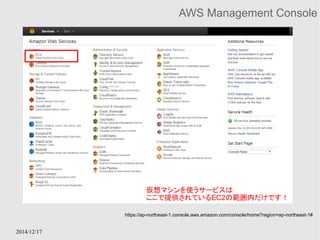
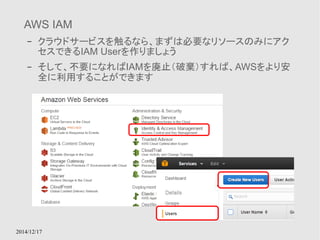
US Japan
USUser Japan User
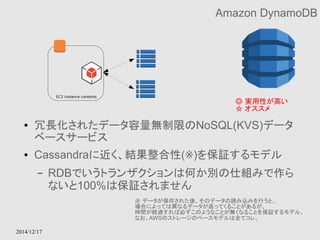
アメリカのユーザはUS内のサーバーから、
日本のユーザは日本内のサーバーからコンテンツを取得す
ることで、効率よくコンテンツを入手できる
2014/12/17
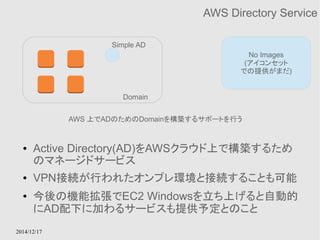
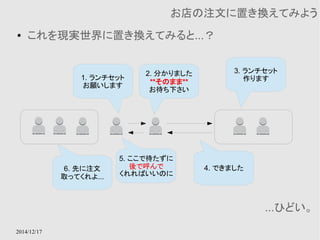
Amazon CloudFront
● 効率よく世界中にコンテンツ(画像、音声、映像ファイルな
ど)を配信するためのサービス
● 技術的に言い換えれば、世界中にAWSがキャッシュ
サーバーを立ててくれているので、そのサーバーを効率
よく利用させてもらうためのサービス
25.
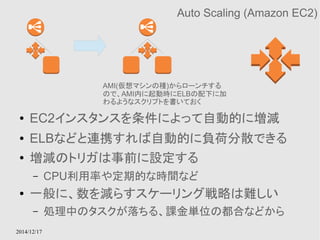
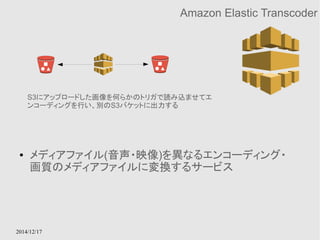
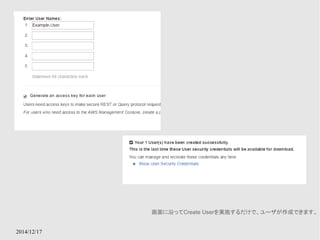
corporate data center
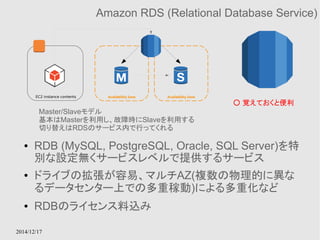
社内のデータをクラウド上に適切にバックアップする仕組みを提供する
GWインスタンスは社内にあっても良い
2014/12/17
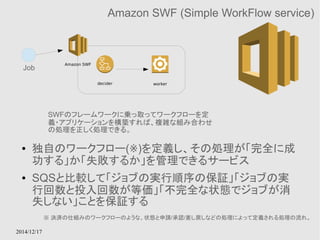
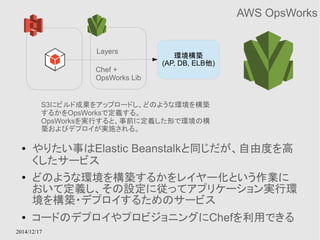
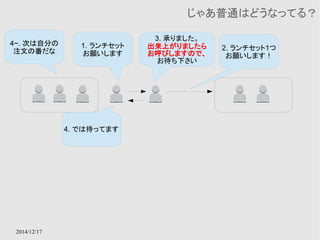
Amazon StorageGateway
● StorageGatewayとGWインスタンスを利用してオンプレ
のデータをクラウド上にも保存するためのサービス
● GW用インスタンスはデータの性質によって、Cache、S3
など適切なストレージにデータを保持する
● Hybrid Cloudの1形態をサポートするサービス
26.
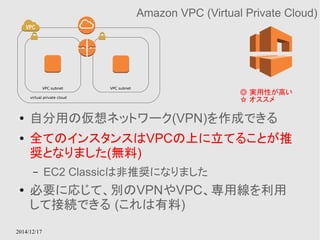
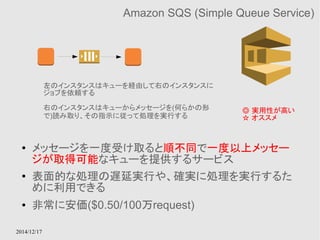
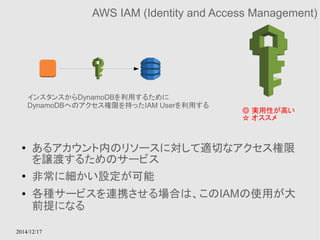
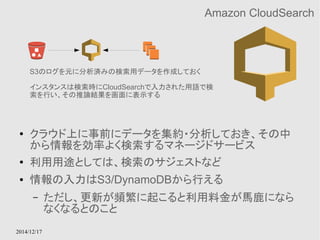
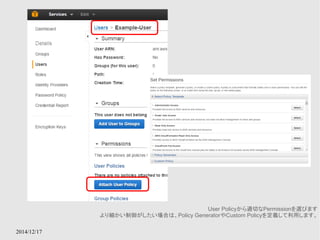
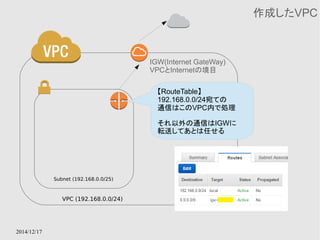
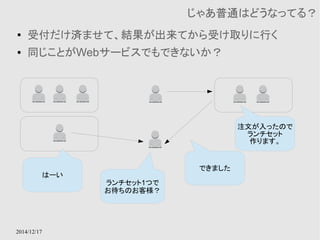
EC2 instance contentsAvailability Zone Availability Zone
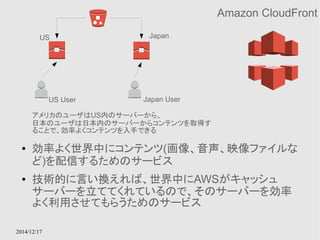
多重化されたキャッシュモデル
切り替えはElastiCacheのサービス内で行ってくれる
2014/12/17
Amazon ElastiCache
● RDSのキャッシュ版みたいなもの
● MemcachedとRedisがサポートされている
● Multi-AZによる多重化をサポートする






































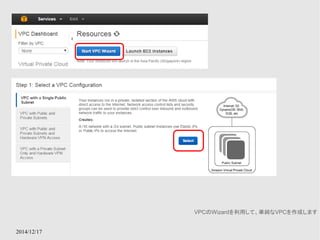


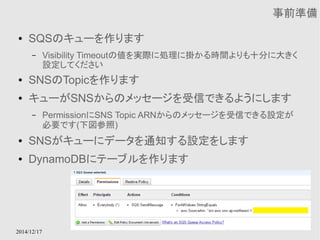
![設定 (“aws configure”を実行)
2014/12/17
ファイル保存のためにS3を利用する
$ aws configure
AWS Access Key ID : (IAMのAccess Key)
AWS Secret Access Key : (IAMのSecret Access Key)
Default region name : ap-northeast-1
Default output format [None]: (何も入力せずEnter)](https://image.slidesharecdn.com/aws-141217024533-conversion-gate01/85/AWS-71-320.jpg)


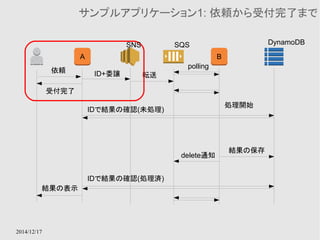
![2014/12/17
Fabric (番外)
● Python2.7で動作するDeployツールで、シェルの薄いラッ
パーとしても動作する
● コマンドの実行結果を文字列として取得できる
import json
import fabric.api
# コマンド 'aws ec2 describe-instances' を実行し
# 出力結果をresponse_jsonに格納する
response_json = fabric.api.local('aws ec2 describe-instances', capture=True)
# 文字列から dict (JavaでいうMap) に変換
response = json.loads(response_json)
# あとは普通のPythonでのプログラミングとして操作できる
# response['Reservations'][...]](https://image.slidesharecdn.com/aws-141217024533-conversion-gate01/85/AWS-74-320.jpg)



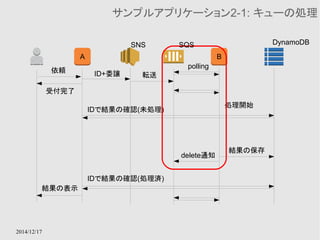
![def get_messages(else_value=None):
conn = boto.sqs.connect_to_region(REGION,
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
queue = conn.get_queue(QUEUE_NAME)
if FROM_RAW_MESSAGE:
from boto.sqs.message import RawMessage
queue.set_message_class(RawMessage)
msgs = queue.get_messages(num_messages=1)
if len(msgs) == 0:
return else_value
return msgs[0]
def main():
msg = get_messages()
if msg == None:
return
try:
body = json.loads(msg.get_body())
id = body['Subject']
put_with_longtime(id)
msg.delete()
except Exception as e:
logging.exception(e)
2014/12/17
QUEUE_NAMEは作成したキューの名前
AWS-CLIやSNSからデータを受け取る場
合はRawMessageを指定する必要がある
Pollingして、メッセージが取得できなければ一旦
終了してよい
(定期的にこのプログラムが実行されるため)
Subjectで渡したIDをキーにして、重いデータを
処理する
正常に処理が終了すれば、Queueにメッセージ
の消去命令を送る。
処理が失敗(例外で終了)した場合はdeleteメッ
セージが送られないので、VisibilityTimeout後に
メッセージが復活する](https://image.slidesharecdn.com/aws-141217024533-conversion-gate01/85/AWS-86-320.jpg)
![def heavy_procedure(id):
import uuid
ids = []
for i in xrange(0,5):
time.sleep(1)
ids.append(str(uuid.uuid4()))
return ':'.join(ids)
def put_with_longtime(id):
value = heavy_procedure(id)
import boto.dynamodb2
from boto.dynamodb2.table import Table
conn = boto.dynamodb2.connect_to_region(REGION,
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
table = Table(TABLE_NAME, connection=conn)
table.put_item(data={
'id': id,
'value': value
}, overwrite=True)
2014/12/17
重い処理を行うダミー関数
事前に作成したテーブル名
(Key: id, Value: value) の組でテーブルに上書き保存](https://image.slidesharecdn.com/aws-141217024533-conversion-gate01/85/AWS-88-320.jpg)




































![[Azure Deep Dive] クラウド デザイン パターン ~優れたシステム構築のためのガイダンス~](https://cdn.slidesharecdn.com/ss_thumbnails/200151004madcdp-151216090016-thumbnail.jpg?width=640&height=640&fit=bounds)























