Download as PDF, PPTX

















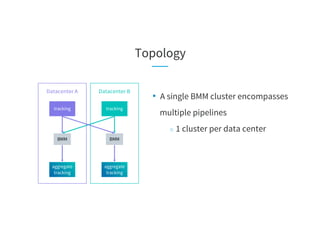



![On-demand Diagnostics
Brooklin
Engine
Diagnostics
Rest API
ZooKeeper
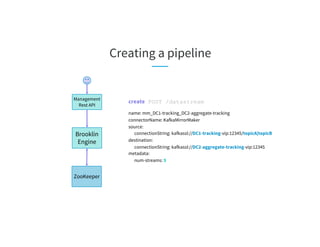
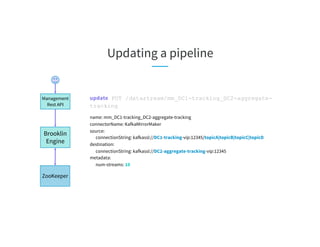
getAllStatus GET /diag?datastream=mm_DC1-tracking_DC2-aggregate-tracking
host1.prod.linkedin.com:
datastream: mm_DC1-tracking_DC2-aggregate-tracking
assignedTopicPartitions: [topicA-0, topicA-3, topicB-0, topicB-2]
autoPausedPartitions: [{topicA-3: {reason: SEND_ERROR, description: failed to produce messages from this
partition}}]
manuallyPausedPartitions: []
host2.prod.linkedin.com:
datastream: mm_DC1-tracking_DC2-aggregate-tracking
assignedTopicPartitions: [topicA-1, topicA-2, topicB-1, topicB-3]
autoPausedPartitions: []
manuallyPausedPartitions: []](https://image.slidesharecdn.com/03celiakung-181023060113/85/More-Data-More-Problems-Scaling-Kafka-Mirroring-Pipelines-at-LinkedIn-35-320.jpg)






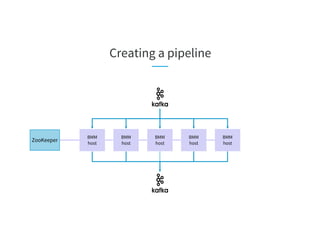
![Flushless Produce
sp0 consumer producer
checkpoint
manager
o1, o2 o1, o2 o1, o2
o1
o2
Source
Destination
ack(sp0, o2)
dp0
dp1
● Checkpoint manager maintains producer-acknowledged offsets for
each source partition
Source partition sp0
in-flight: [o1]
acked: [o2]
safe checkpoint: --](https://image.slidesharecdn.com/03celiakung-181023060113/85/More-Data-More-Problems-Scaling-Kafka-Mirroring-Pipelines-at-LinkedIn-44-320.jpg)
![Flushless Produce
sp0 consumer producer
checkpoint
manager
o3, o4 o3, o4 o3, o4
o3
o4
Source
Destination
ack(sp0, o1)
dp0
dp1
● Update safe checkpoint to largest acknowledged offset that is less
than oldest in-flight (if any)
Source partition sp0
in-flight: [o3, o4]
acked: [o1, o2]
safe checkpoint: o2](https://image.slidesharecdn.com/03celiakung-181023060113/85/More-Data-More-Problems-Scaling-Kafka-Mirroring-Pipelines-at-LinkedIn-45-320.jpg)

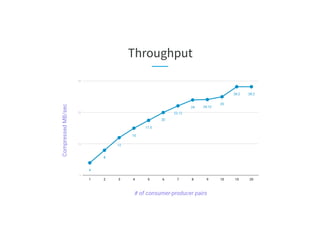
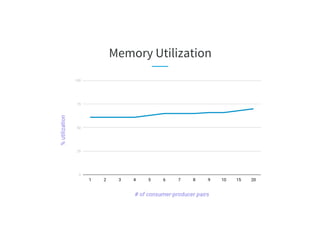
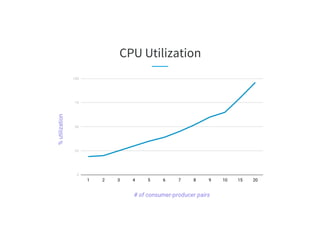








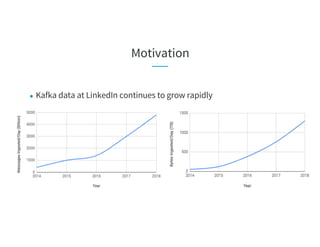
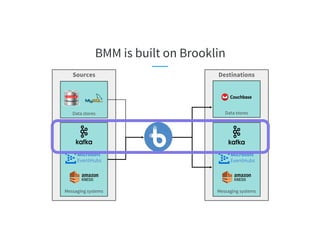
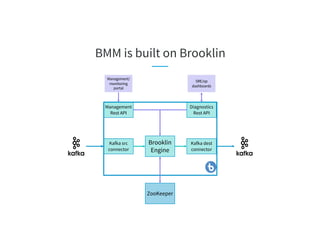
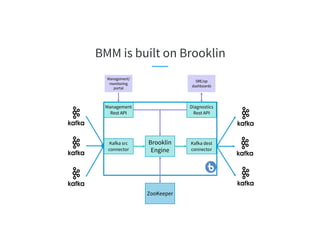
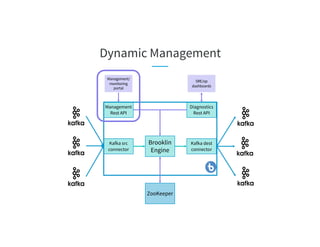
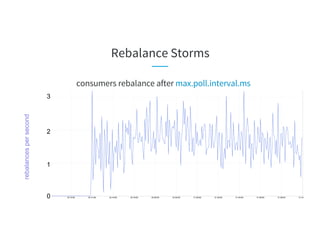
The document discusses the challenges of scaling Kafka MirrorMaker (KMM) pipelines at LinkedIn, which are facing issues with scalability, operability, and fragility due to rapid data growth and complex configurations. It introduces Brooklin MirrorMaker (BMM), which is built on the Brooklin stream ingestion service, designed for higher stability and performance management. The document details BMM's architecture, diagnostics, and performance metrics, highlighting its efficiency in managing data mirroring across multiple data centers.












































![[ODSC EUROPE 2022] Eagleeye - Data Pipeline for Anomaly Detection in Cyber Se...](https://cdn.slidesharecdn.com/ss_thumbnails/odsceurope2022eagleeye-datapipelineforanomalydetectionincybersecurity-250320161155-77fa6dd8-thumbnail.jpg?width=640&height=640&fit=bounds)









































