Downloaded 136 times
![HDFS-HC: A Data Placement Module for Heterogeneous Hadoop Clusters 02/28/11 Xiao Qin Department of Computer Science and Software Engineering Auburn University http://www.eng.auburn.edu/~xqin [email_address] Slides 2-20 are adapted from notes by Subbarao Kambhampati (ASU), Dan Weld (U. Washington), Jeff Dean, Sanjay Ghemawat, (Google, Inc.)](https://image.slidesharecdn.com/mapreduce-hdfs-hc-110228142255-phpapp01/75/HDFS-HC-A-Data-Placement-Module-for-Heterogeneous-Hadoop-Clusters-1-2048.jpg)



![Map in Lisp (Scheme) (map f list [list 2 list 3 … ] ) (map square ‘ (1 2 3 4)) (1 4 9 16) (reduce + ‘ (1 4 9 16)) (+ 16 (+ 9 (+ 4 1) ) ) 30 (reduce + (map square (map – l 1 l 2 )))) Unary operator Binary operator](https://image.slidesharecdn.com/mapreduce-hdfs-hc-110228142255-phpapp01/75/HDFS-HC-A-Data-Placement-Module-for-Heterogeneous-Hadoop-Clusters-7-2048.jpg)





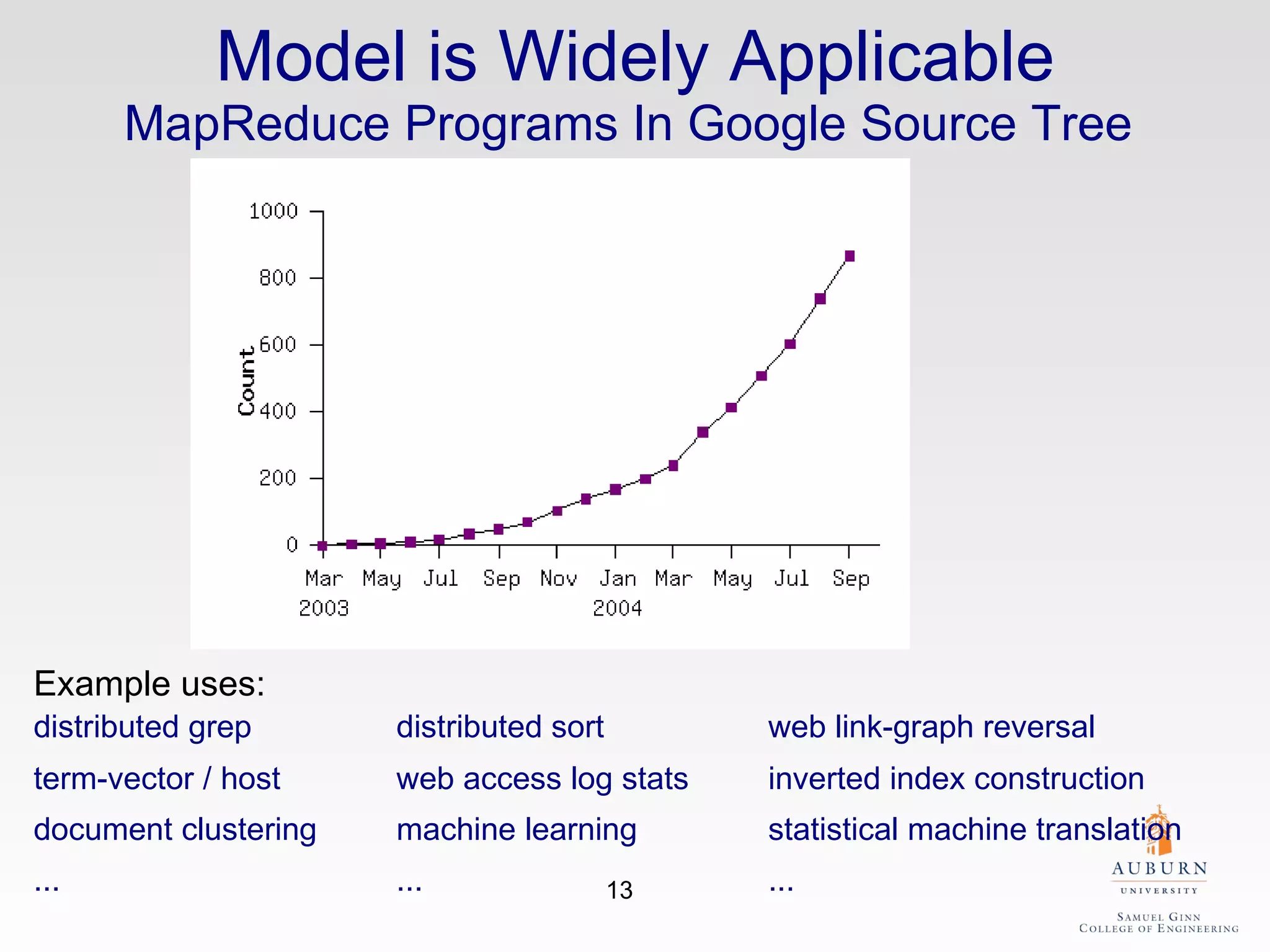


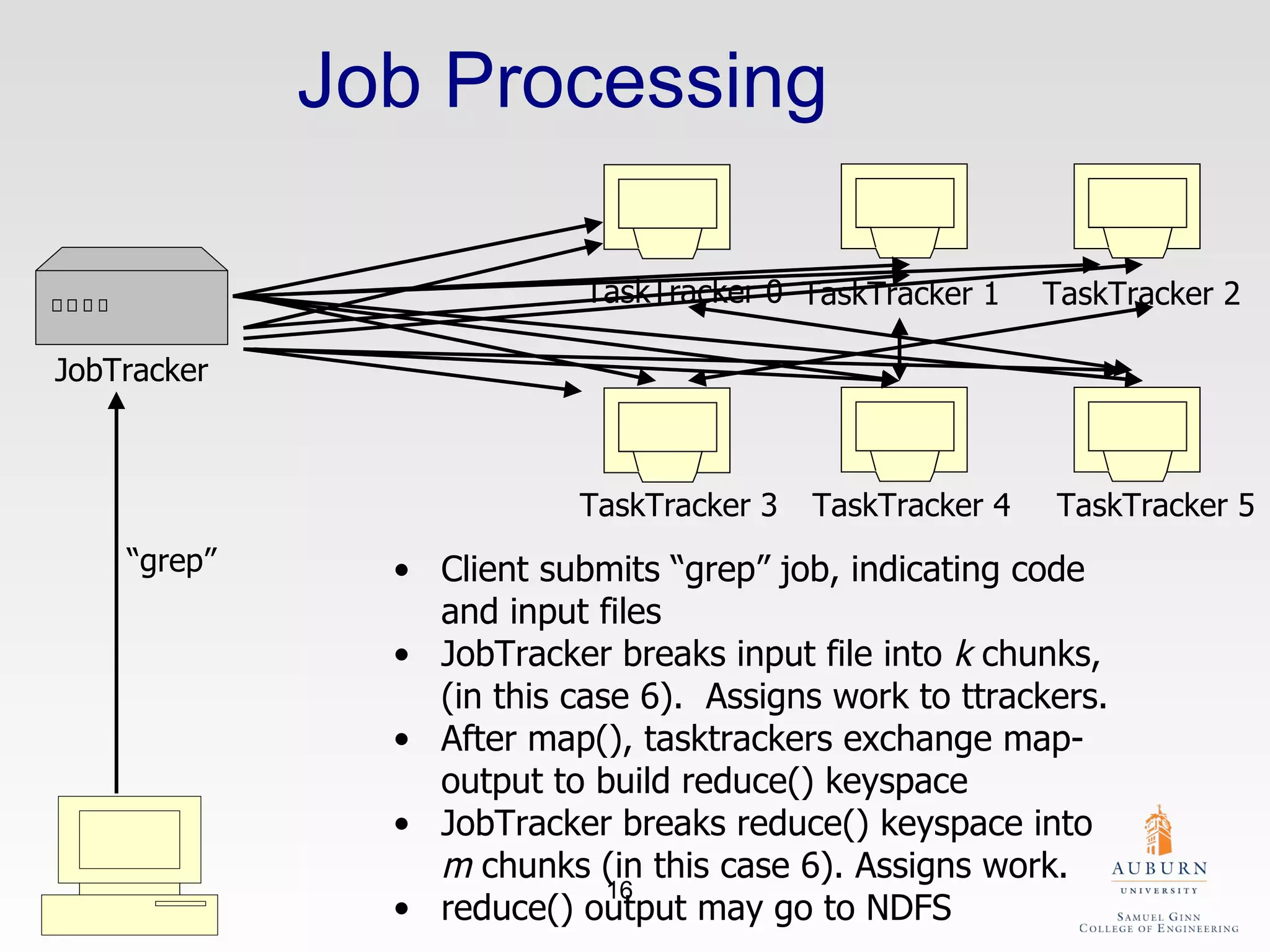
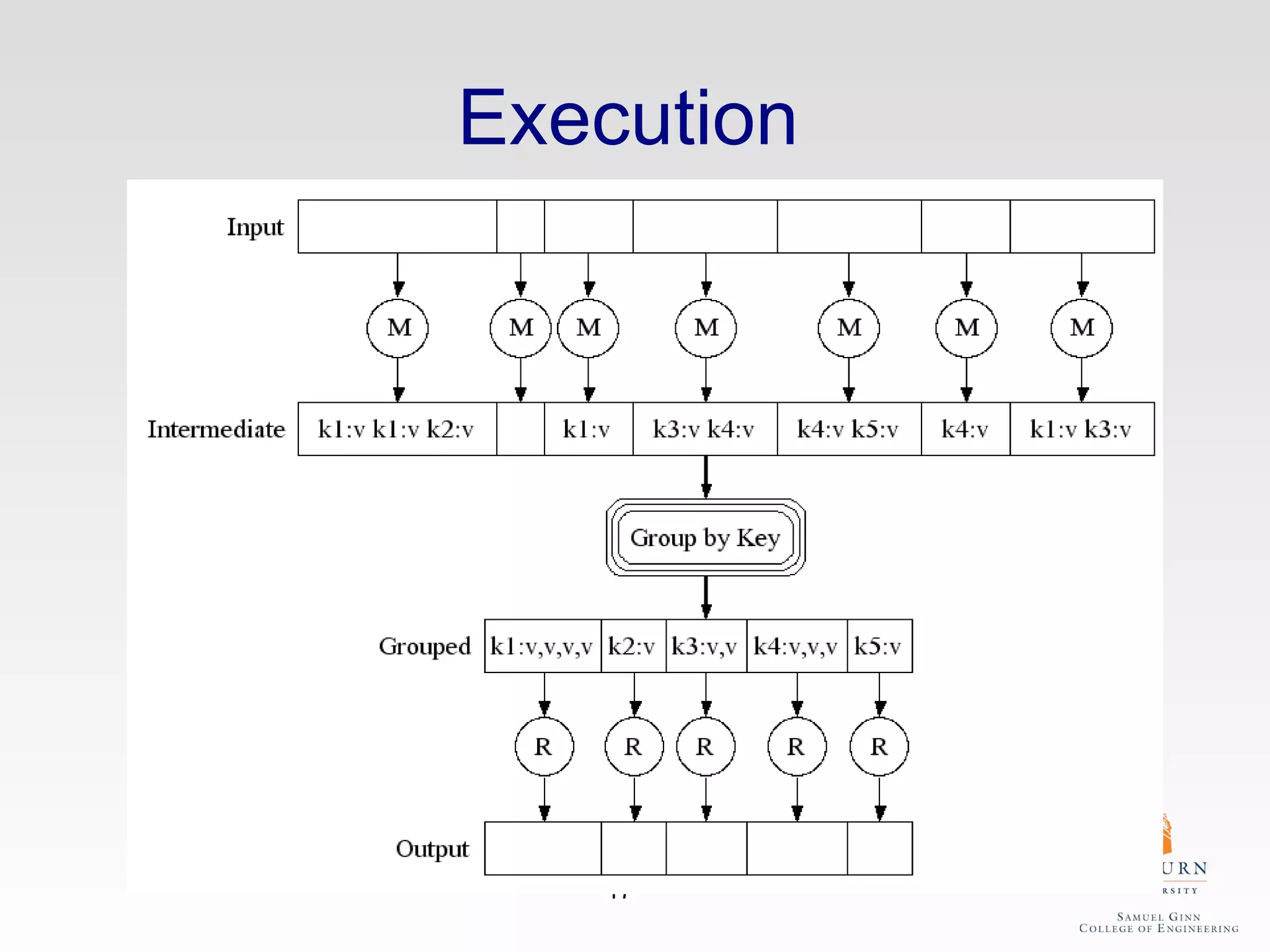
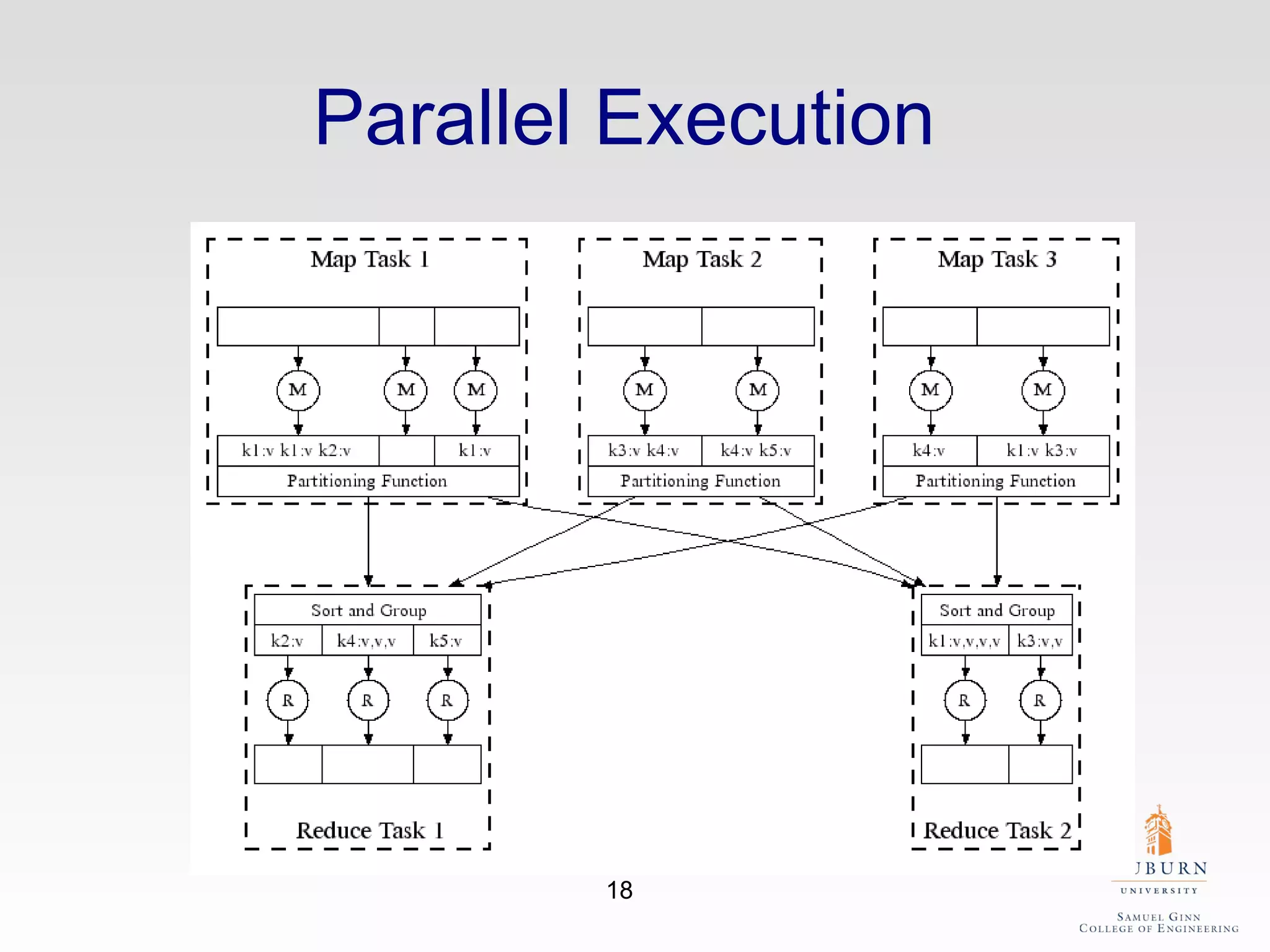



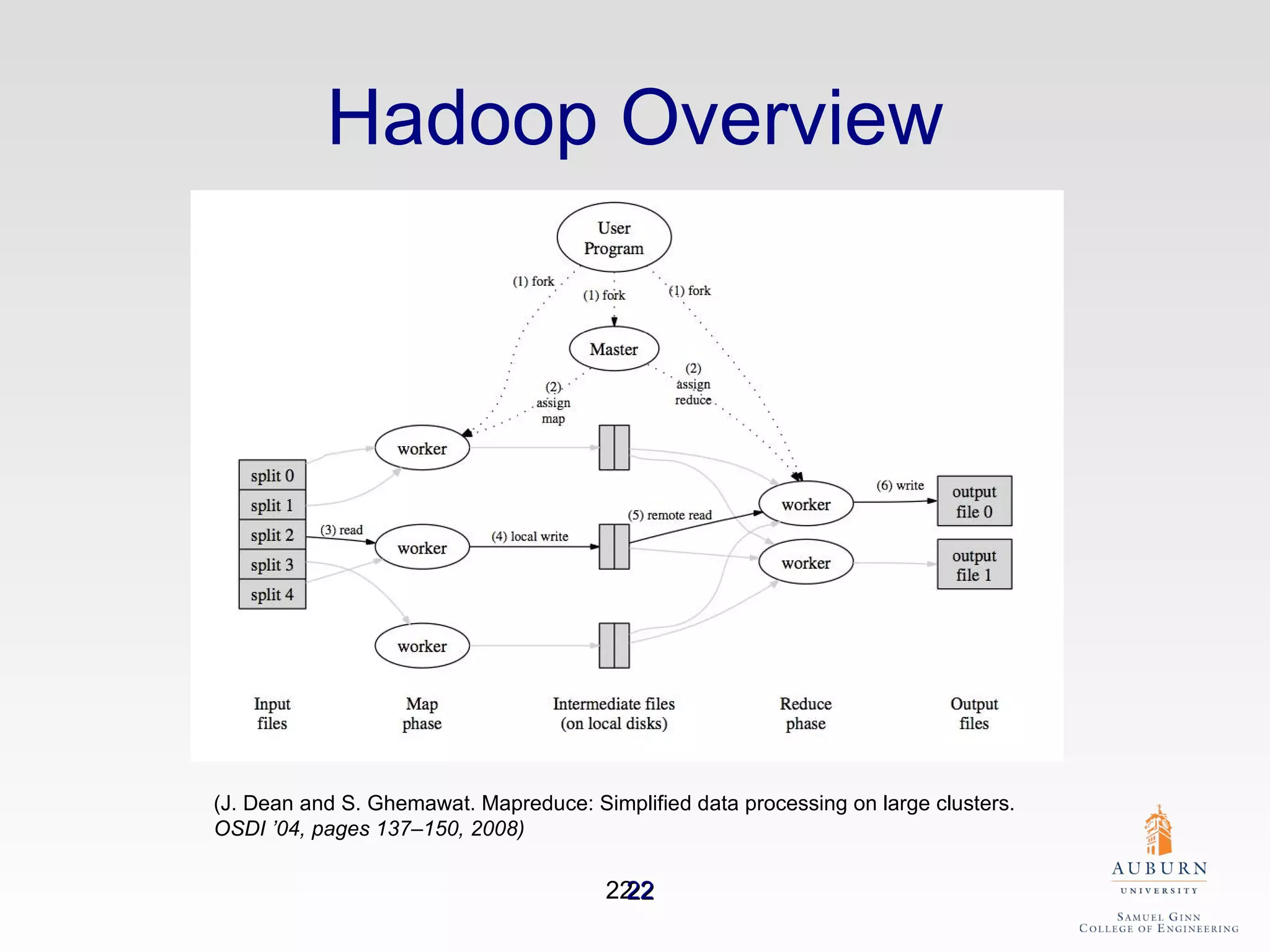

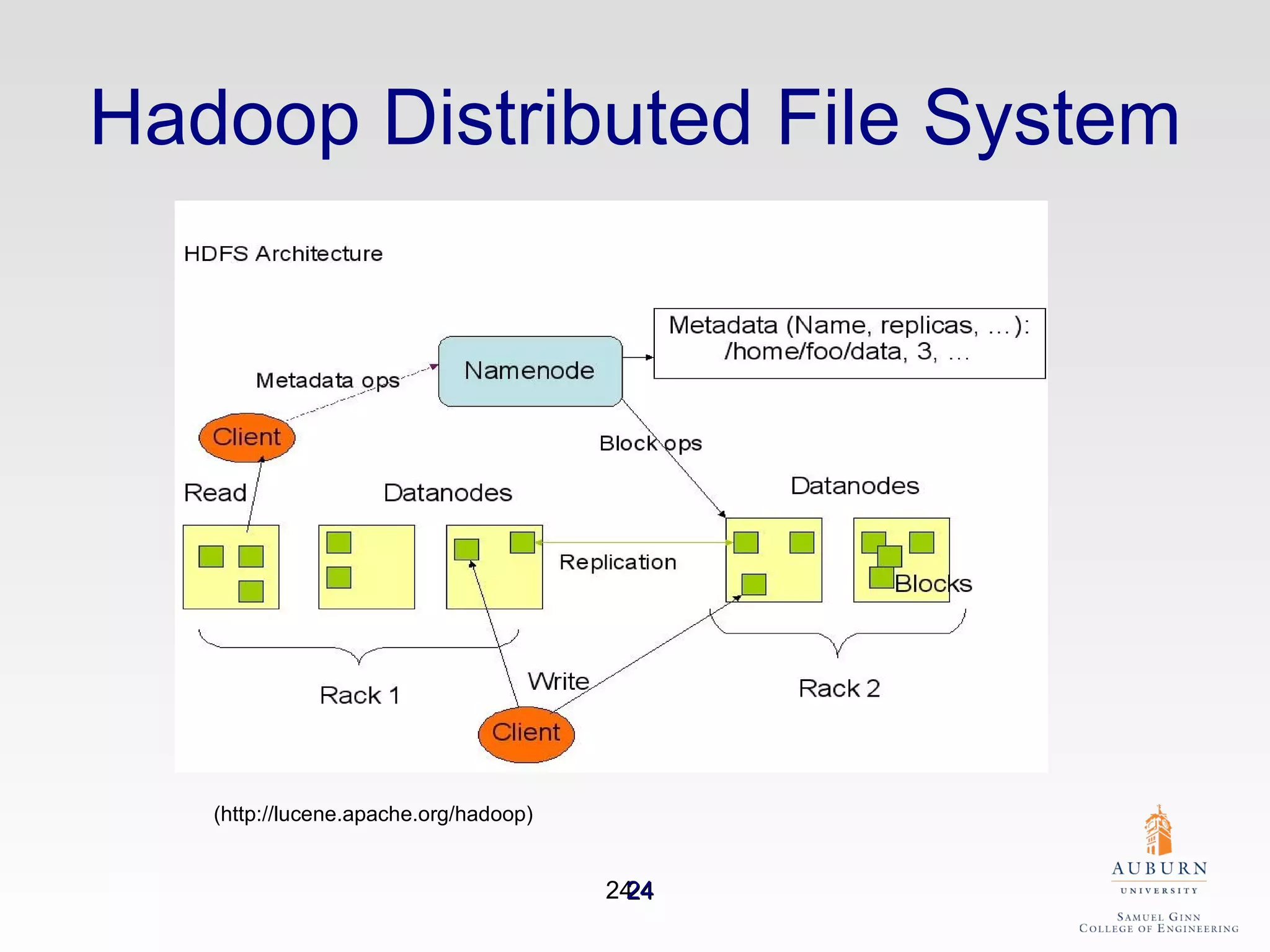
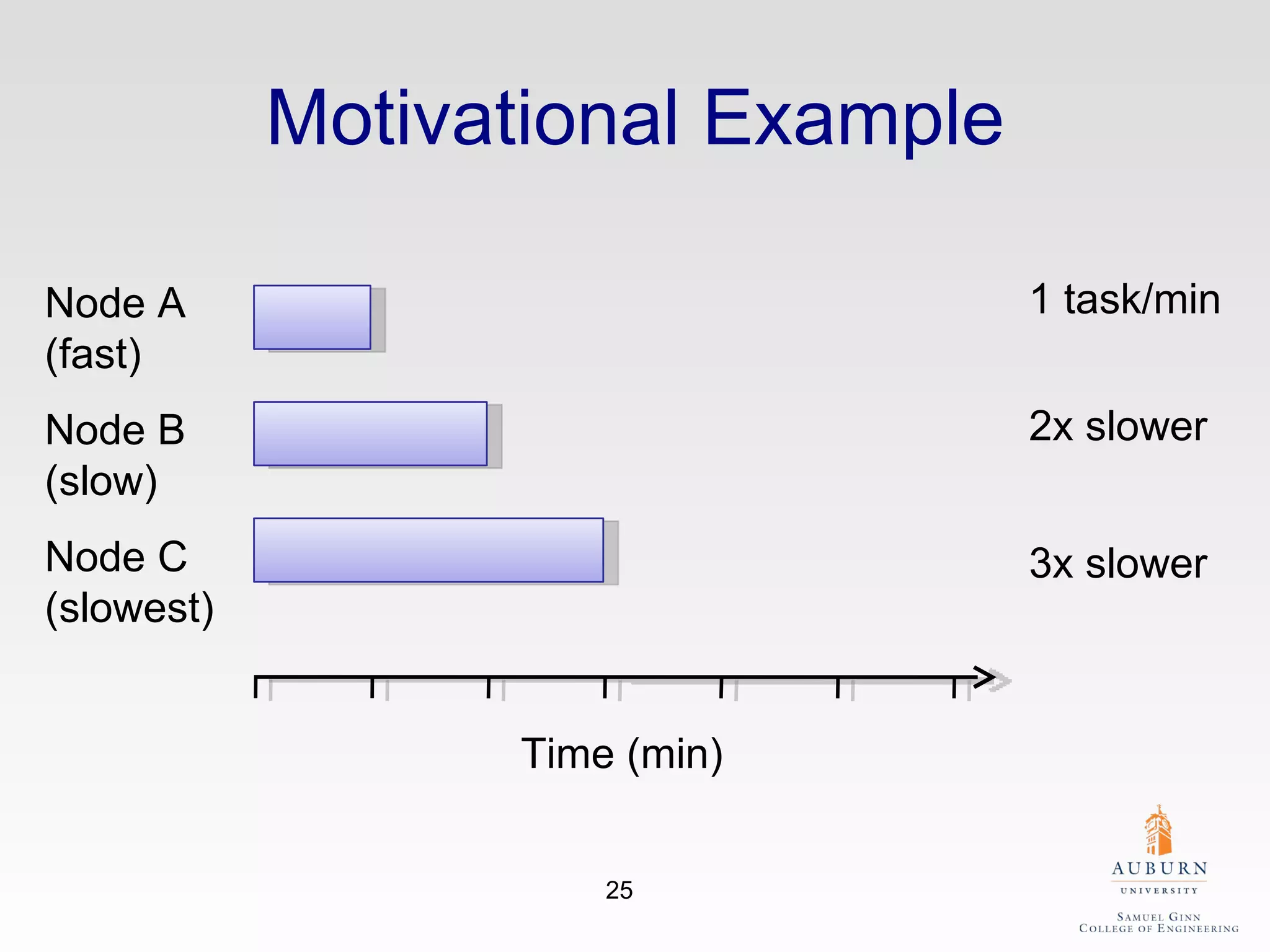

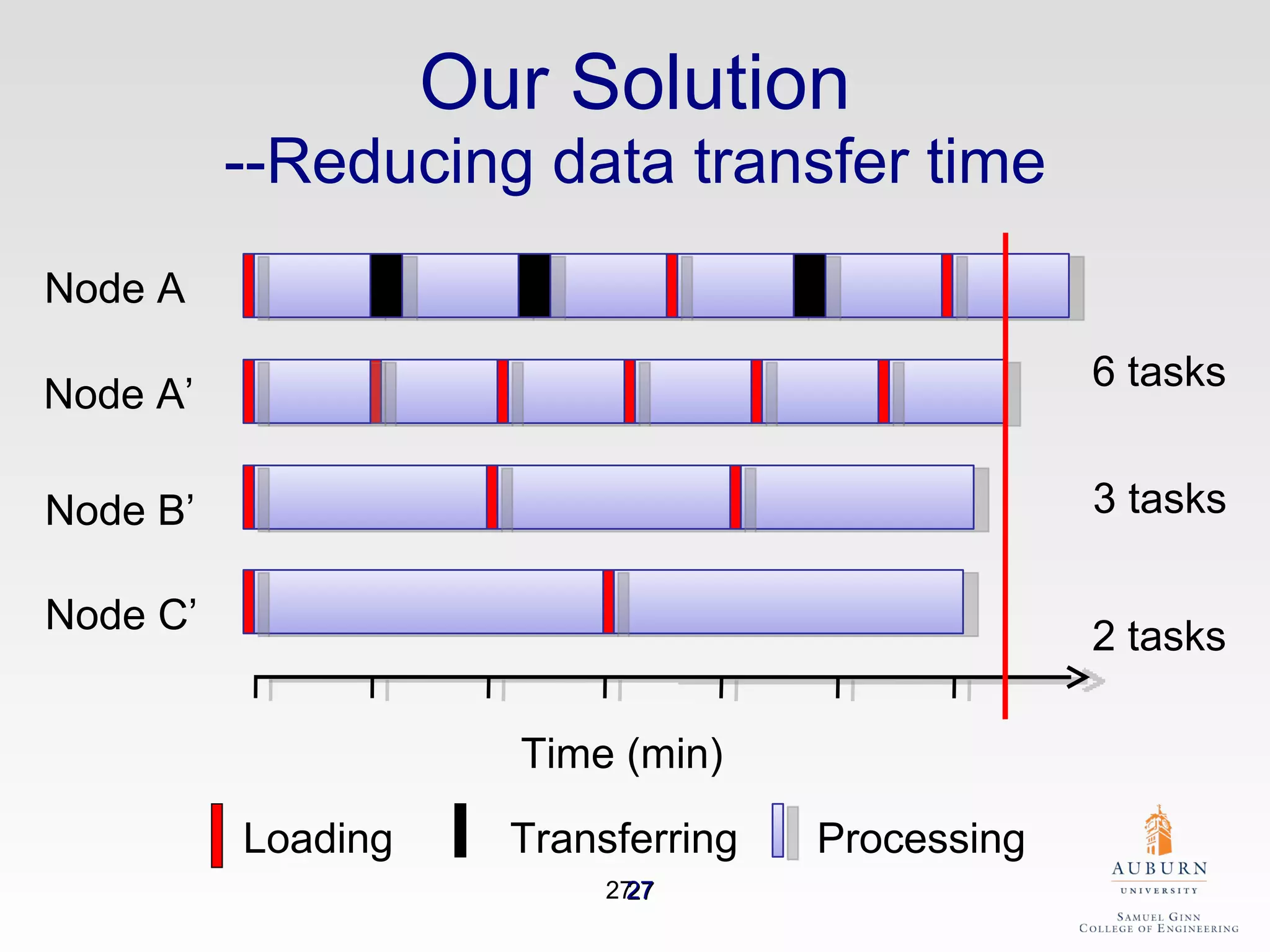
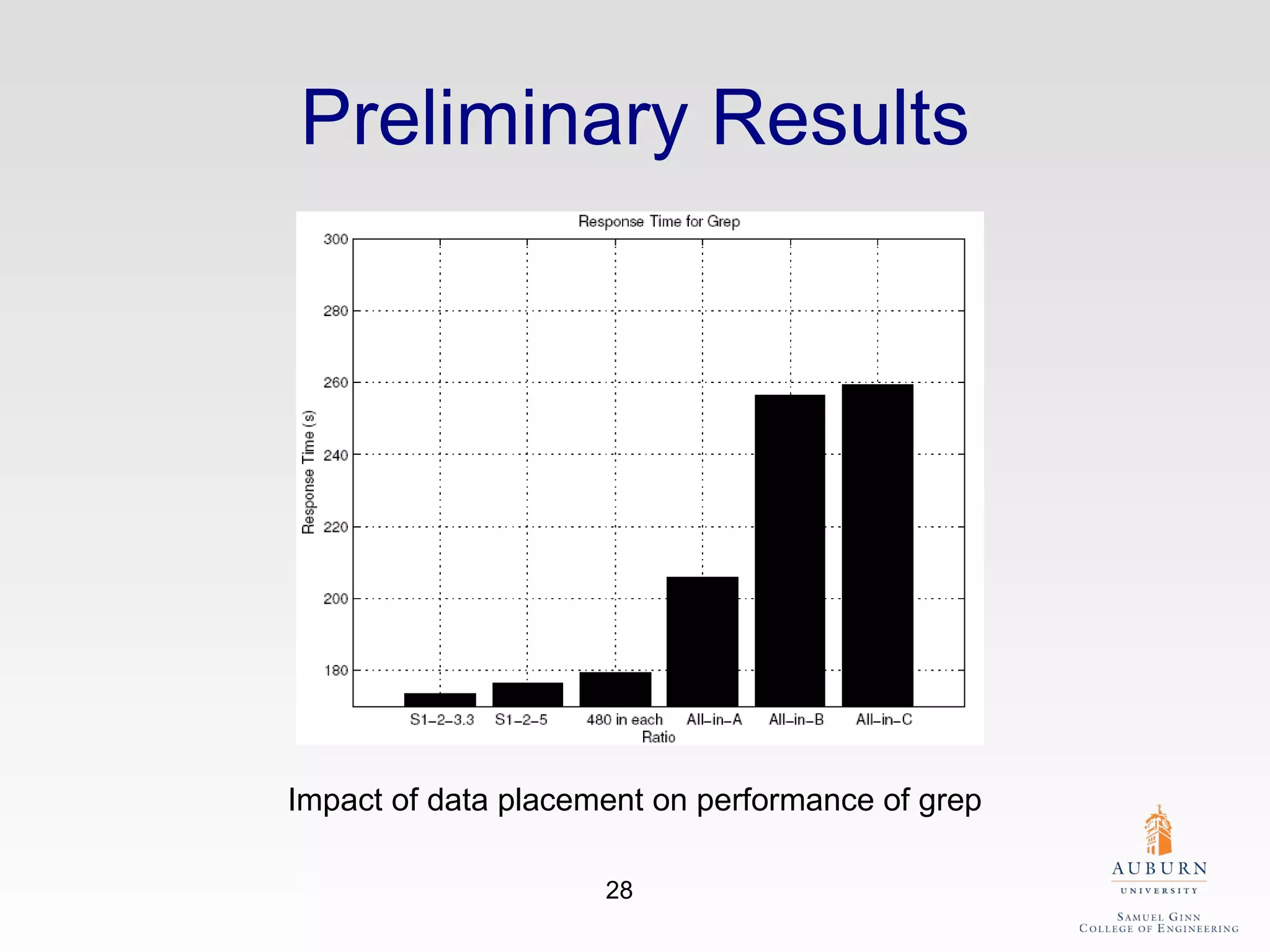



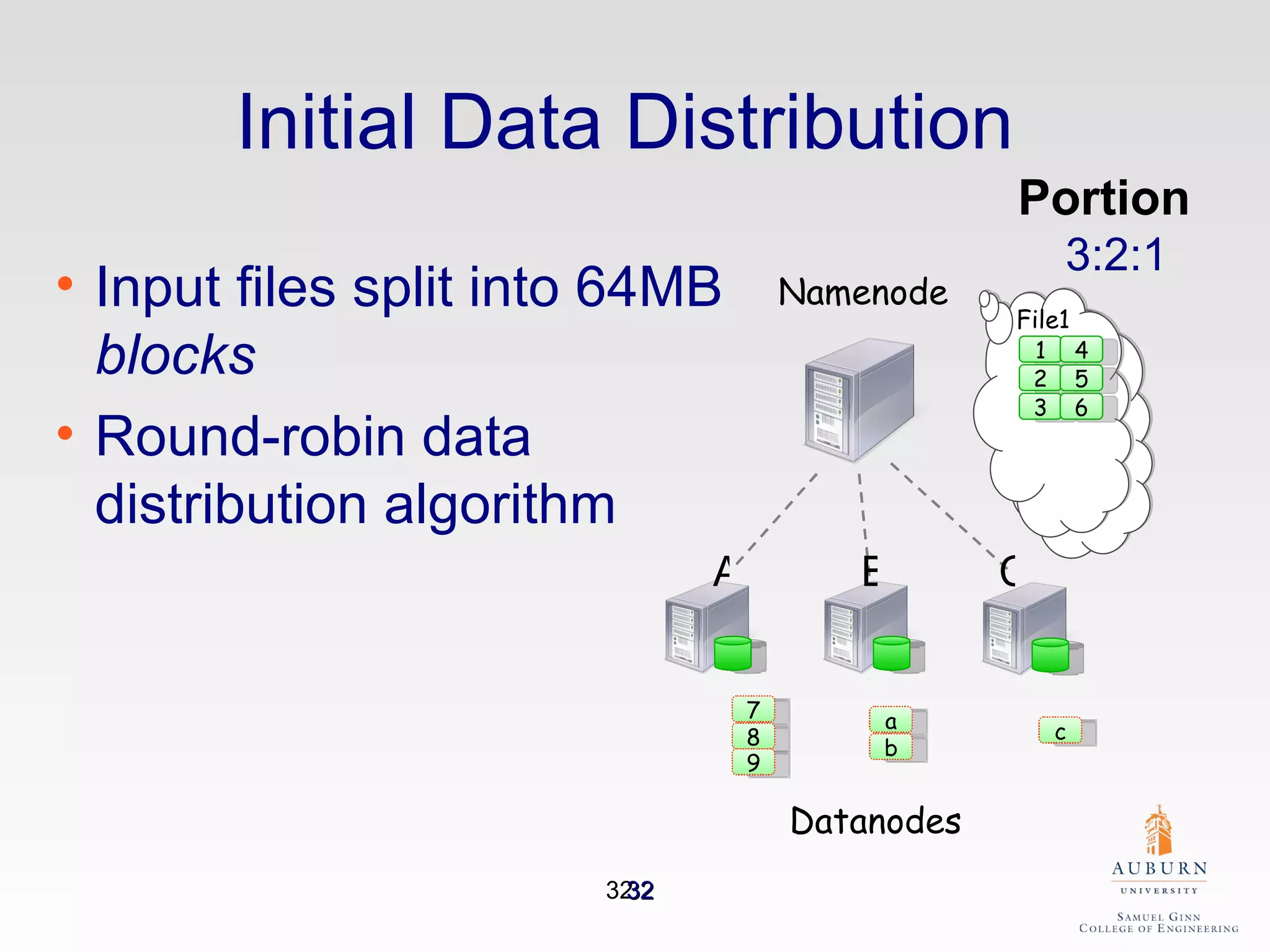
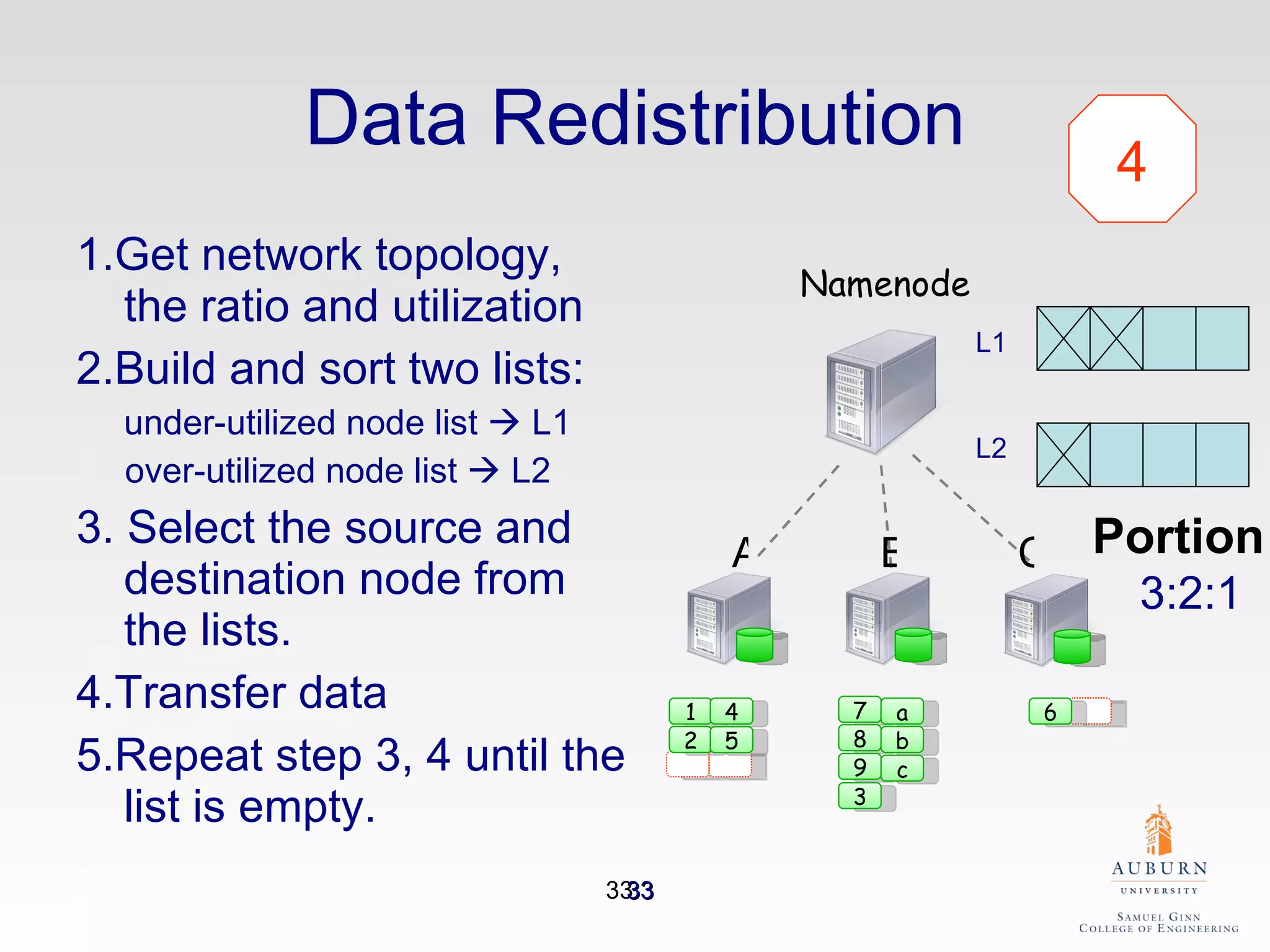

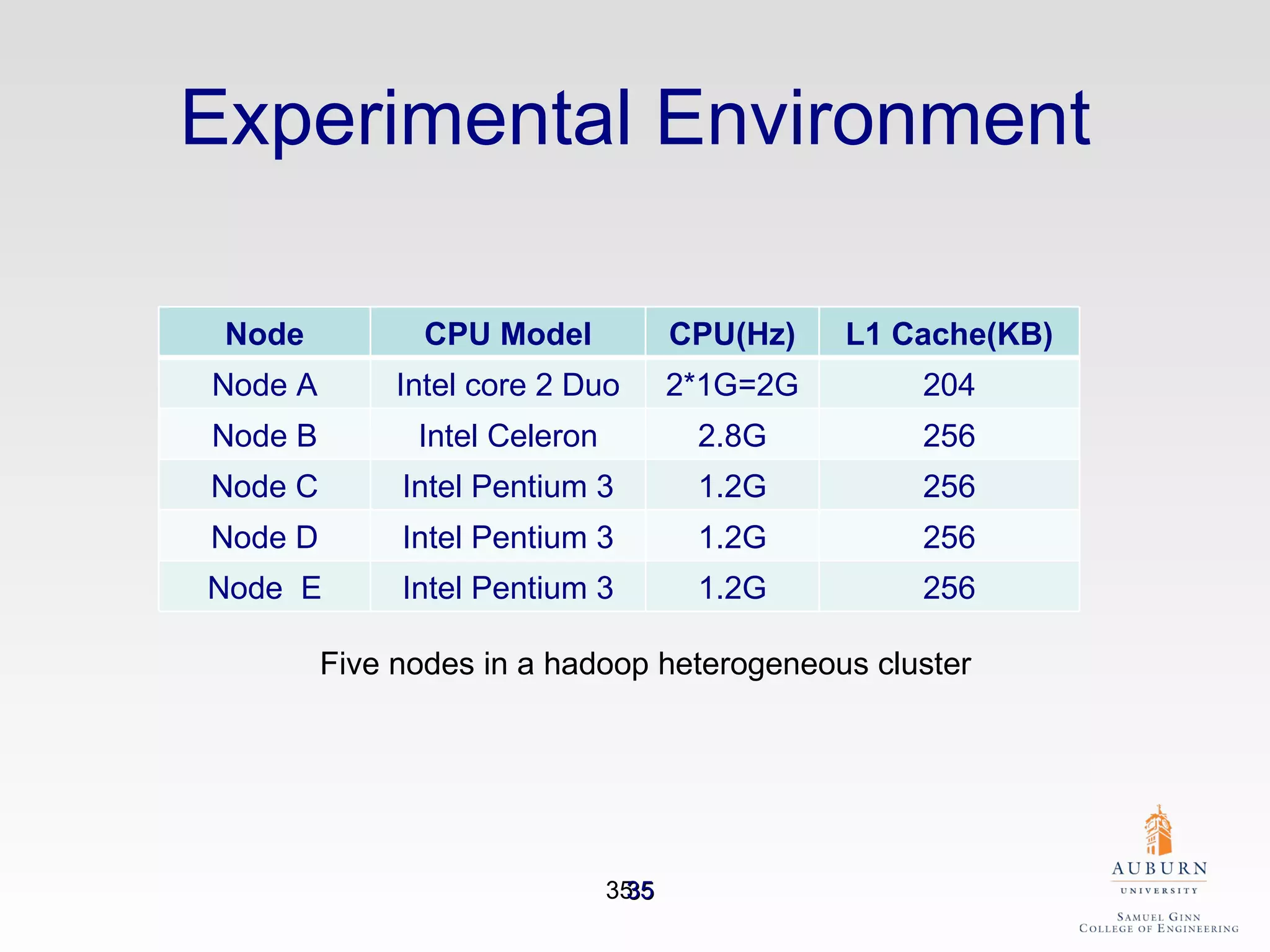


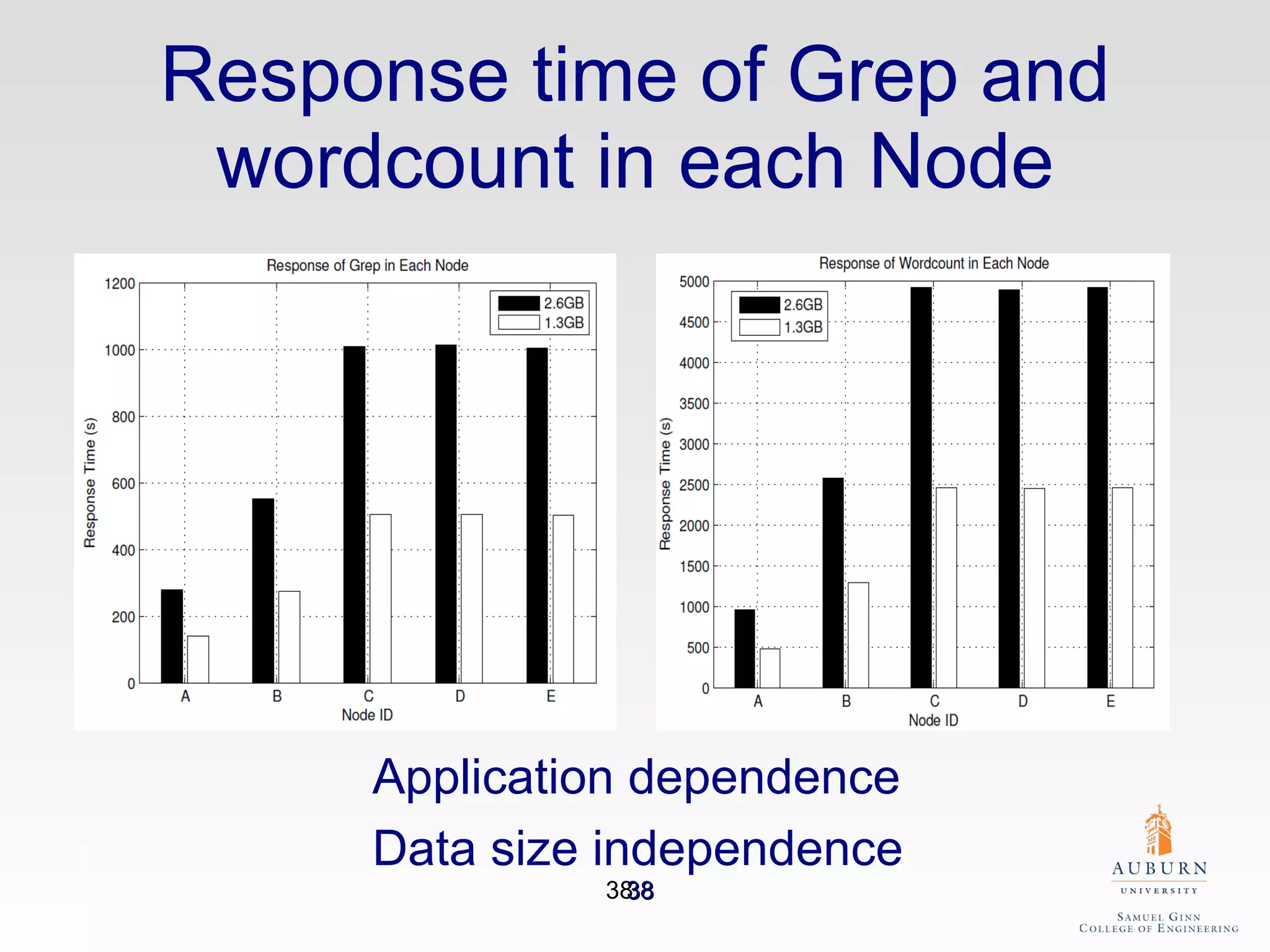

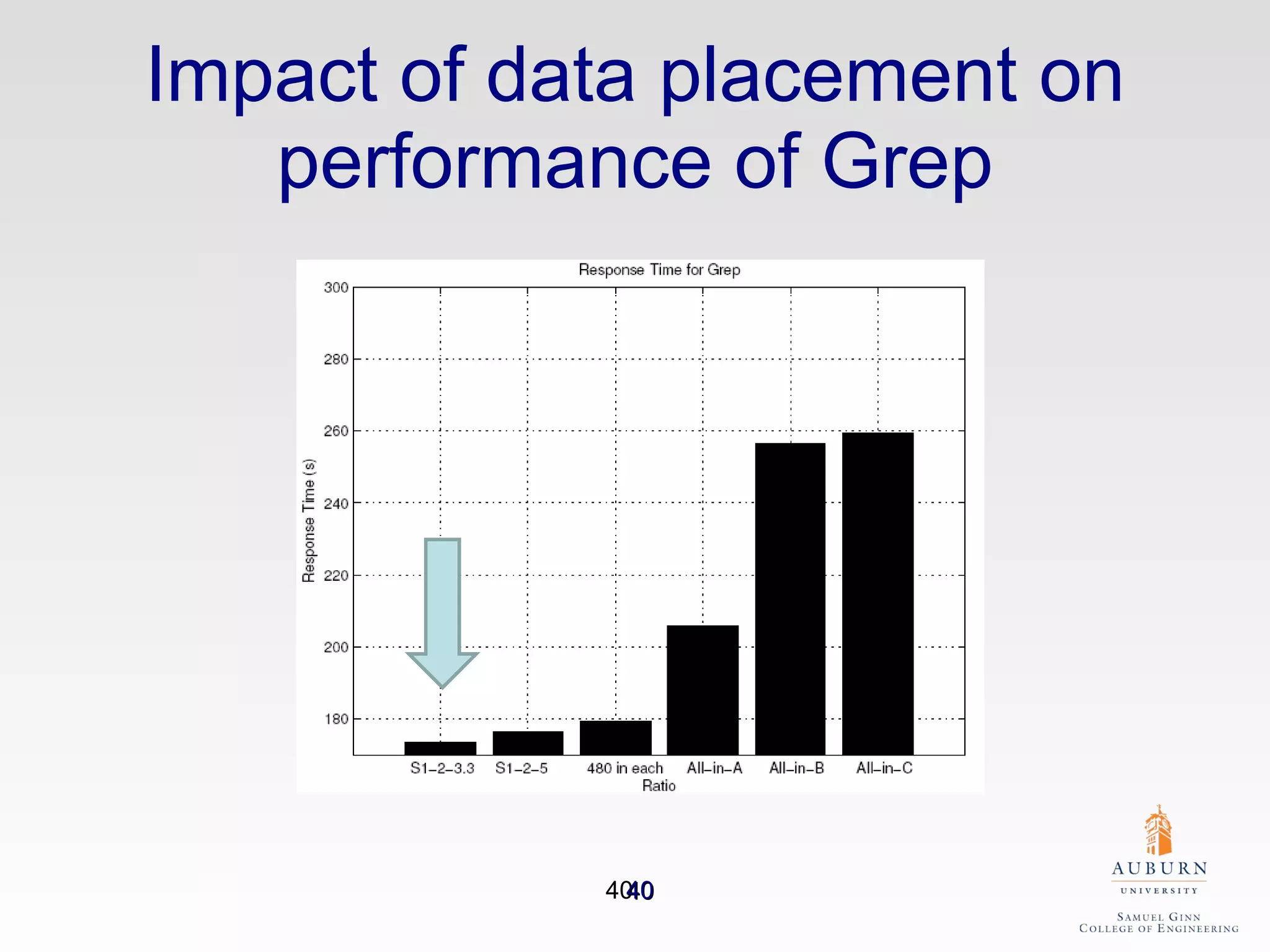
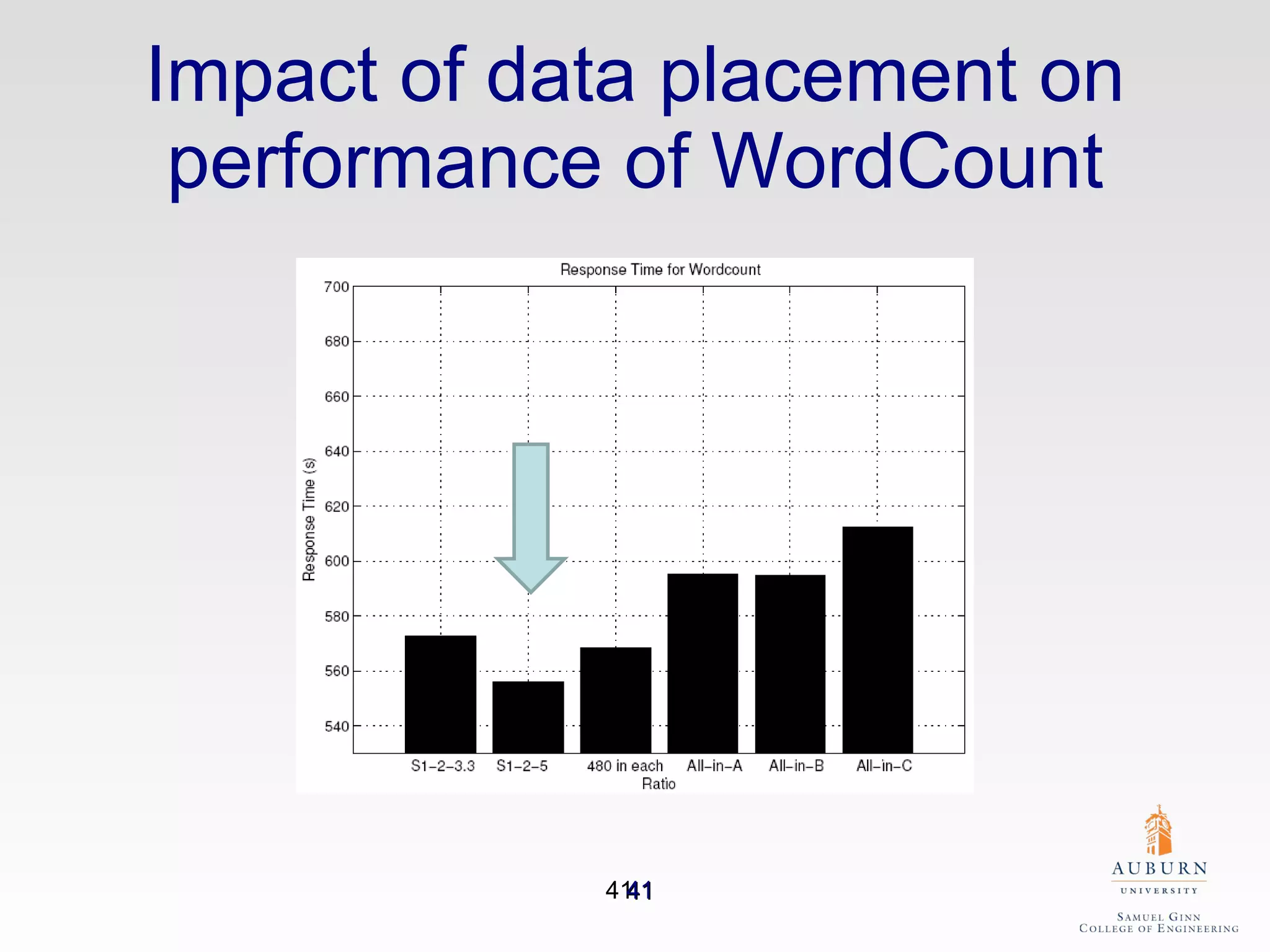







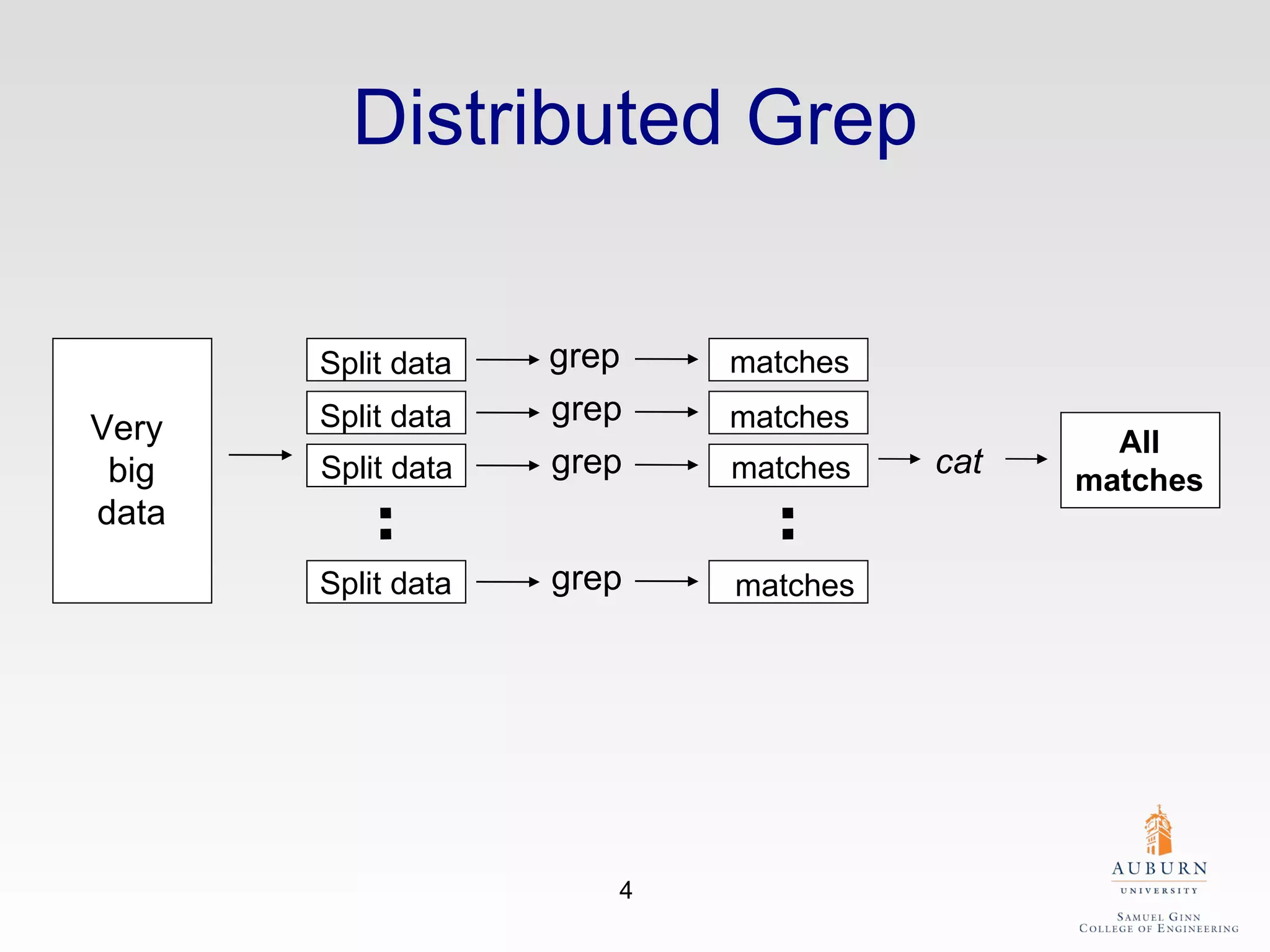
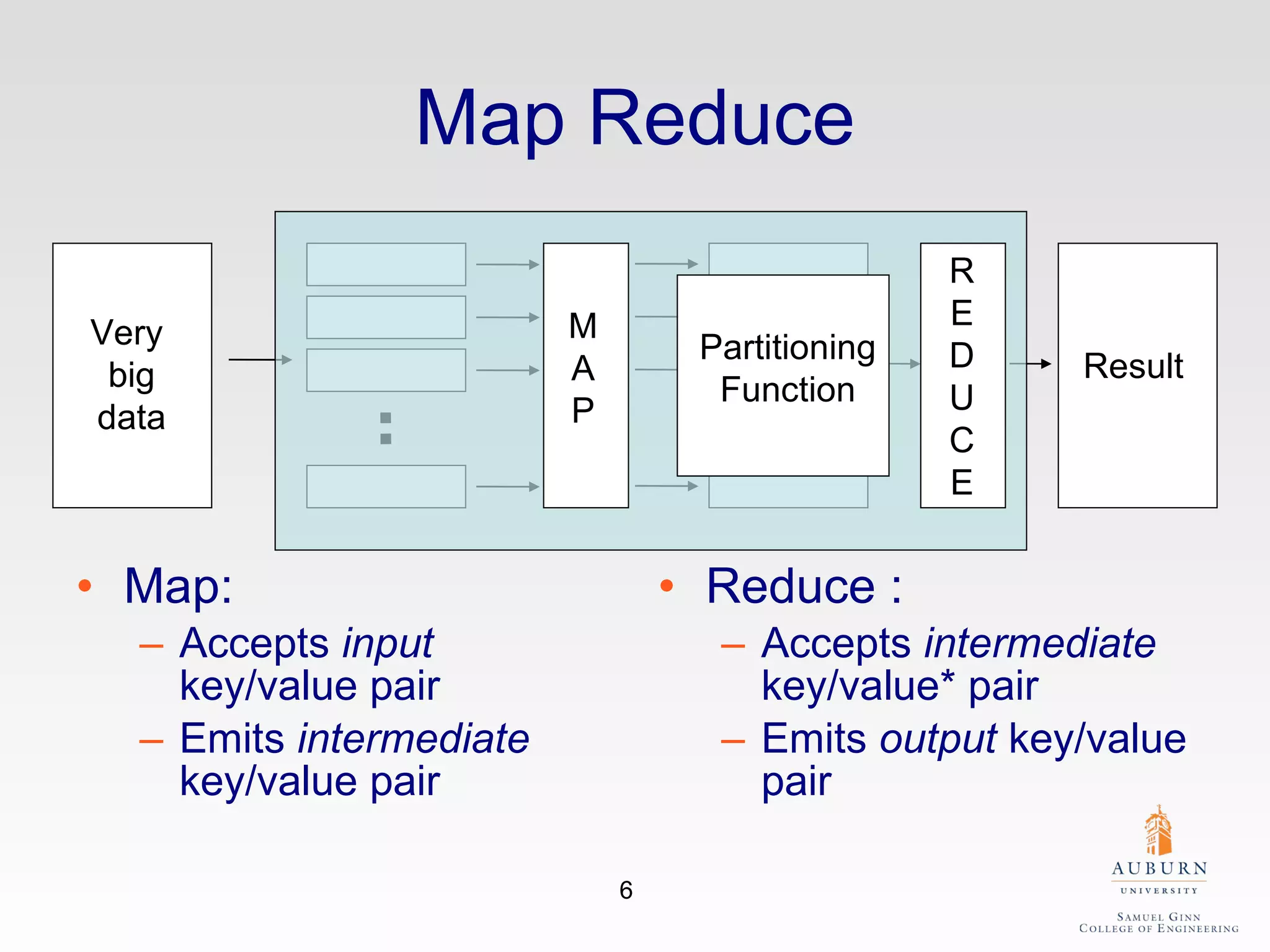
The document discusses the hdfs-hc module designed to enhance data placement in heterogeneous Hadoop clusters for improved performance in large-scale data processing. It outlines the MapReduce programming model, its implementation, and the challenges faced due to heterogeneity in computing resources. Additionally, it presents techniques for measuring computing ratios and optimizing data distribution across nodes to minimize time spent on data transfer and processing.













































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









































