-106-320.jpg)
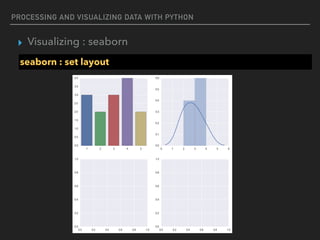
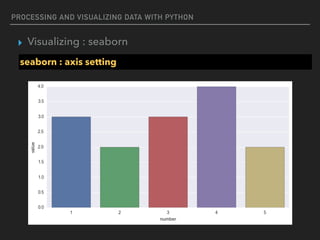
![PROCESSING AND VISUALIZING DATA WITH PYTHON
▸ Visualizing : seaborn
seaborn : axis setting
%matplotlib inline
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
f,ax = plt.subplots(figsize=(10, 5))
sns.barplot(x=[1,2,3,4,5],y=[3,2,3,4,2])
ax.set_xlabel("number")
ax.set_ylabel("value")](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-108-320.jpg)
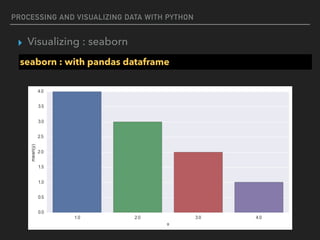
![PROCESSING AND VISUALIZING DATA WITH PYTHON
▸ Visualizing : seaborn
seaborn : with pandas dataframe
%matplotlib inline
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
d = {'x' : [1., 2., 3., 4.], 'y' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)
f,ax = plt.subplots(figsize=(10, 5))
sns.barplot(x=‘x’,y=‘y’,data=df)](https://image.slidesharecdn.com/funwithpython-161113140606/85/Fun-with-Python-110-320.jpg)










































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)












