模倣学習 Learning fromdemonstration
スキル:物事をうまくやるための知識
スキルライブラリ:スキルの集合
Demonstration は軌道だけではない(人間や操作対象物の動きを取ってスキ
ルモデルを作る・・・というのはひとつのやり方であって,それが本質ではない)
現状,Robot learning における複雑さ(次元の呪いなど)を解決する最も強力
な手段
Robot (learning) の研究者は常に「人はどうするか」を考えている
人間の知能にも模倣学習が大きな影響を与えている
ふたつの学習ステージ
ロボットが人から学習(転移)
自分でさらに学習
Yasuo Kuniyoshi and Masayuki Inaba and Hirochika Inoue: Learning by
Watching: Extracting Reusable Task Knowledge fromVisual Observation of
Human Performance, IEEE Transactions on Robotics and Automation, 1994.
Tetsunari Inamura and IwakiToshima and HiroakiTanie andYoshihiko
Nakamura: Embodied Symbol Emergence Based on Mimesis Theory,The
International Journal of Robotics Research, 2004.
Jakel, R. and Schmidt-Rohr, S.R. and Losch, M. and Dillmann, R.:
Representation and constrained planning of manipulation strategies in the
context of Programming by Demonstration, ICRA 2010.
Aude Billard and Daniel Grollman: Robot learning by demonstration,
Scholarpedia, Vol. 8, No. 12, 2013.
http://www.scholarpedia.org/article/Robot_learning_by_demonstration
14
AkihikoYamaguchi, Christopher G. Atkeson, andTsukasa Ogasawara:
Pouring Skills with Planning and Learning Modeled from Human
Demonstrations, International Journal of Humanoid Robotics,Vol.12,
No.3, July, 2015.
15.
強化学習
15
テキスト
Sutton, Barto ReinforcementLearning: An Introduction, The MIT Press, 1998.
https://webdocs.cs.ualberta.ca/~sutton/book/ebook/the-book.html
モデルベース
S.~Schaal and C.~Atkeson, ``Robot juggling: implementation of memory-based
learning,'' in the IEEE International Conference on Robotics and Automation
(ICRA'94), vol.~14, no.~1, 1994, pp. 57--71.
J.~Morimoto, G.~Zeglin, and C.~Atkeson, ``Minimax differential dynamic
programming: Application to a biped walking robot,'' in the IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS'03), vol.~2, 2003, pp. 1927--
1932.
モデルフリー
J.~Kober and J.~Peters, ``Policy search for motor primitives in robotics,'' Machine
Learning, vol.~84, no. 1-2, pp. 171--203, 2011.
E.~Theodorou, J.~Buchli, and S.~Schaal, ``Reinforcement learning of motor skills in
high dimensions: A path integral approach,'' in the IEEE International Conference on
Robotics and Automation (ICRA'10), may 2010, pp. 2397--2403.
D.~Ernst, P.~Geurts, and L.~Wehenkel, ``Tree-based batch mode reinforcement
learning,'' Journal of Machine Learning Research, vol.~6, pp. 503--556, 2005.
P.~Kormushev, S.~Calinon, and D.~G. Caldwell, ``Robot motor skill coordination
with EM-based reinforcement learning,'' in the IEEE/RSJ International Conference on
Intelligent Robots and Systems (IROS'10), 2010, pp. 3232--3237.
A.~Yamaguchi, J.~Takamatsu, and T.~Ogasawara, ``DCOB: Action space for
reinforcement learning of high dof robots,'' Autonomous Robots, vol.~34, no.~4, pp.
327--346, 2013.
J.~Kober, A.~Wilhelm, E.~Oztop, and J.~Peters, ``Reinforcement learning to adjust
parametrized motor primitives to new situations,'' Autonomous Robots, vol.~33, pp.
361--379, 2012.
S.~Levine, N.~Wagener, and P.~Abbeel, ``Learning contact-rich manipulation skills
with guided policy search,'' in the IEEE International Conference on Robotics and
Automation (ICRA'15), 2015.
組み合わせ
R.~S. Sutton, ``Integrated architectures for learning, planning, and reacting based on
approximating dynamic programming,'' in the Seventh International Conference on
Machine Learning. Morgan Kaufmann, 1990, pp. 216--224.
R.~S. Sutton, C.~Szepesv¥'{a}ri, A.~Geramifard, and M.~Bowling, ``Dyna-style
planning with linear function approximation and prioritized sweeping,'' in
Proceedings of the 24th Conference on Uncertainty in Artificial Intelligence, 2008, pp.
528--536.
Yamaguchi et al. "DCOB: Action space for reinforcement learning of high
DoF robots", Autonomous Robots, 2013
YouTube:RL_MotionLearning (by myself)
https://www.youtube.com/playlist?list=PL41
MvLpqzOg8FF0xekWT9NXCdjzN_8PUS
16.
強化学習
16
By J. Koberand J. Peters
Learning Motor Primitives for Robotics (Ball-in-cup)
http://www.ausy.tu-
darmstadt.de/Research/LearningMotorPrimitives
https://www.youtube.com/watch?v=cNyoMVZQdYM
By P. Kormushev et al.
Video: Robot Arm Wants Nothing MoreThanTo MasterThe Art OfThe
Flapjack-Flip
http://www.popsci.com/technology/article/2010-07/after-50-attempts-
hard-working-flapjack-bot-learns-flip-pancakes-video
http://programming-by-demonstration.org/showPubli.php?publi=3018
https://vimeo.com/13387420#at=NaN
17.
その他のロボット学習
E.~Magtanong, A.~Yamaguchi, K.~Takemura,J.~Takamatsu, andT.~Ogasawara,
``Inverse kinematics solver for android faces with elastic skin,'' in Latest
Advances in Robot Kinematics, Innsbruck, Austria, 2012, pp. 181--188.
17
使われた技術の例(WPI-CMU)
23
・ Did well(14/16 points over 2 days, drill)
・ Did not fall
・ Did not require physical human intervention
歩行制御
・不整地はLRFで検出
・複数レベル(階層型)の最適化
・フットステップの最適化
・軌道の最適化
・最適化ベースの逆動力学(QPを全身に対して)
LIPMTrajectory Optimization
Team WPI-CMU: Darpa Robotics Challenge
http://www.cs.cmu.edu/~cga/drc/
(cmu-drc-final-public.zip, dw1.pptx)
24.
使われた技術の例(AIST-NEDO)
24
Shin’ichiro Nakaoka, MitsuharuMorisawa, Kenji Kaneko, Shuuji Kajita and Fumio Kanehiro,
"Development of an Indirect-typeTeleoperation Interface for Biped Humanoid Robots“, 2014
http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7028105
25.
A Compilation ofRobots Falling Down at the DARPA Robotics Challenge
https://www.youtube.com/watch?v=g0TaYhjpOfo
DRC と AI
どのくらい自律性があったか
少なくともオペレータルームとの通信遅延・帯域制限を補えるくらいには
モーションプラニングは多くのチームが使っていた
しかしオペレータの指示は重要だった(どこに行くか,何をするかe.g. バルブをつかむ,操作対
象の大まかな位置 e.g. バルブの位置)
どのくらい学習技術が使われたか
ロボット学習のスペシャリストも参加していた(e.g.Christopher Atkeson, RussTedrake)
C. G. Atkeson et al.: “NO FALLS, NO RESETS: Reliable Humanoid Behavior in the DARPA
Robotics Challenge” http://www.cs.cmu.edu/~cga/drc/paper14.pdf
"The absence of horizontal force and yaw torque sensing in the Atlas feet limited our ability to
avoid foot slip, reduce the risk of falling, and optimize gait using learning.“
"Learning to plan better is hard.To be computationally feasible for real-time control, a
cascade of smaller optimizations is usually favored, which for us and many others eventually
boiled down to reasoning about long term goals using a simplified model and a one-step
constrained convex optimization that uses the full kinematics and dynamics"
どのくらい汎用性が高いAI技術が使われたか
モーションプラニング
最適化アルゴリズム
28
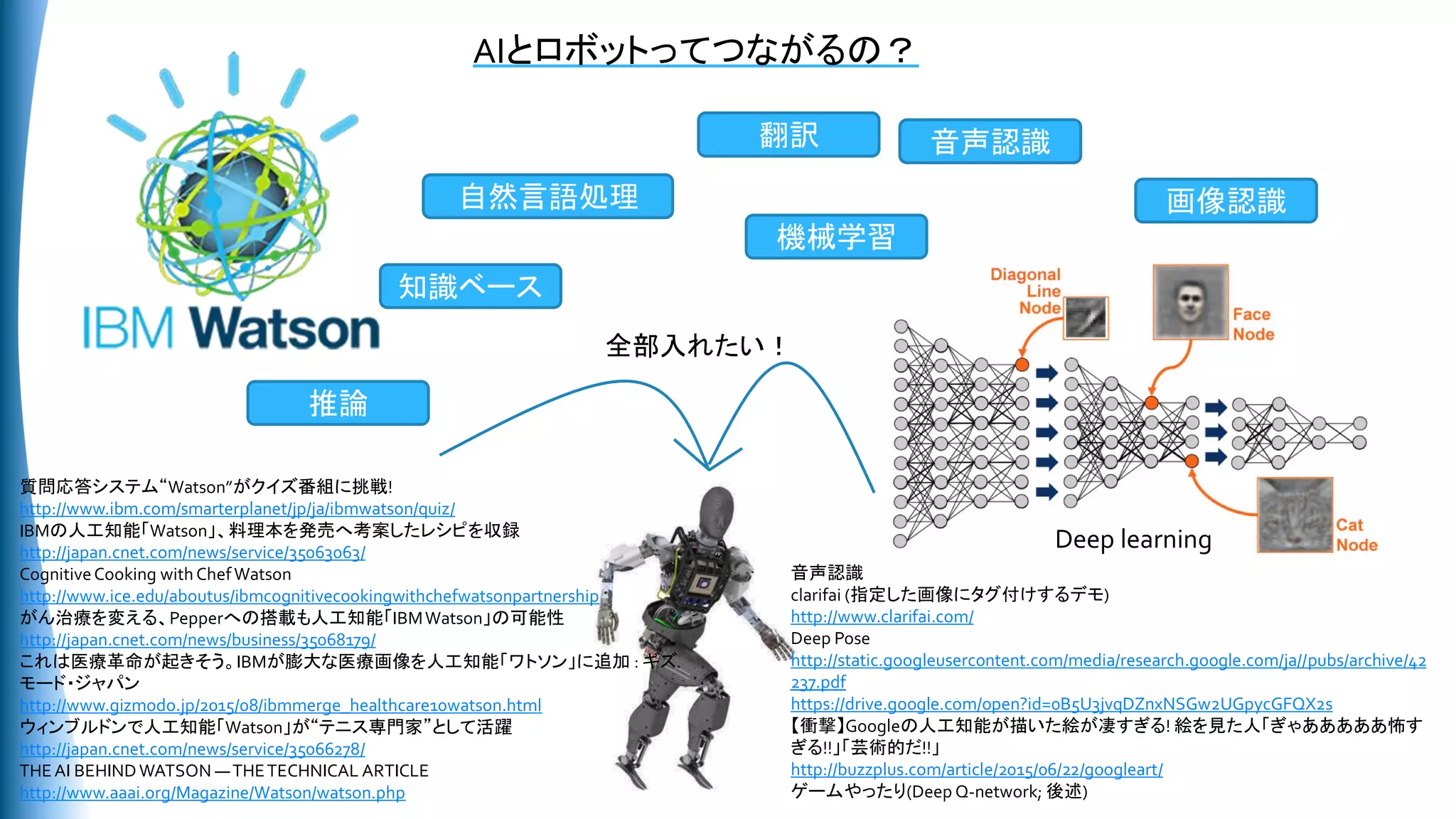
で,ディープラーニングって何?
(層が深い?)ニューラルネット
多くの機械学習の大会を制覇.応用:画像認識,音声認識,翻訳,・・・
なぜ(層が深いと)うまくいくかよくわかってないらしい
Cf. Deep v.s.shallow:
Lei Jimmy Ba, Rich Caruana: Do Deep Nets Really Need to be Deep?, NIPS 2014.
何が成功の秘訣?
Convolution (畳み込み)
Dropout (確率的に隠れ層の出力を無視) → 過学習を防止
ReLU (Linear Rectified Unit; max(x,0)) が良かった? 非線形のアクティベーション関数
LSTM (RNN)
(Pre-training (隠れ層の事前学習)・Auto Encorder → 層が深い場合の学習テクニック)
ビッグデータ e.g. ImageNet
何がすごいの?
これまで: 画像 → 特徴量抽出 → ニューラルネット
DNN (Deep Neural Network):画像 → ニューラルネット
特徴量抽出のデザインが不要になった(ただし Convolution などの細工は必要?)
Jurgen Schmidhuber: Deep Learning in Neural Networks: An Overview, Technical Report IDSIA-03-14 / arXiv:1404.7828 v2
[cs.NE], 2014. http://arxiv.org/abs/1404.7828
深層学習基本語彙( 40 分で!図付き!) by NAIST http://www.phontron.com/slides/neubig14deeplunch11-ja.pdf
Large Scale Deep Learning by Jeff Dean (Google)
http://static.googleusercontent.com/media/research.google.com/ja//people/jeff/CIKM-keynote-Nov2014.pdf
Hinton (talk): Brains, Sex, and Machine Learning https://youtu.be/DleXA5ADG78
岡谷 貴之 (PFN), ディープラーニングと画像認識 --基礎と最近の動向-- http://www.orsj.or.jp/archive2/or60-
4/or60_4_198.pdf32
33.
Deep Q network– DNN X 強化学習
V. Mnih, et al.: PlayingAtari with Deep Reinforcement Learning, NIPS Deep LearningWorkshop, 2013.
Fitted Q iteration: 安定な行動価値関数(Q(x,a))の学習手法;任意の回帰手法を行動価値関数の近似器
としてそのまま使える
Damien Ernst, Pierre Geurts, and LouisWehenkel:Tree-Based Batch Mode Reinforcement Learning, Journal of
Machine Learning Research,Vol.6, pp.503-556, 2005.
Neural Fitted QI: Fitted QIのニューラルネットを使った派生版
Martin Riedmiller: Neural fitted Q iteration -- first experiences with a data efficient neural reinforcement
learning method, In 16th EuropeanConference on Machine Learning, pp.317-328 2005.
DQN: Fitted Q iteration の関数近似器にDNNを使った(だけ)
DNNのおかげで,入力の状態を画像のように高次元にしても学習できた(DNNの性質をうまく利用)
逆に,行動空間の複雑性はそれほどないことに注意(ロボットの難しいタスクでそのまま使えるかはかなり疑問)
33
入力:
84 x 84の画像を
x 4フレーム分
出力:
コマンド(行動)ごとの価値
Q(x,a) = Q(画像列,コマンド)
を学習(i.e. 価値関数ベースの強化学習)
Beetzらの研究
Lars Kunze, MichaelBeetz:
Envisioning the qualitative effects
of robot manipulation actions
using simulation-based projections,
Artificial Intelligence, 2014.
Karinne Ramirez-Amaro and
Michael Beetz and Gordon Cheng:
Transferring skills to humanoid
robots by extracting semantic
representations from observations
of human activities, Artificial
Intelligence, 2015.
The RoboHow project
https://robohow.eu/videos
36 The RoboHow project https://youtu.be/0eIryyzlRwA
Robot pouring
AkihikoYamaguchi, ChristopherG. Atkeson, andTsukasa
Ogasawara: Pouring Skills with Planning and Learning Modeled
from Human Demonstrations, International Journal of
Humanoid Robotics,Vol.12, No.3, pp.1550030, July, 2015.
http://akihikoy.net/info/wdocs/Yamaguchi,Atkeson,2015-
Pouring%20Skills%20with%20Planning%20and%20Learning..-
IJHR.pdf
video: https://www.youtube.com/watch?v=GjwfbOur3CQ
AkihikoYamaguchi, Christopher G. Atkeson: Differential
Dynamic Programming withTemporally Decomposed Dynamics,
in Proceedings of the 15th IEEE-RAS International Conference
on Humanoid Robots (Humanoids2015), Seoul, 2015.
https://www.researchgate.net/publication/282157952_Differenti
al_Dynamic_Programming_with_Temporally_Decomposed_Dy
namics
video: https://youtu.be/OrjTHw0CHew
39
http://reflectionsintheword.files.wordpress.com/
2012/08/pouring-water-into-glass.jpg
http://schools.graniteschools.org/
edtech-canderson/files/2013/01/
heinz-ketchup-old-bottle.jpg
http://old.post-gazette.com/images2/
20021213hosqueeze_230.jpg http://img.diytrade.com/cdimg/1352823/17809917/
0/1292834033/shampoo_bottle_bodywash_bottle.jpg
http://www.nescafe.com/
upload/golden_roast_f_711.png
40.
Guputaらの研究
Lerrel Pinto, AbhinavGupta: Supersizing
Self-supervision: Learning to Grasp from
50KTries and 700 Robot Hours,
arXiv:1509.06825 [cs.LG].
http://arxiv.org/abs/1509.06825
Supersizing Self-supervision: Learning to
grasp from 50KTries and 700 Robot Hours
https://www.youtube.com/watch?v=oSqHc
0nLkm8
40
41.
Abbeel らの研究
{Levine}, S.and {Finn}, C. and {Darrell},T. and {Abbeel}, P.: End-to-EndTraining of DeepVisuomotor
Policies, arXiv:1504.00702, 2015.
Sergey Levine and NolanWagener and Pieter Abbeel: Learning Contact-Rich Manipulation Skills with
Guided Policy Search, ICRA 2015.
Jeremy Maitin-Shepard and Marco Cusumano-Towner and Jinna Lei and Pieter Abbeel: Cloth Grasp Point
Detection based on Multiple-View Geometric Cues with Application to RoboticTowel Folding, ICRA 2010.
41
Test on a pile of 5 randomly-
dropped towels (50X)
https://www.youtube.com/wat
ch?v=gy5g33S0Gzo
ロボットは嘘をつくか?
殺人ロボットを禁止するべきか?
反対サイドの意見 - “No,we should not ban autonomous weapons”
http://spectrum.ieee.org/automaton/robotics/artificial-
intelligence/we-should-not-ban-killer-robots
賛成サイドの意見 - “Yes, we should ban autonomous weapons”
http://spectrum.ieee.org/automaton/robotics/artificial-
intelligence/why-we-really-should-ban-autonomous-weapons
ロボットは人の仕事を奪うか?
YESだとして,それはネガティブなこと?
(不幸を回避するにはどうすればいい?)
44



![バズワード
人工知能
ディープラーニング
ビッグデータ
「政治用語」だと考えています --- 使い過ぎるとはずかしい
企業が食いついてくれる
論文が目を引きやすくなる
グラントが取りやすい・・・?
「バズワード」を使うことが悪いとは思わない
お金が循環しているし我々研究者にも
今学習している人: 惑わされないように注意してください
4
[wiki/バズワード]
バズワード(英: buzzword)とは、一見、説得力があるように見えるが、具体性がなく明確な合意や定義
のないキーワードのことである。ただし、「バズワード」という用語自体の定義が曖昧なので、「バズワード
自体がバズワードである」とする説もある。
そろそろ「ディープラーニングは
(強い)AIじゃねーよ」みたいな批
判が出かけてますが,そんなん
当たり前です.くれぐれも批判
的な意見に萎縮しないように.](https://image.slidesharecdn.com/naistlecture20151106-151107071645-lva1-app6891/75/slide-4-2048.jpg)





![11
人間はどうしてる?
→スキルの模倣学習
ダイナミクスが未知
→強化学習
ほかのロボット学習
部分的に機械学習を使ったり
汎用性・汎化性
汎用性・汎化性が高いものほどAIっぽい
“汎用性のコスト”
歩行もある意味AI ← 弱いAI
(歩行研究者はそう言わない
→ ほかのタスクにそのまま使えないから
i.e. 汎用性が低い)
ロボットのAIについて,
AIかそうでないかの議論はあまり意味がない
(見方によって異なる)
→ それでみんなAIと呼ぶのでしょう...
ロボットのAI - Robot learning
自律性
(人間が制御しなくていい)
(人間がプログラムしなくていい)
AIっぽい!
学習能力
(ロボットが勝手に覚える)
AIっぽい!
モーションプラニング(推論)
・RRT
・動的計画法
・最適化
[AIの評価尺度]
ロボットが「できる」とロボットで「やってみた」
の違いは大きい → 研究者に惑わされるな!](https://image.slidesharecdn.com/naistlecture20151106-151107071645-lva1-app6891/75/slide-11-2048.jpg)




















![で,ディープラーニングって何?
(層が深い?)ニューラルネット
多くの機械学習の大会を制覇.応用:画像認識,音声認識,翻訳,・・・
なぜ(層が深いと)うまくいくかよくわかってないらしい
Cf. Deep v.s. shallow:
Lei Jimmy Ba, Rich Caruana: Do Deep Nets Really Need to be Deep?, NIPS 2014.
何が成功の秘訣?
Convolution (畳み込み)
Dropout (確率的に隠れ層の出力を無視) → 過学習を防止
ReLU (Linear Rectified Unit; max(x,0)) が良かった? 非線形のアクティベーション関数
LSTM (RNN)
(Pre-training (隠れ層の事前学習)・Auto Encorder → 層が深い場合の学習テクニック)
ビッグデータ e.g. ImageNet
何がすごいの?
これまで: 画像 → 特徴量抽出 → ニューラルネット
DNN (Deep Neural Network):画像 → ニューラルネット
特徴量抽出のデザインが不要になった(ただし Convolution などの細工は必要?)
Jurgen Schmidhuber: Deep Learning in Neural Networks: An Overview, Technical Report IDSIA-03-14 / arXiv:1404.7828 v2
[cs.NE], 2014. http://arxiv.org/abs/1404.7828
深層学習基本語彙( 40 分で!図付き!) by NAIST http://www.phontron.com/slides/neubig14deeplunch11-ja.pdf
Large Scale Deep Learning by Jeff Dean (Google)
http://static.googleusercontent.com/media/research.google.com/ja//people/jeff/CIKM-keynote-Nov2014.pdf
Hinton (talk): Brains, Sex, and Machine Learning https://youtu.be/DleXA5ADG78
岡谷 貴之 (PFN), ディープラーニングと画像認識 --基礎と最近の動向-- http://www.orsj.or.jp/archive2/or60-
4/or60_4_198.pdf32](https://image.slidesharecdn.com/naistlecture20151106-151107071645-lva1-app6891/75/slide-32-2048.jpg)







![Guputaらの研究
Lerrel Pinto, Abhinav Gupta: Supersizing
Self-supervision: Learning to Grasp from
50KTries and 700 Robot Hours,
arXiv:1509.06825 [cs.LG].
http://arxiv.org/abs/1509.06825
Supersizing Self-supervision: Learning to
grasp from 50KTries and 700 Robot Hours
https://www.youtube.com/watch?v=oSqHc
0nLkm8
40](https://image.slidesharecdn.com/naistlecture20151106-151107071645-lva1-app6891/75/slide-40-2048.jpg)















![[ICML2019読み会in京都] Agnostic Federated Learning](https://cdn.slidesharecdn.com/ss_thumbnails/roadrolleragnosticfederatedlearning-190804065508-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]最新の深層強化学習](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackdeepreinforce-1-170217050318-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]Learning agile and dynamic motor skills for legged robots](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar0125nishimura-190125001509-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning quadrupedal locomotion over challenging terrain](https://cdn.slidesharecdn.com/ss_thumbnails/dl20201029koheinishimura-201113025552-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)









