This document provides an overview of linear algebra concepts that are essential for machine learning, focusing on factorization and linear transformations. It covers topics such as row and column spaces, rank of a matrix, inner product spaces, the Gram-Schmidt process, and examples of linear transformations. Key concepts include the properties of matrix factorizations, the definition of linear operators, and the conditions for linear mappings to be one-to-one and onto.



![Rank of a Matrix
The dimension of the row (column) space of A is called the
row (column) rank of A.
The row rank and column rank of the m × n matrix A = [aij ]
are equal.
Dr. Ceni Babaoglu cenibabaoglu.com
Linear Algebra for Machine Learning: Factorization and Linear Transformations](https://image.slidesharecdn.com/3-190206231415/85/3-Linear-Algebra-for-Machine-Learning-Factorization-and-Linear-Transformations-4-320.jpg)














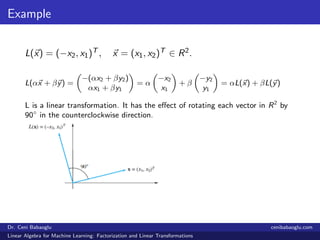





![Example
Let L : R3 → R3 be defined by
L([ u1 u2 u3 ]) = [ 2u1 − u3 u1 + u2 − u3 u3 ]
and S = {[1 0 0], [0 1 0], [0 0 1]} be the natural basis
for R3. The representation of L with respect of S is
A =
2 0 −1
1 1 −1
0 0 1
.
Considering S = {[1 0 1], [0 1 0], [1 1 0]} as ordered
bases for R3, the transition matrix P from S to S is
P =
1 0 1
0 1 1
1 0 0
P−1
=
0 0 1
−1 1 1
1 0 −1
.
Dr. Ceni Babaoglu cenibabaoglu.com
Linear Algebra for Machine Learning: Factorization and Linear Transformations](https://image.slidesharecdn.com/3-190206231415/85/3-Linear-Algebra-for-Machine-Learning-Factorization-and-Linear-Transformations-25-320.jpg)





































































