Recommended
PDF
Amazon S3を中心とするデータ分析のベストプラクティス
PDF
MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~(映像情報メディア学会2021年冬季大会企画セッショ...
PDF
20200630 AWS Black Belt Online Seminar Amazon Cognito
PPTX
データ収集の基本と「JapanTaxi」アプリにおける実践例
PDF
PDF
Amazon SageMaker 推論エンドポイントを利用したアプリケーション開発
PDF
20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS...
PDF
RDF Semantic Graph「RDF 超入門」
PDF
PDF
20190220 AWS Black Belt Online Seminar Amazon S3 / Glacier
PDF
PDF
AWS Black Belt Techシリーズ Amazon EMR
PDF
リクルートのビッグデータ活用基盤とビッグデータ活用のためのメタデータ管理Webのご紹介
PDF
AWS Black Belt Online Seminar 2017 Amazon DynamoDB
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
PDF
AWS Black Belt Online Seminar AWS Key Management Service (KMS)
PDF
20191001 AWS Black Belt Online Seminar AWS Lake Formation
PDF
Amazon SageMaker で始める機械学習
PPTX
技術者として抑えておきたい Power BI アーキテクチャ
PPTX
PDF
Azure Monitor Logで実現するモダンな管理手法
PDF
ブレインパッドにおける機械学習プロジェクトの進め方
PDF
Database Encryption and Key Management for PostgreSQL - Principles and Consid...
PDF
Data × AI でどんな業務が改善できる? 製造業様向け Data × AI 活用ユースケース & 製造MVPソリューションのご紹介
PDF
Dapr × Kubernetes ではじめるポータブルなマイクロサービス(CloudNative Days Tokyo 2020講演資料)
PPTX
S3 整合性モデルと Hadoop/Spark の話
PPTX
PDF
Redmine + MySQL 応答性能の調査結果と対策
PDF
PDF
202106 AWS Black Belt Online Seminar 小売現場のデータを素早くビジネス に活用するAWSデータ基盤
More Related Content
PDF
Amazon S3を中心とするデータ分析のベストプラクティス
PDF
MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~(映像情報メディア学会2021年冬季大会企画セッショ...
PDF
20200630 AWS Black Belt Online Seminar Amazon Cognito
PPTX
データ収集の基本と「JapanTaxi」アプリにおける実践例
PDF
PDF
Amazon SageMaker 推論エンドポイントを利用したアプリケーション開発
PDF
20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS...
PDF
RDF Semantic Graph「RDF 超入門」
What's hot
PDF
PDF
20190220 AWS Black Belt Online Seminar Amazon S3 / Glacier
PDF
PDF
AWS Black Belt Techシリーズ Amazon EMR
PDF
リクルートのビッグデータ活用基盤とビッグデータ活用のためのメタデータ管理Webのご紹介
PDF
AWS Black Belt Online Seminar 2017 Amazon DynamoDB
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
PDF
AWS Black Belt Online Seminar AWS Key Management Service (KMS)
PDF
20191001 AWS Black Belt Online Seminar AWS Lake Formation
PDF
Amazon SageMaker で始める機械学習
PPTX
技術者として抑えておきたい Power BI アーキテクチャ
PPTX
PDF
Azure Monitor Logで実現するモダンな管理手法
PDF
ブレインパッドにおける機械学習プロジェクトの進め方
PDF
Database Encryption and Key Management for PostgreSQL - Principles and Consid...
PDF
Data × AI でどんな業務が改善できる? 製造業様向け Data × AI 活用ユースケース & 製造MVPソリューションのご紹介
PDF
Dapr × Kubernetes ではじめるポータブルなマイクロサービス(CloudNative Days Tokyo 2020講演資料)
PPTX
S3 整合性モデルと Hadoop/Spark の話
PPTX
PDF
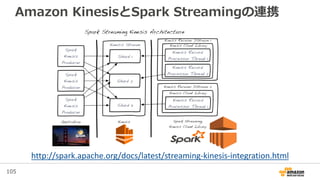
Redmine + MySQL 応答性能の調査結果と対策
Similar to AWSでのビッグデータ分析
PDF
PDF
202106 AWS Black Belt Online Seminar 小売現場のデータを素早くビジネス に活用するAWSデータ基盤
PDF
AWS Lambdaによるデータ処理理の⾃自動化とコモディティ化
PDF
ビッグデータサービス群のおさらい & AWS Data Pipeline
PDF
PDF
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
PDF
AWS初心者向けWebinar AWSでBig Data活用
PDF
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
PDF
PDF
PDF
Data discoveryを支えるawsのbig data技術と最新事例
PDF
AWS Black Belt Online Seminar 2017 AWS Summit Tokyo 2017 まとめ
PDF
[Sumo Logic x AWS 共催セミナー_20190829] Sumo Logic on AWS -AWS を活用したログ分析とセキュリティモニ...
PPTX
20121221 AWS re:Invent 凱旋報告
PDF
PDF
Cm re growth-devio-mtup11-sapporo-004
PPTX
Security Operations and Automation on AWS
PDF
【IVS CTO Night & Day】AWSにおけるビッグデータ活用
PDF
20151030 オープンデータとセキュリティon aws
PDF
More from Amazon Web Services Japan
PDF
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
PDF
マルチテナント化で知っておきたいデータベースのこと
PDF
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
PDF
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
PDF
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
PPTX
20220409 AWS BLEA 開発にあたって検討したこと
PDF
Infrastructure as Code (IaC) 談義 2022
PPTX
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
PDF
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
PDF
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
PDF
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
PDF
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
PDF
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
PDF
Amazon QuickSight の組み込み方法をちょっぴりDD
PDF
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
PDF
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
PDF
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
PDF
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
PDF
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
PDF
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
PDF
アジャイル導入が止まる3つの壁 ─ 文化・他部門・組織プロセスをどう乗り越えるか
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
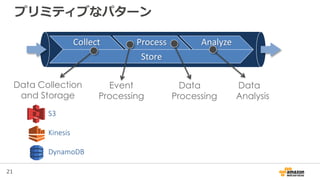
AWSでのビッグデータ分析 1. 2. 3. 3
自己紹介
• Ryosuke Iwanaga (岩永 亮介)
– a.k.a @riywo
• Amazon Data Services Japan
• Solutions Architect
– Startup, Gaming
– Big Data / Deployment / Container
• Before Amazon
– Software Engineer / Ops Engineer / DBA / etc.
4. 4
Solutions Architect at ADSJ
• AWSの日本での利用
促進を行う
– AWSに関する技術支
援(無料)
– セミナー、ハンズオン
等登壇
– ブログ等での情報発信
• Black beltやってます
毎週水曜18:00〜
Black belt Webinar配信中!
#awsblackbelt
「AWS セミナー」で検索
5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 14
• Tokyoリージョンは2つのAZで構成
• 2つのAZを利用した冗長構成も簡単
各リージョンは複数のAZで構成される
EU (Ireland)
Availability
Zone A
Availability
Zone C
Availability
Zone B
Asia Pacific (Tokyo)
Availability
Zone A
Availability
Zone B
US West (Oregon)
Availability
Zone A
Availability
Zone B
US West(Northern California)
Availability
Zone A
Availability
Zone B
Asia Pacific (Singapore)
Availability
Zone A
Availability
Zone B
AWS GovCloud (US)
Availability
Zone A
Availability
Zone B
South America (Sao Paulo)
Availability
Zone A
Availability
Zone B
US East (Northern Virginia)
Availability
Zone D
Availability
Zone C
Availability
Zone B
Availability
Zone E
Availability
Zone A
Asia Pacific (Sydney)
Availability
Zone A
Availability
Zone B
EU (Frankfurt)
Availability
Zone A
Availability
Zone B
*AZ=Availability Zoneの略
距離の離れたデータセンタ群
15. 16. 16
TECHNICAL &
BUSINESS
SUPPORT
Account
Management
Support
Professional
Services
Solutions
Architects
Training &
Certification
Security
& Pricing
Reports
Partner
Ecosystem
AWS
MARKETPLACE
Backup
Big Data
& HPC
Business
Apps
Databases
Development
Industry
Solutions
Security
MANAGEMENT
TOOLS
Queuing
Notifications
Search
Orchestration
Email
ENTERPRISE
APPS
Virtual
Desktops
Storage
Gateway
Sharing &
Collaboration
Email &
Calendaring
Directories
HYBRID CLOUD
MANAGEMENT
Backups
Deployment
Direct
Connect
Identity
Federation
Integrated
Management
SECURITY &
MANAGEMENT
Virtual Private
Networks
Identity &
Access
Encryption
Keys
Configuration Monitoring Dedicated
INFRASTRUCTURE
SERVICES
Regions
Availability
Zones
Compute
Storage
O b j e c t s
,
B l o c k s ,
F i l e s
Databases
SQL, NoSQL,
Caching
CDNNetworking
PLATFORM
SERVICES
APP
Mobile
& Web
Front-end
Functions
Identity
Data Store
Real-time
DEVELOPMENT
Containers
Source
Code
Build
Tools
Deploymen
t
DevOps
MOBILE
Sync
Identity
Push
Notifications
Mobile
Analytics
Mobile
Backend
ANALYTICS
Data
Warehousing
Hadoop
Streaming
Data
Pipelines
Machine
Learning
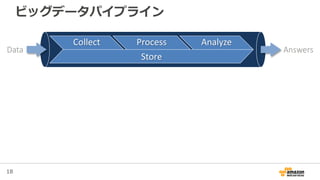
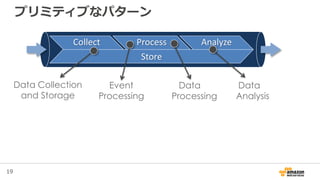
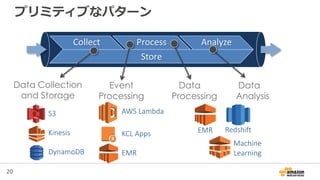
17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 41
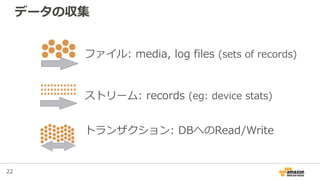
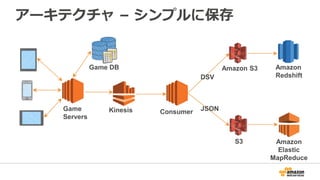
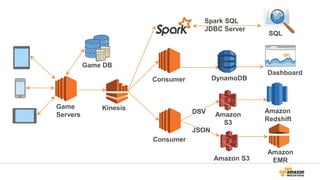
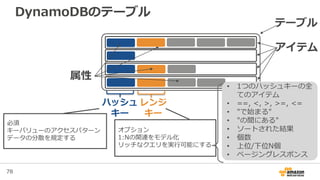
データ収集
Source of data
• Mobile devices
• Game servers
• Ad networks
Data size & growth
• 500 G+/day
• 500 M+ events/day
• Size of event ~ 1 KB
Analytics Data
{"player_id":"323726381807586881","player_level":169,"device":"iPhone
5","version":"iOS 7.1.2”,"platfrom":"ios","client_build":"440”,
"db":”mw_dw_ios","table":"player_login",
"uuid":"1414566719-rsl3hvhu7o","time_created":"2014-10-29 00:11:59”}
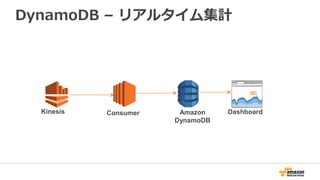
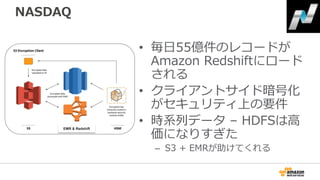
42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. NASDAQ
レガシーなデータウェアハウス
• 高価 (毎年 $1.16M)
• 限られた容量 (オンラインデータだと1年)
• 毎取引日に40〜80億行が追加され保存されている:
– Orders
– Trades
– Quotes
– Market Data
– Security Master
– Membership
DWはマーケットシェアの分析、
クライアントのアクティビティ、
監視、請求の仕組み、その他から
使われる
53. 54. 55. 56. 57. 58. 58
Presto-Amazon Kinesis connector by Qubole
• KinesisのStreamに対
して直接PrestoのSQL
を実行できる
– QuboleというPresto as
a Serviceなら簡単に設
定可能
• チェックポイントを
使ってリアルタイム検
出やダッシュボード等
http://aws.typepad.com/sajp/2015/07/presto-amazon-kinesis-connector-for-interactively-querying-streaming-data.html
59. 59
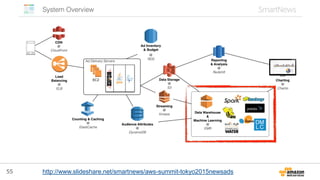
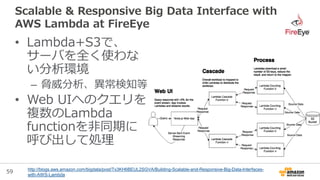
Scalable & Responsive Big Data Interface with
AWS Lambda at FireEye
http://blogs.aws.amazon.com/bigdata/post/Tx3KH6BEUL2SGVA/Building-Scalable-and-Responsive-Big-Data-Interfaces-
with-AWS-Lambda
• Lambda+S3で、
サーバを全く使わな
い分析環境
– 脅威分析、異常検知等
• Web UIへのクエリを
複数のLambda
functionを非同期に
呼び出して処理
60. 61. 62. 63. Amazon S3
• Amazon S3はオブジェクトを保存(“ファイル”的な)
• オブジェクトはバケットに保存される
• バケットは1つのAWSリージョンの中で、複数のAZに
渡って複製してデータを保持する
– クロスリージョンの複製も、最近リリースされました!
• 高い耐久性、高い可用性、高いスケーラビリティ
• 安全
• 99.999999999%の耐久性を持つ設計
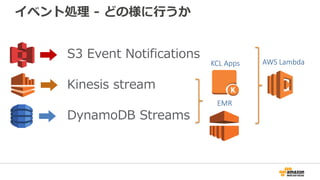
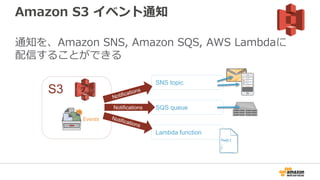
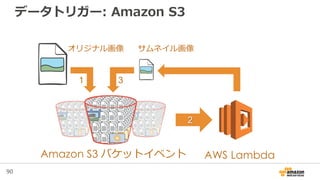
64. 65. Amazon S3 イベント通知
通知を、Amazon SNS, Amazon SQS, AWS Lambdaに
配信することができる
S3
Events
SNS topic
SQS queue
Lambda function
Notifications
Foo() {
…
}
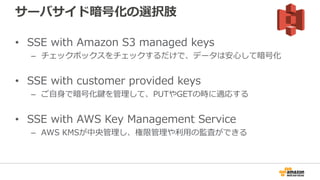
66. サーバサイド暗号化の選択肢
• SSE with Amazon S3 managed keys
– チェックボックスをチェックするだけで、データは安心して暗号化
• SSE with customer provided keys
– ご自身で暗号化鍵を管理して、PUTやGETの時に適応する
• SSE with AWS Key Management Service
– AWS KMSが中央管理し、権限管理や利用の監査ができる
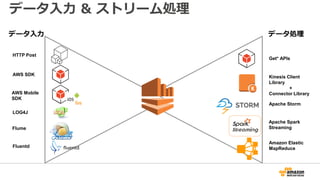
67. 68. 69. 70. 71. 72. データ入力 & ストリーム処理
HTTP Post
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client
Library
+
Connector Library
Apache Storm
Amazon Elastic
MapReduce
データ入力 データ処理
AWS Mobile
SDK
Apache Spark
Streaming
73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 主な処理パターン2つ
• ストリーム処理 (リアルタイム)
– データストリームのイベントに対してリアルタイムで反応
– 比較的シンプルなデータ計算 (集約、フィルタ、スライディング
ウィンドウ)
• マイクロバッチ (準リアルタイム)
– データストリームのイベントの小さいバッチに対する準リアルタイ
ムな処理
– 分析のための標準的な処理やクエリエンジン
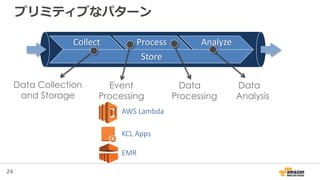
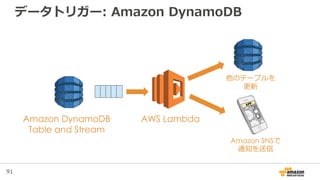
83. 84. クラウド上でのイベント駆動なコンピュート
• Lambda functions: ステートレスでリクエスト
駆動なコード実行
– 他のサービスでのイベントからトリガーされる
• Amazon S3バケットにPUTされた
• Amazon DynamoDBテーブルに書き込まれた
• Amazon Kinesisストリームのレコード
– これらを簡単にしてくれる
• データがクラウドに来たらすぐに変換する
• データ駆動な監査、分析、そして通知を実行する
• キックされるワークフロー
85. 86. 87. 87
Bring your own code
• Node.jsまたはJavaで書かれたコー
ドを実行
• コード内では以下も可能
– スレッド/プロセスの生成
– バッチスクリプトや他の実行ファイルの実行
– /tmpのread/write
• 各種ライブラリも利用可能
– ネイティブライブラリも可能
– 利用するライブラリを一緒にアップロード
88. 89. 90. 91. 92. 93. Kinesis Client Library (KCL)
Client library for fault-tolerant, at least-once, Continuous
Processing
• Shardと同じ数のWorker
• Workerを均等にロードバランシング
• 障害感知と新しいWorkerの立ち上げ
• Shardの数に応じてworkerが動作する
• ShardのSplitやMergeにも追従
• AutoScalingでエラスティック
• チェックポインティングとAt least once処理
これらの煩雑な処理を意識することなく
ビジネスロジックに集中することができる。
94. 95. 96. 97. 97
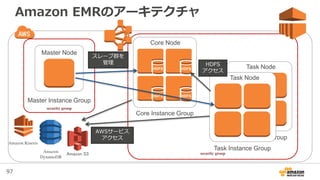
Task Node
Task Instance Group
Amazon EMRのアーキテクチャ
Master Node
Master Instance Group
Amazon S3
Core Node
Core Instance Group
HDFS HDFS
HDFS HDFS
Task Node
Task Instance Group
スレーブ群を
管理 HDFS
アクセス
AWSサービス
アクセス
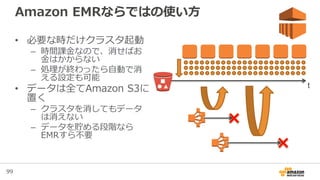
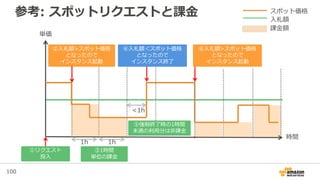
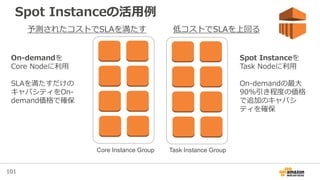
98. 99. 100. 101. 101
Spot Instanceの活用例
Task Instance GroupCore Instance Group
予測されたコストでSLAを満たす 低コストでSLAを上回る
On-demandを
Core Nodeに利用
SLAを満たすだけの
キャパシティをOn-
demand価格で確保
Spot Instanceを
Task Nodeに利用
On-demandの最大
90%引き程度の価格
で追加のキャパシ
ティを確保
102. 102
Hive, Spark on Amazon EMR
• Applicationサポート
– クラスタ起動時に指定
– すぐに利用可能
• Metastore
– デフォルトではMaster
上のMySQLに保存
– hive-site.xmlを設定し
て任意のMySQLも利用
可能
$ aws emr create-cluster …
--applications Name=Hive Name=Spark
…
103. 103
CREATE TABLE call_data_records (
start_time bigint,
end_time bigint,
…
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ","
STORED BY
'com.amazon.emr.kinesis.hive.KinesisStorageHandler'
TBLPROPERTIES("kinesis.stream.name"=”MyTestStream")
;
Amazon EMRでの連携: Hive + Amazon Kinesis
104. 105. 106. 107. Apache Spark Streaming
• ウィンドウベースの変換
– countByWindow, countByValueAndWindow etc.
• スケーラビリティ
– 分割された入力stream
– それぞれのレシーバは別々のワーカ上で動くことができる
• 耐障害性
– StreamingのためのWrite Ahead Log (WAL)
– ステートフルで、確実に一度だけ
108. 108
Amazon EMR Release 4.0.0
• Apache Bigtopベースの新しいパッケージング
– より高速なリリースサイクル
– Release 4.0.0(7/24リリース)のアプリケーションバージョン
• Hadoop 2.6.0, Hive 1.0, Spark 1.4.1など
• アプリケーションの設定カスタマイズが簡単
– 設定値を渡すと、設定ファイルを変更してくれる
• Spark on YARNのDynamic Allocationが簡単
– 面倒なJAR配置や設定が済んでいる
109. 110. 110
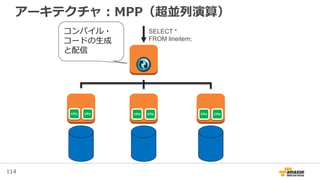
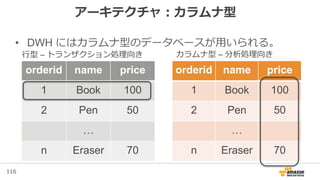
Amazon Redshift の概要
• Data Warehouse as a Service – 分析用に整理された大量の統合
業務データの管理サービス(フルマネージドサービス)
• 拡張性:数百GB〜数PBまで拡張可能
• 高速:カラムナ型、超並列演算(MPP)
• 低額:インスタンスの従量課金(初期費用、ライセンス費用不要)
111. 111
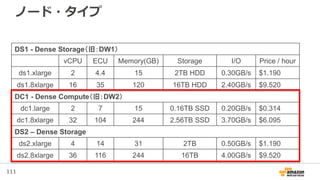
ノード・タイプ
DS1 - Dense Storage(旧:DW1)
vCPU ECU Memory(GB) Storage I/O Price / hour
ds1.xlarge 2 4.4 15 2TB HDD 0.30GB/s $1.190
ds1.8xlarge 16 35 120 16TB HDD 2.40GB/s $9.520
DC1 - Dense Compute(旧:DW2)
dc1.large 2 7 15 0.16TB SSD 0.20GB/s $0.314
dc1.8xlarge 32 104 244 2.56TB SSD 3.70GB/s $6.095
DS2 – Dense Storage
ds2.xlarge 4 14 31 2TB 0.50GB/s $1.190
ds2.8xlarge 36 116 244 16TB 4.00GB/s $9.520
112. 113. 114. 115. 116. 117. 118. 119. 119
Machine Learning as a Service
Amazonが提供するアルゴリズム
– 利用者は自分でアルゴリズムの実装や詳細な
チューニングを行う必要がない
パッケージサービスとしての提供
– 必要なワークフローが予め提供されている
スケーラビリティ
– 利用者はシステムの拡張やその運用について
も考える必要がない
120. 121. 122. 123. 124. 125. 126. 127. 128. 129. 130. 131. 132. 133.















































![71
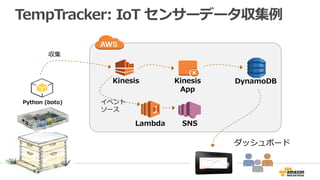
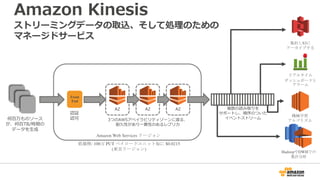
Amazon Kinesis構成内容
Data
Sources
App.4
[Machine
Learning]
App.1
[Aggregate &
De-Duplicate]
Data
Sources
Data
Sources
Data
Sources
App.2
[Metric
Extraction]
S3
DynamoDB
Redshift
App.3
[Real-time
Dashboard]
Data
Sources
Availability
Zone
Shard 1
Shard 2
Shard N
Availability
Zone
Availability
Zone
Kinesis
AWSEndpoint
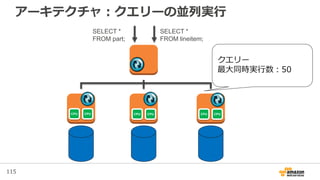
• 用途単位でStreamを作成、Streamは1つ以上のShardで構成される
• Shardは、データ入力側 1MB/sec, 1000 TPS、データ処理側 2 MB/sec, 5TPSのキャパシティを持つ
• 入力するデータをData Recordと呼び、入力されたData Recordは、24 時間かつ複数のAZに保管される
• Shardの増加減によってスケールの制御が可能
Stream](https://image.slidesharecdn.com/tokyowebminingawsbigdata-150801045611-lva1-app6891/85/AWS-71-320.jpg)














































































![[Sumo Logic x AWS 共催セミナー_20190829] Sumo Logic on AWS -AWS を活用したログ分析とセキュリティモニ...](https://cdn.slidesharecdn.com/ss_thumbnails/sumologiconaws-loganalysisandsecuritymonitoringusingaws-20190829-190829114856-thumbnail.jpg?width=640&height=640&fit=bounds)














![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)



















